自然语言处理(二十五):Transformer与torchtext构建语言模型
自然语言处理笔记总目录
Transformer介绍
本案例取自PyTorch官网的LANGUAGE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
首先导入一些包
import math
import torch
from torch import nn
from torch.nn import TransformerEncoder, TransformerEncoderLayer
Step 1:Define the model
nn.TransformerEncoder由多层nn.TransformerEncoderLayer组成,还需要一个正方形的注意掩码,防止未来信息的泄露。将nn.TransformerEncoder的输出直接送入最终的Linear层即是本任务的Decoder,最后在经过softmax函数,这里softmax隐藏在nn.CrossEntropyLoss中
class TransformerModel(nn.Module):
def __init__(self, ntoken, d_model, nhead, d_hid, nlayers, dropout=0.5):
"""
:param ntoken: 词表大小
:param d_model: 词嵌入维度
:param nhead: 头数
:param d_hid: 隐藏层维度
:param nlayers: 编码器层数
:param dropout: dropout
:return:
"""
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(d_model, dropout)
encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, d_model)
self.d_model = d_model
self.decoder = nn.Linear(d_model, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, src_mask):
"""
:param src: Tensor, shape [seq_len, batch_size]
:param src_mask: Tensor, shape [seq_len, seq_len]
:return: output Tensor of shape [seq_len, batch_size, ntoken]
"""
src = self.encoder(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, src_mask)
output = self.decoder(output)
return output
def generate_square_subsequent_mask(sz):
"""生成一个上三角矩阵,主对角线及以下为0,主对角线之上为-inf"""
return torch.triu(torch.ones(sz, sz) * float('-inf'), diagonal=1)
位置编码:
# 和之前写的位置编码的代码几乎是一样的
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化一个绝对位置矩阵,包含词汇的绝对位置,大小为max_len x 1
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
"""
:param x: Tensor, shape [seq_len, batch_size, embedding_dim]
"""
x = x + self.pe[:x.size(0)]
return self.dropout(x)
Step 2:Load and batch data
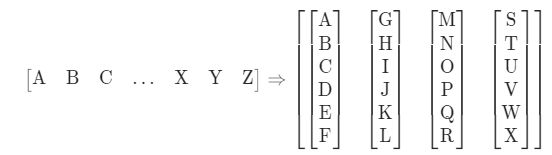
我们将使用torchtext来生成 Wikitext-2 数据集,vocab对象是基于训练数据集构建的,batchify()函数将数据集排列为列,以修剪掉数据分成大小为batch_size的批量后剩余的所有标记,如下图所示
from torchtext.datasets import WikiText2
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
train_iter = WikiText2(split='train') # 训练数据迭代器
tokenizer = get_tokenizer('basic_english') # 基本的英文分词器
vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['' ])
vocab.set_default_index(vocab['' ]) # 设置单词索引,当某个单词不在词汇表中,则返回0
# print(vocab(tokenizer('here is an example'))) # [1291, 23, 30, 617]
def data_process(raw_text_iter):
data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
# print(data_process(['here is an example'])) # tensor([1291, 23, 30, 617])
# train_iter在构建词表的时候用掉了,这里再次创建
train_iter, val_iter, test_iter = WikiText2()
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batchify(data, bsz):
"""
分割数据,并且移除多余数据
:param data: Tensor, shape [N] 文本数据 train_data、val_data、test_data
:param bsz: int, batch_size,每次模型更新参数的数据量
:return: Tensor of shape [N // bsz, bsz]
"""
seq_len = data.size(0) // bsz
data = data[:seq_len * bsz]
data = data.view(bsz, seq_len).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size) # [seq_len, batch_size] 句子是竖着的
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
filter()用法
numel():返回当前tensor中元素的个数
Step 3:Functions to generate input and target sequence
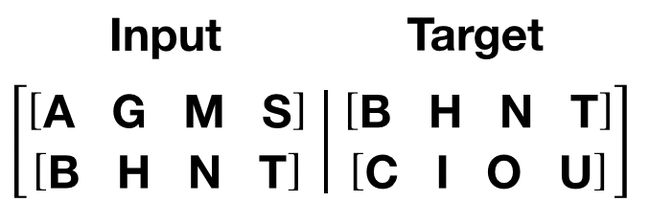
get_batch()函数为转换器模型生成输入和目标序列。 它将源数据细分为长度为bptt的块。 对于语言建模任务,模型需要以下单词作为Target。 例如,如果bptt值为 2,则i = 0时,我们将获得以下两个变量:
# print(train_data.shape) # torch.Size([102499, 20])
# 每个句子长度为102499,明显不科学,我们要限制句子的长度
bptt = 35 # 句子最大长度
def get_batch(source, i):
"""
:param source: Tensor, shape [full_seq_len, batch_size]
:param i: 批次数
:return: tuple (data, target), where data has shape [seq_len, batch_size] and
target has shape [seq_len * batch_size]
"""
# 前面的批次都会是bptt的值, 只不过最后一个批次中
# 句子长度可能不够bptt的35个, 因此会变为len(source) - 1 - i的值
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i + seq_len]
target = source[i + 1:i + 1 + seq_len].reshape(-1)
return data, target
source = test_data
i = 1
data, target = get_batch(source, i)
# print(data.shape) # torch.Size([35, 10])
# print(target.shape) # torch.Size([350])
Step 4:Initiate an instance
# 超参数定义
ntokens = len(vocab) # size of vocabulary
emsize = 200 # embedding dimension
d_hid = 200 # dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # number of heads in nn.MultiheadAttention
dropout = 0.2 # dropout probability
model = TransformerModel(ntokens, emsize, nhead, d_hid, nlayers, dropout).to(device)
Step 5:Run the model
import copy
import time
criterion = nn.CrossEntropyLoss()
lr = 5.0
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.95)
def train(model):
model.train()
total_loss = 0.
