泰坦尼克号生存预测-----基于决策树模型(机器学习- sklearn)
"""主要是存储本人的笔记为主,但是希望和各位进行交流""
简介:该代码主要会用 train_test_split 及 cross_val_score验证模型的有效度。 此外,还会用GridSearchCV找出模型最优的参数。
step 1:对数据进行处理,比如填补或者删除缺失值。此外, 决策树无法处理文字,所以,我们需要把性别(sex)及 船票号码(embark)转换数字。比如,0,1,2等无意义的数字。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import numpy as np
import graphviz
"""读取数据及观察数据"""
data = pd.read_csv("data【瑞客论坛 www.ruike1.com】.csv")
data.info()
data.head()
"""处理数据"""
##删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
# inplace 是指将原有的数据进行合并。axis = 1 是指列00
data.drop(["Cabin","Name","Ticket","Cabin"],inplace=True,axis=1)
data.info()
#以整体年龄的平均数填充缺失值年龄,
data["Age"] = data["Age"].fillna(data["Age"].mean())
data.info()
#将缺失值的“行” 一并删除。 括号内 默认是“0”, 0 是指行的意思,反之1则是列的意思
data = data.dropna()
data.info()
#tolist是将数据转换成list的形式,而 unique主要是找出该数据含有那几种分类
label_1 = data["Embarked"].unique().tolist()
#将数据以 o 1 3 进行替换。 替换的原因是 decision tree classifier是不接受中文字的运算
data["Embarked"] = data["Embarked"].apply(lambda x: label_1.index(x))
#这是另外一种投机的转换方法。 因为 male 和femal 是以 true 和 false 的数据形式进行表达。
#我们直接按照下面的代码进行强制转换便可
data["Sex"] = (data["Sex"]== "male").astype("int")
Step 2 建立模型。
"""建立模型"""
#取出 所有行 的所有列的columns不等于 survivied的值
x = data[["Pclass","Sex","Age","SibSp","Fare","Embarked"]]
y = data["Survived"]
print(y)
#拆分数据集
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size = 0.3)Step 3 粗略看看模型的分数(用train test split 及 cross validation(交叉验证)的方法)。
注意到:由于在step 2, 我们用了train test split 分割了数据。 数据的索引会有所混乱(ie,0 1 2,30,29,60之类的情况)。 所以在下面代码的 for 循环 是为了将代码的索引整理成 0 1 2 3. 这个步骤是为了在后面进行更好的测试模型的效能。
#由于索引在拆分的时候已经出现了混乱, 所以为了更好的进行modeling的操作,所以需要进行重新排列索引
for i in [x_train, x_test, y_train, y_test]:
i.index = range(i.shape[0])
clf = DecisionTreeClassifier(random_state=(25))
clf = clf.fit(x_train, y_train)
#这个是第一种验证模型的有效度
score_1 = clf.score(x_test, y_test)
score_1
#这是第二种方法验证模型的有效度
score_2 = cross_val_score(clf, x,y, cv=10).mean()
score_2
从上图可以看到两个score 的分数差异很大(0.58及0.78. 满分为1)。说明model还有很大的改善空间。
Step 4 找出模型的最优的参数。
1.train and test split 和 cross_val_score 的方法
我们会用matplotlip 进行数据可视化。看看cross_val_score 和cross_val_score 的有效度有没有出现过大的偏差。如果有的话,会用其他方法参数将模型的表现进行最大的提高。
"""数据可视化,看看model的有效度"""
tr = []
td = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=(25), max_depth=(i +1),criterion="entropy",min_samples_leaf =16)
clf.fit(x_train,y_train)
score_tr = clf.score(x_train,y_train)
score_td = cross_val_score(clf, x,y,cv =10).mean()
tr.append(score_tr)
td.append(score_td)
print(max(td))
plt.plot(range(1,11),tr, color = "red",label ="train")
plt.plot(range(1,11),td, color = "blue",label ="test")
plt.legend()
plt.show()
#利用上面得到的参数重新建模,看看实际效果
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,max_depth=3
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
从上图可以看到,train(红线) 和 test(蓝线)最接近重叠的地方是当max_depth= 3的时候。因此,我们会选择 maxd_depth 等于 3的结果。基于个人的经验, 我觉得criterion改为“entropy'会令model的性能更加好。
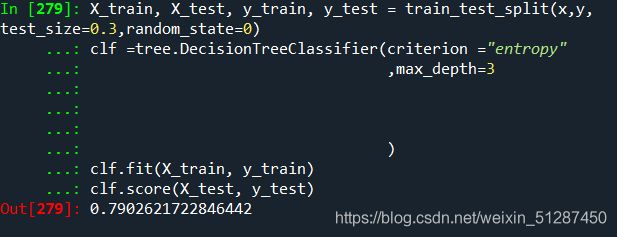
当我们套入这个参数(max_depth= 3)及criterion = entropy',我们可以看到分数是0.79分数。比step 3的分数要好很多。
2. 用GridSearchCV的方法找出最优的参数。但是这个方法并非完美的。因为,这个方法是基于下列的所以参数中找出最高的score,但是也许不要 min samples leaf 的参数或许能得到更高的分数
""利用用网格搜索调整参数,找出最高的有效度的决策树。但是这并非最精准的。因为,这个方法是基于下列的所以参数中找出最高的score,
但是也许不要 min samples leaf 的参数或许能得到更高的分数"""
gini_thresholds = np.linspace(0,0.5,20)
arameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(x_train,y_train)
GS.best_params_
GS.best_score_
#利用上面得到的参数重新建模,看看实际效果
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,splitter="best"
,max_depth=6
,min_samples_leaf =1
,min_samples_split =10
,min_impurity_decrease= 0
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
Step 5: 我们基于 Step 4已经找到了最优模型的参数,选择可以用graphviz 进行决策树的可视化了。
"""选取最优的分数进行graphviz可视化"""
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,splitter="best"
,max_depth=6
,min_samples_leaf =1
,min_samples_split =10
,min_impurity_decrease= 0
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
feature_name =["Pclass","Sex","Age","SibSp","Fare","Embarked"]
dot_data = tree.export_graphviz(clf
, feature_names = feature_name
, class_names =["生","死"]
, filled = True#圆头的意思
, rounded =True#颜色的意思
)
graphviz.Source(dot_data)
最后的结果如下啦:

我对于 这一步可视化的代码并不是特别熟悉。希望各位能提供更好的代码及解释,感谢!
