59、【查找】哈希表——拉链法和开放地址寻址法(C/C++版)
一、算法介绍
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
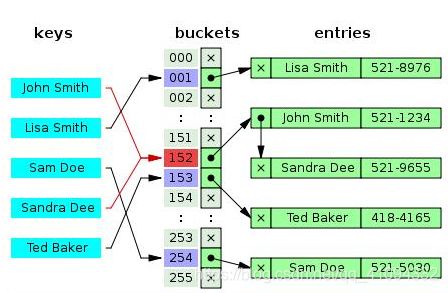
哈希表实现将一个较大的集合映射到一个相对较小的集合内,在一个较大的值域里从中选出一些数插入、查询,删除操作一般不真正的将数据从存储空间中清除,而是做一个标记,意为删除。
1、哈希函数
哈希函数y = F(x) ,一般选用一下四种方式构造:
(1)直接定址法:
H(key) = key 或 H(key) = a × key + b,式中a和b是常数。此方式计算最简单且不会产生冲突,适合关键字的分布基本连续,若分布不连续,则会造成存储空间的大量浪费。
(2)除留余数法:
最简单最常用的方法,假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,同时离2的整次幂尽可能的远,因为这样子取值其冲突概率会最小。
H(key) = key %p
但此时也产生了一个问题,不同的数取模可能会得到一个相同的结果,从而导致值域和定义域不是一对一的关系,而变成了一对多的关系,使其不能通过哈希函数来唯一确定一个值,将这种现象称为冲突。
(3)数字分析法:
设关键字是r进制数,而r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀一些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,此时应选取数码分布较为均匀的若干位作为散列地址。此方法适用于已知的关键字集合,若更换了关键字,则需要重新构造新的哈希函数。
(4)平方取中法
取关键字的平方值的中间几位作为散列地址。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布较为均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。
2、冲突处理
为了解决冲突设计便设计了两种存储结构去解决这个问题,分别为开放寻址法和拉链法。
(1)拉链法
为避免不同关键字会被映射到同一个地址空间中,便将所有同义词存储在同一个线性链表中,这个线性表由其散列地址唯一标识。将非同义词标记在数组中的不同位置,数组中的不同下标对应的元素将会指向不同的同义词线性表的起始地址。

(2)开放寻址法
开放寻址法是将可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。其数学递推式为:
F = (H(key) + d) % m
式中d为增序序列,m为散列表表长。
对于增量序列,分为线性探测法和平方探测法:
[1] 线性探测法: 简单来说,若发生冲突则顺序查看表中下一个单元,当查找到表尾地址时,再从表头地址开始查找。直到找到一个空闲地址或查边全表。当具有较多同义词时,会发生** “聚集”(或堆积) ** 现象,大大降低查找效率。
[2] 平方探索法: 查找跳跃长度为线性整数的平方,即0 、 12 、(-1)2 、 22 、(-2)2 、33 、(-3)2…。该方法可以使表中存的元素相对均匀的分布,避免了堆积现象。
二、题目描述
维护一个集合,支持如下几种操作:
I x,插入一个数 x;
Q x,询问数 x是否在集合中出现过;
现在要进行 N次操作,对于每个询问操作输出对应的结果。
输入格式
第一行包含整数 N,表示操作数量。
接下来 N行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式
对于每个询问指令 Q x,输出一个询问结果,如果 x在集合中出现过,则输出 Yes,否则输出 No。每个结果占一行。
数据范围
1≤N≤105
−109≤x≤109
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
三、题目分析
分别使用拉链法和开放地址寻址法进行实现。
四、算法实现
1、获取质数
在数学中负数取模后为正数,但在C++中负数取模后将会为负数。
例如:
数学:-10 % 3 = 2,
C++:-10 % 3 = -1。
自然数的取模运算的定义是这样的:
如果a和d是两个自然数,d非零,可以证明存在两个唯一的整数 q 和 r,满足 a = qd + r 且0 ≤ r < d。其中,q 被称为商,r 被称为余数,d就是模。
那么对于负数,是否可以沿用这样的定义呢?
假如我们按照正数求余的规则求 (-10) mod 3 的结果,就可以表示 -10 为 (-4)* 3 +2。
因此在程序设计中,可以将-10取绝对值,然后再模,即| -10 | mod 3 = 1,代码上可写为:(n % 3 + 3) % 3。
参考资料:
【科普】-求素数为什么只需要求到平方根就行?
