兼顾Accuracy和Diversity!用于Image Captioning的变分Transformer模型!
【摘要】
在生成自然且语义正确的字幕时,准确度和多样性是两个基本的可度量表现。目前已经做出了许多努力,以加强其中一个,而另一个由于权衡差距而衰退。然而,妥协并没有取得进展。衰减的多样性使captioner成为一个重复机器,衰减的准确性使其成为一个假的描述机器。在这项工作中,作者开发了一种新的变分Transformer(Variational Transformer)框架,以同时提高精度和多样性。为了保证准确性,作者引入了“不可见信息先验”和“自动选择GMM”来指导编码器在不同场景中学习精确的语言信息和对象关系。为了确保多样性,作者提出了“范围中值奖励”baseline,以在基于RL的训练过程中保留更多多样性的候选句子,并获得更高的奖励。实验表明,与baseline相比,本文的方法实现了准确度(CIDEr)和多样性(self-CIDEr)的同时提升,分别提高了1.1%和4.8%。此外,在新提出的权衡差距衡量标准下,本文的方法优于其他方法,至少有3.55%的提升。
1. 论文和代码地址

Variational Transformer: A Framework Beyond the Trade-off between Accuracy and Diversity for Image Captioning
论文地址:https://arxiv.org/abs/2205.14458[1]
代码地址:未开源
2. Motivation

在图像字幕中,生成多样化和准确的字幕是一项具有挑战性的任务,尽管付出了最大努力,但尚未完成。虽然目前的captioning最新方法在准确性和多样性方面都取得了接近人类Ground Truth的数值结果,但定性结果不能说是好结果,如上图所示。人类在准确度(CIDEr)方面只有87.8,而目前机器学习模型的最高分至少达到130。由于描述的多样性,具有良好语义结构的人类字幕获得这种低度量结果是合理的。然而,对于基于机器学习的工作,很难以较低的准确率揭示真实的语义表现。另一方面,目前提出的用于捕获多样性的通用度量不涉及准确性,使用错误的词语可能会产生误导,从而表现出不断膨胀的多样性分数。因此,作者认为,多样性生成应取决于精度评估。
从这一点出发,作者提出了一种新的Variational Transformer(V aT)框架,该框架具有精度和多样性保证程序。具体来说,作者首先设计了一个“隐形信息优先”(IIP),使用无掩码输入句子来指导编码器来学习精确的语言attention map。然后,作者将V AE的单一高斯先验修改为“自动选择GMM”(AGMM),以适应不同场景中对象关系的复杂分布。IIP和AGMM共同构建了准确性保证程序。其次,为了确保准确性,强化学习(RL)是必不可少的。因此,作者提出重新制定self-critical sequence training(SCST),采用“范围中值奖励”(RMR) baseline,以在RL训练期间保留更多不同的候选句子,并获得更高的奖励。本文的变分框架和RMR共同构成了多样性保障程序。
3. 方法
3.1 Variational Auto Encoder
![]()
V AE理论建立在一个假设上,即原始数据点x围绕一个由嵌入z参数化的低维流形聚集。因此,只要知道z的真实分布,我们就可以从z重建x。式(1)右侧显示了vanilla VAE中x的对数似然的 Evidence Lower Bound(ELBO)。在理想情况下,我们希望p和q之间的距离最小化为0。因此,为了最大化x的objective likelihood,只需要最小化负的ELBO。然而,由于数据源有限,很难发现z的真实分布。传统的解决方案是假设潜变量z根据给定的分布进行操作,如标准正态分布或高斯混合分布。
在上式(1)中的ELBO中,作者发现了两个特定的优化目标:数据点x的重建对数似然和后验和先验之间的KL散度。在常见的AE模型中,仅使用对数似然作为重建损失,而在V AEs中,KL散度在正常AE结构的基础上引导一条额外的变分路径。在本文的模型中,作者利用这一路径引入“隐形信息先验”。
3.2 Overall Framework

在本文的VaT模型中,作者使用了多个注意力层和采样器来建立输入序列和输出概率之间的确定性和随机联系。在上图中,有两个不同的注意力层。对于自注意力层,作者保留了原始Transformer编码器的相同结构。对于多头注意层,作者仅在原有Transformer多头注意模块的基础上进行了细微的调整。具体而言,我作者在同一层中针对不同部分选择性地组合查询搜索、残差结构和前馈模块,如上图右侧所示。
Invisible Information Prior
对于每个时间步,当前单词的生成都基于生成的句子片段 x < t x
在训练期间,正态变分过程有一条额外的先验路径。在使用逐字生成模式时,此优先路径使V AE有可能引入不可见的信息。具体来说,对于潜变量z的每个位置,作者将完整的目标句子x视为先验信息,同时将mask句子 x _ < t x\_{
![]()
其中表示不同模块中的参数,并且:
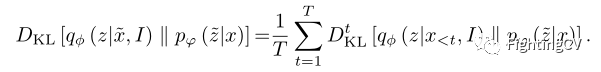
T是序列长度,中的图像I起到补充posterior encoder的作用,以弥补由零碎句子造成的信息丢失。
3.3 Auto-selectable Gaussian Mixture Model

