近端梯度下降
近端梯度下降
1. 问题模型
目标函数: m i n f ( x ) = g ( x ) + h ( x ) min f(x)=g(x)+h(x) minf(x)=g(x)+h(x)
目标函数 f ( x ) f(x) f(x)为非光滑可导的目标函数,可以将其分为两部分, g ( x ) g(x) g(x)为凸的光滑可导的函数 h ( x ) h(x) h(x)为凸的非光滑可导的函数。通过解这两个子问题,得到 f ( x ) f(x) f(x)的最优解。
2.基本概念
2.1 投影算子
投影算子 p r o x f : R n → R n prox_f: R^n → R^n proxf:Rn→Rn 定义为:
![]()
可以直观地理解为,希望找到一个 x x x既要最小化 f ( x ) f(x) f(x),又希望 x x x尽可能地与 v v v点接近
如果加入缩放因子 λ \lambda λ,投影算子的定义为:
f ( x ) = 1 / 2 x T A x + b T x + c f(x)=1/2 x^T Ax+b^T x+c f(x)=1/2xTAx+bTx+c
- f ( x ) = 1 / 2 x T A x + b T x + c f(x)=1/2 x^T Ax+b^T x+c f(x)=1/2xTAx+bTx+c
p r o x λ f ( v ) = a r g m i n x ( 1 / 2 x T A x + b T x + c + 1 / 2 λ ∣ ( ∣ x − v ∣ ) ∣ 2 2 ) prox_λf (v)=argmin_x (1/2 x^T Ax+b^T x+c+1/2λ |(|x-v|)|_2^2) proxλf(v)=argminx(1/2xTAx+bTx+c+1/2λ∣(∣x−v∣)∣22)
当 f ( x ) + 1 / 2 λ ∣ ( ∣ x − v ∣ ) ∣ 2 2 f(x)+1/2λ |(|x-v|)|_2^2 f(x)+1/2λ∣(∣x−v∣)∣22的梯度为0时,得到 f f f在 v v v点的投影:
x = ( I + λ A ) − 1 ( v − λ b ) x=(I+λA)^{-1} (v-λb) x=(I+λA)−1(v−λb) - f ( x ) = ∣ x ∣ f(x)=|x| f(x)=∣x∣
p r o x λ f ( v ) = a r g m i n x ( ∣ x ∣ + 1 / 2 λ ∣ ( ∣ x − v ∣ ) ∣ 2 2 ) prox_λf (v)=argmin_x (|x|+1/2λ |(|x-v|)|_2^2) proxλf(v)=argminx(∣x∣+1/2λ∣(∣x−v∣)∣22)
利用软阈值算子:

- f ( x ) = I C ( x ) f(x)=I_C (x) f(x)=IC(x)
.
I C ( x ) I_C (x) IC(x)为集合C上的指示函数,如果 x ∈ C , I C ( x ) = 0 x∈C,I_C (x)=0 x∈C,IC(x)=0,如果 x ∉ C , I C ( x ) = + ∞ x∉C,I_C (x)=+∞ x∈/C,IC(x)=+∞
2.2 Lipschitz连续
如果 ∇ f ∇f ∇f是Lipschitz连续的,那么满足
∣ ∣ ∇ f ( x ) − ∇ f ( y ) ∣ ∣ 2 ≤ L ∣ ∣ x − y ∣ ∣ 2 , ∀ x , y ||∇f(x)- ∇f(y)||_2≤L||x-y| |_2, ∀x,y ∣∣∇f(x)−∇f(y)∣∣2≤L∣∣x−y∣∣2,∀x,y
对一维情况来说,有
∣ ∇ f ( x ) − ∇ f ( y ) ∣ ≤ L ∣ x − y ∣ |∇f(x)-∇f(y)|≤L|x-y| ∣∇f(x)−∇f(y)∣≤L∣x−y∣
则, ∣ ∇ f ( x ) − ∇ f ( y ) ∣ / ∣ x − y ∣ ≤ L |∇f(x)-∇f(y)|/|x-y| ≤L ∣∇f(x)−∇f(y)∣/∣x−y∣≤L
