mmdet-tools工具测试
Log Analysis
analyze_logs.py
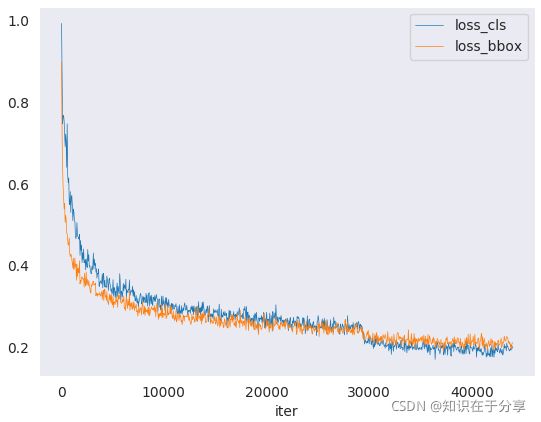
python analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
python analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --legend loss_cls loss_bbox
python analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
python analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --legend loss_cls loss_bbox --out losses.pdf
python analyze_logs.py plot_curve log.json log2.json --keys loss_bbox --legend run1 run2
python analyze_logs.py plot_curve log.json log2.json --keys loss_cls --legend run1 run2
python analyze_logs.py plot_curve log.json log2.json --keys bbox_mAP --legend run1 run2
python analyze_logs.py cal_train_time log.json
-----Analyze train time of log.json-----
slowest epoch 19, average time is 0.3012
fastest epoch 14, average time is 0.2760
time std over epochs is 0.0058
average iter time: 0.2905 s/iterpython analyze_logs.py cal_train_time log.json --include-outliers
-----Analyze train time of log.json-----
slowest epoch 19, average time is 0.3046
fastest epoch 14, average time is 0.2790
time std over epochs is 0.0060
average iter time: 0.2938 s/iter

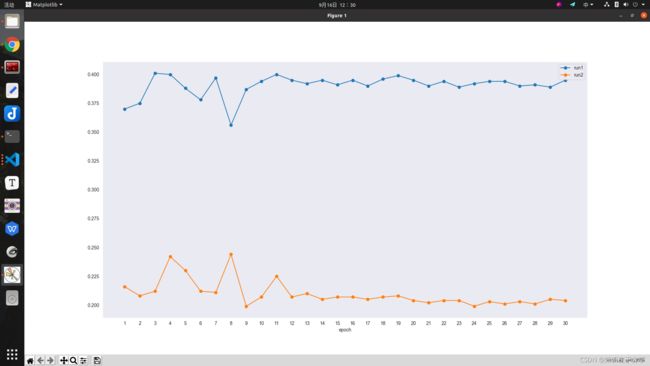
log.json的数据格式如下
第一行是模型信息,如果我们自己制作的时候,这个可不要,主要保存信息的json格式如下
{"env_info": "sys.platform: linux\nPython: 3.7.10 (default, Jun 4 2021, 14:48:32) [GCC 7.5.0]\nCUDA available: True\nGPU 0,1: Tesla V100-SXM2-32GB\nCUDA_HOME: /usr/local/cuda\nNVCC: Cuda compilation tools, release 10.1, V10.1.168\nGCC: gcc (Ubuntu 8.4.0-1ubuntu1~16.04.1) 8.4.0\nPyTorch: 1.6.0+cu101\nPyTorch compiling details: PyTorch built with:\n - GCC 7.3\n - C++ Version: 201402\n - Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications\n - Intel(R) MKL-DNN v1.5.0 (Git Hash e2ac1fac44c5078ca927cb9b90e1b3066a0b2ed0)\n - OpenMP 201511 (a.k.a. OpenMP 4.5)\n - NNPACK is enabled\n - CPU capability usage: AVX2\n - CUDA Runtime 10.1\n - NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75\n - CuDNN 7.6.3\n - Magma 2.5.2\n - Build settings: BLAS=MKL, BUILD_TYPE=Release, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN_WRAPPER -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, USE_CUDA=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_STATIC_DISPATCH=OFF, \n\nTorchVision: 0.7.0+cu101\nOpenCV: 4.5.2\nMMCV: 1.2.4\nMMCV Compiler: GCC 7.3\nMMCV CUDA Compiler: 10.1\nMMDetection: 2.8.0+HEAD", "config": "model = dict(\n type='FasterRCNN',\n pretrained='torchvision://resnet50',\n backbone=dict(\n type='ResNet',\n depth=50,\n num_stages=4,\n out_indices=(0, 1, 2, 3),\n frozen_stages=1,\n norm_cfg=dict(type='BN', requires_grad=True),\n norm_eval=True,\n style='pytorch'),\n neck=dict(\n type='FPN',\n in_channels=[256, 512, 1024, 2048],\n out_channels=256,\n num_outs=5),\n rpn_head=dict(\n type='RPNHead',\n in_channels=256,\n feat_channels=256,\n anchor_generator=dict(\n type='AnchorGenerator',\n scales=[8],\n ratios=[0.5, 1.0, 2.0],\n strides=[4, 8, 16, 32, 64]),\n bbox_coder=dict(\n type='DeltaXYWHBBoxCoder',\n target_means=[0.0, 0.0, 0.0, 0.0],\n target_stds=[1.0, 1.0, 1.0, 1.0]),\n loss_cls=dict(\n type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),\n loss_bbox=dict(type='SmoothL1Loss', loss_weight=1.0)),\n roi_head=dict(\n type='StandardRoIHead',\n bbox_roi_extractor=dict(\n type='SingleRoIExtractor',\n roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),\n out_channels=256,\n featmap_strides=[4, 8, 16, 32]),\n bbox_head=dict(\n type='Shared2FCBBoxHead',\n in_channels=256,\n fc_out_channels=1024,\n roi_feat_size=7,\n num_classes=1,\n bbox_coder=dict(\n type='DeltaXYWHBBoxCoder',\n target_means=[0.0, 0.0, 0.0, 0.0],\n target_stds=[0.1, 0.1, 0.2, 