千万级数据清洗ETL设计方案
千万级数据清洗项目分析总结
- 项目简介
-
- 一、需求分析
-
- 1. 前期需求
- 2. 中期需求
- 3. 后期需求
- 二、技术支持
-
- 1. MySQL
- 2. Redis
- 三、框架设计
-
- 1. 流线型代码
- 2. 工厂模式
- 四、调式工作
-
- 1. 线上测试
- 五、问题回顾
-
- 1. Mysql使用问题
- 2. Reids使用问题
- 3. 设计思路问题
- 关注收藏不迷路,持续更新
距离上次写博客已经过去好几个月了,中间其实还是有大量的时间去写博客的,但还是应为比较懒,就没写,毕竟咱也不是要成为吸粉的博主,每日更新比较基础的知识嘛,要整就整点有难度的,这才过瘾嘛。

现在看看之前自己的一些博客,讲的东西确实比较适合基础薄弱的同学,但是毕竟大家来CSDN,肯定还是想找到自己解决不了的问题的答案嘛,与其到处去搬运别人写好的资料,还不如自己找个时间认认真真的思考一下最近的几个月都干了什么,毕竟前有温故而知新,后有学而不思则罔嘛。
项目简介
这个项目只是目前大项目中的一个需求而已,数据清洗在企业中的作用不言而喻,用户能否正确的看到网站的信息,全靠着对从各个渠道获取到的数据进行整理的需求。不同的数据量所需要的技术支持自然是不同的,对于才几十万或者上百的数据量,可能自己写一个简单的类,使用几个方法去格式化就搞定了。但是对于从不同渠道,不同格式的数据源,数据量上千万的处理需求来说,就必须使用一套能稳定输出的框架设计方案。
一、需求分析
1. 前期需求
项目刚接手的时候,要求其实还没多高,只不过是需要对于不同的数据源进行单独的处理和统一格式化,项目还处于初期设计,数据量也不是很全,所有当时只需要一个类,其中在写几个方法即可,包括但不限于,数据库获取原始数据、数据筛选、数据格式化、数据去重、数据入库。

2. 中期需求
项目进行了一两个月后,第一版比较完整的数据从各个网站获取下来了,这里所说的完整是对于前期设计的数据库中的所有表,都已经有数据存在。这是的需求就开始提高了,虽然还是提取数据、筛选、格式化、去重数据,但是使用之前的流线型代码(后面会讲到)已经不能满足日常的功能需求了,必须要对代码进行重构,这里就需要使用工厂模式(后面会讲到)。

3. 后期需求
到了后期项目临近上线,需要进行大量的环境测试,则需要在不同的环境下的数据清洗,都能产出一样的数据,包括但不限于,线上环境、线下环境、测试环境等。在保证数据稳定输出的前提下,也要保证不同的环境在同时进行数据清洗时获取到的数据是相同的,同时面临的数据备份,数据库表设计等优化使用的问题(后面会讲到)。
二、技术支持
1. MySQL
因为数据的来源和结构基本是不一样的,好一点的网站,返回的数据源就是json格式,而比较差的网站,返回的数据格式则都是HTML,这对于数据的统一保存是个大问题。

所以我们在设计表字段的时候,没有将所需要的字段一一列出,而是将整个完整的原始数据存入一个字段中,在数据清洗的时候从该字段中格式化出需要的字段,这样就解决了不同数据源相同格式存入数据库的需求。需要注意的是,不同的表的不同数据必须要有一个标识来判断数据的来源,对于后面的ETL数据清洗有着非常重要的作用。
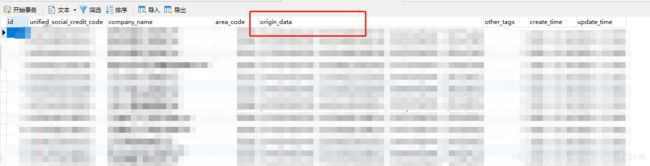
设计数据表的时候还需要预留一两个备用字段(other_tags…),避免重复修改表结构的情况出现。
2. Redis
redis的使用涉及的东西就比较多了,目前整个清洗流程中用到的几个功能大概有:
- 缓存临时数据,减少数据库查询压力
- 不同数据的清洗结果计数
- 数据去重
- 任务结束标识
- 查询数据库使用的缓存下标(用于程序断开后能继续从断开处继续执行)

这里在使用的过程中,还是存在着比较严重的问题的,也是因为前期的清洗设计没有设计好导致,具体问题会在下面的redis使用中讲解。
三、框架设计
1. 流线型代码
流线型代码就是最为普通的代码结构了,属于一个类中完成多个功能,所有功能耦合性高,代码串行,不易调式,不易走读,一步错步步错。这样的代码适用于比较小的项目,只要保证代码能跑起来,捕捉到异常,不会中断程序即可(这种代码不能用于生产),大家可以想想自己的代码是不是这样的,最明显的特征就是串行。

