对抗样本(对抗攻击)入门
什么是对抗样本?
从2013年开始,深度学习模型在多种应用上已经能达到甚至超过人类水平,比如人脸识别,物体识别,手写文字识别等等。 在之前,机器在这些项目的准确率很低,如果机器识别出错了,没人会觉得奇怪。但是现在,深度学习算法的效果好了起来,去研究算法犯的那些不寻常的错误变得有价值起来。其中一种错误叫对抗样本(adversarial examples)。
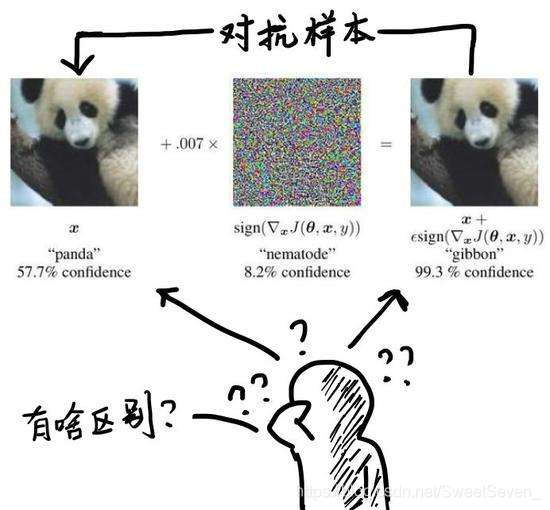
对抗样本(Adversarial examples)是指为了发现某些不被人们注意的特征而使最大化模型的损失函数,从而在数据集中通过故意添加细微的干扰(往往是人类肉眼所无法察觉的干扰)所形成的输入样本,会导致模型以高置信度给出一个错误的输出。
在图像识别中,可以理解为原来被一个卷积神经网络(CNN)分类为一个类(比如“熊猫”)的图片,经过非常细微甚至人眼无法察觉的改动后,突然被误分成另一个类(比如“长臂猿”)。
对抗样本存在的普遍性
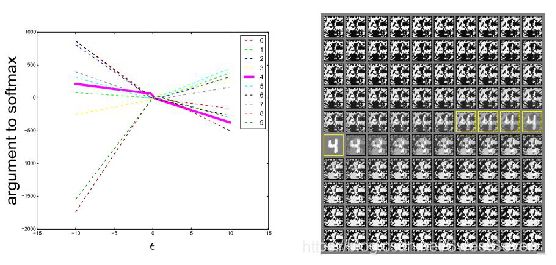
上图表明,在不同的 ϵ 下,可以看到FGSM可以在一维的连续子空间内产生对抗样本,而不是特定的区域。
体现在
(1)对抗样本普遍存在于各种神经网络模型
(2)同样的对抗样本集会对由不同网络训练出的模型造成干扰
(3)也会对由不同数据集相同网络训练出的模型造成干扰。
出现这种普遍性的原因在于:
不论是以什么数据集和神经网络训练出的分类器都具有泛化能力,所以分类器可以在训练集的不同子集上训练出大致相同的分类权重。底层分类权重的稳定性反过来又会导致对抗样本中的稳定性。
为什么会产生对抗样本?
