如何制作数据集并基于yolov5训练成模型并部署
如何制作数据集并基于yolov5训练成模型
一个正常的视觉AI开发步骤如下:收集和组织图像、标记您感兴趣的对象、训练模型、将其部署到云端/当做一个端口
文章目录
- 如何制作数据集并基于yolov5训练成模型
-
- 一、搜集图片
-
- 1、下载已有的数据集
- 2、使用自己拍摄的图片
- 3、在网站上使用爬虫爬取图片
- 二、标注图片
-
- 1、在线标注网站MAKE SENSE的介绍
- 2、创建标签
- 3、使用MAKE SENSE网站标注并导出
- 三、制作数据集
-
- 1、创建mydata文件夹
- 2、将之前的图片以及标注数据放入mydata文件夹
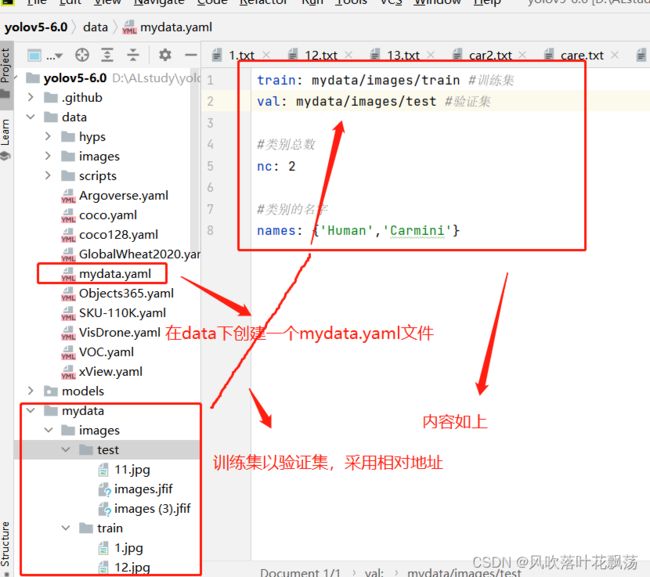
- 3、新建一个mydata.yaml文件,
- 四、基于数据集训练模型
-
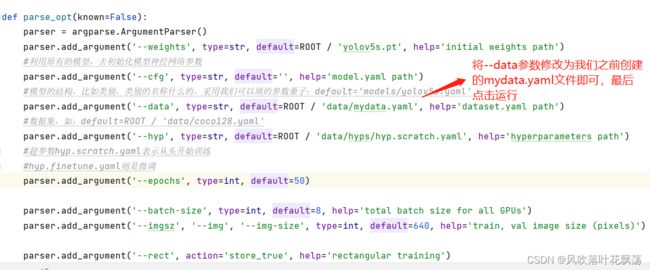
- 1、修改train.py中data参数
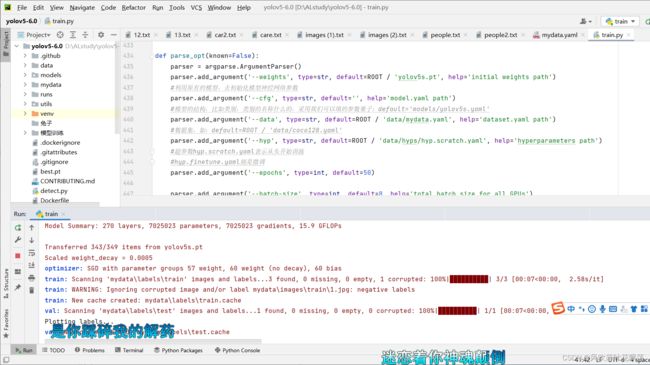
- 2、开始根据制作好的数据集训练模型
- 3、模型训练结束
- 五、部署模型
-
- 1、保存刚刚训练的模型的相对地址
- 2、在detect.py中调用模型
- 3、检测正常运行结果如下
- 六、将yolov5部署在云端或做为一个端口被其他程序调用
-
- 1、基于ros机器人的物体检测
- 2、部署到微信小程序
- 3、部署到安卓/苹果上的APP上
一、搜集图片
1、下载已有的数据集
如果出于学习,或者应用范围比较广泛,对鲁棒性要求较高,可以使用一些
公开的数据集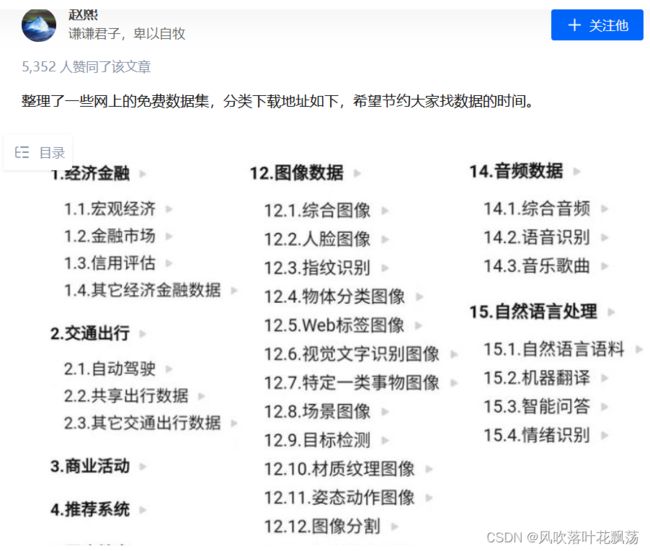
知乎地址:https://zhuanlan.zhihu.com/p/25138563
当然这只是公开数据集的一部分,大家可以继续检索到。
其他搜集的找数据集的网站
1.datafountain
https://www.datafountain.cn/datasets
2.聚数力
http://dataju.cn/Dataju/web/searchDataset
