基于sklearn的鸢尾花分类模型
1、鸢尾花数据获取及查看
可以通过sklearn直接获取数据集:
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
data = load_iris()
print(data)可以查看data中包含的信息,这里我们需要用到的是data,以及target信息。
# 提取鸢尾花数据的特征以及标签
## 数据集主要包含四维特征 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'
train = data["data"]
label = data["target"]输入两维信息查看数据的分布情况,这里我选择的是'sepal length', 'petal length':
# 选取两维数据查看数据的分布
for i in range(len(train)):
if label[i]==0:
plt.scatter([train[i][0]], [train[i][2]],c="r")
elif label[i]==1:
plt.scatter([train[i][0]], [train[i][2]],c="g")
else:
plt.scatter([train[i][0]], [train[i][2]],c="b")
plt.show()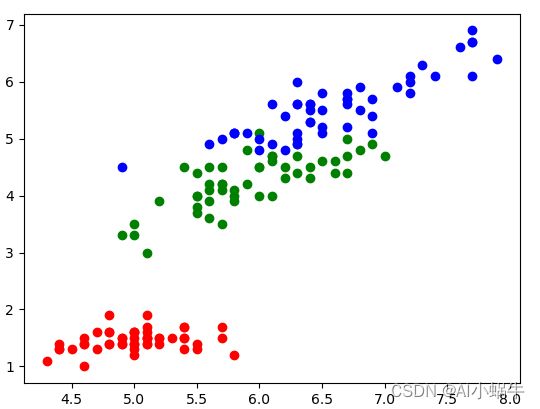
可以看到,基本上这两维特征就能把鸢尾花的数据分开,因此利用四维数据是可以把三种类型的画分开。
2、构建鸢尾花分类模型
对于数据来说,需要划分数据集,分为测试集与训练集:
from sklearn.model_selection import train_test_split
# 划分数据集 这里选择测试集为 20%
data_train,data_test, target_train,target_test = \
train_test_split(train,label,test_size = 0.2,random_state = 22)
对数据进行标准化,将特征划分到0~1区间上,这样便于我们提取特征:
from sklearn.preprocessing import StandardScaler
# 对数据进行标准化
stdScaler = StandardScaler().fit(data_train)
train = stdScaler.transform(data_train)
test = stdScaler.transform(data_test)
(1)SVM
构建SVM模型,这里我没有选择参数,用最基本的模型,对于一些参数的选择,可以查看sklearn库的一些信息选择:
from sklearn.svm import SVC
svm = SVC().fit(train,target_train)
## 预测训练集结果
target_pred = svm.predict(test)
print(target_pred)
true = np.sum(target_pred == target_test )
print('预测结果准确率为:', true/target_test.shape[0])
结果如下:
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
预测结果准确率为: 0.9666666666666667(2)决策树(DT)
from sklearn.tree import DecisionTreeClassifier
DT = DecisionTreeClassifier().fit(train,target_train)
## 预测训练集结果
target_pred = DT.predict(test)
print(target_pred)
true = np.sum(target_pred == target_test )
print('预测结果准确率为:', true/target_test.shape[0])结果如下:
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 1]
预测结果准确率为: 0.9(3)朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB().fit(train,target_train)
## 预测训练集结果
target_pred = nb.predict(test)
print(target_pred)
true = np.sum(target_pred == target_test )
print('预测结果准确率为:', true/target_test.shape[0])结果如下:
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
预测结果准确率为: 0.9666666666666667