OCR在转转游戏的应用
OCR在转转游戏的应用
1.什么是OCR?
OCR(optical character recognition)是将图片进行扫描,提取其中的文字的技术。如今,不少业务领域都用到了OCR技术。比如某些快递软件支持识别包含地址信息的图片,解析出用户地址。

2.游戏业务引入OCR的背景
在用户发布游戏商品时,我们希望用户将参数填的越全越好,这样有助于搜索、个性化推荐、统计数据。但是,以王者荣耀为例,目前王者荣耀有400+皮肤,将所有拥有的皮肤填写一遍非常麻烦,所以我们希望通过用户上传图片或商品封面,提取其中的参数信息,填入商品信息中,以达到补全参数、减少用户操作的目的。

3.问题
目前腾讯、百度、58等公司都提供了OCR识别API,转转也有自研的OCR能力,对一张用户上传的图片进行OCR识别可以得到一个文本集合。

["曙李逍遥","伽罗太华","李信一念神度","虞娅云宽雀翎","公孙离析雪灵祝","椅右京枫霜尽","孙尚香音你闪耀","娜可露露前尘镜","百里守约碎云","马可波罗深海之息"]
结合OCR识别结果我们可以发现一些问题
- 图中有10个皮肤,但是用户只拥有5个皮肤,灰色的皮肤是未拥有的,我们不希望将用户未拥有的皮肤也识别出来。
- 对复杂文字支持不是很好,比如把“李信一念神魔”识别为了“李信一念神度”,把“橘右京枫霜尽”识别为了“椅右京枫霜尽”,所以在进行参数匹配时,我们希望有一定容错性。
由此产生了两个要解决的问题
- 只识别拥有的皮肤
- 匹配时有一定容错

4.如何只识别拥有的皮肤
通过观察用户上传的图片我们可以发现:
-
图片可以分为10个皮肤区域以及背景区域,我们只关注皮肤区域,所以需要先想办法将皮肤区域与背景区域分离。
-
划分完皮肤区域后,我们可以对10个区域依次进行判断,区分出这到底是一个未拥有的皮肤区域还是已拥有的皮肤区域。
4.1.划分皮肤区域
如何将皮肤区域和背景区域分离呢?通过观察我们能看到:
- 背景区域的颜色比较单调,大部分大都是蓝色、灰色以及右侧的一些白色丝带。
- 皮肤区域色彩会丰富一些,有各种炫酷的色彩和艺术字。
所以是否能尝试使用色彩数来区分皮肤区域和背景区域呢?
对用户上传图片的色彩数量进行统计,得到以下趋势:
上图为从横向开始遍历,使用Set对纵向所有像素的颜色进行去重,得到的颜色数量变化趋势。可以看出,五个较为明显的凸起即对应了图上的5列皮肤。
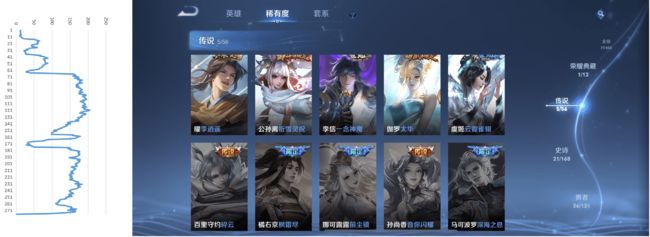
上图为从纵向开始遍历,使用Set对横向所有像素的颜色进行去重,得到的颜色数量变化趋势。可以看出,两个较为明显的凸起即对应了图上的2行皮肤。
因此,如果某个点附近颜色数量发生剧烈变化就可以认为这是一个边界点,相邻两个边界点相连可以组成线段,横向的线段和纵向的线段相连可以组成矩形。按照这个思路对图片进行划分后效果如下。

这样就初步实现了将皮肤区域和背景区域分离
4.2保留拥有的皮肤
对于已拥有的皮肤和未拥有的皮肤,他们的颜色数量都很丰富,继续用颜色数量区分的效果不是很理想,那如何进行区分呢?
-
已拥有的皮肤区域:整体比较鲜艳,所以饱和度高、亮度高的像素占比更高
-
未拥有的皮肤区域:整体比较暗淡,所以饱和度高、亮度高的像素占比低
所以,我们可以在划分矩形后,首先对矩形的长宽比进行初次过滤,然后提取矩形中像素的颜色,计算亮度和饱和度大于阈值的像素占比,保留占比高的矩形。
private static double colorScore(BufferedImage img, Rectangle rect, double brightnessThreshold, double saturationThreshold){
int total = 0;
Set<Integer> set = new HashSet<>();
for (int i = (int) rect.getX(); i < (int) (rect.getX() + rect.getWidth()); i++) {
// 垂直方向截取中间部分,因为上边和下边一般有彩色的文字,影响判断
for (int j = (int) (rect.getY() + rect.getHeight() / 4); j < (int) (rect.getY() + rect.getHeight() * 3 / 4); j++) {
// 获取RGB
int color = img.getRGB(i, j);
int r = (color >> 16) & 0xff;
int g = (color >> 8) & 0xff;
int b = color & 0xff;
// 计算饱和度
double max = Math.max(r, Math.max(g, b));
double min = Math.min(r, Math.min(g, b));
double saturation = 1 - min / max;
// 计算亮度
double brightness = 0.3 * r + 0.6 * g + 0.1 * b;
// 统计大于阈值的像素
if (brightness > brightnessThreshold && saturation > saturationThreshold) {
set.add(color);
}
total++;
}
}
if (total == 0) {
return 0;
}
// 统计大于阈值像素在所有像素的占比
return set.size() / (double) total;
}
在对阈值进行一些调优后,最终保留结果如下。