0.2]),\n reg_class_agnostic=False,\n loss_cls=dict(\n type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),\n loss_bbox=dict(type='SmoothL1Loss', loss_weight=1.0))))\ntrain_cfg = dict(\n rpn=dict(\n assigner=dict(\n type='MaxIoUAssigner',\n pos_iou_thr=0.7,\n neg_iou_thr=0.3,\n min_pos_iou=0.3,\n match_low_quality=True,\n ignore_iof_thr=-1),\n sampler=dict(\n type='RandomSampler',\n num=256,\n pos_fraction=0.5,\n neg_pos_ub=-1,\n add_gt_as_proposals=False),\n allowed_border=-1,\n pos_weight=-1,\n debug=False),\n rpn_proposal=dict(\n nms_across_levels=False,\n nms_pre=2000,\n nms_post=1000,\n max_num=1000,\n nms_thr=0.7,\n min_bbox_size=0),\n rcnn=dict(\n assigner=dict(\n type='MaxIoUAssigner',\n pos_iou_thr=0.5,\n neg_iou_thr=0.5,\n min_pos_iou=0.5,\n match_low_quality=False,\n ignore_iof_thr=-1),\n sampler=dict(\n type='RandomSampler',\n num=512,\n pos_fraction=0.25,\n neg_pos_ub=-1,\n add_gt_as_proposals=True),\n pos_weight=-1,\n debug=False))\ntest_cfg = dict(\n rpn=dict(\n nms_across_levels=False,\n nms_pre=1000,\n nms_post=1000,\n max_num=1000,\n nms_thr=0.7,\n min_bbox_size=0),\n rcnn=dict(\n score_thr=0.05,\n nms=dict(type='nms', iou_threshold=0.5),\n max_per_img=100))\ndataset_type = 'CocoDataset'\ndata_root = 'data/coco/'\nimg_norm_cfg = dict(\n mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)\ntrain_pipeline = [\n dict(type='LoadImageFromFile'),\n dict(type='LoadAnnotations', with_bbox=True),\n dict(type='Resize', img_scale=(2000, 1500), keep_ratio=True),\n dict(type='RandomFlip', flip_ratio=0.5),\n dict(\n type='Normalize',\n mean=[123.675, 116.28, 103.53],\n std=[58.395, 57.12, 57.375],\n to_rgb=True),\n dict(type='Pad', size_divisor=32),\n dict(type='DefaultFormatBundle'),\n dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])\n]\ntest_pipeline = [\n dict(type='LoadImageFromFile'),\n dict(\n type='MultiScaleFlipAug',\n img_scale=(1800, 1000),\n flip=False,\n transforms=[\n dict(type='Resize', keep_ratio=True),\n dict(type='RandomFlip'),\n dict(\n type='Normalize',\n mean=[123.675, 116.28, 103.53],\n std=[58.395, 57.12, 57.375],\n to_rgb=True),\n dict(type='Pad', size_divisor=32),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n ])\n]\ndata = dict(\n samples_per_gpu=2,\n workers_per_gpu=2,\n train=dict(\n type='CocoDataset',\n ann_file='data/coco/train_v5.json',\n img_prefix='data/coco/save_pic/',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(type='LoadAnnotations', with_bbox=True),\n dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),\n dict(type='RandomFlip', flip_ratio=0.5),\n dict(\n type='Normalize',\n mean=[123.675, 116.28, 103.53],\n std=[58.395, 57.12, 57.375],\n to_rgb=True),\n dict(type='Pad', size_divisor=32),\n dict(type='DefaultFormatBundle'),\n dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])\n ]),\n val=dict(\n type='CocoDataset',\n ann_file='data/coco/test_v5.json',\n img_prefix='data/coco/save_pic/',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(\n type='MultiScaleFlipAug',\n img_scale=(1800, 1000),\n flip=False,\n transforms=[\n dict(type='Resize', keep_ratio=True),\n dict(type='RandomFlip'),\n dict(\n type='Normalize',\n mean=[123.675, 116.28, 103.53],\n std=[58.395, 57.12, 57.375],\n to_rgb=True),\n dict(type='Pad', size_divisor=32),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n ])\n ]),\n test=dict(\n type='CocoDataset',\n ann_file='data/coco/test_v5.json',\n img_prefix='data/coco/save_pic/',\n pipeline=[\n dict(type='LoadImageFromFile'),\n dict(\n type='MultiScaleFlipAug',\n img_scale=(1800, 1000),\n flip=False,\n transforms=[\n dict(type='Resize', keep_ratio=True),\n dict(type='RandomFlip'),\n dict(\n type='Normalize',\n