3.中文NLP数据集搜索
https://www.cluebenchmarks.com/dataSet_search.html
4.阿里云天池
https://tianchi.aliyun.com/dataset/?spm=5176.12282016.J_9711814210.24.2c656d92n0Us6s
5.谷歌数据集好像要
2、使用自己拍摄的图片
将拍摄的目标图片全部保存在电脑上
3、在网站上使用爬虫爬取图片
下面是使用爬虫下载图片的代码
import os
import sys
import time
import urllib
import requests
import re
from bs4 import BeautifulSoup
import time
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
url = "https://cn.bing.com/images/async?q={0}&first={1}&count={2}&scenario=ImageBasicHover&datsrc=N_I&layout=ColumnBased&mmasync=1&dgState=c*9_y*2226s2180s2072s2043s2292s2295s2079s2203s2094_i*71_w*198&IG=0D6AD6CBAF43430EA716510A4754C951&SFX={3}&iid=images.5599"
def getImage(url, count):
'''从原图url中将原图保存到本地'''
try:
time.sleep(0.5)
urllib.request.urlretrieve(url, './imgs/hat' + str(count + 1) + '.jpg')
except Exception as e:
time.sleep(1)
print("本张图片获取异常,跳过...")
else:
print("图片+1,成功保存 " + str(count + 1) + " 张图")
def findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx, count):