【简洁易懂】为什么判断素数时只需要循环到该数的平方根
假设一个数不为质数,那么可表示为x = a * b,则 a <= 根号x,b >= 根号x,
因此一个不为质数的数,其乘积组成的这个数必为一个比根号x小或等于,一个比根号x大或等于,在寻找质数的过程中只需要在一侧范围内寻找即可,从而对搜索次数进行了优化。
#include <stdio.h>
const int N = 1e5;
int GetPrimNum(int n){
for(int i = n; i > 0; i++){
bool flag = true;
for(int j = 2; j * j <= i; j++){ // 求小于i开根号的数
if(i % j == 0){
flag = false;
}
}
if(flag) return i;
}
return -1;
}
int main(){
int n = GetPrimNum(N);
if(n != -1){
printf("%d", n);
}else
puts("No prim number");
return 0;
}
根据上述代码实现,可得当数据个数为100000时,质数取100003。
2、拉链法
* 实现邻接表前置知识
42、【链表】静态单链表(C/C++版)
#include <stdio.h>
const int N = 1e5 + 3; // 选取的质数为100003
int h[N], e[N], ne[N], idx; // 构建邻接表
void insert(int x){ // 头插法
int k = (x % N + N) % N; // 除留余数法
e[idx] = x; ne[idx] = h[k]; h[k] = idx++;
}
bool query(int k){ // 查找
int n = (k % N + N) % N;
for(int i = h[n]; i != -1; i = ne[i]){
if(e[i] == k)
return true;
}
return false;
}
int main(){
int m; scanf("%d", &m);
// 初始化邻接表
for(int i = 0; i <= N; i++) h[i] = -1;
while(m--){
char op[2]; scanf("%s", op);
int x; scanf("%d", &x);
if(*op == 'I') insert(x);
else{
if(query(x)) puts("Yes");
else puts("No");
}
}
return 0;
}
无注释代码
#include <stdio.h>
const int N = 1e5 + 3;
int h[N], e[N], ne[N], idx;
void insert(int x){
int k = (x % N + N) % N;
e[idx] = x; ne[idx] = h[k]; h[k] = idx++;
}
bool query(int k){
int n = (k % N + N) % N;
for(int i = h[n]; i != -1; i = ne[i]){
if(e[i] == k)
return true;
}
return false;
}
int main(){
int m; scanf("%d", &m);
for(int i = 0; i <= N; i++) h[i] = -1;
while(m--){
char op[2]; scanf("%s", op);
int x; scanf("%d", &x);
if(*op == 'I') insert(x);
else{
if(query(x)) puts("Yes");
else puts("No");
}
}
return 0;
}
3、开放寻址法
一般开数组范围是给定数据个数的2-3倍,
#include <stdio.h>
const int N = 2*1e5 + 3, NU = 0x3f3f3f3f; // N为指数,NU为NULL标记
int h[N]; // 数组存储
int find(int x){
int t = (x % N + N) % N;
while(h[t] != NU && h[t] != x){ // 当所找的当前位置不为NULL并且也不是x时,继续向后查找
t = t + 1 % N; // 查到N时,再重头开始查
}
return t; // 返回的t为空位置的下标或目标元素的下标
}
int main(){
int m; scanf("%d", &m);
for(int i = 0; i <= N; i++) h[i] = NU;
while(m--){
char op[2]; scanf("%s", op);
int x; scanf("%d", &x);
if(*op == 'I') h[find(x)] = x; //将x赋值给h中的空位置下标
else{
if(h[find(x)] == x) puts("Yes"); // 若该下标对应的数为x,则查找成功
else puts("No"); // 若为NU说明不存在该数
}
}
return 0;
}
无注释代码
#include <stdio.h>
const int N = 2 * 1e5 + 3, NU = 0x3f3f3f3f;
int h[N];
int find(int x){
int u = (x % N + N) % N;
while(h[u] != NU && h[u] != x){
u = u + 1 % N;
}
return u;
}
int main(){
int m; scanf("%d", &m);
for(int i = 0; i <= N; i++) h[i] = NU;
while(m--){
char op[2]; scanf("%s", op);
int x; scanf("%d", &x);
if(*op == 'I') h[find(x)] = x;
else{
if(h[find(x)] == x) puts("Yes");
else puts("No");
}
}
return 0;
}