mean=[123.675, 116.28, 103.53],\n std=[58.395, 57.12, 57.375],\n to_rgb=True),\n dict(type='Pad', size_divisor=32),\n dict(type='ImageToTensor', keys=['img']),\n dict(type='Collect', keys=['img'])\n ])\n ]))\nevaluation = dict(interval=1, metric='bbox')\noptimizer = dict(type='SGD', lr=0.002, momentum=0.9, weight_decay=0.0001)\noptimizer_config = dict(grad_clip=None)\nlr_config = dict(\n policy='step',\n warmup='linear',\n warmup_iters=500,\n warmup_ratio=0.3333333333333333,\n step=[8, 11])\ntotal_epochs = 30\ncheckpoint_config = dict(interval=1)\nlog_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])\ndist_params = dict(backend='nccl')\nlog_level = 'INFO'\nload_from = '/home/ninghua/hanzhexin/mmdetection-2.8.0/work_dirs/zhexin_bigpic_config/epoch_30.pth'\nresume_from = None\nworkflow = [('train', 1)]\nwork_dir = './work_dirs/zhexin_bigpic_train_config'\ngpu_ids = range(0, 2)\n", "seed": null, "exp_name": "zhexin_bigpic_train_config.py"}
{"mode": "train", "epoch": 1, "iter": 50, "lr": 0.0008, "memory": 3826, "data_time": 0.35869, "loss_rpn_cls": 0.00235, "loss_rpn_bbox": 0.0012, "loss_cls": 0.08144, "acc": 96.35938, "loss_bbox": 0.05092, "loss": 0.13591, "time": 0.6985}
{"mode": "train", "epoch": 1, "iter": 100, "lr": 0.00093, "memory": 3826, "data_time": 0.04285, "loss_rpn_cls": 0.00259, "loss_rpn_bbox": 0.00135, "loss_cls": 0.08863, "acc": 96.12109, "loss_bbox": 0.05383, "loss": 0.14639, "time": 0.34858}
{"mode": "train", "epoch": 1, "iter": 150, "lr": 0.00106, "memory": 3826, "data_time": 0.01855, "loss_rpn_cls": 0.00212, "loss_rpn_bbox": 0.00122, "loss_cls": 0.08046, "acc": 96.39355, "loss_bbox": 0.05043, "loss": 0.13423, "time": 0.30862}
{"mode": "train", "epoch": 1, "iter": 200, "lr": 0.0012, "memory": 3826, "data_time": 0.02169, "loss_rpn_cls": 0.00229, "loss_rpn_bbox": 0.00101, "loss_cls": 0.07634, "acc": 96.56934, "loss_bbox": 0.04471, "loss": 0.12435, "time": 0.31049}
{"mode": "train", "epoch": 1, "iter": 250, "lr": 0.00133, "memory": 3826, "data_time": 0.01755, "loss_rpn_cls": 0.00234, "loss_rpn_bbox": 0.00127, "loss_cls": 0.07967, "acc": 96.4707, "loss_bbox": 0.05072, "loss": 0.134, "time": 0.29072}
{"mode": "train", "epoch": 1, "iter": 300, "lr": 0.00146, "memory": 3826, "data_time": 0.01774, "loss_rpn_cls": 0.00186, "loss_rpn_bbox": 0.00128, "loss_cls": 0.08555, "acc": 96.09668, "loss_bbox": 0.05363, "loss": 0.14233, "time": 0.35023}
{"mode": "train", "epoch": 1, "iter": 350, "lr": 0.0016, "memory": 3826, "data_time": 0.01824, "loss_rpn_cls": 0.00277, "loss_rpn_bbox": 0.00135, "loss_cls": 0.08343, "acc": 96.35742, "loss_bbox": 0.05326, "loss": 0.14082, "time": 0.32053}
{"mode": "train", "epoch": 1, "iter": 400, "lr": 0.00173, "memory": 3826, "data_time": 0.01862, "loss_rpn_cls": 0.00263, "loss_rpn_bbox": 0.00123, "loss_cls": 0.08313, "acc": 96.38184, "loss_bbox": 0.05332, "loss": 0.14031, "time": 0.32231}
{"mode": "train", "epoch": 1, "iter": 450, "lr": 0.00186, "memory": 3826, "data_time": 0.01823, "loss_rpn_cls": 0.00236, "loss_rpn_bbox": 0.00136, "loss_cls": 0.08246, "acc": 96.33301, "loss_bbox": 0.05589, "loss": 0.14206, "time": 0.33274}
{"mode": "train", "epoch": 1, "iter": 500, "lr": 0.002, "memory": 3826, "data_time": 0.0185, "loss_rpn_cls": 0.00328, "loss_rpn_bbox": 0.00127, "loss_cls": 0.0796, "acc": 96.41406, "loss_bbox": 0.05293, "loss": 0.13708, "time": 0.31506}
{"mode": "train", "epoch": 1, "iter": 550, "lr": 0.002, "memory": 3826, "data_time": 0.0223, "loss_rpn_cls": 0.00307, "loss_rpn_bbox": 0.00142, "loss_cls": 0.08207, "acc": 96.31934, "loss_bbox": 0.05239, "loss": 0.13895, "time": 0.33209}
{"mode": "train", "epoch": 1, "iter": 600, "lr": 0.002, "memory": 3826, "data_time": 0.01679, "loss_rpn_cls": 0.00237, "loss_rpn_bbox": 0.00156, "loss_cls": 0.08317, "acc": 96.29004, "loss_bbox": 0.05274, "loss": 0.13985, "time": 0.30244}
{"mode": "train", "epoch": 1, "iter": 650, "lr": 0.002, "memory": 3826, "data_time": 0.01964, "loss_rpn_cls": 0.00366, "loss_rpn_bbox": 0.00112, "loss_cls": 0.08293, "acc": 96.27246, "loss_bbox": 0.04925, "loss": 0.13697, "time": 0.31234}
{"mode": "train", "epoch": 1, "iter": 700, "lr": 0.002, "memory": 3826, "data_time": 0.01933, "loss_rpn_cls": 0.00261, "loss_rpn_bbox": 0.0015, "loss_cls": 0.08491, "acc": 96.17773, "loss_bbox": 0.05666, "loss": 0.14568, "time": 0.33414}
{"mode": "train", "epoch": 1, "iter": 750, "lr": 0.002, "memory": 3826, "data_time": 0.02078, "loss_rpn_cls": 0.00226, "loss_rpn_bbox": 0.00143, "loss_cls": 0.08713, "acc": 96.10059, "loss_bbox": 0.05606, "loss": 0.14688, "time": 0.32215}
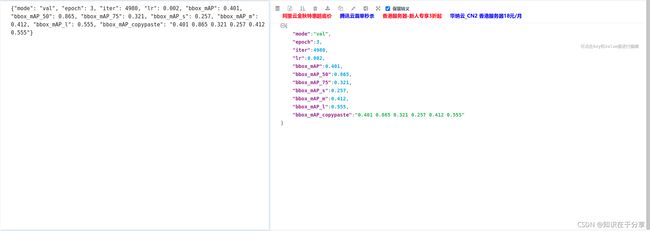
{"mode": "val", "epoch": 3, "iter": 4980, "lr": 0.002, "bbox_mAP": 0.401, "bbox_mAP_50": 0.865, "bbox_mAP_75": 0.321, "bbox_mAP_s": 0.257, "bbox_mAP_m": 0.412, "bbox_mAP_l": 0.555, "bbox_mAP_copypaste": "0.401 0.865 0.321 0.257 0.412 0.555"}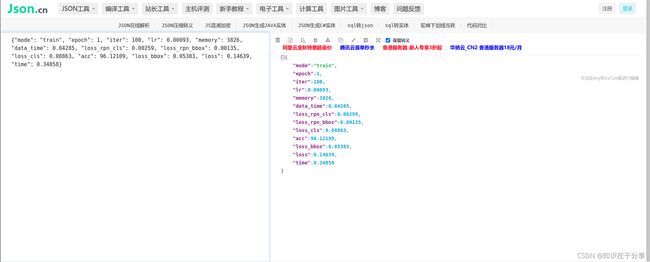
代码:
import argparse
import json
from collections import defaultdict
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
def cal_train_time(log_dicts, args):
for i, log_dict in enumerate(log_dicts):
print(f'{"-" * 5}Analyze train time of {args.json_logs[i]}{"-" * 5}')
all_times = []
for epoch in log_dict.keys():
if args.include_outliers:
all_times.append(log_dict[epoch]['time'])
else:
all_times.append(log_dict[epoch]['time'][1:])
all_times = np.array(all_times)
epoch_ave_time = all_times.mean(-1)
slowest_epoch = epoch_ave_time.argmax()
fastest_epoch = epoch_ave_time.argmin()
std_over_epoch = epoch_ave_time.std()
print(f'slowest epoch {slowest_epoch + 1}, '
f'average time is {epoch_ave_time[slowest_epoch]:.4f}')
print(f'fastest epoch {fastest_epoch + 1}, '
f'average time is {epoch_ave_time[fastest_epoch]:.4f}')
print(f'time std over epochs is {std_over_epoch:.4f}')
print(f'average iter time: {np.mean(all_times):.4f} s/iter')
print()
def plot_curve(log_dicts, args):
if args.backend is not None:
plt.switch_backend(args.backend)
sns.set_style(args.style)
# if legend is None, use {filename}_{key} as legend
legend = args.legend
if legend is None:
legend = []
for json_log in args.json_logs:
for metric in args.keys:
legend.append(f'{json_log}_{metric}')
assert len(legend) == (len(args.json_logs) * len(args.keys))
metrics = args.keys
num_metrics = len(metrics)
for i, log_dict in enumerate(log_dicts):
epochs = list(log_dict.keys())
for j, metric in enumerate(metrics):
print(f'plot curve of {args.json_logs[i]}, metric is {metric}')
if metric not in log_dict[epochs[0]]:
raise KeyError(
f'{args.json_logs[i]} does not contain metric {metric}')
if 'mAP' in metric:
xs = np.arange(1, max(epochs) + 1)
ys = []
for epoch in epochs:
ys += log_dict[epoch][metric]
ax = plt.gca()
ax.set_xticks(xs)
plt.xlabel('epoch')
plt.plot(xs, ys, label=legend[i * num_metrics + j], marker='o')
else:
xs = []
ys = []
num_iters_per_epoch = log_dict[epochs[0]]['iter'][-1]
for epoch in epochs:
iters = log_dict[epoch]['iter']
if log_dict[epoch]['mode'][-1] == 'val':
iters = iters[:-1]
xs.append(
np.array(iters) + (epoch - 1) * num_iters_per_epoch)
ys.append(np.array(log_dict[epoch][metric][:len(iters)]))
xs = np.concatenate(xs)
ys = np.concatenate(ys)
plt.xlabel('iter')
plt.plot(
xs, ys, label=legend[i * num_metrics + j], linewidth=0.5)
plt.legend()
if args.title is not None:
plt.title(args.title)
if args.out is None:
plt.show()
else:
print(f'save curve to: {args.out}')
plt.savefig(args.out)