'''从缩略图列表页中找到原图的url,并返回这一页的图片数量'''
soup = BeautifulSoup(html, "lxml")
link_list = soup.find_all("a", class_="iusc")
url = []
for link in link_list:
result = re.search(rule, str(link))
#将字符串"amp;"删除
url = result.group(0)
#组装完整url
url = url[8:len(url)]
#打开高清图片网址
getImage(url, count)
count += 1
#完成一页,继续加载下一页
return count
def getStartHtml(url, key, first, loadNum, sfx):
'''获取缩略图列表页'''
page = urllib.request.Request(url.format(key, first, loadNum, sfx),
headers=header)
html = urllib.request.urlopen(page)
return html
if __name__ == '__main__':
name = "戴帽子" #图片关键词
path = './imgs/hat' #图片保存路径
countNum = 2000 #爬取数量
key = urllib.parse.quote(name)
first = 1
loadNum = 35
sfx = 1
count = 0
rule = re.compile(r"\"murl\"\:\"http\S[^\"]+")
if not os.path.exists(path):
os.makedirs(path)
while count < countNum:
html = getStartHtml(url, key, first, loadNum, sfx)
count = findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx,
count)
first = count + 1
sfx += 1
二、标注图片
1、在线标注网站MAKE SENSE的介绍
MAKE SENSE
make-sense 是一个被YOLOv5官方推荐使用的图像标注工具。
相比于其他工具,make-sense的上手难度非常低,仅需数分钟,玩家便能熟练掌握工作台中的功能选项,快速地进入工作状态;此外,由于make-sense是一款web应用,各个操作系统的玩家可打破次元壁实现工作协同。
2、创建标签
新建一个名为labels的文件,按照每行为一个标签的原则,依次输入
栗子如下:

3、使用MAKE SENSE网站标注并导出
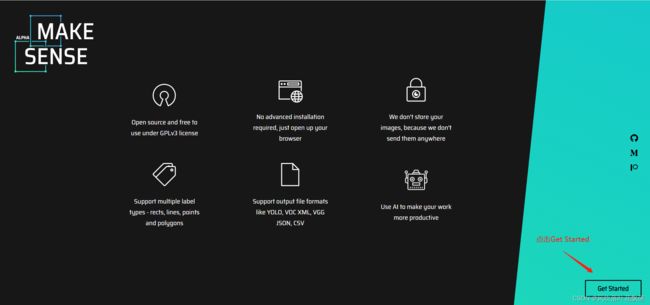
打开网站
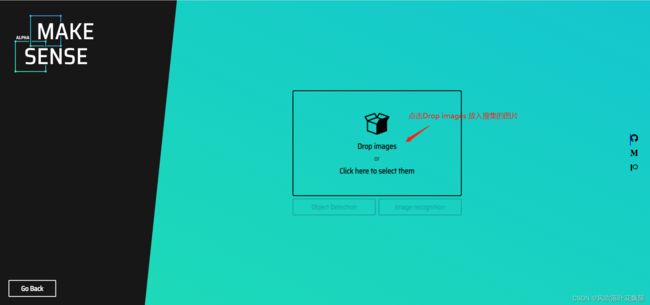
点击放入图片
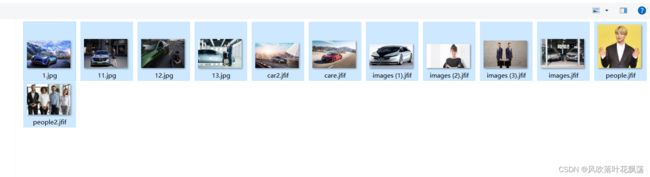
全选搜集到的图片并确认
根据标注需求点击对应的,在这里我们点击物体检测

点击Load labels from file。表示从文件中批量导入标签
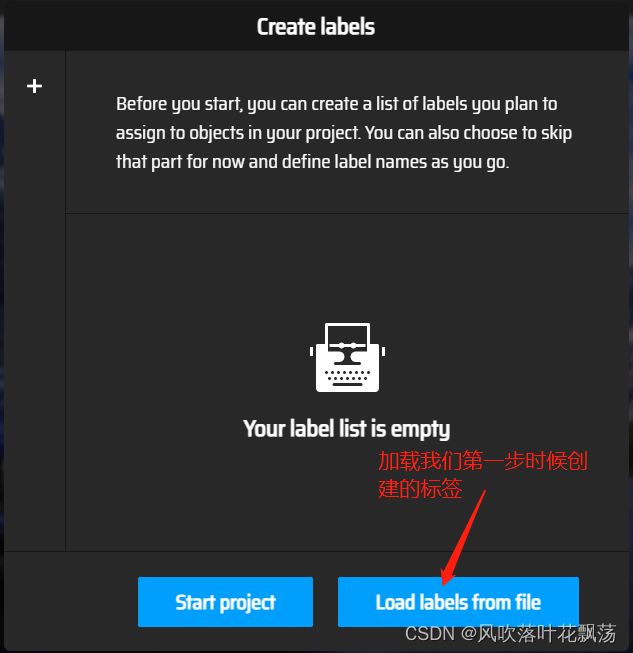
放入后点击Create labels list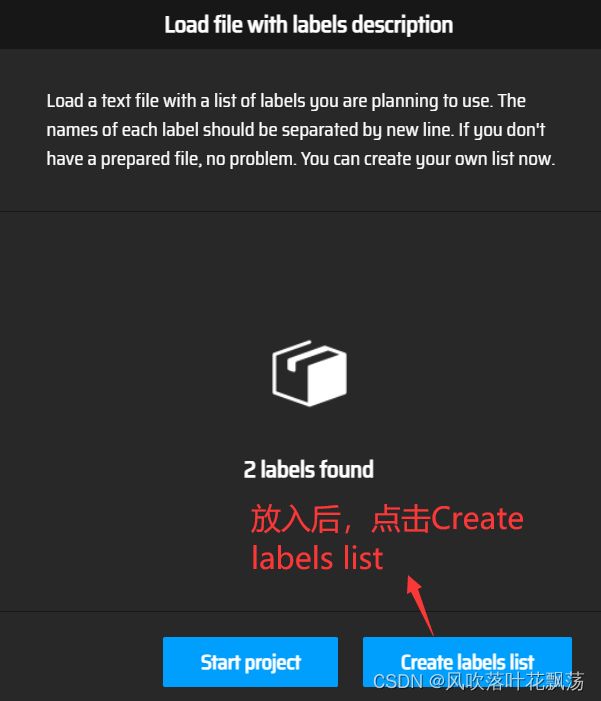
最后点击开始项目,就可以开始标注了
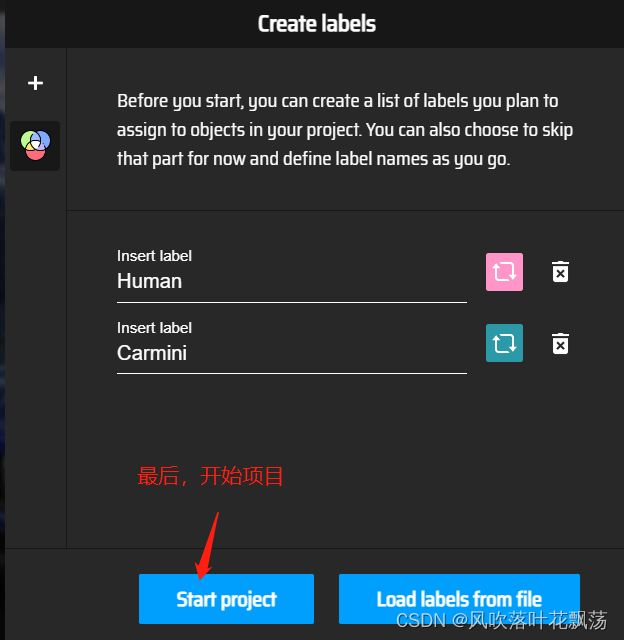
依次标注每一个图片
导出标注结果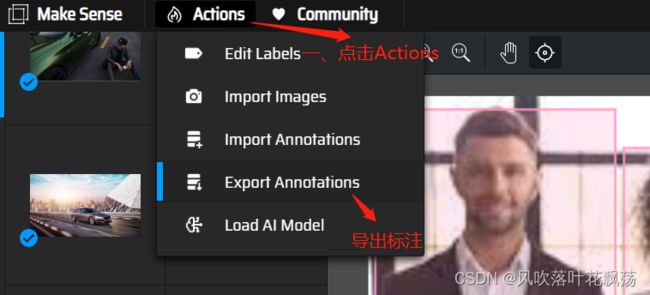
选择导出格式,并导出
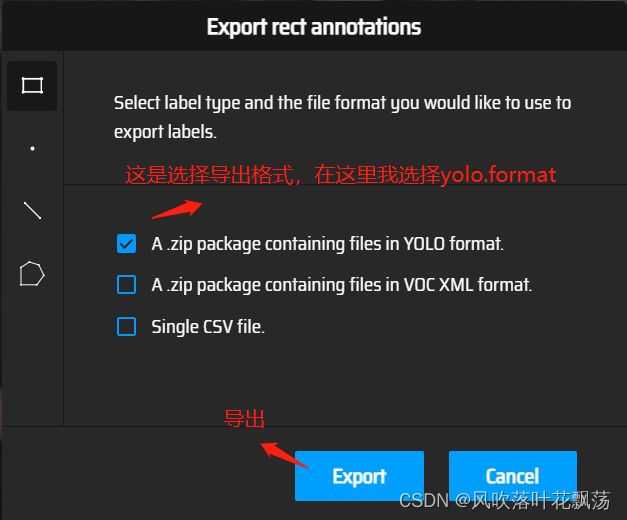
导出压缩包参考如下:
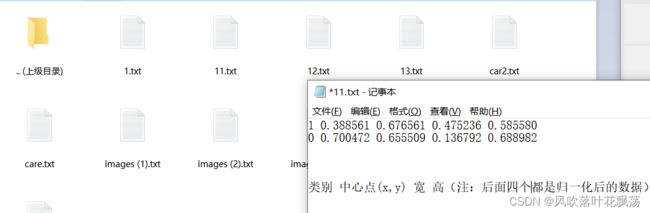
到这里图片与标签就都准备好了,可以准备开始制作数据集
三、制作数据集
1、创建mydata文件夹
创建文件夹mydata
其内部构造如下
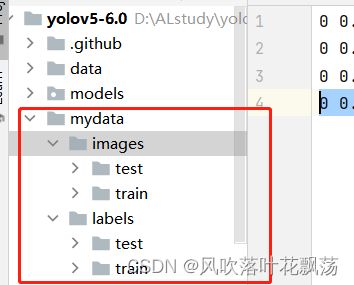
2、将之前的图片以及标注数据放入mydata文件夹