log_interval = 200
start_time = time.time()
src_mask = generate_square_subsequent_mask(bptt).to(device)
num_batches = len(train_data) // bptt
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
batch_size = data.size(0)
if batch_size != bptt:
src_mask = src_mask[:batch_size, :batch_size]
output = model(data, src_mask)
loss = criterion(output.view(-1, ntokens), targets)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) # 梯度裁剪
optimizer.step()
total_loss += loss.item()
if batch % log_interval == 0 and batch > 0:
lr = scheduler.get_last_lr()[0]
ms_per_batch = (time.time() - start_time) * 1000 / log_interval
cur_loss = total_loss / log_interval
ppl = math.exp(cur_loss)
print(f'| epoch {epoch:3d} | {batch:5d}/{num_batches:5d} batches | '
f'lr {lr:02.2f} | ms/batch {ms_per_batch:5.2f} | '
f'loss {cur_loss:5.2f} | ppl {ppl:8.2f}')
total_loss = 0
start_time = time.time()
def evaluate(model, eval_data):
model.eval()
total_loss = 0.
src_mask = generate_square_subsequent_mask(bptt).to(device)
with torch.no_grad():
for i in range(0, eval_data.size(0) - 1, bptt):
data, targets = get_batch(eval_data, i)
batch_size = data.size(0)
if batch_size != bptt:
src_mask = src_mask[:batch_size, :batch_size]
output = model(data, src_mask)
output_flat = output.view(-1, ntokens)
total_loss += batch_size * criterion(output_flat, targets).item()
return total_loss / (len(eval_data) - 1)
循环遍历。 如果验证损失是迄今为止迄今为止最好的,保存模型。并在每个周期之后调整学习率。
best_val_loss = float('inf') # 保存最低的loss
epochs = 5
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(model)
val_loss = evaluate(model, val_data)
val_ppl = math.exp(val_loss) # 困惑度,越低越好
elapsed = time.time() - epoch_start_time
print('-' * 89)
print(f'| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | '
f'valid loss {val_loss:5.2f} | valid ppl {val_ppl:8.2f}')
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = copy.deepcopy(model)
scheduler.step()
Out:
| epoch 1 | 200/ 2928 batches | lr 5.00 | ms/batch 36.25 | loss 8.22 | ppl 3721.31
| epoch 1 | 400/ 2928 batches | lr 5.00 | ms/batch 18.66 | loss 6.95 | ppl 1048.14
| epoch 1 | 600/ 2928 batches | lr 5.00 | ms/batch 18.73 | loss 6.48 | ppl 648.89
| epoch 1 | 800/ 2928 batches | lr 5.00 | ms/batch 18.64 | loss 6.32 | ppl 554.08
| epoch 1 | 1000/ 2928 batches | lr 5.00 | ms/batch 18.68 | loss 6.20 | ppl 492.78
| epoch 1 | 1200/ 2928 batches | lr 5.00 | ms/batch 18.77 | loss 6.17 | ppl 475.86
| epoch 1 | 1400/ 2928 batches | lr 5.00 | ms/batch 18.80 | loss 6.12 | ppl 453.58
| epoch 1 | 1600/ 2928 batches | lr 5.00 | ms/batch 18.88 | loss 6.11 | ppl 452.17
| epoch 1 | 1800/ 2928 batches | lr 5.00 | ms/batch 18.74 | loss 6.03 | ppl 416.26
| epoch 1 | 2000/ 2928 batches | lr 5.00 | ms/batch 18.69 | loss 6.02 | ppl 413.09
| epoch 1 | 2200/ 2928 batches | lr 5.00 | ms/batch 18.68 | loss 5.90 | ppl 366.05
| epoch 1 | 2400/ 2928 batches | lr 5.00 | ms/batch 18.76 | loss 5.97 | ppl 392.08
| epoch 1 | 2600/ 2928 batches | lr 5.00 | ms/batch 18.69 | loss 5.96 | ppl 388.64
| epoch 1 | 2800/ 2928 batches | lr 5.00 | ms/batch 18.82 | loss 5.89 | ppl 362.42
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 60.99s | valid loss 5.80 | valid ppl 331.79
-----------------------------------------------------------------------------------------
| epoch 2 | 200/ 2928 batches | lr 4.75 | ms/batch 18.87 | loss 5.88 | ppl 356.48
| epoch 2 | 400/ 2928 batches | lr 4.75 | ms/batch 18.73 | loss 5.86 | ppl 350.79
| epoch 2 | 600/ 2928 batches | lr 4.75 | ms/batch 18.84 | loss 5.67 | ppl 289.74
| epoch 2 | 800/ 2928 batches | lr 4.75 | ms/batch 18.73 | loss 5.70 | ppl 298.65
| epoch 2 | 1000/ 2928 batches | lr 4.75 | ms/batch 18.71 | loss 5.65 | ppl 285.12
| epoch 2 | 1200/ 2928 batches | lr 4.75 | ms/batch 18.76 | loss 5.68 | ppl 291.53
| epoch 2 | 1400/ 2928 batches | lr 4.75 | ms/batch 18.76 | loss 5.69 | ppl 296.89
| epoch 2 | 1600/ 2928 batches | lr 4.75 | ms/batch 18.74 | loss 5.71 | ppl 301.69
| epoch 2 | 1800/ 2928 batches | lr 4.75 | ms/batch 18.74 | loss 5.65 | ppl 283.23
| epoch 2 | 2000/ 2928 batches | lr 4.75 | ms/batch 18.86 | loss 5.66 | ppl 287.13
| epoch 2 | 2200/ 2928 batches | lr 4.75 | ms/batch 18.77 | loss 5.55 | ppl 256.27
| epoch 2 | 2400/ 2928 batches | lr 4.75 | ms/batch 18.72 | loss 5.64 | ppl 280.60
| epoch 2 | 2600/ 2928 batches | lr 4.75 | ms/batch 18.71 | loss 5.64 | ppl 281.32
| epoch 2 | 2800/ 2928 batches | lr 4.75 | ms/batch 18.72 | loss 5.57 | ppl 263.44
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 57.57s | valid loss 5.68 | valid ppl 294.34
-----------------------------------------------------------------------------------------
| epoch 3 | 200/ 2928 batches | lr 4.51 | ms/batch 18.99 | loss 5.60 | ppl 270.62
| epoch 3 | 400/ 2928 batches | lr 4.51 | ms/batch 18.79 | loss 5.63 | ppl 277.79
| epoch 3 | 600/ 2928 batches | lr 4.51 | ms/batch 18.80 | loss 5.42 | ppl 226.29
| epoch 3 | 800/ 2928 batches | lr 4.51 | ms/batch 18.78 | loss 5.48 | ppl 239.64
| epoch 3 | 1000/ 2928 batches | lr 4.51 | ms/batch 18.75 | loss 5.43 | ppl 228.49
| epoch 3 | 1200/ 2928 batches | lr 4.51 | ms/batch 18.70 | loss 5.48 | ppl 239.29
| epoch 3 | 1400/ 2928 batches | lr 4.51 | ms/batch 18.75 | loss 5.48 | ppl 240.92
| epoch 3 | 1600/ 2928 batches | lr 4.51 | ms/batch 18.76 | loss 5.51 | ppl 246.19
| epoch 3 | 1800/ 2928 batches | lr 4.51 | ms/batch 18.77 | loss 5.47 | ppl 236.52
| epoch 3 | 2000/ 2928 batches | lr 4.51 | ms/batch 18.72 | loss 5.47 | ppl 238.51
| epoch 3 | 2200/ 2928 batches | lr 4.51 | ms/batch 18.78 | loss 5.35 | ppl 210.82
| epoch 3 | 2400/ 2928 batches | lr 4.51 | ms/batch 19.11 | loss 5.46 | ppl 235.03
| epoch 3 | 2600/ 2928 batches | lr 4.51 | ms/batch 18.75 | loss 5.47 | ppl 236.98
| epoch 3 | 2800/ 2928 batches | lr 4.51 | ms/batch 18.73 | loss 5.39 | ppl 220.22
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 57.65s | valid loss 5.61 | valid ppl 273.44
-----------------------------------------------------------------------------------------
| epoch 4 | 200/ 2928 batches | lr 4.29 | ms/batch 18.89 | loss 5.43 | ppl 229.22
| epoch 4 | 400/ 2928 batches | lr 4.29 | ms/batch 18.75 | loss 5.46 | ppl 235.84
| epoch 4 | 600/ 2928 batches | lr 4.29 | ms/batch 18.77 | loss 5.27 | ppl 194.07
