tensorflow/serving部署keras的h5模型服务
当我们使用keras训练好模型之后,下一步就是部署服务了,采用flask直接加载keras的h5模型,服务的并发性能会很低。如果为了追求高并发性能,就可以采用Nginx+gunicorn+gevent的方式来启动服务,这种方式服务虽然可以达到极高的并发性能,但却存在一个问题,也就是gunicorn的方式是启动了多个进程,每个进程都会加载一次模型,造成服务启动后所占用的内存很大,另外直接加载h5模型,整个进程随着使用过程中占用内存也会也逐步增大,这就是python存在了内存泄漏的问题。之前我一个项目部署到生产环境中,使用了两天,占用内存就已经达到了十几个G,因此不得不采用每天定时重启服务这种策略。因此采用tensorflow/serving的方式来部署服务。
本文中采用的环境为:
python 3.8.13
TensorFlow 2.50
1 keras的h5模型转换为pb格式
这里以一个验证码识别模型为例进行转换,验证码识别采用crnn+ctc的形式训练,得到的模型文件为h5格式。
使用如下代码将h5模型转换为tensorflow/serving需要的pb格式文件:
from keras import models
import keras.backend as K
from tensorflow.python.framework import graph_util
import tensorflow._api.v2.compat.v1 as tf
tf.disable_eager_execution()
'''
tf.saved_model.builder.SavedModelBuilder
这种模型转换的模型可以提供给TensorFlow Serving使用
多一个Variable文件
'''
def keras_model_to_tfs(model, export_path):
signature = tf.saved_model.signature_def_utils.predict_signature_def(
inputs={'input_x': model.input},
outputs={'output_y': model.output}
)
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
builder.add_meta_graph_and_variables(
sess=K.get_session(),
tags=[tf.saved_model.tag_constants.SERVING],
signature_def_map={
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: signature,
},
legacy_init_op=legacy_init_op)
builder.save()
print('转换完成!')
if __name__=='__main__':
network=models.load_model('./model/hebei.h5')
export_path='pb2'
keras_model_to_tfs(network,export_path)
运行如上代码,得到转换好的pb文件。

重复以上过程,再转换一个模型,新建如下目录yzmModels,该目录下的树形结构为:

hebei目录下的100001目录的文件为转换的第一个模型文件;
chongqing目录下的100001目录的文件为转换的第二个模型文件;
models.config的文件内容如下:
model_config_list:{
config:{
name:"hebei",
base_path:"/models/multiModel/hebei",
model_platform:"tensorflow"
},
config:{
name:"chongqing",
base_path:"/models/multiModel/chongqing",
model_platform:"tensorflow"
}
}
2 使用docker启动tensorflow/serving服务
将yzmModels这个目录上传到服务器里,如下所示:

拉取一个tensorflow/serving的docker镜像
docker pull tensorflow/serving:2.5.1
接着启动docker服务:
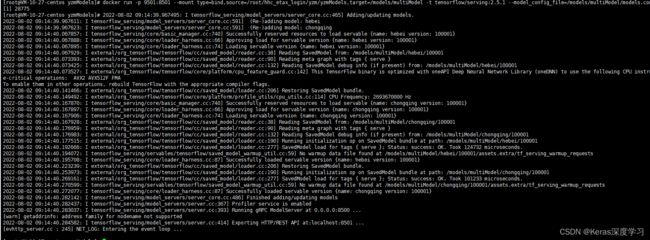
docker run -p 9501:8501 --mount type=bind,source=/root/hhc_etax_login/yzm/yzmModels,target=/models/multiModel -t tensorflow/serving:2.5.1 --model_config_file=/models/multiModel/models.config &
9501为主机上的端口,8501为容器中的端口,容器中的端口8501这个不可更改。source=/root/hhc_etax_login/yzm/yzmModels这个目录为主机上模型文件所在目录。启动成功后,如下所示:
 服务开启好后,我们来测试这个TensorFlow/serving服务是否运行成功,容器的服务对应于主机上的端口为9501,因此使用如下命令测试:
服务开启好后,我们来测试这个TensorFlow/serving服务是否运行成功,容器的服务对应于主机上的端口为9501,因此使用如下命令测试:
curl http://localhost:9501/v1/models/hebei
返回结果如下:
{
"model_version_status": [
{
"version": "100001",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": ""
}
}
]
}
使用python代码来测试hebei这个模型,TensorFlow/serving服务传的数据是矩阵形式的,代码如下:
import numpy as np
import requests
import json
if __name__=='__main__':
#(1, 32, 77, 3)
#img_array代表图像数据,也就是传入模型的输入数据
img_array=np.random.randn(1,32,77,3)
#数组形式数据转为列表格式
img_list=img_array.tolist()
json_data={
'instances':img_list
}
url='http://localhost:9501/v1/models/hebei:predict'
res=requests.post(url=url,json=json_data)
if res.status_code==200:
#对模型的预测结果进行处理
predictions=json.loads(res.text).get('predictions')
if predictions:
y_pred=np.array(predictions)
print(y_pred.shape)
如上所示,因为对于hebei模型的输入图片数据格式形状为(1,32,77,3),在代码里构造了一个这种数据,在使用模型进行预测验证码图片时,这个地方传入真实图片的矩阵数据即可。运行结果如下:
