Objects as Points 论文精读
对象作为点
摘要
目标检测在图像中将检测对象定义为一个与坐标轴对齐的框。大多数成功的对象检测器都会列举几乎详尽的潜在对象位置列表,并对每个位置进行分类。这是浪费的、低效的,并且需要额外的后处理。在本文中,我们采用了不同的方法。 我们将一个对象建模为一个点——它的边界框的中心点。我们的检测器使用关键点估计来找到中心点并回归到所有其他对象属性,例如大小、3D 位置、方向,甚至姿势。 我们基于中心点的方法 CenterNet 比相应的基于边界框的检测器具有端到端的可微分、更简单、更快且更准确。 CenterNet 在 MS COCO 数据集上实现了最佳速度-准确度权衡,142 FPS 时 AP 为 28.1%,52 FPS 时 AP 为 37.4%,多尺度测试时 1.4 FPS 时 AP 为 45.1%。 我们使用相同的方法来估计 KITTI 基准中的 3D 边界框和 COCO 关键点数据集上的人体姿势。 我们的方法与复杂的多阶段方法具有竞争力并实时运行。

图一 实时探测器COCO验证的速度-精度权衡。拟议的CenterNet优于一系列最先进的算法
一、简介
目标检测为许多视觉任务提供支持,例如实例分割 [7,21,32]、姿势估计 [3,15,39]、跟踪 [24,27] 和动作识别 [5]。 目标检测有很多扩展应用,例如:监控 [57]、自动驾驶 [53] 和视觉问题解析 [1]。 当前的对象检测器通过一个紧密包围对象的轴对齐边界框来表示每个对象[18,19,33,43,46]。然后,他们将对象检测简化为大量潜在对象边界框的图像分类。对于每个边界框,分类器确定图像内容是特定对象还是背景。Onestage 检测器 [33, 43] 在图像上滑动可能的边界框(称为锚点)的复杂排列,并直接对它们进行分类,而无需指定框内容。两阶段检测器 [18, 19, 46] 重新计算每个潜在框的图像特征,然后对这些特征进行分类。后处理,即非极大值抑制,然后通过计算边界框 IoU 去除同一实例的重复检测。这种后处理很难区分和训练[23],因此大多数当前的检测器都不是端到端可训练的。尽管如此,在过去的五年中[19],这个想法已经取得了很好的经验成功[12,21,25,26,31,35,47,48,56,62,63]。然而,基于滑动窗口的对象检测器有点浪费,因为它们需要枚举所有可能的对象位置和尺寸。
在本文中,我们提供了一种更简单、更有效的替代方案。我们通过边界框中心的一个点来表示对象(参见图 2)。然后直接从中心位置的图像特征回归其他属性,例如对象大小、尺寸、3D 范围、方向和姿势。 目标检测是一个标准的关键点估计问题[3,39,60]。 我们只需将输入图像输入到生成热图的全卷积网络 [37,40]。 此热图中的峰值对应于对象中心。 每个峰值的图像特征预测物体边界框的高度和权重。 该模型使用标准的密集监督学习进行训练 [39,60]。 推理是单个网络前向传递,没有用于后处理的非极大值抑制。
我们的方法是通用的,可以轻松扩展到其他任务。我们通过预测每个中心点的额外输出来提供 3D 对象检测 [17] 和多人人体姿态估计 [4] 的实验(见图 4)。对于 3D 边界框估计,我们回归到对象绝对深度、3D 边界框尺寸和对象方向 [38]。对于人体姿态估计,我们将 2D 关节位置视为距中心的偏移量,并在中心点位置直接回归到它们。
我们方法的简单性使其能够以非常高的速度运行 CenterNet(图 1)。使用简单的 Resnet18 和上卷积层 [55],我们的网络以 142 FPS 的速度运行,具有 28.1% 的 COCO 边界框 AP。 通过精心设计的关键点检测网络 DLA34 [58],我们的网络以 52 FPS 的速度实现了 37.4% 的 COCO AP。配备最先进的关键点估计网络、Hourglass-104 [30,40] 和多尺度测试,我们的网络以 1.4 FPS 的速度实现了 45.1% 的 COCO AP。 在 3D 边界框估计和人体姿态估计方面,我们以更高的推理速度与最先进的技术竞争。
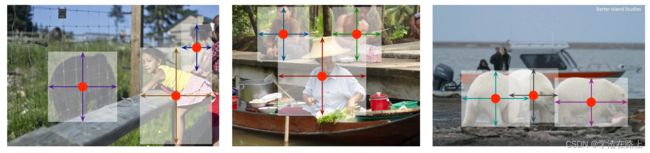
图二 我们将对象建模为其边界框的中心点。 边界框大小和其他对象属性是从中心的关键点特征推断出来的。 最好以彩色观看。
二、相关工作
通过区域分类进行对象检测
第一个成功的深度对象检测器之一RCNN [19],从大量候选区域 [52] 中枚举对象位置,对其进行裁剪,并使用深度网络对每个对象进行分类。 Fast-RCNN [18] 改为裁剪图像特征,以节省计算量。 然而,这两种方法都依赖于缓慢的低级区域提议方法。
使用隐式anchors进行对象检测
Faster RCNN [46] 在检测网络中生成区域提议。它对低分辨率图像网格周围的固定形状边界框(锚)进行采样,并将每个边界框分类为“前景”或“非前景”。 anchors区域与任何真是区域的IOU大于0.7,认为是正样本,小于0.3认为是负样本,负责忽略。每个生成的区域再次被分类[18]。将提议分类器更改为多类分类构成了一级检测器的基础。对一级检测器的一些改进包括anchors形状先验[44、45]、不同的特征分辨率[36]以及不同样本之间的损失重新加权[33]。
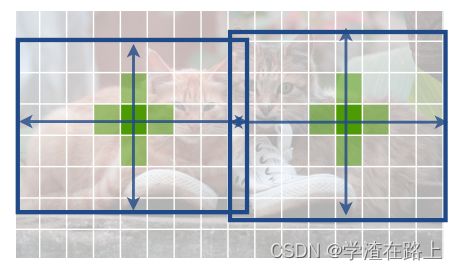
我们的方法与基于anchors的 onestage 方法密切相关 [33,36,43]。中心点可以看作是一个与形状无关的anchors(见图 3)。但是,有一些重要的区别。首先,我们的 CenterNet 仅根据位置分配“anchors”,而不是框重叠 [18]。我们没有用于前景和背景分类的手动阈值 [18]。 其次,我们每个对象只有一个正“锚”,因此不需要非极大值抑制(NMS)[2]。我们只是在关键点热图中提取局部峰值 [4,39]。第三,与传统的目标检测器 [21,22](输出步幅为 16)相比,CenterNet 使用更大的输出分辨率(输出步幅为 4)。这消除了对多个anchors的需要 [47]。
通过关键点估计进行对象检测
我们不是第一个使用关键点估计进行对象检测的人。CornerNet [30] 检测两个边界框角作为关键点,而 ExtremeNet [61] 检测所有对象的顶部、左侧、底部、最右侧和中心点。 这两种方法都建立在与我们的 CenterNet 相同的稳健关键点估计网络上。然而,它们需要在关键点检测之后进行组合分组阶段,这会显着减慢每个算法的速度。另一方面,我们的 CenterNet 只需为每个对象提取一个中心点,而无需分组或后处理。
单目3D物体检测
3D 边界框估计为自动驾驶提供动力 [17]。Deep3Dbox [38] 使用慢速 RCNN [19] 风格框架,首先检测 2D 对象 [46],然后将每个对象输入 3D 估计网络。3D RCNN [29] 为 Faster-RCNN [46] 添加了一个额外的头部,然后是 3D 投影。 Deep Manta [6] 使用经过许多任务训练的从粗到细的 Faster-RCNN [46]。我们的方法类似于 Deep3Dbox [38] 或 3DRCNN [29] 的单阶段版本。因此,CenterNet 比竞争方法更简单、更快。
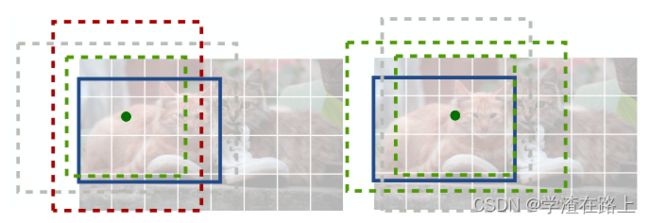
a)基于标准anchors的检测。anchors在与任何对象的重叠 IoU > 0.7 时计为正样本,在重叠 IoU < 0.3 时计为负样本,否则将被忽略。
b)基于中心点的检测。中心像素被分配给对象。附近点的负损失减少。对象大小已回归。
图三 基于锚的检测器 (a) 和我们的中心点检测器 (b) 之间的差异。 最好在屏幕上观看。
三、初步工作
令 I ∈ R W×H×3 ,I为宽度为 W 和高度为 H 的输入图像。我们的目标是生成一个关键点热图 ^ Y ∈ [0,1] W R × H R ×C ,其中 R 是输出步幅,C 是关键点类型的数量。关键点类型包括人体姿态估计中的 C = 17 个人体关节 [4,55],或目标检测中的 C = 80 (COCO数据集)个对象类别 [30,61]。我们在文献 [4,40,42] 中使用 R = 4 的默认输出步幅。 输出步幅通过因子 R 对输出预测进行下采样。预测 ^ Y x,y,c = 1 对应于检测到的关键点,而 ^ Y x,y,c = 0 是背景。 我们使用几种不同的全卷积编解码网络从图像I预测ˆY:叠加沙漏网络[30,40],上卷积残差网络(ResNet)[22,55],和深层聚合(DLA)
我们按照 Law 和 Deng [30] 训练关键点预测网络。对于 c 类的每个地面实况关键点 p ∈ R 2,我们计算一个低分辨率等效项 ∼ p = b p R c。然后,我们使用高斯核
![]()
,其中 σ p 是对象尺寸自适应标准差 [30]。 如果同一类的两个高斯重叠,我们取元素最大值[4]。 训练目标是具有焦点损失的减少惩罚的像素逻辑回归 [33]:
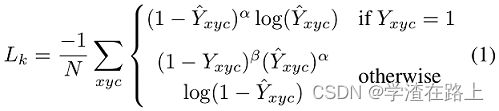
其中 α 和 β 是焦点损失的超参数 [33],N 是图像 I 中关键点的数量。选择 N 的归一化以将所有正焦点损失实例归一化为 1。我们使用 α = 2 和 在我们所有的实验中,β = 4,遵循 Law 和 Deng [30]。
为了恢复由输出步幅引起的离散化误差,我们额外预测了一个局部偏移 ^ O ∈ R W R × H R ×2,对于每个中心点。 所有类 c 共享相同的偏移量预测。 使用 L1 损失训练偏移量

监督仅作用于关键点位置 ~ p,所有其他位置都被忽略。
在下一节中,我们将展示如何将此关键点估计器扩展到通用目标检测器。
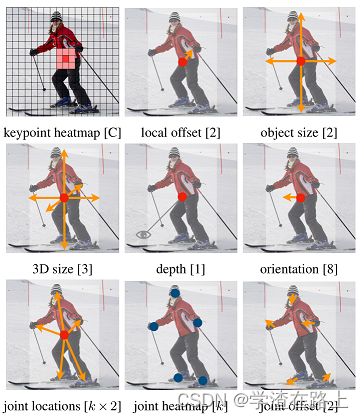
图 4:我们网络针对不同任务的输出:顶部用于对象检测,中间用于 3D 对象检测,底部:用于姿势估计。 所有模态都由一个共同的主干产生,具有不同的 3 × 3 和 1 × 1 输出卷积,由 ReLU 分隔。 括号中的数字表示输出通道。 详见第 4 节。
四、对象作为点
令 (x (k) 1 ,y (k) 1 ,x (k) 2 ,y (k) 2 ) 为类别 c k 的对象 k 的边界框。 它的中心点位于 p k = ( x (k) 1 +x (k) 2 2 , y (k) 1 +y (k) 2 2 )。 我们使用我们的关键点估计器 ^ Y 来预测所有中心点。 此外,我们回归到每个对象 k 的对象大小 s k = (x (k) 2 - x (k) 1 ,y (k) 2 - y (k) 1 )。 为了限制计算负担,我们对所有对象类别使用单个大小预测 ^ S ∈ R W R × H R ×2。 我们在中心点使用 L1 损失,类似于目标 2:

我们不对比例进行归一化,直接使用原始像素坐标。 我们改为按常数 λ size 缩放损失。总体训练目标是
![]()
除非另有说明,否则我们在所有实验中设置 λ size = 0.1 和 λ off = 1。 我们使用单个网络来预测关键点 ^ Y 、偏移 ^ O 和大小 ^ S。网络在每个位置预测总共 C + 4 个输出。 所有输出共享一个通用卷积骨干网络。 对于每种模态,主干的特征然后通过一个单独的 3 × 3 卷积、ReLU 和另一个 1 × 1 卷积。图 4 显示了网络输出的概览。 第 5 节和补充材料包含额外的架构细节。
从点到边界框
在推理时,我们首先独立地提取每个类别的热图中的峰值。 我们检测所有值大于或等于其 8 个连接邻居的响应,并保留前 100 个峰值。 设 ^ P c 是 n 个检测到的中心点的集合 ^ P = {(^ x i , ^ y i )} n i=1 类 c。 每个关键点位置由整数坐标 (x i ,y i ) 给出。 我们使用关键点值 ^ Y x i y i c 作为其检测置信度的度量,并在位置生成一个边界框
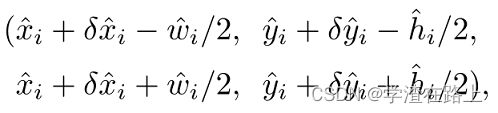
其中 (δ^ x i ,δ^ y i ) = ^ O ^ x i ,^ y i 是偏移预测, (^ w i , ^ h i ) = ^ S ^ x i ,^ y i 是大小预测。 所有输出都是直接从关键点估计产生的,不需要基于 IoU 的非极大值抑制 (NMS) 或其他后处理。 峰值关键点提取可作为 NMS 的充分替代方案,并且可以使用 3 × 3 最大池化操作在设备上有效实现。
4.1 3D检测
3D 检测估计每个对象的 3D 边界框,并且每个中心点需要三个附加属性:深度、3D 维度和方向。 我们为每个人添加一个单独的头。 深度 d 是每个中心点的单个标量。 然而,深度很难直接回归。 我们改为使用 Eigen 等人的输出变换。 [13] 和 d = 1/σ( ^ d) - 1,其中 σ 是 sigmoid 函数。 我们将深度计算为关键点估计器的附加输出通道 ^ D ∈ [0,1] W R × H R。 它再次使用由 ReLU 分隔的两个卷积层。 与以前的模式不同,它在输出层使用反 sigmoidal 变换。 在 S 形变换之后,我们使用原始深度域中的 L1 损失来训练深度估计器。
对象的 3D 维度是三个标量。 我们使用单独的 head ^ Γ ∈ R W R × H R ×3 和 L1 损失直接回归到它们的绝对值(以米为单位)。
默认情况下,方向是单个标量。 但是,它可能很难回归。 我们关注 Mousavian 等人。 [38]并将方向表示为两个带有in-bin回归的bin。具体来说,使用 8 个标量对方向进行编码,每个 bin 有 4 个标量。 对于一个 bin,两个标量用于 softmax 分类,其余两个标量回归到每个 bin 内的一个角度。 有关这些损失的详细信息,请参阅补充。
4.2. 人体姿态估计
人体姿态估计旨在为图像中的每个人体实例估计 k 个 2D 人体关节位置(对于 COCO,k = 17)。 我们将姿势视为中心点的 k × 2 维属性,并通过到中心点的偏移量对每个关键点进行参数化。 我们直接回归到jointoffsets(inpixels) ^ J ∈ R W R × H R ×k×2,损失L1。 我们通过掩盖损失来忽略不可见的关键点。 这导致了一个基于回归的单阶段多人人体姿势估计器,类似于慢速 RCNN 版本的对应物 Toshev 等人。 [51] 和孙等人。 [49]。