plt.cla()
def add_plot_parser(subparsers):
parser_plt = subparsers.add_parser(
'plot_curve', help='parser for plotting curves')
parser_plt.add_argument(
'json_logs',
type=str,
nargs='+',
help='path of train log in json format')
parser_plt.add_argument(
'--keys',
type=str,
nargs='+',
default=['bbox_mAP'],
help='the metric that you want to plot')
parser_plt.add_argument('--title', type=str, help='title of figure')
parser_plt.add_argument(
'--legend',
type=str,
nargs='+',
default=None,
help='legend of each plot')
parser_plt.add_argument(
'--backend', type=str, default=None, help='backend of plt')
parser_plt.add_argument(
'--style', type=str, default='dark', help='style of plt')
parser_plt.add_argument('--out', type=str, default=None)
def add_time_parser(subparsers):
parser_time = subparsers.add_parser(
'cal_train_time',
help='parser for computing the average time per training iteration')
parser_time.add_argument(
'json_logs',
type=str,
nargs='+',
help='path of train log in json format')
parser_time.add_argument(
'--include-outliers',
action='store_true',
help='include the first value of every epoch when computing '
'the average time')
def parse_args():
parser = argparse.ArgumentParser(description='Analyze Json Log')
# currently only support plot curve and calculate average train time
subparsers = parser.add_subparsers(dest='task', help='task parser')
add_plot_parser(subparsers)
add_time_parser(subparsers)
args = parser.parse_args()
return args
def load_json_logs(json_logs):
# load and convert json_logs to log_dict, key is epoch, value is a sub dict
# keys of sub dict is different metrics, e.g. memory, bbox_mAP
# value of sub dict is a list of corresponding values of all iterations
log_dicts = [dict() for _ in json_logs]
for json_log, log_dict in zip(json_logs, log_dicts):
with open(json_log, 'r') as log_file:
for line in log_file:
log = json.loads(line.strip())
# skip lines without `epoch` field
if 'epoch' not in log:
continue
epoch = log.pop('epoch')
if epoch not in log_dict:
log_dict[epoch] = defaultdict(list)
for k, v in log.items():
log_dict[epoch][k].append(v)
return log_dicts
def main():
args = parse_args()
json_logs = args.json_logs
for json_log in json_logs:
assert json_log.endswith('.json')
log_dicts = load_json_logs(json_logs)
eval(args.task)(log_dicts, args)
if __name__ == '__main__':
main()
Error Analysis
参考:
MMDetection v2 目标检测(4):模型训练和测试 - 简书
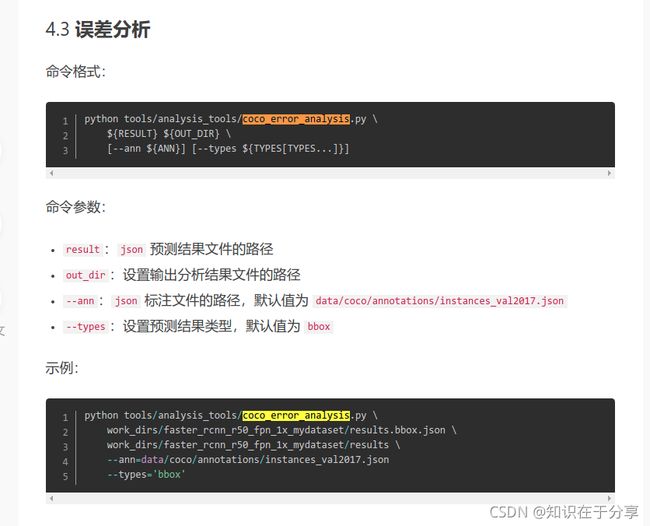
如果想把代码保存成coco_result.json的形式
需要写一个inference,保存形式参卡:
使用COCO API评估模型在COCO数据集上的结果 - 知乎
用于COCO API测试的结果的文件格式 - 知乎
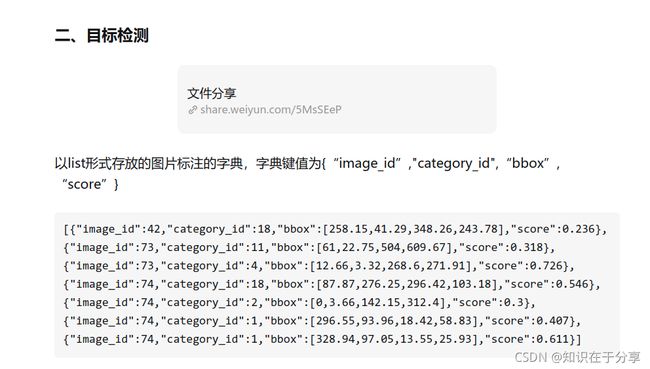
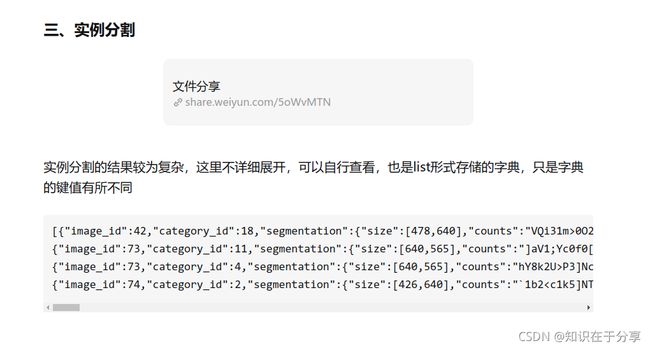
通过mmdet命令就可以获得这个json
./tools/dist_test.sh faster_rcnn_r50_fpn_1x_coco_ynh.py checkpoints.pth 1 --format-only
--eval-options "jsonfile_prefix=./faster-rcnn_test-dev_results"得到
faster-rcnn_test-dev_results.bbox.json
就可以运行了,记得跑代码把原代码中的多进程48改为小一点,不然机器抗不住
with Pool(processes=8) as pool:
args = [(k, cocoDt, cocoGt, catId, iou_type)
for k, catId in enumerate(catIds)]
analyze_results = pool.starmap(analyze_individual_category, args)bbox-person-allarea.png
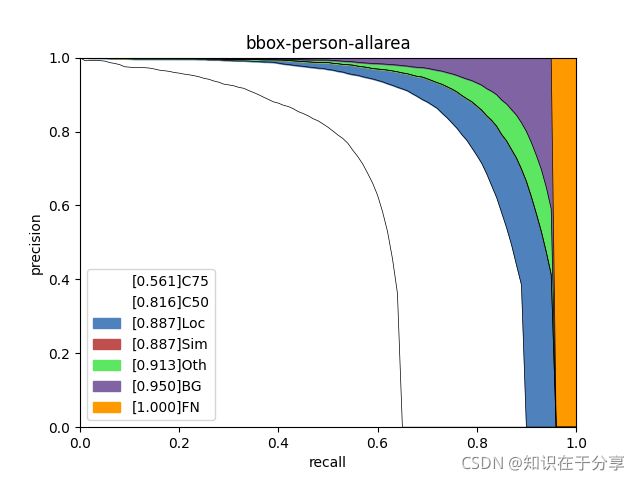
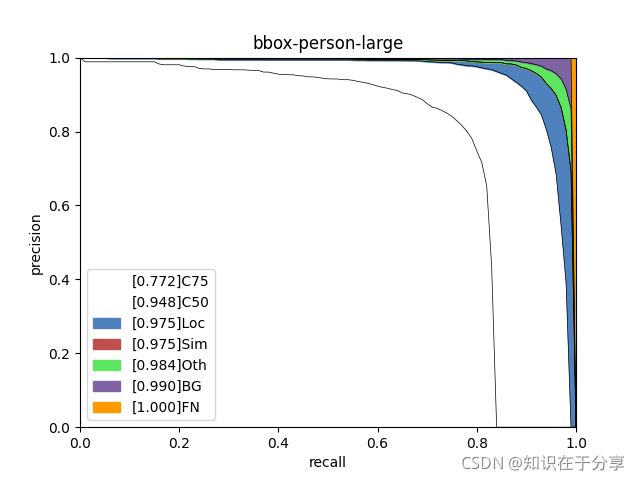
bbox-person-large.png
bbox-person-medium.png
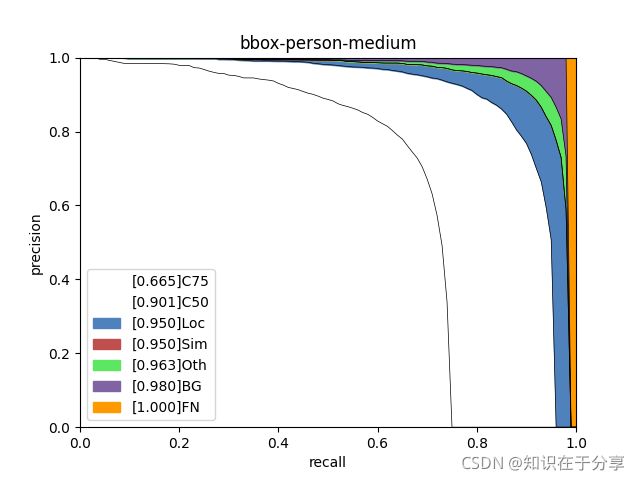
bbox-person-small.png
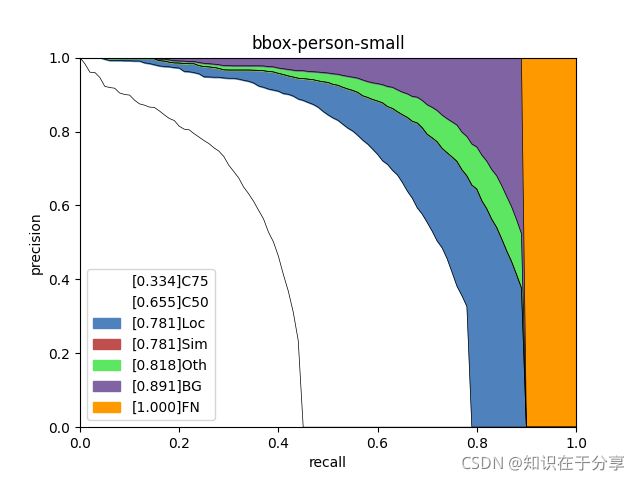
bbox-airplane-allarea.png

bbox-airplane-large.png
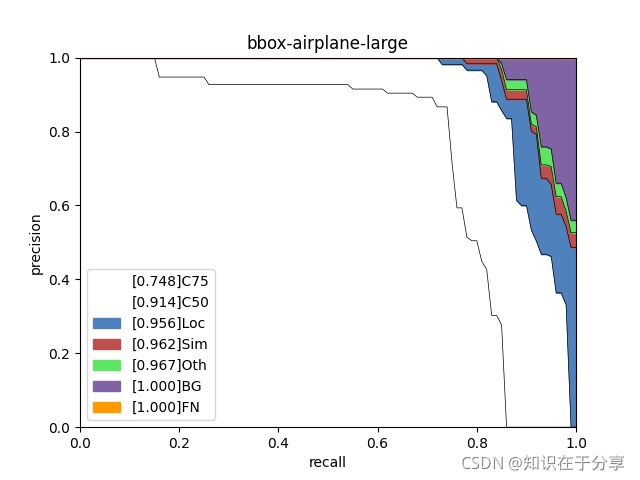
bbox-airplane-medium.png
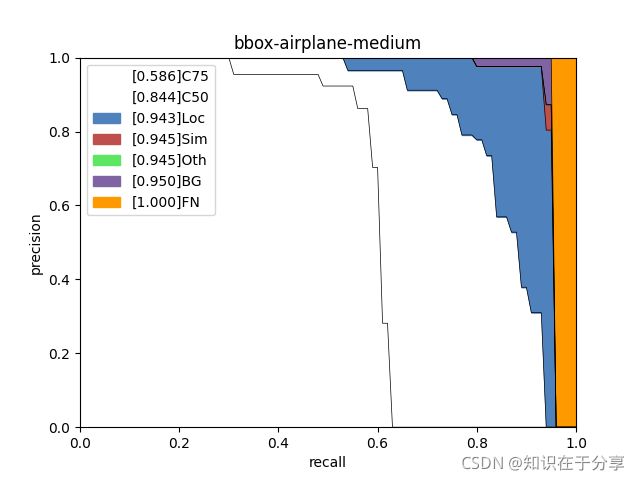
bbox-airplane-small.png
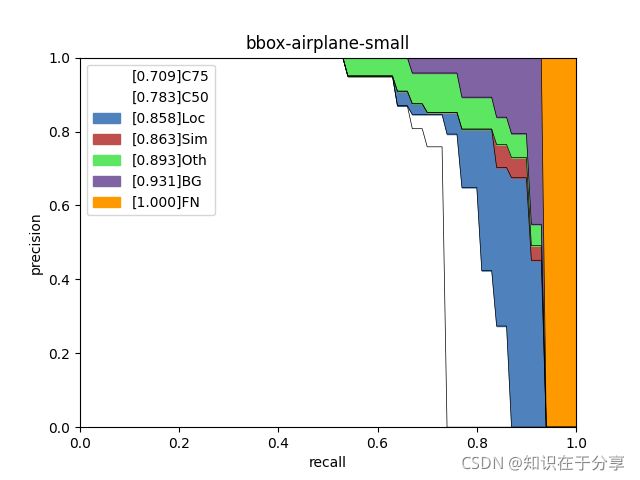
coco_error_analysis.py
analyzes COCO results per category and by different criterion. It can also make a plot to provide useful information.