2. 工厂模式
工厂模式大家应该听得还是比较多的,现实的项目中用的也会比较多,无论是大的项目还是小的项目,从工厂模式基本都能套的上,主要的特征就是OOP,通过面向对象的设计,功能独立开,低耦合,易读、易维护,可扩展性强。
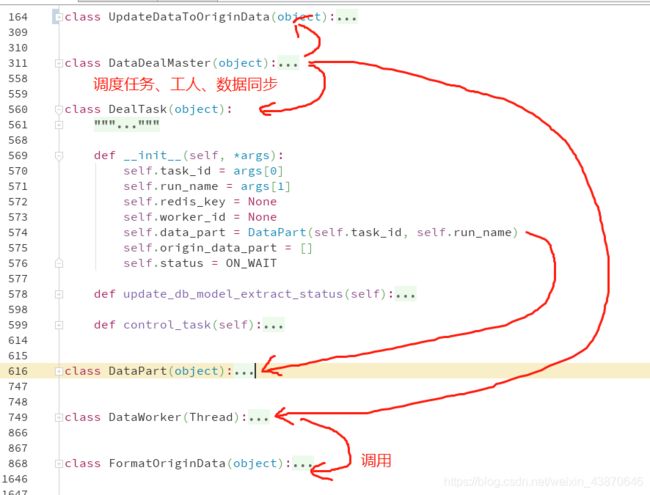
我这边的清洗项目所目前使用的就是工厂模式,拥有六个类,分别是Master类,Task类,Worker类,DataPart类,FormatData类,Update类。
- Master类主要用于任务的分配和工人的调度,当然还是有一些附加的功能如:初始化工人、任务、数据库、redis等;
- Task类主要是任务的调度,判断任务是否完成以及更新任务的状态;
- Worker类主要是工人做工,从任务类中拿到数据包后进行加工数据;
- DataPaet类主要是从数据库中获取数据包,将数据包,数据包则由Task类进行分配;
- FormatData类主要负责将原始数据进行粗加工再细加工,最后筛选、格式化、去重,返回业务数据,由Worker类进行调用;
- Update类主要是进行数据的更新和同步,数据至少需要有两份,一份用于业务需求,一份备份保存。
四、调式工作
1. 线上测试
回顾整个项目的编写,除了主程序ETL的代码,加上其他的几个调用文件代码,加起来不过五千多行。但是整个项目花了大概两个月的时间才稳定下来。平均一天才写一百来行,通过这两个月的项目设计和持续优化,让我明白了什么叫花60%的时间思考,20%的时间写代码,20%的时间调式。

从项目初期到现在,用很多地方的代码写了删,删了又写,反反复复,浪费了大量的时间,这就是典型的没有想明白就开始动手写代码。用在测试上的时间远远大于思考逻辑和写代码的时间,这是相当要命的事情,如果代码的逻辑流程,思考的完善,那么代码写起来是很快的,也不会有遗漏的地方,最怕的就是写一点,调式一下,再写一点,再调式一下,不仅容易漏掉重要的逻辑,所消耗的时间成本也是巨大的,再次引以为戒。
五、问题回顾
1. Mysql使用问题
mysql在使用中遇到的问题如下:
-
查询数据库句法问题,查询语句虽不复杂,但是查询的量大;
在使用sql语句时,一次性将整个数据库表的内容读到内存中是既不安全和不可靠的,一来内存使用太高影响性能,二来程序中断数据丢失不安全。
-
DDL事务为提交,倒是出现数据库表锁;
MYSQL未配置autocommit=1时,所有事务需要进行手动的commit,而数据清洗程序,需要进行大量的查询,更新,提交操作,则更需要注意事务的提交,当使用sql使用不当,导致查询时间较长,又未进行提交时,其他的所有表操作都得等到表锁释放,从而堵塞。
-
数据库表设计问题,导致数据库单表压力巨大
当数据量不是很大的时候,我们将数据存放在一张表中当然是没有问题的,但是现在的数据量达到上千万,内存将近7G,那么数据库的设计和索引设计就尤为关键。
2. Reids使用问题
redis使用问题主要集中在把redis当作数据库使用,如果在单节点,将大量的数据存入redis中,则会导致数据无法继续存入,若触发redis的数据淘汰机制,则会删除最先入库的数据,从而使用失败。

现在则必须重新规范使用redis,大量的数据需要进行存储和处理时,建议使用链式结构,一边消耗一边存入,并给所使用的队列设置阈值,保证redis的正常使用。
3. 设计思路问题
从最开始的设计,我这边就存在问题,并没有准确的判断出后面需要处理的数据量以及mysql、redis使用上的问题,导致项目至今重构了三次。虽然一次比一次更加的完善和健壮,但是消耗的时间成本也是巨大的,尽量不要再使用流线型的代码处理任何需求,认真思考需求以及后期可能遇到的问题,使用60% 的时间去思考和设计框架,编写开发文档和逻辑流程图,当这些准备工作完成之后,再写代码那还不是信手拈来。
关注收藏不迷路,持续更新