完整代码如下:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import numpy as np
import graphviz
"""读取数据及观察数据"""
data = pd.read_csv("data【瑞客论坛 www.ruike1.com】.csv")
data.info()
data.head()
"""处理数据"""
##删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
# inplace 是指将原有的数据进行合并。axis = 1 是指列00
data.drop(["Cabin","Name","Ticket","Cabin"],inplace=True,axis=1)
data.info()
#以整体年龄的平均数填充缺失值年龄,
data["Age"] = data["Age"].fillna(data["Age"].mean())
data.info()
#将缺失值的“行” 一并删除。 括号内 默认是“0”, 0 是指行的意思,反之1则是列的意思
data = data.dropna()
data.info()
#tolist是将数据转换成list的形式,而 unique主要是找出该数据含有那几种分类
label_1 = data["Embarked"].unique().tolist()
#将数据以 o 1 3 进行替换。 替换的原因是 decision tree classifier是不接受中文字的运算
data["Embarked"] = data["Embarked"].apply(lambda x: label_1.index(x))
#这是另外一种投机的转换方法。 因为 male 和femal 是以 true 和 false 的数据形式进行表达。
#我们直接按照下面的代码进行强制转换便可
data["Sex"] = (data["Sex"]== "male").astype("int")
data.head()
"""建立模型"""
#取出 所有行 的所有列的columns不等于 survivied的值
x = data[["Pclass","Sex","Age","SibSp","Fare","Embarked"]]
y = data["Survived"]
print(y)
#拆分数据集
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size = 0.3)
#由于索引在拆分的时候已经出现了混乱, 所以为了更好的进行modeling的操作,所以需要进行重新排列索引
for i in [x_train, x_test, y_train, y_test]:
i.index = range(i.shape[0])
clf = DecisionTreeClassifier(random_state=(25))
clf = clf.fit(x_train, y_train)
#这个是第一种验证模型的有效度
score_1 = clf.score(x_test, y_test)
score_1
#这是第二种方法验证模型的有效度
score_2 = cross_val_score(clf, x,y, cv=10).mean()
score_2
"""数据可视化,看看model的有效度"""
tr = []
td = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=(25), max_depth=(i +1),criterion="entropy",min_samples_leaf =16)
clf.fit(x_train,y_train)
score_tr = clf.score(x_train,y_train)
score_td = cross_val_score(clf, x,y,cv =10).mean()
tr.append(score_tr)
td.append(score_td)
print(max(td))
plt.plot(range(1,11),tr, color = "red",label ="train")
plt.plot(range(1,11),td, color = "blue",label ="test")
plt.legend()
plt.show()
#利用上面得到的参数重新建模,看看实际效果
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,max_depth=3
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
"""利用用网格搜索调整参数,找出最高的有效度的决策树。但是这并非最精准的。因为,这个方法是基于下列的所以参数中找出最高的score,
但是也许不要 min samples leaf 的参数或许能得到更高的分数"""
gini_thresholds = np.linspace(0,0.5,20)
arameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(x_train,y_train)
GS.best_params_
GS.best_score_
#利用上面得到的参数重新建模,看看实际效果
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,splitter="best"
,max_depth=6
,min_samples_leaf =1
,min_samples_split =10
,min_impurity_decrease= 0
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
"""选取最优的分数进行graphviz可视化"""
X_train, X_test, y_train, y_test = train_test_split(x,y, test_size=0.3,random_state=0)
clf =tree.DecisionTreeClassifier(criterion ="entropy"
,splitter="best"
,max_depth=6
,min_samples_leaf =1
,min_samples_split =10
,min_impurity_decrease= 0
)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
feature_name =["Pclass","Sex","Age","SibSp","Fare","Embarked"]
dot_data = tree.export_graphviz(clf
, feature_names = feature_name
, class_names =["生","死"]
, filled = True#圆头的意思
, rounded =True#颜色的意思
)
graphviz.Source(dot_data)