为了细化关键点,我们使用标准的自下而上的多人体姿态估计 [4,39,41] 进一步估计 k 个人体关节热图 ^ Φ ∈ R W R × H R ×k。 我们用焦点损失和局部像素偏移来训练人类关节热图,类似于本3节中讨论的中心检测。
然后,我们将初始预测捕捉到此热图上最近检测到的关键点。 在这里,我们的中心偏移作为一个分组提示,将单个关键点检测分配给他们最近的人实例。 具体来说,让 (^ x, ^ y) 为检测到的中心点。 我们首先回归到所有关节位置 l j = (^ x, ^ y) + ^ J ^ x^ yj 对于 j ∈ 1...k。 我们还从对应的热图中提取所有关键点位置 L j = { ∼ l ji } n j i=1,每个关节类型 j 的置信度 > 0.1。然后,我们将每个回归位置 l j 分配给其最近的检测到的关键点 argmin l∈L j (l−l j ) 2 ,仅考虑检测对象边界框内的联合检测。
五、实施细节
我们用 4 种架构进行实验:ResNet-18、ResNet101 [55]、DLA-34 [58] 和 Hourglass-104 [30]。 我们使用可变形卷积层 [12] 修改 ResNets 和 DLA-34,并按原样使用 Hourglass 网络。
Hourglass
沙漏网络 [30, 40] 将输入下采样 4 倍,然后是两个顺序沙漏模块。 每个沙漏模块都是一个具有跳跃连接的对称 5 层上下卷积网络。 这个网络非常大,但通常会产生最佳的关键点估计性能。
ResNet
肖等人 [55] 用三个上卷积网络增强标准残差网络 [22],以允许更高分辨率的输出(输出步幅 4)。 我们首先将三个上采样层的通道分别更改为 256,128,64,以节省计算量。 然后,我们分别在通道 256、128、64 的每个上卷积之前添加一个 3 × 3 可变形卷积层。上卷积核被初始化为双线性插值。有关详细的架构图,请参阅补充。
DLA
深层聚合(DLA)[58]是一个具有分层跳跃连接的图像分类网络。我们利用 DLA 的完全卷积上采样版本进行密集预测,它使用迭代深度聚合来对称地增加特征图分辨率。我们使用从较低层到输出的可变形卷积 [63] 来增加跳跃连接。 具体来说,我们在每个上采样层用 3×3 可变形卷积替换原始卷积。 有关详细的架构图,请参阅补充。
我们在每个输出头之前添加一个 3 × 3 卷积层,256 通道。 最后的 1 × 1 卷积然后产生所需的输出。 我们在补充材料中提供了更多细节。
训练
我们在 512 × 512 的输入分辨率上进行训练。这为所有模型产生了 128×128 的输出分辨率。 我们使用随机翻转、随机缩放(在 0.6 到 1.3 之间)、裁剪和颜色抖动作为数据增强,并使用 Adam [28] 来优化整体目标。 我们不使用增强来训练 3D 估计分支,因为裁剪或缩放会改变 3D 测量值。 对于残差网络和 DLA-34,我们使用 128 的批量大小(在 8 个 GPU 上)和 5e-4 的学习率进行 140 个 epoch 的训练,学习率分别在 90 和 120 个 epoch 下降了 10 倍(遵循 [55 ])。 对于 Hourglass-104,我们遵循ExtremeNet [61] 并使用批量大小 29(在 5 个 GPU 上,主 GPU 批量大小为 4)和学习率 2.5e-4 进行 50 个时期,在 40 时期下降 10 倍学习率 . 