代码:
import copy
import os
from argparse import ArgumentParser
from multiprocessing import Pool
import matplotlib.pyplot as plt
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
def makeplot(rs, ps, outDir, class_name, iou_type):
cs = np.vstack([
np.ones((2, 3)),
np.array([.31, .51, .74]),
np.array([.75, .31, .30]),
np.array([.36, .90, .38]),
np.array([.50, .39, .64]),
np.array([1, .6, 0])
])
areaNames = ['allarea', 'small', 'medium', 'large']
types = ['C75', 'C50', 'Loc', 'Sim', 'Oth', 'BG', 'FN']
for i in range(len(areaNames)):
area_ps = ps[..., i, 0]
figure_tile = iou_type + '-' + class_name + '-' + areaNames[i]
aps = [ps_.mean() for ps_ in area_ps]
ps_curve = [
ps_.mean(axis=1) if ps_.ndim > 1 else ps_ for ps_ in area_ps
]
ps_curve.insert(0, np.zeros(ps_curve[0].shape))
fig = plt.figure()
ax = plt.subplot(111)
for k in range(len(types)):
ax.plot(rs, ps_curve[k + 1], color=[0, 0, 0], linewidth=0.5)
ax.fill_between(
rs,
ps_curve[k],
ps_curve[k + 1],
color=cs[k],
label=str(f'[{aps[k]:.3f}]' + types[k]))
plt.xlabel('recall')
plt.ylabel('precision')
plt.xlim(0, 1.)
plt.ylim(0, 1.)
plt.title(figure_tile)
plt.legend()
# plt.show()
fig.savefig(outDir + f'/{figure_tile}.png')
plt.close(fig)
def analyze_individual_category(k, cocoDt, cocoGt, catId, iou_type):
nm = cocoGt.loadCats(catId)[0]
print(f'--------------analyzing {k + 1}-{nm["name"]}---------------')
ps_ = {}
dt = copy.deepcopy(cocoDt)
nm = cocoGt.loadCats(catId)[0]
imgIds = cocoGt.getImgIds()
dt_anns = dt.dataset['annotations']
select_dt_anns = []
for ann in dt_anns:
if ann['category_id'] == catId:
select_dt_anns.append(ann)
dt.dataset['annotations'] = select_dt_anns
dt.createIndex()
# compute precision but ignore superclass confusion
gt = copy.deepcopy(cocoGt)
child_catIds = gt.getCatIds(supNms=[nm['supercategory']])
for idx, ann in enumerate(gt.dataset['annotations']):
if (ann['category_id'] in child_catIds
and ann['category_id'] != catId):
gt.dataset['annotations'][idx]['ignore'] = 1
gt.dataset['annotations'][idx]['iscrowd'] = 1
gt.dataset['annotations'][idx]['category_id'] = catId
cocoEval = COCOeval(gt, copy.deepcopy(dt), iou_type)
cocoEval.params.imgIds = imgIds
cocoEval.params.maxDets = [100]
cocoEval.params.iouThrs = [.1]
cocoEval.params.useCats = 1
cocoEval.evaluate()
cocoEval.accumulate()
ps_supercategory = cocoEval.eval['precision'][0, :, k, :, :]
ps_['ps_supercategory'] = ps_supercategory
# compute precision but ignore any class confusion
gt = copy.deepcopy(cocoGt)
for idx, ann in enumerate(gt.dataset['annotations']):
if ann['category_id'] != catId:
gt.dataset['annotations'][idx]['ignore'] = 1
gt.dataset['annotations'][idx]['iscrowd'] = 1
gt.dataset['annotations'][idx]['category_id'] = catId
cocoEval = COCOeval(gt, copy.deepcopy(dt), iou_type)
cocoEval.params.imgIds = imgIds
cocoEval.params.maxDets = [100]
cocoEval.params.iouThrs = [.1]
cocoEval.params.useCats = 1
cocoEval.evaluate()
cocoEval.accumulate()
ps_allcategory = cocoEval.eval['precision'][0, :, k, :, :]
ps_['ps_allcategory'] = ps_allcategory
return k, ps_
def analyze_results(res_file, ann_file, res_types, out_dir):
for res_type in res_types:
assert res_type in ['bbox', 'segm']
directory = os.path.dirname(out_dir + '/')
if not os.path.exists(directory):
print(f'-------------create {out_dir}-----------------')
os.makedirs(directory)
cocoGt = COCO(ann_file)
cocoDt = cocoGt.loadRes(res_file)
imgIds = cocoGt.getImgIds()
for res_type in res_types:
res_out_dir = out_dir + '/' + res_type + '/'
res_directory = os.path.dirname(res_out_dir)
if not os.path.exists(res_directory):
print(f'-------------create {res_out_dir}-----------------')
os.makedirs(res_directory)
iou_type = res_type
cocoEval = COCOeval(
copy.deepcopy(cocoGt), copy.deepcopy(cocoDt), iou_type)
cocoEval.params.imgIds = imgIds
cocoEval.params.iouThrs = [.75, .5, .1]
cocoEval.params.maxDets = [100]
cocoEval.evaluate()
cocoEval.accumulate()
ps = cocoEval.eval['precision']
ps = np.vstack([ps, np.zeros((4, *ps.shape[1:]))])
catIds = cocoGt.getCatIds()
recThrs = cocoEval.params.recThrs
with Pool(processes=48) as pool:
args = [(k, cocoDt, cocoGt, catId, iou_type)
for k, catId in enumerate(catIds)]
analyze_results = pool.starmap(analyze_individual_category, args)
for k, catId in enumerate(catIds):
nm = cocoGt.loadCats(catId)[0]
print(f'--------------saving {k + 1}-{nm["name"]}---------------')
analyze_result = analyze_results[k]
assert k == analyze_result[0]
ps_supercategory = analyze_result[1]['ps_supercategory']
ps_allcategory = analyze_result[1]['ps_allcategory']
# compute precision but ignore superclass confusion
ps[3, :, k, :, :] = ps_supercategory
# compute precision but ignore any class confusion
ps[4, :, k, :, :] = ps_allcategory
# fill in background and false negative errors and plot
ps[ps == -1] = 0
ps[5, :, k, :, :] = (ps[4, :, k, :, :] > 0)
ps[6, :, k, :, :] = 1.0
makeplot(recThrs, ps[:, :, k], res_out_dir, nm['name'], iou_type)
makeplot(recThrs, ps, res_out_dir, 'allclass', iou_type)
def main():
parser = ArgumentParser(description='COCO Error Analysis Tool')
parser.add_argument('result', help='result file (json format) path')
parser.add_argument('out_dir', help='dir to save analyze result images')
parser.add_argument(
'--ann',
default='data/coco/annotations/instances_val2017.json',
help='annotation file path')
parser.add_argument(
'--types', type=str, nargs='+', default=['bbox'], help='result types')
args = parser.parse_args()
analyze_results(args.result, args.ann, args.types, out_dir=args.out_dir)
if __name__ == '__main__':
main()
robustness_eval.py
参考:

使用该代码需要mmdetection的pkl格式的结果
通过代码
