style transform图像风格转换实战
一、项目目标
实现图像风格的转换,原理为:
1、设置vgg网络用于提取内容和风格特征,其中内容特征在输入靠后的层,风格特征在比较靠近输入的层上提取,分别保存
2、设置一个网络,forward返回的是nn.Parameter()。目标图的更新将在此基础上更新,相当于生成的新图是一个可以反向传播的计算图。将合成的图像视作网络参数。注意vgg网络只是用于特征提取,不参与更新。
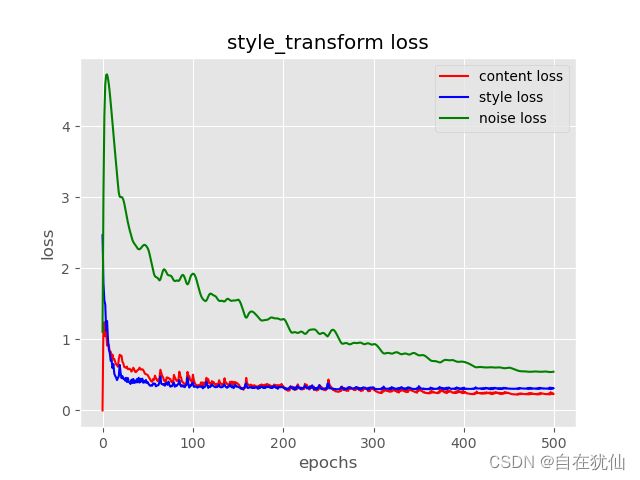
3、设置content loss、style loss 和图像全变分降噪损失noise loss。权重设置为1,1e3和10
4、训练策略采用Adam,并且采用变化的学习率每50轮*0.8
二、代码
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import d2I.torch1 as d2l
import torchvision.transforms as transforms
import torchvision
content_img_path = '../img/rainier.jpg'
style_img_path = '../img/autumn-oak.jpg'
mean= torch.tensor([0.485,0.456,0.406])
std = torch.tensor([0.229,0.224,0.225])
resize_shape = (300,450)
content_img = d2l.Image.open(content_img_path)
style_img = d2l.Image.open(style_img_path)
# 图像预处理
def preprocess(X,resize_shape):
ts = transforms.Compose([
transforms.Resize(resize_shape),
transforms.ToTensor(),
transforms.Normalize(mean,std)
])
return ts(X).unsqueeze(0)
# 图像后处理,用以显示
def proprocess(X):
img = X[0].detach().cpu()
img = torch.clamp(img.permute(1,2,0)*std+mean,0,1)
return transforms.ToPILImage()(img.permute(2,0,1))
style_nets,content_nets = [0,5,10,19,28],[25] # 一般来说,越靠近输入层,越容易抽取图像的细节信息;反之,则越容易抽取图像的全局信息。
net = torchvision.models.vgg19(pretrained=True)
net = nn.Sequential(*[net.features[i] for i in range(max(content_nets+style_nets)+1)])
def feature_extract(X,net,content_nets,style_nets):
contents=[]
styles=[]
for i in range(len(net)):
X = net[i](X)
if i in content_nets:
contents.append(X)
elif i in style_nets:
styles.append(X)
return contents,styles
def get_contents(X, net, content_nets, style_nets,device):
content_x = preprocess(X, resize_shape).to(device)
content_y,_ = feature_extract(content_x, net, content_nets, style_nets)
return content_x,content_y
def get_styles(X, net, content_nets, style_nets,device):
style_x = preprocess(X, resize_shape).to(device)
_,style_y = feature_extract(style_x, net, content_nets, style_nets)
return style_x,style_y
def content_loss(cy_hat,cy):
return torch.square(cy_hat-cy.detach()).mean()
def gram(y):
num_channel,n = y.shape[1],y.numel()//y.shape[1]
y = y.reshape((num_channel,n))
return torch.matmul(y,y.T)/(num_channel*n)
def style_loss(y_hat,y_gram):
return torch.square(gram(y_hat)-y_gram.detach()).mean()
def nosie_loss(x):
no_l = 0.5 * (torch.abs(x[:,:,1:,:] - x[:,:,:-1,:]).mean() +