test与train集合一般比例为2:8或3:7
例子如下:
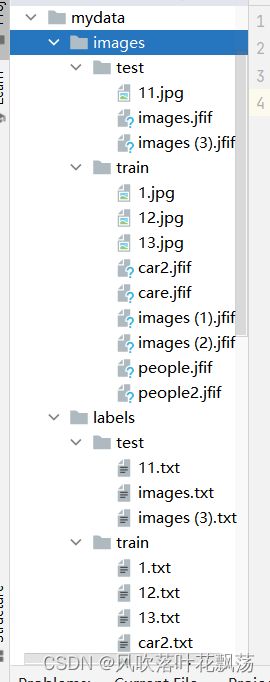
3、新建一个mydata.yaml文件,
四、基于数据集训练模型
1、修改train.py中data参数
2、开始根据制作好的数据集训练模型
3、模型训练结束
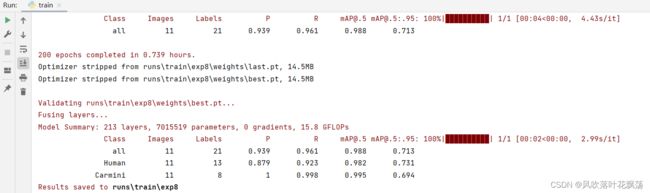
注:由上图可以看到这次训练的模型保存在runs/train/exp6
参数介绍
P Precision,精确率
对类A来说(下面提到的都是被预测成A的):
P = 正确数 / 预测总数
或 P = 正确数/ 正确数+错误数
即,预测的东西正确了多少百分比。
R Recall,召回率
对类A来说(下面提到的都是被归为A类的):
R = 预测正确数 / 真实A类总数。
或 R = 预测正确数 / 被预测到的A + 未被预测到的A
即,预测的东西找到了多少百分比。
[email protected]:mean Average Precision
即将IoU设为0.5时,计算每一类的所有图片的AP(可以理解为识别精度),然后所有类别求平均,即mAP
[email protected]:0.95:mean Average Precision
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
五、部署模型
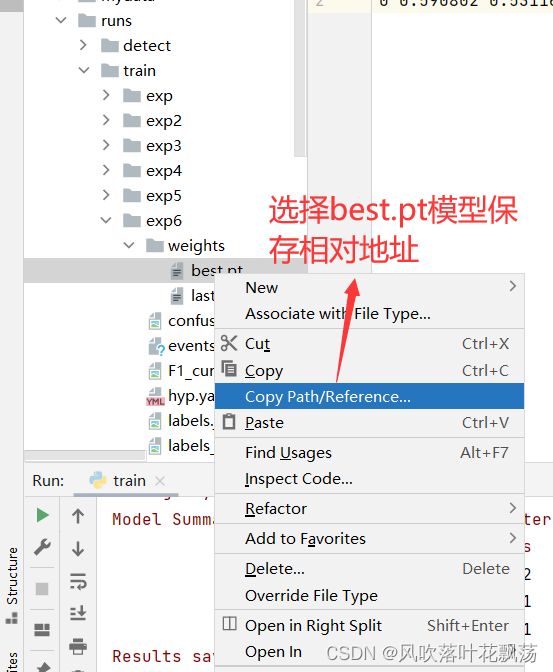
1、保存刚刚训练的模型的相对地址
2、在detect.py中调用模型
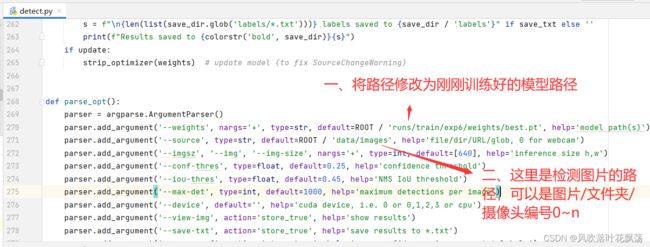
注:由于我们的数据集很少很少只是用来做示范的,可能没检测出什么,这不是步骤问题,只是量太少而已。
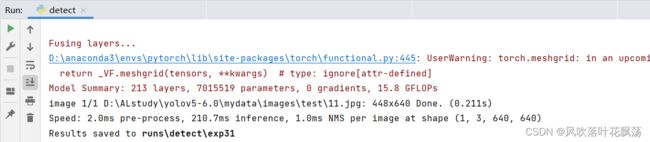
3、检测正常运行结果如下
六、将yolov5部署在云端或做为一个端口被其他程序调用
1、基于ros机器人的物体检测
2、部署到微信小程序
3、部署到安卓/苹果上的APP上
注:这三部分,还在学习,在之后会补上开源源码以及代码解析。