mmcv.dump(outputs, args.out)的形式保存
outputs通过如下代码
outputs应该就是普通的list组成,每张图一个list,每个list有bbox或bbox+segm
from mmdet.core import encode_mask_results
def single_gpu_test(model,
data_loader,
show=False,
out_dir=None,
show_score_thr=0.3):
model.eval()
results = []
dataset = data_loader.dataset
prog_bar = mmcv.ProgressBar(len(dataset))
for i, data in enumerate(data_loader):
with torch.no_grad():
result = model(return_loss=False, rescale=True, **data)
batch_size = len(result)
if show or out_dir:
if batch_size == 1 and isinstance(data['img'][0], torch.Tensor):
img_tensor = data['img'][0]
else:
img_tensor = data['img'][0].data[0]
img_metas = data['img_metas'][0].data[0]
imgs = tensor2imgs(img_tensor, **img_metas[0]['img_norm_cfg'])
assert len(imgs) == len(img_metas)
for i, (img, img_meta) in enumerate(zip(imgs, img_metas)):
h, w, _ = img_meta['img_shape']
img_show = img[:h, :w, :]
ori_h, ori_w = img_meta['ori_shape'][:-1]
img_show = mmcv.imresize(img_show, (ori_w, ori_h))
if out_dir:
out_file = osp.join(out_dir, img_meta['ori_filename'])
else:
out_file = None
model.module.show_result(
img_show,
result[i],
show=show,
out_file=out_file,
score_thr=show_score_thr)
# encode mask results
if isinstance(result[0], tuple):
result = [(bbox_results, encode_mask_results(mask_results))
for bbox_results, mask_results in result]
results.extend(result)
for _ in range(batch_size):
prog_bar.update()
return results然后我又去仔细看了下,好像不是,需要开启一个参数,才能获得这个pkl
参考:
robustness_eval.py:'list' object has no attribute 'keys' · Issue #3753 · open-mmlab/mmdetection · GitHub
https://github.com/open-mmlab/mmdetection/issues/4158
我会用coco2017数据集和官方自带的模型和权重测试
代码:
import os.path as osp
from argparse import ArgumentParser
import mmcv
import numpy as np
def print_coco_results(results):
def _print(result, ap=1, iouThr=None, areaRng='all', maxDets=100):
titleStr = 'Average Precision' if ap == 1 else 'Average Recall'
typeStr = '(AP)' if ap == 1 else '(AR)'
iouStr = '0.50:0.95' \
if iouThr is None else f'{iouThr:0.2f}'
iStr = f' {titleStr:<18} {typeStr} @[ IoU={iouStr:<9} | '
iStr += f'area={areaRng:>6s} | maxDets={maxDets:>3d} ] = {result:0.3f}'
print(iStr)
stats = np.zeros((12, ))
stats[0] = _print(results[0], 1)
stats[1] = _print(results[1], 1, iouThr=.5)
stats[2] = _print(results[2], 1, iouThr=.75)
stats[3] = _print(results[3], 1, areaRng='small')
stats[4] = _print(results[4], 1, areaRng='medium')
stats[5] = _print(results[5], 1, areaRng='large')
stats[6] = _print(results[6], 0, maxDets=1)
stats[7] = _print(results[7], 0, maxDets=10)
stats[8] = _print(results[8], 0)
stats[9] = _print(results[9], 0, areaRng='small')
stats[10] = _print(results[10], 0, areaRng='medium')
stats[11] = _print(results[11], 0, areaRng='large')
def get_coco_style_results(filename,
task='bbox',
metric=None,
prints='mPC',
aggregate='benchmark'):
assert aggregate in ['benchmark', 'all']
if prints == 'all':
prints = ['P', 'mPC', 'rPC']
elif isinstance(prints, str):
prints = [prints]
for p in prints:
assert p in ['P', 'mPC', 'rPC']
if metric is None:
metrics = [
'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10', 'AR100',
'ARs', 'ARm', 'ARl'
]
elif isinstance(metric, list):
metrics = metric
else:
metrics = [metric]
for metric_name in metrics:
assert metric_name in [
'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10', 'AR100',
'ARs', 'ARm', 'ARl'
]
eval_output = mmcv.load(filename)
num_distortions = len(list(eval_output.keys()))
results = np.zeros((num_distortions, 6, len(metrics)), dtype='float32')
for corr_i, distortion in enumerate(eval_output):
for severity in eval_output[distortion]:
for metric_j, metric_name in enumerate(metrics):
mAP = eval_output[distortion][severity][task][metric_name]
results[corr_i, severity, metric_j] = mAP
P = results[0, 0, :]
if aggregate == 'benchmark':
mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
else:
mPC = np.mean(results[:, 1:, :], axis=(0, 1))
rPC = mPC / P
print(f'\nmodel: {osp.basename(filename)}')
if metric is None:
if 'P' in prints:
print(f'Performance on Clean Data [P] ({task})')
print_coco_results(P)
if 'mPC' in prints:
print(f'Mean Performance under Corruption [mPC] ({task})')
print_coco_results(mPC)
if 'rPC' in prints:
print(f'Realtive Performance under Corruption [rPC] ({task})')
print_coco_results(rPC)
else:
if 'P' in prints:
print(f'Performance on Clean Data [P] ({task})')
for metric_i, metric_name in enumerate(metrics):
print(f'{metric_name:5} = {P[metric_i]:0.3f}')
if 'mPC' in prints:
print(f'Mean Performance under Corruption [mPC] ({task})')
for metric_i, metric_name in enumerate(metrics):
print(f'{metric_name:5} = {mPC[metric_i]:0.3f}')
if 'rPC' in prints:
print(f'Relative Performance under Corruption [rPC] ({task})')
for metric_i, metric_name in enumerate(metrics):
print(f'{metric_name:5} => {rPC[metric_i] * 100:0.1f} %')
return results
def get_voc_style_results(filename, prints='mPC', aggregate='benchmark'):
assert aggregate in ['benchmark', 'all']
if prints == 'all':
prints = ['P', 'mPC', 'rPC']
elif isinstance(prints, str):
prints = [prints]
for p in prints:
assert p in ['P', 'mPC', 'rPC']
eval_output = mmcv.load(filename)
num_distortions = len(list(eval_output.keys()))
results = np.zeros((num_distortions, 6, 20), dtype='float32')
for i, distortion in enumerate(eval_output):
for severity in eval_output[distortion]:
mAP = [
eval_output[distortion][severity][j]['ap']
for j in range(len(eval_output[distortion][severity]))
]
results[i, severity, :] = mAP
P = results[0, 0, :]
if aggregate == 'benchmark':
mPC = np.mean(results[:15, 1:, :], axis=(0, 1))
else:
mPC = np.mean(results[:, 1:, :], axis=(0, 1))
rPC = mPC / P