| epoch 4 | 800/ 2928 batches | lr 4.29 | ms/batch 18.75 | loss 5.33 | ppl 205.91
| epoch 4 | 1000/ 2928 batches | lr 4.29 | ms/batch 18.71 | loss 5.28 | ppl 197.32
| epoch 4 | 1200/ 2928 batches | lr 4.29 | ms/batch 18.60 | loss 5.32 | ppl 205.38
| epoch 4 | 1400/ 2928 batches | lr 4.29 | ms/batch 18.51 | loss 5.35 | ppl 210.13
| epoch 4 | 1600/ 2928 batches | lr 4.29 | ms/batch 18.49 | loss 5.38 | ppl 217.76
| epoch 4 | 1800/ 2928 batches | lr 4.29 | ms/batch 18.47 | loss 5.33 | ppl 206.47
| epoch 4 | 2000/ 2928 batches | lr 4.29 | ms/batch 18.52 | loss 5.33 | ppl 207.32
| epoch 4 | 2200/ 2928 batches | lr 4.29 | ms/batch 18.47 | loss 5.20 | ppl 182.16
| epoch 4 | 2400/ 2928 batches | lr 4.29 | ms/batch 18.48 | loss 5.32 | ppl 203.72
| epoch 4 | 2600/ 2928 batches | lr 4.29 | ms/batch 18.48 | loss 5.33 | ppl 205.98
| epoch 4 | 2800/ 2928 batches | lr 4.29 | ms/batch 18.68 | loss 5.26 | ppl 193.05
-----------------------------------------------------------------------------------------
| end of epoch 4 | time: 57.06s | valid loss 5.55 | valid ppl 256.44
-----------------------------------------------------------------------------------------
| epoch 5 | 200/ 2928 batches | lr 4.07 | ms/batch 18.59 | loss 5.30 | ppl 201.26
| epoch 5 | 400/ 2928 batches | lr 4.07 | ms/batch 18.47 | loss 5.33 | ppl 207.39
| epoch 5 | 600/ 2928 batches | lr 4.07 | ms/batch 18.55 | loss 5.14 | ppl 170.04
| epoch 5 | 800/ 2928 batches | lr 4.07 | ms/batch 18.49 | loss 5.20 | ppl 180.89
| epoch 5 | 1000/ 2928 batches | lr 4.07 | ms/batch 18.50 | loss 5.17 | ppl 175.22
| epoch 5 | 1200/ 2928 batches | lr 4.07 | ms/batch 18.49 | loss 5.21 | ppl 183.48
| epoch 5 | 1400/ 2928 batches | lr 4.07 | ms/batch 18.51 | loss 5.23 | ppl 186.35
| epoch 5 | 1600/ 2928 batches | lr 4.07 | ms/batch 18.54 | loss 5.27 | ppl 194.44
| epoch 5 | 1800/ 2928 batches | lr 4.07 | ms/batch 18.50 | loss 5.22 | ppl 184.42
| epoch 5 | 2000/ 2928 batches | lr 4.07 | ms/batch 18.51 | loss 5.23 | ppl 186.21
| epoch 5 | 2200/ 2928 batches | lr 4.07 | ms/batch 18.53 | loss 5.09 | ppl 161.85
| epoch 5 | 2400/ 2928 batches | lr 4.07 | ms/batch 18.55 | loss 5.21 | ppl 182.69
| epoch 5 | 2600/ 2928 batches | lr 4.07 | ms/batch 18.47 | loss 5.23 | ppl 186.25
| epoch 5 | 2800/ 2928 batches | lr 4.07 | ms/batch 18.48 | loss 5.16 | ppl 173.32
-----------------------------------------------------------------------------------------
| end of epoch 5 | time: 56.74s | valid loss 5.54 | valid ppl 255.56
-----------------------------------------------------------------------------------------
Step 6:Evaluate the best model on the test dataset
# 测试集
test_loss = evaluate(best_model, test_data)
test_ppl = math.exp(test_loss)
print('=' * 89)
print(f'| End of training | test loss {test_loss:5.2f} | '
f'test ppl {test_ppl:8.2f}')
print('=' * 89)
Out:
=========================================================================================
| End of training | test loss 5.46 | test ppl 234.79
=========================================================================================