用模型训练分类问题的时候,目标是如何更好的分类,所以模型会尽量扩大样本和boundary之间的距离,扩大每一个class区域的空间。这样做的好处是让分类更容易,但坏处是也在每一个区域里包括了很多并不属于这个class的空间。
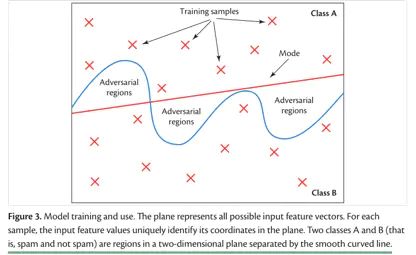
产生对抗样本的原因并不是过拟合,而是图像特征维度太高还有模型过于线性,神经网络所学到的模型不能在高维空间完全泛化。否则不可能广泛的存在于各个神经网络训练出的模型中。
简单来说就是在二维三维空间上属于一个类别的多个物品,在四维以及更高维的空间可能属于不同类别。所以如果神经网络在低于特征维度的空间内学到的模型,很可能在更高维的空间内并不成立。而在低维空间被分类成同一类,在高维空间不再属于这个类的样本,就属于对抗样本。
进一步来说,在高维空间,每个像素值只需要非常小的改变,这些改变会通过和线性模型的参数进行点乘累计造成很明显的变化。而图片通常都有极高的维度,所以不需要担心维度不够。也就是说,只要方向正确,图像只要迈一小步,而在特征空间上是一大步,就能大程度的跨越决策层。
那么,很多人会有疑问,深度学习模型也是以为太线性了?深度学习的精髓不就是那些非线性激活函数吗,如果没有非线性的激活函数,再深再多层的网络和一个单层的线性模型也什么区别,也就不可能这么有效果而被广泛使用了。
虽然激活函数它们都是非线性函数,但却都一定程度上是线性的,比如现在最流行的relu,有一半是线性的,再回想以前流行的sigmoid函数或者tanh函数,都是希望输入值落在中间接近线性的部分而不是两边斜率接近0的部分,防止梯度消失。这也是为什么relu能取代之前sigmoid的原因,更稳定快速的训练。
其实仔细一想可以明白,深度模型本实确实是一个非常非线性的模型,但是模型能的组成部分都是线性的,全连接网络的矩阵乘法是线性的,卷积网络的卷积计算也是计算点乘,线性的,还有序列模型用到LSTM用的是最简单的加法,更是线性的。
注意,我们可以说深度学习模型从输入到输出的映射是线性的,但是从模型的参数到输出的映射不是线性的,因为每层的参数,权重矩阵是相乘得到的,这也是深度学习模型不好训练的原因之一,参数和输出的非线性关系。所以针对优化输入的优化问题要比针对模型参数的优化问题要容易得多。
入门需要阅读的论文
- 近两周需要看的paper -- 具体的攻击防御方法
-
攻击方法
-
白盒--常见的对抗攻击算法
-
单步
-
L-BFGS
-
https://arxiv.org/abs/1312.6199
-
-
FGSM
-
https://arxiv.org/abs/1412.6572
-
-
-
迭代
-
BIM
-
https://arxiv.org/abs/1607.02533
-
-
JSMA
-
https://arxiv.org/abs/1511.07528
-
-
DeepFool
-
https://arxiv.org/abs/1511.04599
-
-
-
...
-
-
黑盒--先了解白盒攻击方法
-
one-pixel attack
-
https://arxiv.org/abs/1710.08864
-
-
...
-
-
-
需要了解的一些平台
百度的代码可读性高一些,可是模型集合度有一些少
IBM代码可读性最低,但是包含了很多种类的攻击方法,还有防御和对抗训练,以及评价鲁棒性的方法
cleverhans的可读性适中,包含的模型多于百度少于IBM
大家可以根据自己的情况慢慢进行代码的阅读,上面提到的论文下面的平台中都包含有源码。有更多的读论文需求的朋友也可以先根据下面平台中包含的模型来找对应的论文看。
-
百度
-
advbox
-
https://github.com/advboxes/AdvBox
-
-
perceptron
-
https://github.com/advboxes/perceptron-benchmark
-
-
-
cleverhans
-
https://github.com/tensorflow/cleverhans
-
-
foolbox
-
https://github.com/bethgelab/foolbox
-
-
IBM
-
ART -- 对抗性鲁棒性
-
https://github.com/IBM/adversarial-robustness-toolbox
-
-
-
朱军--realsafe平台
-
说是开源,但是找不到资源
-
-
朱军团队--迁移性更好的对抗攻击方法
-
Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks
-
https://github.com/dongyp13/Translation-Invariant-Attacks
-
-
西交大沈超 DeltaBox – A Sandbox for Deep Learning Testing in Adversarial Environments
-
非开源平台
-
包含主流的深度学习对抗样本攻防算法
-
支持自动化测试,提供多种评测指标
-
深度学习模型可视化解释功能,协助分析对抗样本的攻防方法作用机理
-
支持用户自定义模型,同时提供用户图形界面及API调用支持
-
-
EvadeML-Zoo
-
https://github.com/mzweilin/EvadeML-Zoo
-
提供了常用数据集和预训练模型
-
提供常用攻击与防御算法
-
提供对抗样本的可视化
-
比较古老
-