基于GMM—HMM的语音识别全过程
1.基础知识
语音识别技术就是让机器通过识别与理解把语音信号转换为相应的文本或命令的技术。
语音识别的难点:地域性、场景性、生理性、鸡尾酒问题(多人)。
语音识别任务分类:孤立词识别、连续词识别。
语音识别任务处理流程:
1)语音预处理
2)语音识别算法:传统GMM—HMM算法、基于深度学习算法
2.语音预处理
1)数字化:将从传感器采集的模拟语音信号离散化为数字信号
2)预加重:目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。
3)端点检测:也叫语音活动检测(Voice Activity Detection,VAD),目的是对语音和非语音的区域进行区分,即去掉静音、噪声部分,找到一段语音真正有效的内容。
VAD算法可以粗略的分为三类:基于阈值的、作为分类器的、基于模型
4)分帧:因为语音的短时平稳性,所以要进行“短时分析,即将信号分段,每一段称为一帧(一般10~30ms)。分帧虽然可以使用连续分段的方法,但是一般要采用交叠分段的方法。这是为了使帧与帧之间平滑过度,保持其连续性。

5)加窗:采用可移动的有限长度窗口进行加权的方法来实现语音信号的分帧。加窗的目的是减少语音帧的截断效应。常见的窗有:矩形窗、汉宁窗和汉明窗等。
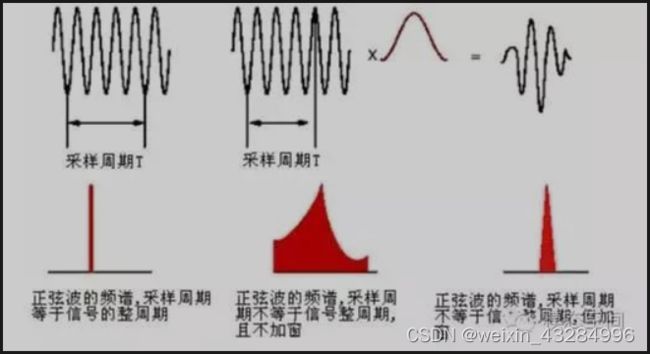
通常对信号进行截断、分帧都需要加窗,因为截断基本都会有频域泄露,而窗函数可以减少截断带来的影响,可以提高变换结果的分辨率。(详解见:什么是泄漏?)
加窗的代价是一帧信号两端的部分被削弱了,没有像中间那部分一样得到重视,故可以使用交叠分段的方法进行分帧。
3.语音识别算法(GMM—HMM算法)
知识补充:
1)三音素表示:[前一个音素,当前音素,下一个音素]三个音素来表示一个音素,因为同一个音素的相邻音素不同,音素的发音也会有所不同
2)每个音素由N个状态构成,N个状态用于表示音素:开始->稳定->结束的整个过程
3)一段特征帧序列往往有很多帧,远远多于状态数,我们的做法是按顺序重复输出每个状态,然后计算每种状态序列概率的和。
例如:三音素分别为:a、b、c,,特征帧的数目为10,那么可能的状态序列为aaabbbcccc、aaaabbbccc等,我们会将所有状态序列的概率求和作为这个特征帧序列由这三个音素产生的概率。
4)语音识别中,音频数据为HMM中的观测状态(可以直接听见看见),音频对应的音素为隐藏状态(观测状态由隐藏状态生成)。
5)贝叶斯公式:
![]()
其中:
![]() :先验概率,表示对一个随机变量概率的最初认识
:先验概率,表示对一个随机变量概率的最初认识
![]() :似然概率,又叫类条件概率密度(类概密),表示在承认先验条件概率下另一个与之相关的随机变量的表现
:似然概率,又叫类条件概率密度(类概密),表示在承认先验条件概率下另一个与之相关的随机变量的表现
![]() :后验概率。表示当前拥有 X 这个条件后 Y的概率
:后验概率。表示当前拥有 X 这个条件后 Y的概率
训练过程:每次输入模型的是一个帧序列和单词序列,训练过程属于HMM模型中的学习问题,使用EM算法迭代求解。
训练步骤:
1)将单词序列细化为三音素序列
2)穷举当前三音素序列所有可能的连续状态序列
3)初始化初始状态矩阵 (π) ,隐藏状态转移矩阵 (A) ,生成观测状态概率矩阵 (B)。
4)根据上一步初始化的模型参数![]() ,通过前向或者后向算法求得每种状态序列的概率(先验)
,通过前向或者后向算法求得每种状态序列的概率(先验)![]()
5)计算每种状态序列得到当前三音素的对数似然函数![]() ,
, 为变量。
为变量。
6)求三音素序列在每种状态序列(先验)上的期望Q(E-step):
![]()
并是这个期望最大(M-step)。从而求得新的模型参数![]() (拉格朗日乘子法)
(拉格朗日乘子法)
7)重复执行3)4)5)6)步直至收敛。
当我们的生成观测状态概率矩阵 (发射矩阵)使用GMM来表示时,我们又多出了 n 个混合高斯模型,因此还要在不同的GMM模型上进行求和,公式如下:
![]()
其中![]() 表示 n 个混合高斯模型参数。
表示 n 个混合高斯模型参数。
训练结束,输出GMM—HMM系统参数![]() 及
及![]() 。
。
识别过程(解码):根据GMM—HMM系统参数及当前输入帧序列,求得概率最大路径。
识别步骤:
1)穷举当前帧序列所对应的所有可能状态序列
2)根据![]() ,得到特征帧序列由每种状态序列产生的概率
,得到特征帧序列由每种状态序列产生的概率
3)一段特征帧序列远多于单词对应的状态数,同一单词序列细化成状态数后,需要将序列中的状态数目扩展到特征帧的数量,拓展后的状态序列会有多种可能,我们将每种可能的状态序列的概率求和,作为特征帧被识别成这个单词序列的似然概率![]() (承认生成的状态序列为 I ,则生成特征帧序列为 O 的概率)。
(承认生成的状态序列为 I ,则生成特征帧序列为 O 的概率)。
4)将上一步计算得到的单词序列的似然概率![]() 和语言模型中的单词序列先验概率
和语言模型中的单词序列先验概率![]() 相乘作为单词序列的后验概率
相乘作为单词序列的后验概率![]() (特征帧序列 O 已经出现,
(特征帧序列 O 已经出现,![]() )。
)。
5)找到后验概率最大的单词序列作为特征帧序列的识别结果。