对于检测,我们微调了 ExtremeNet [61] 中的 Hourglass-104 以节省计算量。 Resnet101 和 DLA-34 的下采样层使用 ImageNet 预训练初始化,上采样层随机初始化。 Resnet-101 和 DLA-34 在 8 个 TITAN-V GPU 上训练需要 2.5 天,而 Hourglass-104 需要 5 天。
推理
我们使用三个级别的测试增强:无增强、翻转增强、翻转和多尺度(0.5、0.75、1、1.25、1.5)。 对于翻转,我们在解码边界框之前平均网络输出。 对于多尺度,我们使用 NMS 来合并结果。 这些增强会产生不同的速度-准确度权衡,如下一节所示
论文地址
https://arxiv.org/abs/1904.07850
代码
https://github.com/xingyizhou/CenterNet
推荐讲解
扔掉anchor!真正的CenterNet——Objects as Points论文解读 - 知乎
个人理解
这个位置总结一下个人对于有anchors和无anchors的一些理解
有anchors
什么是anchors呢??个人理解就是图像进来经过一系列的卷积,得到很多的特征层,特征层上的每一个点都能够在一定程度上代表原始图像上一块区域的特征,因此只要你选的特征层上的点够多,你就能穷举出原始图像中想要识别出来的目标框,这种将可能的目标框穷举的这种方式就是anchors的核心思想,由于目标尺寸不同呀,可能设计了不同的anchors尺寸,由于目标的大小不同呀,可能在不同的特征图上布置anchors,虽然不同的检测方法anchors的细节不太一样。这种穷举预选框,然后对全部预选框进行分类,然后将分类出来的预选框进非极大值抑制得到最终结果,是整个深度学习有anchors目标检测的核心
以SSD为例吧,个人觉得SSD算是有anchors里第一篇基本思想都出来了的文章

SSD里,当图像进来之后,会进行一系列的卷积,然后在第4、7、8、9、10、11六个特征层上布置anchors,然后将全部的anchors进行分类,再将同一个类别相近的框进行非极大值抑制。整体思路就是穷举、分类、挑最好的。
本文
centernet能做很多事,以目标检测为例

目标检测经过一顿卷,同时得到三个特征图,一个热力图用来定位目标中心点,一个偏置图用来精调中心点坐标,一个尺寸图用来定义目标框宽高,以COCO数据集80个类别,输入图像512*512为例,最后生成的三个特征图尺寸缩放4倍。因此第一个特征图尺寸为1*80*128*128,80对应类别,在特征图上的坐标对应中心点的大致坐标;第二个特征图尺寸为1*160*128*128,160为80个类别*(x,y)两个方向的偏置;第三个特征图尺寸为1*160*128*128,160为80个类别*(w,h);
centernet你说他没有anchors吧,确实是没用anchors,但是他的第一个特征图加上第三个特征图,出来的结果不就类似于anchors,第二个特征图类似进行回归位置的矫正。这个思想真是牛呀
细节说明
损失函数
![]()
针对公式4,λ size = 0.1 和 λ off = 1,最后三个特征图,在损失加和的时候三者的系数还不一样,其中wh的损失系数只有其他两者的十分之一,这点在论文后面有描述,作者通过实验发现这个系数设成0.1会更好一些

网络结构
resdcn34