取极限 l i m y → x lim y→x limy→x得, ∣ ∇ 2 f ( x ) ∣ ≤ L |∇^2 f(x)|≤L ∣∇2f(x)∣≤L
根据Taylor展开式得到
f ( x ) ≤ f ( u ) + ∣ ∇ f ( u ) ∣ T ( x − u ) + L / 2 ∣ ∣ x − u ∣ ∣ 2 2 f(x)≤f(u)+|∇f(u)|^T (x-u)+L/2 ||x-u||_2^2 f(x)≤f(u)+∣∇f(u)∣T(x−u)+L/2∣∣x−u∣∣22
左式在u附近的极值点可近似为右式在u附近的极值点
3. 近端梯度下降
目标: m i n f ( x ) = g ( x ) + h ( x ) min f(x)=g(x)+h(x) minf(x)=g(x)+h(x)
迭代更新公式: x ( k ) = p r o x t k h ( x ( k − 1 ) − t k ∇ g ( x ( k − 1 ) ) ) x^{(k)}=prox_{t_k h} (x^{(k-1)}-t_k ∇g(x^{(k-1)} )) x(k)=proxtkh(x(k−1)−tk∇g(x(k−1)))
( t k > 0 t_k>0 tk>0 为步长,为常数或利用线性搜索法确定)
3.1 算法推导
若有 t ≤ 1 / L t≤1/L t≤1/L,若 ∇ g ( x ) ∇g(x) ∇g(x)是满足lipschitz连续的,有
f ( x ) = h ( x ) + g ( x ) ≤ h ( x ) + g ( x k ) + ∇ g ( x k ) T ( x − x k ) + L / 2 ∣ ∣ x − x k ∣ ∣ 2 2 ≤ h ( x ) + g ( x k ) + ∇ g ( x k ) T ( x − x k ) + 1 / 2 t ∣ ∣ x − x k ∣ ∣ 2 2 \begin{aligned} f(x)&=h(x)+g(x)\\ &≤h(x)+g(x^k )+∇g(x^k )^T (x-x^k )+L/2 ||x-x^k ||_2^2 \\ &≤h(x)+g(x^k )+∇g(x^k )^T (x-x^k )+1/2t ||x-x^k ||_2^2 \end{aligned} f(x)=h(x)+g(x)≤h(x)+g(xk)+∇g(xk)T(x−xk)+L/2∣∣x−xk∣∣22≤h(x)+g(xk)+∇g(xk)T(x−xk)+1/2t∣∣x−xk∣∣22
x k + 1 = a r g m i n x ( h ( x ) + g ( x k ) + ∇ g ( x k ) T ( x − x k ) + 1 / 2 t ∣ ∣ x − x k ∣ ∣ 2 2 ) x^{k+1}=argmin_x (h(x)+g(x^k )+∇g(x^k )^T (x-x^k )+1/2t ||x-x^k ||_2^2 ) xk+1=argminx(h(x)+g(xk)+∇g(xk)T(x−xk)+1/2t∣∣x−xk∣∣22)
f ( x ) f(x) f(x)在 x k x^k xk附近的极值点 x k + 1 x^{k+1} xk+1可近似为左端这个目标函数在 x k x^k xk附近的极值点
x k + 1 = a r g m i n x ( h ( x ) + g ( x k ) + ∇ g ( x k ) T ( x − x k ) + 1 / 2 t ∣ ∣ x − x k ∣ ∣ 2 2 ) = a r g m i n x ( h ( x ) + t / 2 ∣ ∣ ∇ g ( x k ) ∣ ∣ 2 2 + ∇ g ( x k ) T ( x − x k ) + 1 / 2 t ∣ ∣ x − x k ∣ ∣ 2 2 ) = a r g m i n x ( h ( x ) + 1 / 2 t ∣ ∣ x − x k + t ∇ g ( x k ) ∣ ∣ 2 2 ) = p r o x t h ( x k − t ∇ g ( x k ) ) \begin{aligned} x^{k+1}&=argmin_x (h(x)+g(x^k )+∇g(x^k )^T (x-x^k )+1/2t ||x-x^k ||_2^2)\\ & =argmin_x (h(x)+t/2 ||∇g(x^k )||_2^2+∇g(x^k )^T (x-x^k )+1/2t ||x-x^k ||_2^2)\\ & =argmin_x (h(x)+1/2t ||x-x^k+t∇g(x^k )||_2^2)\\ & =prox_{th} (x^k-t∇g(x^k )) \end{aligned} xk+1=argminx(h(x)+g(xk)+∇g(xk)T(x−xk)+1/2t∣∣x−xk∣∣22)=argminx(h(x)+t/2∣∣∇g(xk)∣∣22+∇g(xk)T(x−xk)+1/2t∣∣x−xk∣∣22)=argminx(h(x)+1/2t∣∣x−xk+t∇g(xk)∣∣22)=proxth(xk−t∇g(xk))
x k + 1 x^{k+1} xk+1 可近似为 h ( x ) h(x) h(x)在 x k − t ∇ g ( x k ) x^k-t∇g(x^k ) xk−t∇g(xk)处的投影
3.2 具体算法
由于lipschitz常量 L L L通常未知,我们无法确定一个小于等于 1 / L 1/L 1/L的固定步长 t t t,因此我们利用线性搜索确定步长,迭代过程可以表示为
given x k x^k xk, t k − 1 t^{k-1} tk−1,parameter β ∈ ( 0 , 1 ) β∈(0,1) β∈(0,1)
let t ≔ t ( k − 1 ) t≔t^(k-1) t:=t(k−1)
Repeat
z ≔ p r o x λ h ( x k − t ∇ g ( x k ) ) z≔prox_λh (x^k-t∇g(x^k )) z:=proxλh(xk−t∇g(xk))
break if g ( z ) ≤ g ( x k ) + ∇ g ( x k ) T ( z − x k ) + 1 / 2 t ∣ ∣ z − x k ∣ ∣ 2 2 g(z)≤g(x^k )+∇g(x^k )^T (z-x^k )+1/2t ||z-x^k ||_2^2 g(z)≤g(xk)+∇g(xk)T(z−xk)+1/2t∣∣z−xk∣∣22
update t ≔ β t t≔βt t:=βt
Return t k ≔ t , x k + 1 ≔ z t^k≔t,x^{k+1}≔z tk:=t,xk+1:=z
g ( z ) ≤ g ( x k ) + ∇ g ( x k ) T ( z − x k ) + 1 / 2 t ∣ ∣ z − x k ∣ ∣ 2 2 g(z)≤g(x^k )+∇g(x^k )^T (z-x^k )+1/2t ||z-x^k ||_2^2 g(z)≤g(xk)+∇g(xk)T(z−xk)+1/2t∣∣z−xk∣∣22保证的是推导过程中这一步成立(个人理解)
3.3 例子1
h ( x ) = I C ( x ) h(x)=I_C (x) h(x)=IC(x)
p r o x λ h ( x k − t ∇ g ( x k ) ) = a r g m i n x ∈ C ∣ ∣ x − ( x k − t ∇ g ( x k ) ) ∣ ∣ 2 2 prox_λh (x^k-t∇g(x^k ))=argmin_{x∈C}||x-(x^k-t∇g(x^k ))||_2^2 proxλh(xk−t∇g(xk))=argminx∈C∣∣x−(xk−t∇g(xk))∣∣22
首先根据 g ( x ) g(x) g(x)的负梯度方向找到使 g ( x ) g(x) g(x)最小的迭代点 x g k x_g^k xgk,然后找 h ( x ) h(x) h(x)在 x g k x_g^k xgk的投影,由于 h ( x ) h(x) h(x)为集合 C C C上的指示函数,其投影算子可以表示为这个函数,表明新的迭代点不能走出集合 C C C这个区域,当 g ( x ) g(x) g(x)上的在 x k x^k xk附近的极值点 x k + 1 x^{k+1} xk+1超出集合 C C C时,它将会重新投影到集合 C C C上。