print(f'\nmodel: {osp.basename(filename)}')
if 'P' in prints:
print(f'Performance on Clean Data [P] in AP50 = {np.mean(P):0.3f}')
if 'mPC' in prints:
print('Mean Performance under Corruption [mPC] in AP50 = '
f'{np.mean(mPC):0.3f}')
if 'rPC' in prints:
print('Realtive Performance under Corruption [rPC] in % = '
f'{np.mean(rPC) * 100:0.1f}')
return np.mean(results, axis=2, keepdims=True)
def get_results(filename,
dataset='coco',
task='bbox',
metric=None,
prints='mPC',
aggregate='benchmark'):
assert dataset in ['coco', 'voc', 'cityscapes']
if dataset in ['coco', 'cityscapes']:
results = get_coco_style_results(
filename,
task=task,
metric=metric,
prints=prints,
aggregate=aggregate)
elif dataset == 'voc':
if task != 'bbox':
print('Only bbox analysis is supported for Pascal VOC')
print('Will report bbox results\n')
if metric not in [None, ['AP'], ['AP50']]:
print('Only the AP50 metric is supported for Pascal VOC')
print('Will report AP50 metric\n')
results = get_voc_style_results(
filename, prints=prints, aggregate=aggregate)
return results
def get_distortions_from_file(filename):
eval_output = mmcv.load(filename)
return get_distortions_from_results(eval_output)
def get_distortions_from_results(eval_output):
distortions = []
for i, distortion in enumerate(eval_output):
distortions.append(distortion.replace('_', ' '))
return distortions
def main():
parser = ArgumentParser(description='Corruption Result Analysis')
parser.add_argument('filename', help='result file path')
parser.add_argument(
'--dataset',
type=str,
choices=['coco', 'voc', 'cityscapes'],
default='coco',
help='dataset type')
parser.add_argument(
'--task',
type=str,
nargs='+',
choices=['bbox', 'segm'],
default=['bbox'],
help='task to report')
parser.add_argument(
'--metric',
nargs='+',
choices=[
None, 'AP', 'AP50', 'AP75', 'APs', 'APm', 'APl', 'AR1', 'AR10',
'AR100', 'ARs', 'ARm', 'ARl'
],
default=None,
help='metric to report')
parser.add_argument(
'--prints',
type=str,
nargs='+',
choices=['P', 'mPC', 'rPC'],
default='mPC',
help='corruption benchmark metric to print')
parser.add_argument(
'--aggregate',
type=str,
choices=['all', 'benchmark'],
default='benchmark',
help='aggregate all results or only those \
for benchmark corruptions')
args = parser.parse_args()
for task in args.task:
get_results(
args.filename,
dataset=args.dataset,
task=task,
metric=args.metric,
prints=args.prints,
aggregate=args.aggregate)
if __name__ == '__main__':
main()
下载权重:
https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
转换config
python print_config.py ../configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py > faster_rcnn_r50_fpn_1x_coco_ynh.py
结果显示
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 5001/5000, 53.9 task/s, elapsed: 93s, ETA: 0s
writing results to results.pkl
Evaluating bbox...
Loading and preparing results...
DONE (t=1.35s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=37.51s).
Accumulating evaluation results...
DONE (t=6.27s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.581
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.404
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.212
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.410
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.481
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.517
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.326
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.557
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.648
+---------------+-------+--------------+-------+----------------+-------+
| category | AP | category | AP | category | AP |
+---------------+-------+--------------+-------+----------------+-------+
| person | 0.519 | bicycle | 0.280 | car | 0.420 |
| motorcycle | 0.391 | airplane | 0.595 | bus | 0.612 |
| train | 0.561 | truck | 0.337 | boat | 0.260 |
| traffic light | 0.264 | fire hydrant | 0.637 | stop sign | 0.625 |
| parking meter | 0.422 | bench | 0.207 | bird | 0.329 |
| cat | 0.589 | dog | 0.547 | horse | 0.535 |
| sheep | 0.470 | cow | 0.504 | elephant | 0.593 |
| bear | 0.641 | zebra | 0.624 | giraffe | 0.628 |
| backpack | 0.145 | umbrella | 0.337 | handbag | 0.118 |
| tie | 0.297 | suitcase | 0.341 | frisbee | 0.624 |
| skis | 0.204 | snowboard | 0.308 | sports ball | 0.423 |
| kite | 0.392 | baseball bat | 0.238 | baseball glove | 0.324 |
| skateboard | 0.462 | surfboard | 0.332 | tennis racket | 0.444 |
| bottle | 0.373 | wine glass | 0.336 | cup | 0.401 |
| fork | 0.260 | knife | 0.130 | spoon | 0.110 |
| bowl | 0.408 | banana | 0.205 | apple | 0.186 |
| sandwich | 0.315 | orange | 0.283 | broccoli | 0.216 |
| carrot | 0.208 | hot dog | 0.260 | pizza | 0.467 |
| donut | 0.413 | cake | 0.320 | chair | 0.235 |
| couch | 0.368 | potted plant | 0.245 | bed | 0.374 |
| dining table | 0.240 | toilet | 0.533 | tv | 0.528 |
| laptop | 0.550 | mouse | 0.593 | remote | 0.262 |
| keyboard | 0.475 | cell phone | 0.307 | microwave | 0.550 |
| oven | 0.296 | toaster | 0.294 | sink | 0.327 |
| refrigerator | 0.478 | book | 0.137 | clock | 0.493 |
| vase | 0.354 | scissors | 0.212 | teddy bear | 0.427 |
| hair drier | 0.002 | toothbrush | 0.149 | None | None |
+---------------+-------+--------------+-------+----------------+-------+
OrderedDict([('bbox_mAP', 0.374), ('bbox_mAP_50', 0.581), ('bbox_mAP_75', 0.404), ('bbox_mAP_s', 0.212), ('bbox_mAP_m', 0.41), ('bbox_mAP_l', 0.481), ('bbox_mAP_copypaste', '0.374 0.581 0.404 0.212 0.410 0.481')])
后来发现都不行,必须先
test_robustness.py
然后才能
robustness_eval.py
https://github.com/open-mmlab/mmdetection/blob/master/docs/tutorials/robustness_benchmarking.md