NLP预训练模型6 -- 模型轻量化(ALBERT、Q8BERT、DistillBERT、TinyBERT等)
1 背景
模型压缩和加速在工业界应用中十分重要,特别是在嵌入式设备中。压缩和加速在算法层面,大体分为结构设计、量化、剪枝、蒸馏等。本文从这四个方面分析怎么实现BERT轻量化,从而实现BERT模型压缩和加速。
2 结构设计
通过结构设计来实现模型轻量化的手段主要有:权值共享、矩阵分解、分组卷积、分解卷积等。BERT中也广泛使用了这些技术。以ALBERT为例:
矩阵分解:embedding层矩阵分解,分解前参数量 (V * H),分解后(V * E + E * H), 压缩 E/H 倍。
权值共享:ALBERT使用了跨层权值共享方法,不同层的self-attention和fead-forward共享一套参数,压缩率 1/N,N为总层数,典型值为12和24
ALBERT我们放在模型结构优化中进行了分析,这儿就不赘述了,详见 NLP预训练模型5 – 模型结构优化(XLNet、ALBERT、ELECTRA)
3 量化
量化是很通用的模型压缩方法,将32bit浮点压缩为8bit,甚至1bit,可以大大压缩模型体积。我们介绍一篇经典文章 Q8BERT: Quantized 8Bit BERT
论文信息:2019年10月,Intel,NeurIPS 2019
论文地址 https://arxiv.org/abs/1910.06188v2
代码和模型地址 https://github.com/NVIDIA/Megatron-LM
3.1 实现方法
symmetric linear quantization
对称的线性量化,如下面公式

对于8bit量化,M=127
Quantized-Aware Training
采用伪量化,训练时恢复为32bit浮点。
3.2 实验结果
如下所示,作者在GLUE和SQuAD上,对比了32位BERT,和8bit量化后的结果。实验表明量化带来的精度损失很小,大部分在1%以内。但模型体积却可以缩小为原来的1/4。
4 剪枝
剪枝可以分为突触剪枝、神经元剪枝、权重矩阵剪枝等方法。我们介绍一篇权重矩阵剪枝的论文:Are Sixteen Heads Really Better than One?

论文信息:2019年5月,CMU,NeurIPS 2019
论文地址 https://arxiv.org/abs/1905.10650
代码和模型地址 https://github.com/pmichel31415/are-16-heads-really-better-than-1
实现方法
文章深入分析了BERT多头机制中每个头到底有多大用,结果发现很多头其实没啥卵用。他在要去掉的head上,加入mask,来做每个头的重要性分析。
作者先分析了单独去掉每层每个头,WMT任务上bleu的改变。发现,大多数head去掉后,对整体影响不大。如下图所示
然后作者分析了,每层只保留一个最重要的head后,ACC的变化。可见很多层只保留一个head,performance影响不大。如下图所示

由此可见,直接进行权重矩阵剪枝,也是可行的方案。相比突触剪枝和神经元剪枝,压缩率要大很多。
5 蒸馏
利用蒸馏来实现BERT轻量化的论文挺多的,我们重点分析distillBERT和tinyBERT。
5.1 distillBERT

论文信息:2019年10月,HuggingFace,NeurIPS 2019
论文地址 https://arxiv.org/abs/1910.01108
代码和模型地址 https://github.com/huggingface/transformers
distillBERT由大名鼎鼎的HuggingFace出品。主要创新点为:
1、Teacher 12层,student 6层,每两层去掉一层。比如student第二层对应teacher第三层
2、Loss= 5.0Lce+2.0 Lmlm+1.0* Lcos,
1、Lce: soft_label的KL散度
2、Lmlm: mask LM hard_label的交叉熵
3、Lcos:hidden state的余弦相似度
DistilBERT 比 BERT 快 60%,体积比 BERT 小 60%。在glue任务上,保留了 95% 以上的性能。在performance损失很小的情况下,带来了较大的模型压缩和加速效果。
5.2 tinyBERT

论文信息:2019年9月,华为诺亚
论文地址 https://arxiv.org/abs/1909.10351
代码和模型地址 https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
总体结构
重点来看下tinyBERT,它是由华为出品,非常值得深入研究。tinyBERT对embedding层,transformer层(包括hidden layer和attention),prediction层均进行了拟合。如下图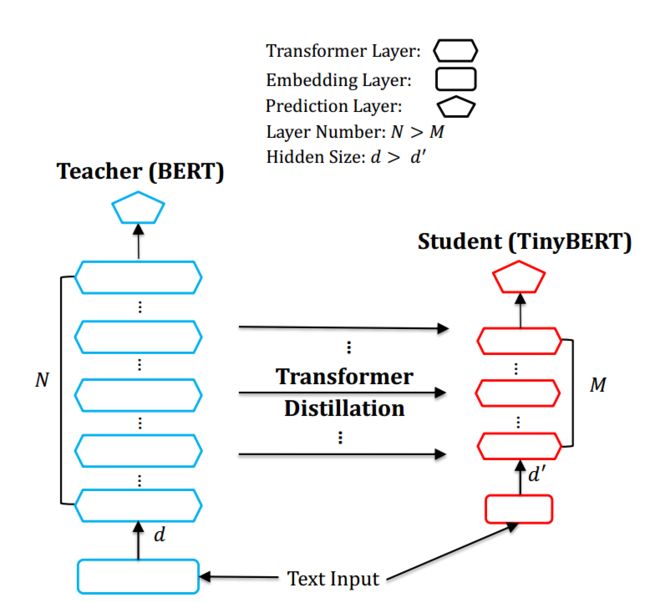
其中Embeddings采用MSE, Prediction采用KL散度, Transformer层的hidden layer和attention,均采用MSE。loss如下

其中m为层数。
效果分析

表2: glue任务上的performance。在glue任务上,可达到bert-base的96%,几乎无损失。
表3: tinyBERT模型大小和推理速度。缩小7.5倍,加速9.4倍。压缩和加速效果十分明显。
消融分析

表6:分析embedding、prediction、attention、hidden layer软标签作用,其中attention和hidden layer作用最大。这个也很好理解,transformer层本来就是整个BERT中最关键的部分。

表7:分析老师学生不同层对应方法的效果,uniform为隔层对应,top为全部对应老师顶部几层,bottom为全部对应老师底部几层。Uniform效果明显好很多。这个也很好理解,浅层可以捕捉低阶特征,深层可以捕捉高阶特征。全是低阶或者高阶显然不合适,我们要尽量荤素搭配。