C语言实现简单哈希表
什么是哈希表
哈希表,也叫散列表,是根据关键码值而直接进行访问的数据结构。通俗点说,就是通过关键值(key)映射到表中的某个位置,以便可以直接访问该节点,以提高查找速度。这个映射函数就是散列函数。
举个例子,我们有很多员工的信息需要存储,比如张三,李四,王五;一般来说我们可以用链表将他们的信息存储起来,当我们需要某个员工的信息时,遍历链表查找出其信息即可。这样的弊端可想而知:查找效率太低。而如果我们有个函数f(x),能将张三,李四,王五分别映射成1,2,3。那我们可以直接将张三,李四,王五的信息分别存储在链表的1,2,3个节点。需要查找某个员工信息时,根据其映射值,直接查找链表对应位置即可,这样便大大提高了查找效率。事实上,我们将f(x)成为散列函数,存放映射记录的结构,就叫散列表(哈希表)。
哈希表的性能
由于哈希表高效的特性,查找或者插入的情况在大多数情况下可以达到O(1),时间主要花在计算hash值上。最糟糕的情况是所有的key都被映射为同一个地址,此时哈希表退化成链表,时间复杂度变为O(n)。但这种情况几乎不会发生。实际上,哈希表是以空间换时间。哈希表会消耗更多的内存,以换取更快的查找效率。
哈希表实现
第一步,构造哈希表。链表结点至少需要三个成员,关键值key,指向key对应数据的结构指针value(最简单就是char *,也可以是结构体指针),链表结点指针next。我会习惯多加一个free_value,它是一个函数指针,作用是free掉value指针指向的内存。如下:
struct kv
{
char *key;
void *value;
void (*free_value)(void *);
struct kv *next;
};
哈希表创建函数如下(hashTable *就是哈希表指针,下同):
hashTable *hash_table_create()
{
hashTable *p = (hashTable *)malloc(sizeof(hashTable));
if (NULL == p)
{
return NULL;
}
p->table = (struct kv **)malloc(MAX_TABLE_SIZE * sizeof(struct kv *));
if (NULL == p->table)
{
free(p);
return NULL;
}
memset(p->table, 0, MAX_TABLE_SIZE * sizeof(struct kv *));
return p;
}
第二步,哈希函数,关于哈希函数我不太了解,因此不做过多阐述,有兴趣的可自行查找资料。总之,它的作用就是将不同key映射成不同的hash值。
static unsigned int hash_33(char* key)
{
unsigned int hash = 0;
while (*key)
{
hash = (hash << 5) + hash + *key++;
}
return hash;
}
第三步,插入函数
int hash_table_put(hashTable *htable, char *key, void *value, void (*free_value)(void *))
{
int i = hash_33(key) % MAX_TABLE_SIZE; // 计算hash值
struct kv *p = htable->table[i];
struct kv *prev = p;
while (p != NULL) // 不同key有可能是同一个hash值,所以需要遍历该节点指向的链表
{
if (0 == strcmp(p->key, key)) // 已存在此节点,删除原来信息,再指向新信息
{
if (p->free_value != NULL)
{
p->free_value(p->value);
}
p->value = value;
p->free_value = free_value;
break;
}
else
{
prev = p;
p = p->next;
}
}
if (NULL == p) // 此key无对应节点,新增一个
{
char *kstr = (char *)malloc(strlen(key) + 1);
if (NULL == kstr)
{
return 1;
}
struct kv *tmp = (struct kv *)malloc(sizeof(struct kv));
if (NULL == tmp)
{
free(kstr);
return 2;
}
strcpy(kstr, key);
tmp->key = kstr;
tmp->value = value;
tmp->free_value = free_value;
tmp->next = NULL;
if (NULL == prev)
{
htable->table[i] = tmp;
}
else
{
prev->next = tmp;
}
}
return 0;
}
第四步,查找函数。根据key计算出hash值,直接查找对应位置即可。如果该位置下有多个节点,需要遍历。
void *hash_table_get(hashTable *htable, char *key)
{
int i = hash_33(key) % MAX_TABLE_SIZE; // 计算hash值
struct kv *p = htable->table[i];
while (p != NULL) // 遍历i位置下的所有节点
{
if (0 == strcmp(p->key, key)) // 找到,返回value
{
return p->value;
}
p = p->next;
}
return NULL;
}
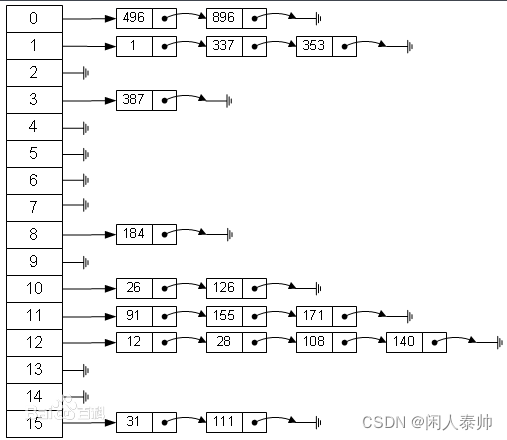
最后创建的哈希表结构如图
下面是个简单的应用例子
typedef struct gnode
{
char size;
int age;
char name[8];
}gnode_t;
void free_gnode(void *gt)
{
if (gt != NULL)
{
free(gt);
}
}
void show_g_info(gnode_t *gt)
{
if (gt != NULL)
{
printf("name : %s, age : %d, size : %c \n\n", gt->name, gt->age, gt->size);
}
}
int main(void)
{
// 创建哈希表
hashTable *tableHead = hash_table_create();
if (NULL == tableHead)
{
return -1;
}
int i = 0;
for (i=1; i<21; i++) // 循环插入20个信息
{
gnode_t *g = (gnode_t *)malloc(sizeof(gnode_t));
if (g != NULL)
{
g->size = 'a' + i % 6;
g->age = 18 + i % 8;
sprintf(g->name, "user%02d", i);
hash_table_put(tableHead, g->name, g, free_gnode);
}
}
// 获取user10 信息
gnode_t *t = (gnode_t *)hash_table_get(tableHead, "user10");
show_g_info(t);
// 获取user20 信息
t = (gnode_t *)hash_table_get(tableHead, "user20");
show_g_info(t);
hash_table_restory(tableHead);
return 0;
}
执行结果如下
@server:~/work/testProj/hash$ ./main
name : user10, age : 20, size : e
name : user20, age : 22, size : c
@server:~/work/testProj/hash$
最后附上 hashtable.c 下载链接 hashtable.c