Ubuntu的Spark 搭建实验(这次是完整的哈,没有错误)
学习目标:
学会Spark环境的搭建
学习内容:
学习Spark搭建环境的过程
一. 软件的下载,解压与安装
二. 环境的配置
学习环境:
环境组合是Spark2.3.3+Java8+Scala2.11(这里都不是最新版本的,需要的话自行去官网搜索就好,直接官网下载就可以)
一、 软件的下载,解压和移动
1.1 软件的下载,这里采用的wget命令代替
wget http://i9000.net:8888/sgn/HUP/spark/spark-2.3.3-bin-hadoop2.7.tgz #spark的下载
wget http://i9000.net:8888/sgn/HUP/spark/scala-2.11.12.tgz #scala的下载
wget http://i9000.net:8888/sgn/HUP/spark/jdk-8u201-linux-x64.tar.gz #jdk的下载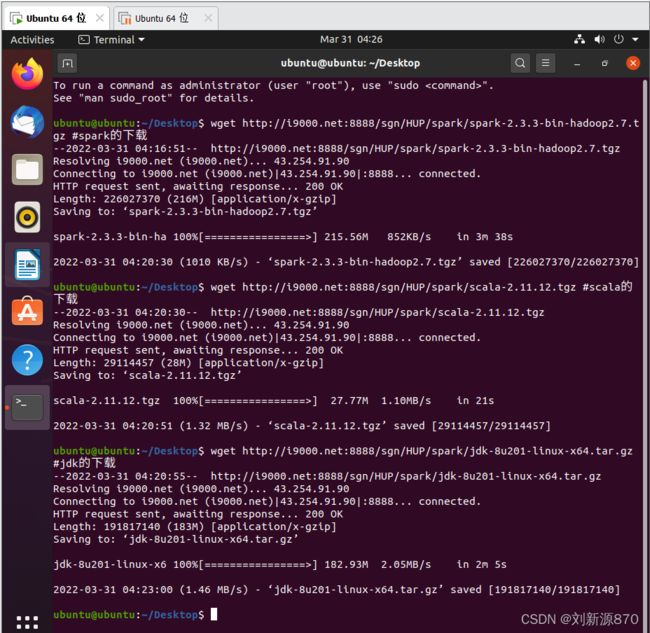
1.2 解压文件
tar -zxvf jdk-8u201-linux-x64.tar.gz
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz
tar -zxvf scala-2.11.12.tgz 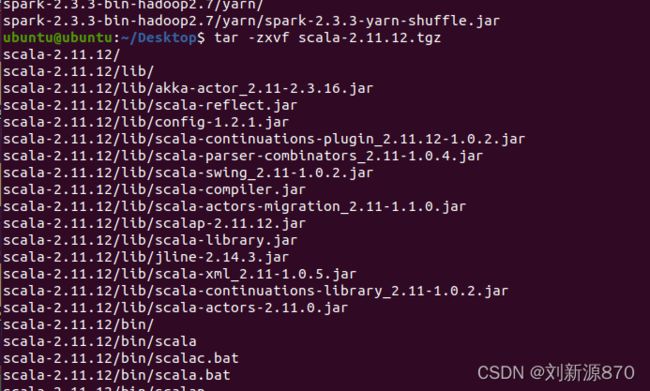
1.3 使用cp命令移动到 /opt里面,sudo是root用户命令。
sudo cp -R jdk1.8.0_201 /opt
sudo cp -R spark-2.3.3-bin-hadoop2.7 /opt
sudo cp -R scala-2.11.12 /opt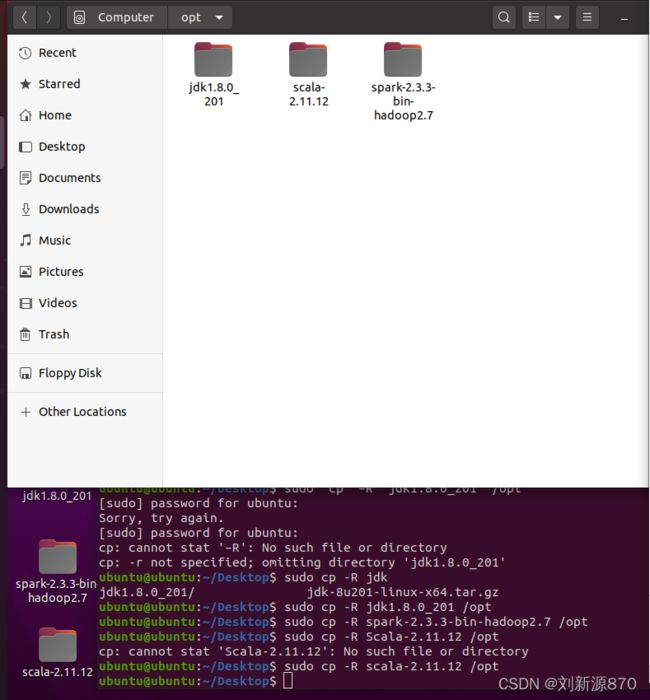
1.4 修改文件夹的权限为777,可以读写改。
sudo chmod -R 777 /opt
![]()
二 、Spark相关配置
Spark在使用之前,需要进行一定的配置。主要包括安装SSH,实现免密码登录,修改环境变量,修改Spark文件夹的访问权限,节点参数配置等。
2.1安装SSH
sudo apt-get update
sudo apt-get install openssh-server 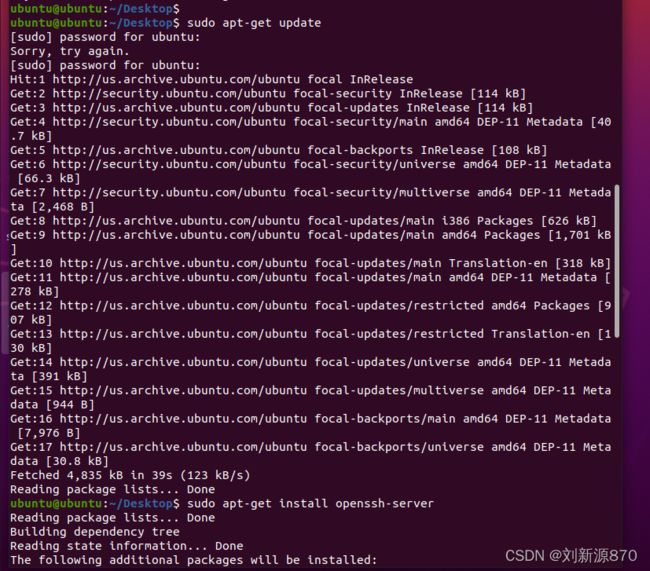
这里面需要点yes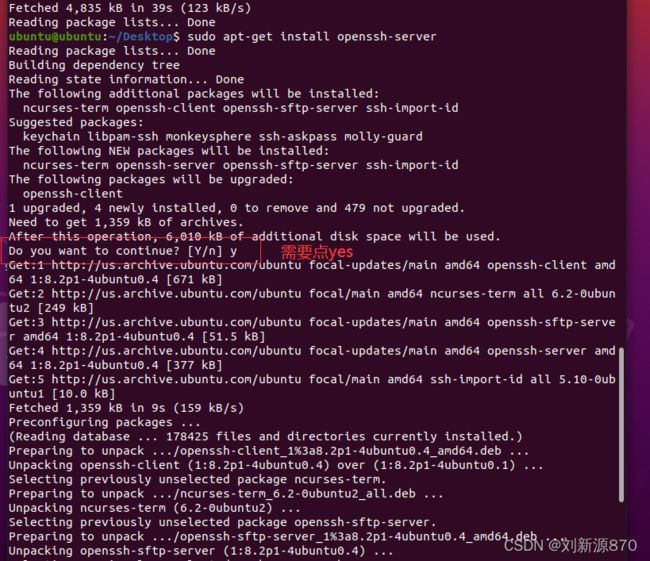
2.2 SSH免密登录
2.2.1安装完ssh后,打开shell,输入命令生成密钥。
ssh-keygen -t rsa连点三个enter
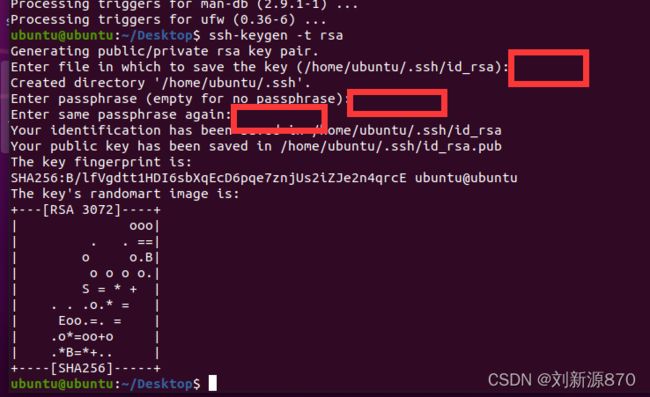
2.2.2把公钥的内容添加到authorized_keys文件中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ![]()
2.2.3更改权限:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys 
2.2.4设置好输出命令:
sudo service ssh start
ssh localhost 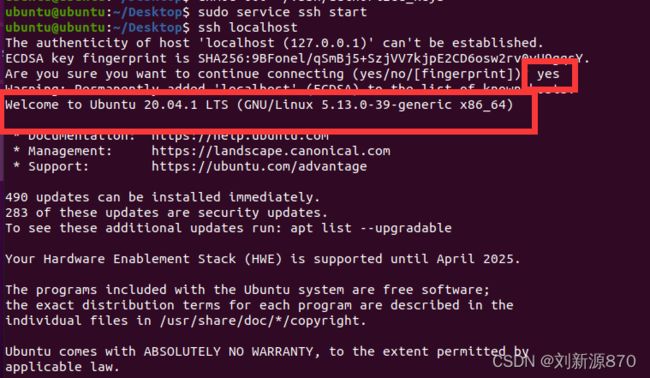
ssh免密这就证明成功啦!
2.3 JAVA环境配置,Scala环境配置,Spark环境配置。
修改环境,进入/Home,里面打开隐藏文件 。
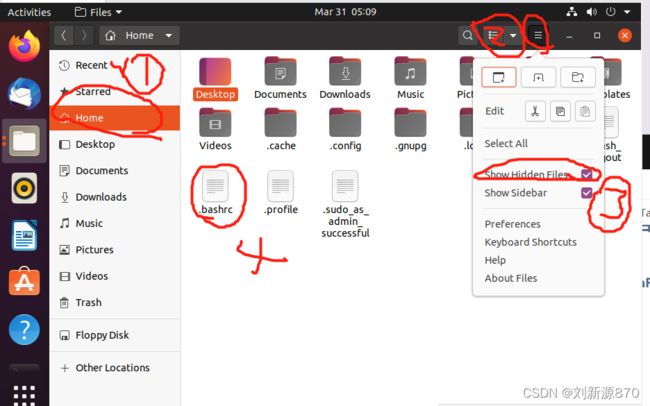
我这里使用windows系统,所以我直接修改,改一下权限命令。
sudo chmod 777 -R /home
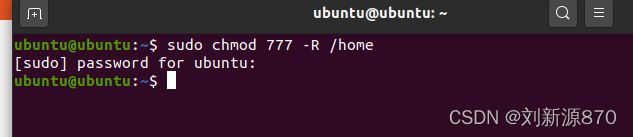
直接双击点进去就可以修改了,就不需要vi了。
直接打开.bashrc文件,在最后面加入环境配置
export JAVA_HOME=/opt/jdk1.8.0_17
export CLASS_PATH=/opt/jdk1.8.0_17/lib
export PATH=$PATH:$JAVA_HOME/bin
export SCALA_HOME=/opt/Scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark-2.3.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin点一下save保存就好了
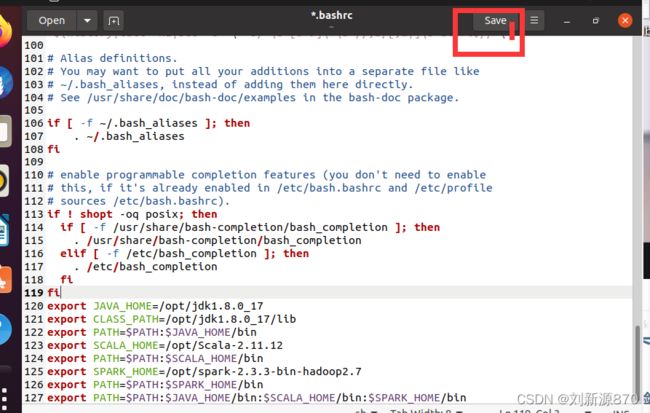
由于配置在/home/.bashrc文件了所以每次重启不需要source了。
2.4 修改Spark配置文件
2.4.1 复制模板文件 在Spark的conf目录中已经存放了Spark环境配置和节点配置以及日志配置等文件 的模板(以template结尾的文件),并且模板文件中有相关配置项的文字描述提示。 将文件夹中spark-env.sh.template、log4j.properties.template、slaves.template三个文件 拷贝为spark-env.sh、log4j.properties、slaves到同一目录下(conf文件夹),注意 把.template去掉,然后Spark启动时就会对文件中的配置项进行读取,否则找不到配置。
cd /opt/spark-2.3.3-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
cp log4j.properties.template log4j.properties
cp slaves.template slaves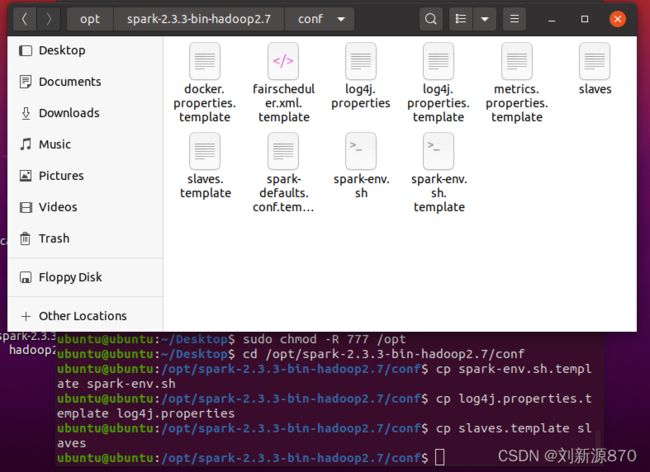
2.4.2 修改spark-env设置主节点和从节点的配置
export JAVA_HOME=/opt/jdk1.8.0_201
export SCALA_HOME=/opt/Scala-2.11.12
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1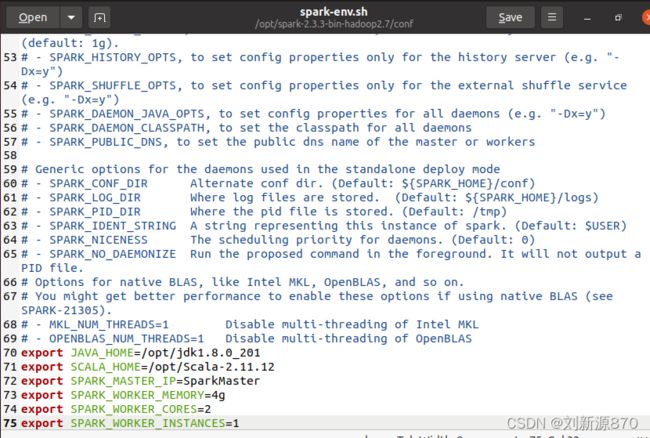
2.4.3修改slaves设置从节点地址 添加节点主机名称。
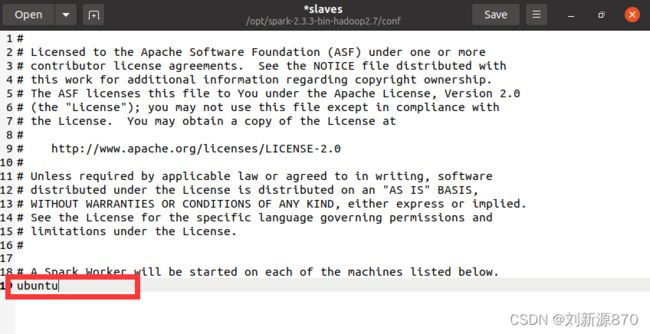
三 、 Spark集群启动与关闭
3.1 进入到Spark目录中:
cd /opt/spark-2.3.3-bin-hadoop2.7/sbin 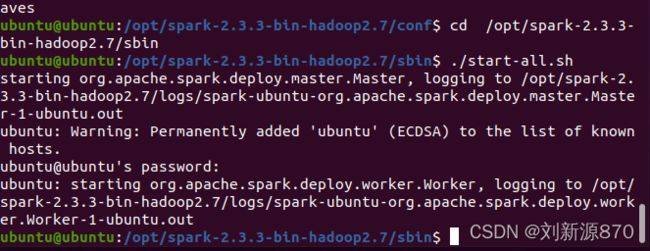
3.1.2 设置文件夹可读可写可执行权限
要更改root用户,不然没办法进行命令
sudo su root
sudo chmod –R 777 /opt/spark-2.3.3-bin-hadoop2.7

3.2 用localhost:8080命令查看是否成功
打开浏览器,输入localhost:8080
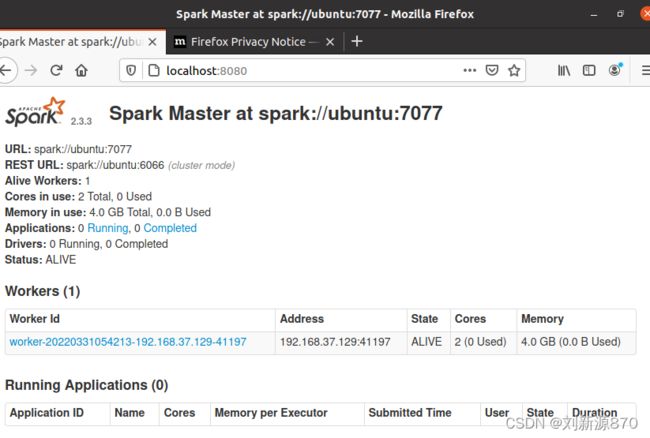
3.3 关闭数据集
./stop-all.sh
./stop-all.sh