这样,在进行OCR识别时,就不会把未拥有的皮肤也识别出来了。
5.解决匹配时的容错
要将“李信一念神度”匹配为“李信一念神魔”这个参数,基本思路是计算两个文本的重复度,如果高于一个阈值即可认定是相同的文本,目前文本相似度计算有两种大致方向:
- 基于NLP
提取两个文本的特征向量,计算向量空间两个向量夹角的余弦相似度。
- 基于串匹配
将字符串进行分割,统计子串是否相同。
为了方便我们采用了第二种方法,在串匹配算法中我们选择了Rabin-Karp算法,其具体思路是使用滑动窗口得出文本的哈希集合,对两个哈希集合进行比对,计算出相似度。

例如:我们使用窗口大小为2,每次滑动1对“李信一念神魔”和“李信一念神度”进行分割,可以得到:
[ “李信” , “信一” , “一念” , “念神” , “神魔” ]
[ “李信” , “信一” , “一念” , “念神” , “神度” ]
而对窗口中元素计算哈希的操作我们可以交给String类的hashCode()方法,所以两个文本计算相似度方法大致如下:
public static void main(String[] args) {
// 模拟滑动窗口分割后的结果
List<String> list1 = Arrays.asList(new String[]{"李信", "信一", "一念", "念神", "神魔"});
List<String> list2 = Arrays.asList(new String[]{"李信", "信一", "一念", "念神", "神度"});
// 向HashSet中添加元素时会计算元素的hash
Set<String> baseSet = new HashSet<>(list2);
float count = 0;
for (String word : list1) {
// contains方法也是通过hash判断的
if (baseSet.contains(word)) {
count += 1;
}
}
// 输出0.8
System.out.println(count / list1.size());
}
在上述过程中,向HashSet中增加元素,以及使用contains方法判断HashSet中是否包含元素时,都是基于String类自带的hashCode()方法进行的:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
由于我们的文本量比较小,对于这种哈希计算方式,是完全满足我们的需求的。
而Rabin-Karp算法认为,在文本量非常大的情况下,先分割窗口然后每次对窗口中的元素单独计算哈希效率是低下的,可以通过改良计算方式,使下一个窗口的哈希与
- 上一个窗口的哈希
- 离开窗口的元素
- 进入窗口的元素
产生关联,加快运算速度,所以给出了一种更快分割窗口并且计算哈希的方式:
/**
* 计算文本的哈希集合
*
* @param str 文本
* @param windowLen 滑动窗口大小
* @param moveLen 每次滑动长度
* @return 文本的哈希集合
*/
public static List<Long> hashCode(String str, int windowLen, int moveLen) {
List<Long> hashList = new ArrayList<>();
int temp = 1;
for (int i = 0; i < windowLen; i++) {
temp = (temp * BASE_NUM) % MOD_NUM;
}
long curHash = 0;
for (int i = 0; i < str.length(); i++) {
// 加上进入窗口元素的哈希
curHash = (curHash * BASE_NUM + str.codePointAt(i)) % MOD_NUM;
if (i > windowLen - 1) {
// 减去离开窗口元素的哈希
curHash = curHash - (str.codePointAt(i - windowLen)) * temp % MOD_NUM;
}
if (curHash < 0) {
curHash += MOD_NUM;
}
if ((i + 1) % moveLen == 0 || (i + 1) == str.length()) {
hashList.add(curHash);
}
}
return hashList;
}
如果一个业务场景需要匹配的文本量非常大,可以尝试选用这用方式。
最终,我们的匹配流程大致如下,在系统启动时,会拉取我们的参数库,使用上面的方式对每个参数进行预处理,得到它们的哈希集合,存到本地,当一个OCR识别结果产生时,计算它的哈希集合,与本地进行匹配,如果发现相似度大于阈值,即认为匹配成功。

这样,我们就保证了一定的容错性。
6.效果
当我们解决了:只识别拥有的皮肤、匹配时有一定容错,这两个问题后就可以线上部署了。
目前OCR只应用在王者荣耀、和平精英两款游戏,上线后每日可为我们的商品补充上千参数。后续会逐步扩展到其他游戏品类。

关于作者:
常睿,转转订单业务Java研发工程师
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~