3.4 加速的近端梯度算法
加入中间变量 y k y^k yk,不是直接对 x k x^k xk求近邻,而是对 y k y^k yk求近邻
given x k , t k − 1 x^k,t^{k-1} xk,tk−1,parameter β ∈ ( 0 , 1 ) β∈(0,1) β∈(0,1)
let t ≔ t ( k − 1 ) t≔t^(k-1) t:=t(k−1)
Repeat
w k = k / ( k + 3 ) w^k=k/(k+3) wk=k/(k+3)
y k ≔ x k + w k − 1 ( x k − x k − 1 ) y^k≔x^k+w^{k-1} (x^k-x^{k-1}) yk:=xk+wk−1(xk−xk−1)
z ≔ p r o x λ h ( y k − t ∇ g ( y k ) ) z≔prox_{λh} (y^k-t∇g(y^k )) z:=proxλh(yk−t∇g(yk))
break if g ( z ) ≤ g ( y k ) + ∇ g ( y k ) T ( z − y k ) + 1 / 2 t ∣ ∣ z − y k ∣ ∣ 2 2 g(z)≤g(y^k )+∇g(y^k )^T (z-y^k )+1/2t ||z-y^k ||_2^2 g(z)≤g(yk)+∇g(yk)T(z−yk)+1/2t∣∣z−yk∣∣22
update t ≔ β t t≔βt t:=βt
Return t k ≔ t , x ( k + 1 ) ≔ z t^k≔t,x^(k+1)≔z tk:=t,x(k+1):=z
3.5 例子2——LASSO回归问题
m i n f ( x ) = 1 / 2 ∣ ∣ A x − b ∣ ∣ 2 2 + p ∣ ∣ x ∣ ∣ 1 minf(x)=1/2 ||Ax-b||_2^2+p||x||_1 minf(x)=1/2∣∣Ax−b∣∣22+p∣∣x∣∣1
x g k = x k − 1 − t ∇ g ( x k − 1 ) = x k − 1 − t A T ( A x k − 1 − b ) x k = p r o x t k h ( x g k ) = a r g m i n x ( p ∣ ∣ x ∣ ∣ 1 + 1 / 2 t ∣ ∣ x − x g k ∣ ∣ 2 2 ) x_g^k=x^{k-1}-t∇g(x^{k-1})=x^{k-1}-tA^T (Ax^{k-1}-b)\\ x^{k}=prox_{t_k h} (x_g^{k})=argmin_x (p||x||_1+1/2t ||x-x_g^{k}||_2^2) xgk=xk−1−t∇g(xk−1)=xk−1−tAT(Axk−1−b)xk=proxtkh(xgk)=argminx(p∣∣x∣∣1+1/2t∣∣x−xgk∣∣22)
求解第二个方程时用到了软阈值,
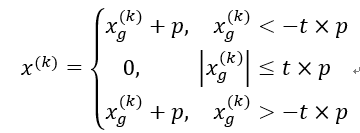
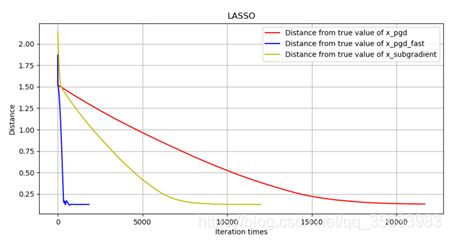
实验结果:
加速的近端梯度下降算法比近端梯度下降算法的速度快了很多,同时,我们同次梯度算法的效果进行了对比,发现快速近端梯度下降算法的收敛速度优势十分明显。
4. 结论
对于凸函数 h ( x ) h(x) h(x),其近端投影 p r o x h t prox_{ht} proxht有解析解; p r o x h t prox_{ht} proxht仅仅依赖于 h h h,因此可以被用于不同的 g g g函数; g g g可以使任意复杂的函数,只要我们能计算其梯度;很多目标函数虽然是凸的,但是可能不可导,通过寻找投影可以解的其最优解,比次梯度法可能具有更好的收敛特性。