在经典的VAE理论中,作者使用标准正态分布作为假设先验。然而,如上图(b)所示,使用单高斯尝试将整个图像集的信息嵌入到z的每个维度的一个参数元组(µ,σ)中。这将在直观和实际的情况下,由于图像的不区分嵌入,保留大量的噪声信息,同时,会导致数据分布与假设先验之间的不匹配。为了克服这个问题,之前工作提出了一种基于GMM的VAE模型,该模型根据每幅图像的目标检测结果手动选择GMM的核。这种模式有两个问题。首先,GMM的容量取决于预训练检测模型的效率。其次,不同场景中的同一对象在GMM中共享同一个核,因此具有相同的均值和方差。换句话说,这些具有不同语义信息的对象将共享相同的潜在表示。
如上图(a)所示,作者统计了训练集中包含“person”的不同对象组,并说明了前300个组的频率。它表现为长尾分布,这意味着可以用一个可行的核数嵌入出现在不同场景中的一个对象的主要信息。但是,每个核的选择应该依赖于语义级别(维度级别),而不是对象级别(一个内核对应一个对象)。因此,作者设计了一种新的GMM选择原则,该原则可以使用一个简单的可学习参数自动匹配不同场景中的对象及其潜在表示。具体而言,根据先验核概率,为z的每个维度选择核。从技术上讲,z的每个维度都有机会将信息的相应部分拟合到每个核中。
作者认为p和q是具有相同数量的组分K的GMM,的边缘密度可表示为:

其中和是p和q中每个分量的先验概率。是x中的高斯分布,µ是均值,是协方差。然后在相对熵的链式作用下,就有了以下上界:
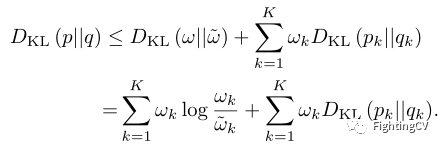
通过搜索p和q分量之间的优化映射关系,可以进一步最小化该上界,但对于深度学习模型来说,搜索过程过于昂贵。因此,作者用这个可行的上界替换了之前KL散度,并将训练目标改为:

3.4 Range-Median Reward Baseline
正如之前所讨论的,单方面提高多样性不足以生成表达性很强的字幕。RL训练对于保证精度性能至关重要。SCST的策略梯度如下所示:
![]()
其中,是从序列位置t的模型中采样的单词,b是贪婪搜索baseline。与一般的交叉熵损失相比,这种形式引入了更好的梯度方差减少。为了实现进一步的改进,减少方差,之前工作将贪婪抽样baseline替换为其余抽样候选句子的平均得分。SCST鼓励分数较高的样本随着训练的进行更有可能被抽样,这不可避免地导致多样性性能降低。即使对于本文的V aT模型,使用SCST也会对多样性性能造成影响。因此,在采用SCST方法时,作者提出了一种新的baseline,该baseline使用所有样本的距离中值来提高多样性,同时不牺牲精度。
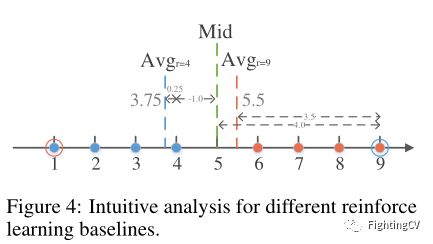
上图中给出了一个极端情况,其中蓝色和橙色圆圈表示两组奖励分数,每组有四个接近的奖励和一个异常值。用和表示这两个群。绿色虚线表示本文的范围中值奖励(RMR)baseline。计算公式如下所示:
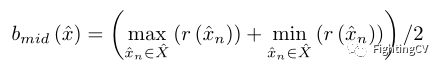
在公式中,作者考虑了所有样本奖励的全局信息。本文的中值baseline保留了更多分数更高的正样本,以提高有效的多样性性能,而不是保留错误推断,以不合理地增加多样性度量分数,而不考虑语义准确性。
本文的中值baseline的另一个优点是,与平均模式相比,鼓励和惩罚的强度会增加。在中,使用中位数和平均baseline,样本9的奖励分别为4.0和3.5。同样,分数较低的样本将使用本文的中值baseline受到更强的惩罚。
4.实验

在上表中,作者展示了不同模型的准确性和多样性性能。在相同的实验条件下,使用32核AGMM的VaT框架优于Transformer baseline,同时提高了准确性和多样性。同时,与其他多样性模型一样,使用单一高斯先验只能促进多样性。

在上表中,作者比较了几种最先进的精确方法,主要包括基于Transformer结构或类似注意力导向结构的方法。

上表总结了不同精度和多样性模型的多样性性能。

在上图(a)中,作者展示了与准确性和多样性性能相关的不同作品的性能。红色虚线是的零界限,其中对于线上的每个点。本文的模型最接近这个界限,这表明本文的模型实现了几乎与多样性消耗相同的精度提升率。在上图(b)中,作者报告了每项工作的具体TPR分数。本文方法是最接近人类标准的模型,具有坚实的精度性能。
5. 总结
在这项工作中,作者提出了一个由不同设计良好的模块组成的新框架,以确保具有准确语义结构的不同生成。首先,作者给出了IIP和AGMM组以保证精度性能。然后,作者给出了RMR baseline,以在坚实的精度基础上提高不同生成的质量。大量的实验表明,本文的模型在准确性和多样性方面都实现了同步提升。
参考资料
[1]
https://arxiv.org/abs/2205.14458: https://arxiv.org/abs/2205.14458
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
已建立深度学习公众号——FightingCV,欢迎大家关注!!!