torch.abs(x[:,:,:,1:] - x[:,:,:,:-1]).mean())
return no_l
class sythnetic_generator(nn.Module):
def __init__(self,resize_shape,**kwargs):
super(sythnetic_generator, self).__init__()
self.resize_shape = resize_shape
self.weight = nn.Parameter(torch.rand(*resize_shape))
def forward(self):
return self.weight
def loss(x,c_preds,c_y,s_preds,s_grams,c_weight,s_weight,n_weight):
c_l = [content_loss(c_hat,c_label)*c_weight for c_hat,c_label in zip(c_preds,c_y)]
s_l = [style_loss(s_hat,s_gram)*s_weight for s_hat,s_gram in zip(s_preds,s_grams)]
n_l = [nosie_loss(x)*n_weight]
loss_out = sum(c_l+s_l+n_l)
return float(sum(c_l)),float(sum(s_l)),float(sum(n_l)),loss_out
def init(x,style_ys,device):
generator = sythnetic_generator(x.shape)
generator = generator.to(device)
generator.weight.data.copy_(x.data)
y_gram = [gram(style_y) for style_y in style_ys]
return generator,generator(),y_gram
def train(content_img,style_img,net,lr,n_epochs,decay_epochs,device):
c_loss,s_loss,n_loss = [],[],[]
content_x, content_y = get_contents(content_img, net, content_nets, style_nets,device)
style_x, style_y = get_styles(style_img, net, content_nets, style_nets,device)
generator,x, y_gram = init(content_x,style_y,device)
optimizer = torch.optim.Adam(generator.parameters(), lr)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=decay_epochs, gamma=0.8)
for epoch in range(n_epochs):
optimizer.zero_grad()
contents_preds,styles_pred = feature_extract(x,net,content_nets,style_nets)
c_l,s_l,n_l,loss_out = loss(x,contents_preds,content_y,styles_pred,y_gram,1,1e3,10)
c_loss.append(c_l);s_loss.append(s_l);n_loss.append(n_l)
loss_out.backward()
optimizer.step()
lr_scheduler.step()
print(f'epoch:{epoch+1} content_loss:{c_l} style_loss:{s_l} noise_loss:{n_l}')
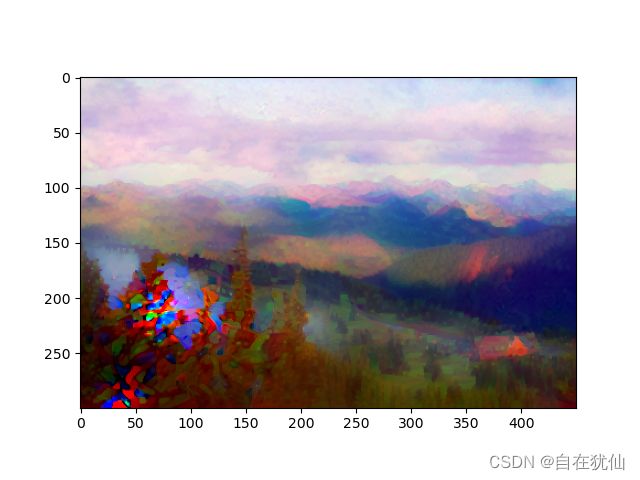
if (epoch+1) % 500 == 0:
show_img = proprocess(x)
d2l.plt.imshow(show_img)
plt.show()
x = range(n_epochs)
plt.figure()
plt.style.use('ggplot')
plt.plot(x,c_loss,'-r',label='content loss')
plt.plot(x, s_loss, '-b', label='style loss')
plt.plot(x, n_loss, '-g', label='noise loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend(loc='best')
plt.title('style_transform loss')
plt.show()
n_epochs=500
decay_epochs=50
lr=0.3
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
train(content_img,style_img,net,lr,n_epochs,decay_epochs,device)
三、实际效果
内容图:

风格图:

运行生成的结果图:
损失函数图: