语音交互知识点汇总
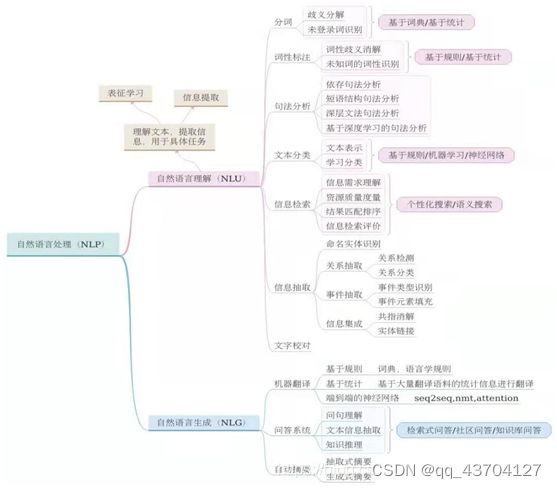
1 NLU
1.自然语言理解(Natural Language Understanding,NLU),使计算机理解自然语言(人类语言文字)等,重在理解。
2.难点:
(1)语言的多样性:语言组成没有规律,组合方式多样灵活
(2)语言的歧义性:一词多义
(3)语言中的噪声:存在多字、少字、错字、噪音等问题
(4)语言的知识依赖:依赖于先天经验和知识
(5)语言的上下⽂:不同上下文,语义各不同
3.层次结构:
(1)语音分析:要根据音位规则,从语音流中区分出一个个独立的音素,再根据音位形态规则找出音节及其对应的词素或词。
(2)词法分析:找出词汇的各个词素,从中获得语言学的信息。
(3)句法分析:对句子和短语的结构进行分析,目的是要找出词、短语等的相互关系以及各自在句中的作用。
(4)语义分析:找出词义、结构意义及其结合意义,从而确定语言所表达的真正含义或概念。
(5)语用分析:研究语言所存在的外界环境对语言使用者所产生的影响。
4.技术发展历程:
(1)基于规则的方法 :通过总结规律来判断自然语言的意图,常⻅的⽅法有:CFG、JSGF等。
- 上下文无关文法(CFG):验证字符串是否符合某个规则文法G
(2) 基于统计的方法 :对语言信息进行统计和分析,并从中挖掘出语义特征,常⻅的方法有:SVM、HMM等。
- 隐马尔科夫模型HMM
- 最大熵马尔可夫模型MEMM
- 条件随机场CRF
(3)基于深度学习的⽅法:CNN,RNN,LSTM
2 NLG
1.自然语言理解(NLG,Natural Language Generation),提供结构化的数据、文本、图表、音频、视频等,生成人类可以理解的自然语言形式的文本。
2.模式:
(1)text-to-text:文本到语言的生成
(2)data-to-text:数据到语言的生成
(3)image-to-text:图像到语言的生成
3.方式:
(1)简单的数据合并:自然语言处理的简化形式,将数据转换为文本(通过类似Excel的函数)。
(2)模板化的NLG:这种形式的NLG使用模板驱动模式来显示输出。数据动态地保持更改,并由预定义的业务规则集生成。
(3)高级NLG:这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果以可理解的方式呈现,如一般用基于深度学习的encoder-decoder结构来实现。
4.步骤:
第一步:内容确定 - Content Determination
首先,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 - Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 - Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 - Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 - Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
5.典型应用:
(1)应用目标:能够大规模的产生个性化内容;帮助人类洞察数据,让数据更容易理解;加速内容生产。
(2)自动写新闻(自动定稿),聊天机器人(机器客服),BI(商业智能)的解读和报告生成
(3)论文写作,摘要生成,自动作诗,新闻写作、报告生成,
3 语音交互
语音交互的流程及使用的技术如下图所示:
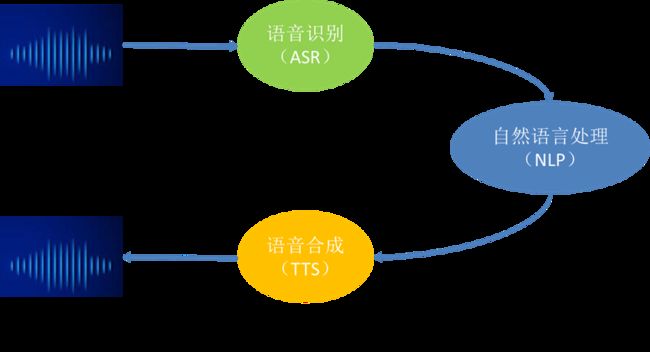
- 语音识别(Automatic Speech Recognition):简称ASR,是将声音转化成文字的过程,相当于耳朵。
- 自然语言处理(Natural Language Processing):简称NLP,是理解和处理文本的过程,相当于大脑。
- 语音合成(Text-To-Speech):简称TTS,是把文本转化成语音的过程,相当于嘴巴。
3.1 语音识别(ASR)
语音识别的流程是:“输入—编码—解码—输出”

语音输入一般是时域的语音信号,数学上用一系列向量表示(length T, dimension d),输出是文本,用一系列token表示(length N, V different tokens),一般来说,在ASR问题中,输入信号的长度T会大于token的长度N

1,编码
把声音转化成机器能识别的样式,即用数字向量表示。输入的声音信号是计算机没办法直接识别的,首先需要将声音信号切割成一小段一小段,然后每一小段都按一定的规则用向量来表示。

2,解码:把数字向量拼接文字的形式

首先,将编译好的向量,放到声学模型中,就可以得到每一小段对应的字母是什么;
然后,把翻译出来的字母再经过语言模型,就可以组装成单词了。
3,Token的选择
Token可以理解为语音和文字之间的一种桥梁纽带,我们听到的语音可以通过AD转化变为数字信号存储,进而以矩阵的形式存储于计算机中,那日常生活中的文字也需要一种转换被计算机所存储使用,ASR问题中,目前主流的token有以下几种:
(1),Phoneme:以声音的基本元素作为Token,不同的单词由不同的音素组成,通过识别输入语音中存在哪些音素进而组合成识别出的文字,这里就存在一个很重要的映射关系表Lexicon,所以这种Token的缺点也很明显,即需要语言学的知识才可以得到Lexicon,而且不同的文献会给出不同的Lexicon

(2). Grapheme:以文字书写的最小单位作为token
优点:(1)不需要语言学知识,是Lexicon free;(2)即使遇到了训练过程中没有出现的Token,也可以期待一下会有什么样的结果(手动滑稽)
缺点:(1)使用起来比较有挑战性,很多发音相同但对应Token确是不同,需要比较强的上下文信息,对模型的学习提出了更高的要求,此时面对的是一个更加复杂的问题;(2)以英文举例,有比较大的拼错风险

(3).Word:用词汇作为Token,对很多语言来说往往都不太适合,因为Token总数量V会非常大,英文因为有明确的空格作为区分词的方式,V的数量还算可以接受,但中文就很难以词作为Token,同时以土耳其语举例,是可以不断加后缀变成新的词汇的,是无法穷举的,所以像这样的语言,都不适合用word作为Token
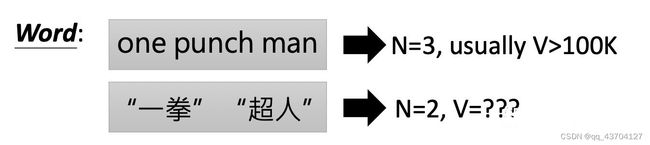
(4).Morpheme:以有富有具体含义的最小单位作为token,是一个介于word和grapheme之间的token,以英文来举例,unbreakable → “un” “break” “able”;rekillable → “re” “kill” “able”
那如何来获取一种语言的Morpheme呢?一般有两种途径:
求助语言学家linguistic
统计发现一些模式statistic
(5).Bytes:更硬核的Token是直接选择计算机中的byte,很显然这种方式的Token是 language independent
上述token方法使用比例为:
Grapheme 41%
Phoneme 32%
Morpheme 17%
Word 10%
3.2 语音合成(TTS)
语音合成,通常又称文语转换(Text To Speech,TTS),是一种可以将任意输入文本转换成相应语音的技术,语音有三大关键成分:信息、音色和韵律。
语音合成根据应用的算法思想的不同,总体可以分为两类:基于统计参数的语音合成(传统)、基于深度学习的语音合成(端到端)。
3.2.1传统的语音合成系统
1,总体框架
通常包含前端和后端两个模块。前端模块主要是对输入文本进行分析,提取后端模块所需要的语言学信息。对中文合成系统来说,前端模块一般包含文本正则化、分词、词性预测、多音字消歧、韵律预测等子模块。后端模块根据前端分析结果,通过一定的方法生成语音波形。

前端模块通常采用NLP(自然语言处理)提取文本的语言学特征;
后端模块一般分为基于统计参数建模的语音合成(Statistical Parameter Speech Synthesis,SPSS,以下简称参数合成),以及基于单元挑选和波形拼接的语音合成(以下简称拼接合成)两条技术主线。
- 参数合成:在训练阶段对语音声学特征、时长信息进行上下文相关建模,在合成阶段通过时长模型和声学模型预测声学特征参数,对声学特征参数做后处理,最终通过声码器恢复语音波形。(优点:音库较小时,有比较稳定的合成效果;缺点:统计建模带来的声学特征参数过平滑,以及声码器对音质会有损伤。)
- 拼接合成:通常也会用到统计模型来指导单元挑选,训练阶段与参数合成基本相同。在合成阶段通过模型计算代价来指导单元挑选,采用动态规划算法选出最优单元序列,再对选出的单元进行能量规整和波形拼接。(优点:可直接使用真实语音片段,最大限度保留语音音质;缺点:需要音库较大,无法保证领域外文本的合成效果。)
2,基于统计参数的语音合成

- 特征提取器的主要作业是生成语言学特征,以帮助声学模型生成更为准确的声学特征。
- 声学模型无法直接产生语音波形,其主要原因是,语音非常复杂且难以建模。因此声学模型一般输出梅尔频谱等中间形式表示,然后再由声码器根据中间形式表示语音。
- 声码器通过梅尔频谱等声学特征生成音频,需要将低维的声学特征映射到高维的语音波形,计算复杂度较高,因此波形波形恢复过程是语音合成系统提升效率的关键步骤之一。另外,由于声码器需要学习预测的信息量较大,因而也限制了最终的语音质量。
3.2.2 端到端的合成语音系统
1,总体框架

2,基于深度学习的语音合成

- 文本预处理:为中文文本添加韵律信息,并将汉字转化为注音序列;
- 声学特征生成网络:根据文本前端输出的信息产生声学特征,如:将注音序列映射到梅尔频谱或线性谱;
- 声码器:利用频谱等声学特征,生成语音样本点并重建时域波形,如:将梅尔频谱恢复为对应的语音。
1.2.1特征网络模型算法
1,Tacotron
Tacotron是第一个真正意义上的端到端语音合成系统。输入文本或者注音字符,输出Linear-Spectrum,再经过声码器Griffin-Lim转换为波形。Tacotron目前推出了两代,Tacotron2主要改进是简化了模型,去掉了复杂的CBHG结构,并且更新了Attention机制,从而提高了对齐稳定性。
(1)结构
网络分为4部分,左侧为Encoder,中间为Attention,右下为Decoder,右上为Post-processing。
Input: 为了避免各种语言的多音字,未录入词发音等问题,Tacotron通常将注音字符作为输入,例如中文可将“拼音”作为输入,可以使用汉字转拼音的python库进行转化。
Output: 根据不同用途,Tacotron可以输出Linear-Spectrum或者Mel-Spectrum两种频谱。可根据声码器进行选择:
| 声码器 |
频谱 |
| Griffin-Lim |
Linear-Spectrum |
| WaveNet |
Linear-Spectrum或者Mel-Spectrum(极端代价更小,推荐使用) |
Post-processing: 在Tacotron+WaveNet框架下,由Tacotron输入注音字符,输出频谱;WaveNet输入频谱,输出波形。post-processing模块加在Tacotron和WaveNet之间,主要目的在于串联多个帧,提高生成质量。seq2seq框架决定了Decoder只能看到前面若干帧,而对后面一无所知。但post-processing可以向前向后观测若干帧,参考信息更多,因此生成质量更高。
(2)CBHG
Encoder和Post-processing都包含一个称为CBHG的结构。所谓CBHG即为:1-D convolution bank + highway network + bidirectional GRU,如下图所示。
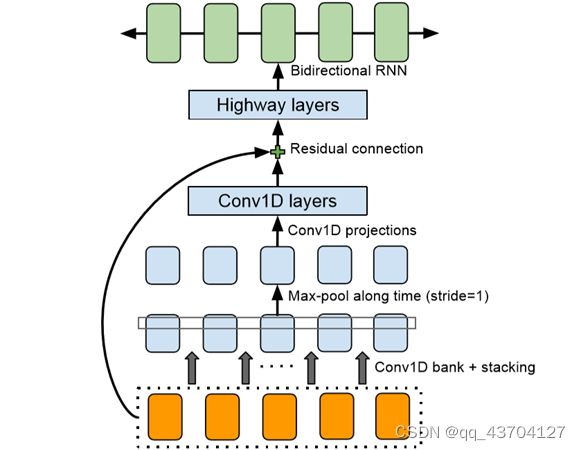
CBHG的网络结构如蓝色框所示,由一维卷积滤波器组,Highway网络和一个双向GRU组成,CBHG是一种强大的网络,常被用来提取序列特征。
(3)Tacotron + WaveNet(声码器)
Tacotron能够将注音字符解压为频谱,需要声码器(SampleRNN、WaveNet、WaveRNN等)将频谱还原成波形。WaveNet是采样点自回归模型的工作方式。模型输入若干历史采样点,输出下一采样点的预测值,也即根据历史预测未来。
一个完整的TTS系统的整体流程即是:注音字符输入Tacotron中,输出Mel-Spectrum;Mel-Spectrum输入WaveNet,输出声音波形。
- DeepVoice
DeepVoice将传统参数合成的TTS系统分拆成多个子模块,每个子模块用一个神经网络模型代替。DeepVoice将语音合成分成5部分进行,分别为:文本转音素(又称语素转音素, G2P)、音频切分、音素时长预测、基频预测、声学模型。
(1)优缺点
优势:提供了完整的TTS解决方案,不像WaveNet需要依赖其它模块提供特征,使用的人工特征也减少了;合成速度快,实时性好
缺陷:误差累积,5个子模块的误差会累积,一个模块出错,整个合成失败,开发和调试难度大;虽然减少使用了人工特征,但在这个完整的解决方案中,仍然需要使用音素标记、重音标记等特征;直接使用文本输入,不能很好解决多音字问题。
(2)DeepVoice2:引入“说话人”向量,能够合成多种音色的语音。
1.2.2 声码器模型算法
1,Griffin-Lim
Griffin-Lim是一种在仅有幅度谱,而缺少相位谱的憒况下重建时域波形的算法。由于要对抛弃相位信息的语音波形进行恢复,因此需要通过迭代,尽可能“猜测”出原始信息。
2,WaveNet
WaveNet是一种典型的自回归生成模型,所谓自回归生成模型,即是利用前面若干时刻变量的线性组合来描述以后某时刻变量的线性回归模型。不对语音做任何先验假设,而是利用神经网络从数据中学习分布,不直接预测语音样本值,而是通过一个采样过程来生成语音。
优势:能根据声学特征,生成高质量的语音。
缺陷:1)每次预测一个采样点,速度慢;2)WaveNet并非完整的TTS方案,依赖其余模块提供高层特征,前端分析出错,直接影响合成效果;3)用于TTS时,初始采样点的选择很重要
3,WaveRNN
WaveRNN采用一种全新的声码器架构,结构尤为简单,主体仅由一个单层循环神经网络(RNN)组成,并且RNN利用稀疏矩阵进一步降低计算量,相比WaveNet合成速度提升10倍左右。
4 图神经网络
图神经网络(Graph Neural Networks,GNN)就是将图数据和神经网络进行结合,在图数据上面进行端对端的计算。
- GNN结构
相比较于神经网络最基本的网络结构全连接层(MLP),特征矩阵乘以权重矩阵,图神经网络多了一个邻接矩阵。计算形式很简单,三个矩阵相乘再加上一个非线性变换
一个比较常见的图神经网络的应用模式如下图,输入是一个图,经过多层图卷积等各种操作以及激活函数,最终得到各个节点的表示,以便于进行节点分类、链接预测、图与子图的生成等等任务。
2.GNN分类
图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Auto-encoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)。
3.图神经网络的几个经典模型与发展
GNN最经典的模型有GCN, GraphSAGE和GAT,下面分别进行介绍:
(1)GCN
Semi-Supervised Classification with Graph Convolutional Networks(ICLR2017) https://arxiv.org/pdf/1609.02907
图卷积网络聚合邻居节点的特征然后做一个线性变换。如下图:
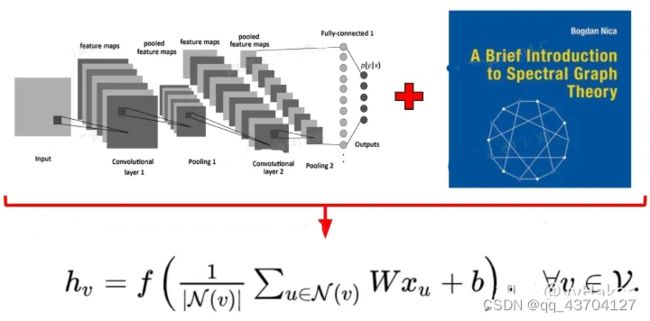
同时为了使得GCN能够捕捉到K-hop的邻居节点的信息,作者还堆叠多层GCN layers,如堆叠K层有:
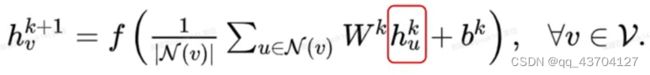
上述式子使用矩阵表示为:

其中D-12ÃD-12是归一化之后的邻接矩阵,H(l)W(l)相当于给l层的所有节点的embedding做了一次线性变换,左乘以邻接矩阵表示对每个节点来说,该节点的特征表示为邻居节点特征相加之后的结果。(注意将D-12ÃD-12换成矩阵A就是GNN结构图中所说的三矩阵相乘)
GCN的缺点也是很显然易见的,第一,GCN需要将整个图放到内存和显存,这将非常耗内存和显存,处理不了大图;第二,GCN在训练时需要知道整个图的结构信息(包括待预测的节点), 这在现实某些任务中也不能实现。
(2)Graph Sample and Aggregate(GraphSAGE)
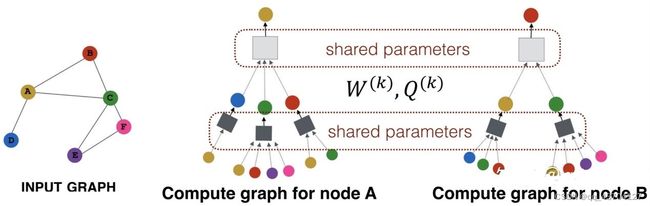
为了解决GCN的两个缺点问题,GraphSAGE被提了出来。GraphSAGE是一个Inductive Learning框架,具体实现中,训练时它仅仅保留训练样本到训练样本的边,然后包含Sample和Aggregate两大步骤,Sample是指如何对邻居的个数进行采样,Aggregate是指拿到邻居节点的embedding之后如何汇聚这些embedding以更新自己的embedding信息。下图展示了GraphSAGE学习的一个过程,

第一步,对邻居采样
第二步,采样后的邻居embedding传到节点上来,并使用一个聚合函数聚合这些邻居信息以更新节点的embedding
第三步,根据更新后的embedding预测节点的标签
下图说明了一个训练好的GrpahSAGE是如何给一个新的节点生成embedding的(即一个前向传播的过程)

首先,(line1)算法首先初始化输入的图中所有节点的特征向量,(line3)对于每个节点v,拿到它采样后的邻居节点N(v)后,(line4)利用聚合函数聚合邻居节点的信息,(line5)并结合自身embedding通过一个非线性变换更新自身的embedding表示。
算法里面的K,它是指聚合器的数量,也是指权重矩阵的数量,还是网络的层数,这是因为每一层网络中聚合器和权重矩阵是共享的。
- Aggregate
网络的层数可以理解为需要最大访问的邻居的跳数(hops),如figure1中图2红色节点的跳数为两跳,则网络层数为2。为了更新红色节点,首先在第一层(k=1),我们会将蓝色节点的信息聚合到红色解节点上,将绿色节点的信息聚合到蓝色节点上。在第二层(k=2)红色节点的embedding被再次更新,不过这次用到的是更新后的蓝色节点embedding,这样就保证了红色节点更新后的embedding包括蓝色和绿色节点的信息,也就是两跳信息。下图很好的说明了节点A和B的更新过程:
常见的聚合器有:

- Sample
GraphSAGE是采用定长抽样的方法,具体来说,定义需要的邻居个数S,然后采用有放回的重采样/负采样方法达到S。保证每个节点(采样后的)邻居个数一致,这样是为了把多个节点以及它们的邻居拼接成Tensor送到GPU中进行批训练。
- 学习聚合器的参数以及权重矩阵W
如果是有监督的情况下,可以使用每个节点的预测lable和真实lable的交叉熵作为损失函数。
如果是在无监督的情况下,可以假设相邻的节点的embedding表示尽可能相近,因此可以设计出如下的损失函数,

- GraphSAGE的优缺点
1)优点
(1)利用采样机制,很好的解决了GCN必须要知道全部图的信息问题,克服了GCN训练时内存和显存的限制,即使对于未知的新节点,也能得到其表示
(2)聚合器和权重矩阵的参数对于所有的节点是共享的
(3)模型的参数的数量与图的节点个数无关,这使得GraphSAGE能够处理更大的图
(4)既能处理有监督任务也能处理无监督任务
2)缺点
每个节点那么多邻居,GraphSAGE的采样没有考虑到不同邻居节点的重要性不同,而且聚合计算的时候邻居节点的重要性和当前节点也是不同的。
(3)Graph Attention Networks(GAT)
为了解决GNN聚合邻居节点的时候没有考虑到不同的邻居节点重要性不同的问题,GAT借鉴了Transformer的idea,引入masked self-attention机制,在计算图中的每个节点的表示的时候,会根据邻居节点特征的不同来为其分配不同的权值。对于输入的图,graph attention layer如下图所示:
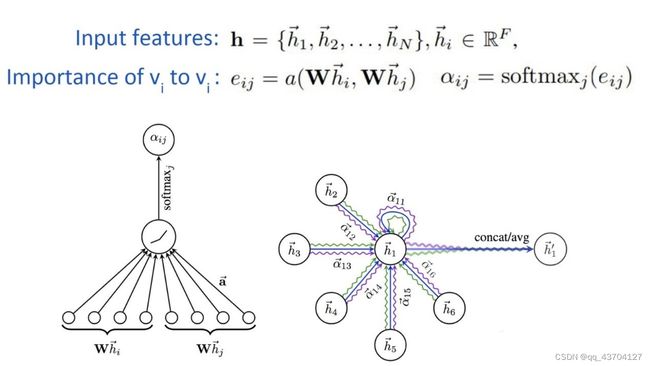
其中a采用了单层的前馈神经网络实现,计算过程如下(注意权重矩阵W对于所有的节点是共享的):

计算完attention之后,就可以得到某个节点聚合其邻居节点信息的新的表示,计算过程如下:
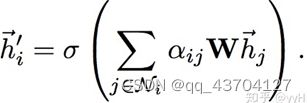
为了提高模型的拟合能力,还引入了多头的self-attention机制,即同时使用多个Wk计算self-attention,然后将计算的结果合并(连接或者求和):
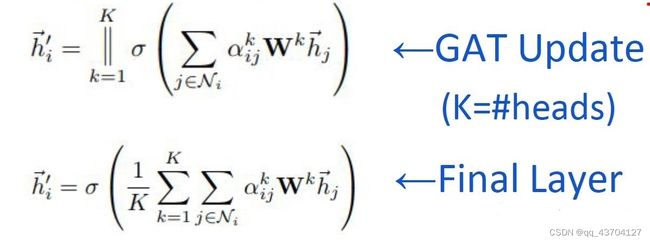
此外,由于GAT结构的特性,GAT无需使用预先构建好的图,因此GAT既适用于Transductive Learning,又适用于Inductive Learning。
- GAT优点:
(1)训练GCN无需了解整个图结构,只需知道每个节点的邻居节点即可
(2)计算速度快,可以在不同的节点上进行并行计算
(3)既可以用于Transductive Learning,又可以用于Inductive Learning,可以对未见过的图结构进行处理
4,无监督的节点表示学习(Unsupervised Node Representation)
由于标注数据的成本非常高,如果能够利用无监督的方法很好的学习到节点的表示,将会有巨大的价值和意义,比较经典的模型有GraphSAGE、Graph Auto-Encoder(GAE)等
Graph Auto-Encoder(GAE)
模型大致流程为:输入图的邻接矩阵A和节点的特征矩阵X,通过编码器(图卷积网络)学习节点低维向量表示的均值μ和方差σ,然后用解码器(链路预测)生成图,如下图所示:
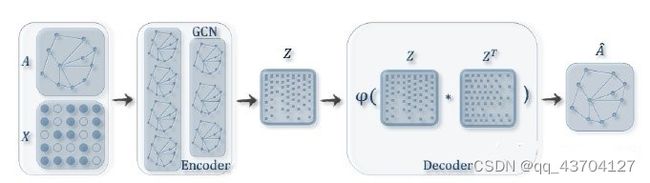
由上图可得编码器(Encoder)采用简单的两层GCN网络,解码器(Encoder)计算两点之间存在边的概率来重构图,损失函数包括生成图和原始图之间的距离度量,以及节点表示向量分布和正态分布的KL-散度两部分。具体公式如下图所示:

图嵌入旨在通过保留图的网络拓扑结构和节点内容信息,将图中顶点表示为低维向量,以便使用简单的机器学习算法(例如,支持向量机分类)进行处理。

注:
1,inductive learing和transductive learing
inductive learing(归纳学习)是我们常见的学习方式。在训练时没见过testing data的特征,通过训练数据训练出一个模型来进行预测,可以直接利用这个已训练的模型预测新数据。
transductive learing(直推学习)是不常见的学习方式,属于半监督学习的一个子问题。在训练时见过testing data的特征,通过观察所有数据的分布来进行预测,如果新加入一个数据,要重新训练整个算法。即直推式学习是用训练集数据和测试集数据共同训练模型,然后再用测试集数据进行测试。
2,自编码器(AutoEncoder,AE)和变分自编码器(Variational auto-encoder,VAE)
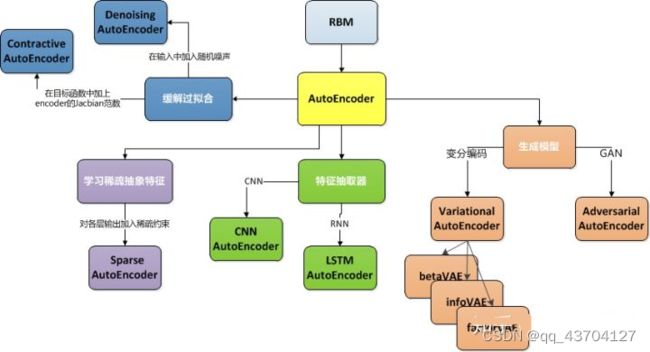
(1)自编码器
属于Unsupervised Learning问题 经常用于数据集预处理进行数据降维或者特征的提取。

特别注意:由于本文是在阅读了大量博客基础上汇总得到的,所以可能有部分内容摘自其他博客,如有冒犯,诚表歉意,并希望能联系解决。