机器学习笔记之EM算法(四)广义EM
机器学习笔记之EM算法——广义EM
- 引言
-
- 回顾:引如隐变量与EM算法的本质
- 狭义EM与广义EM
-
- 回顾:狭义EM算法
- 狭义EM算法的问题
引言
上一节介绍了引入隐变量的本质,本节将狭义EM算法推广至广义EM算法。
回顾:引如隐变量与EM算法的本质
引入EM算法本质上是基于频率学派的思想,针对概率模型 P ( X ∣ θ ) P(\mathcal X \mid \theta) P(X∣θ)中模型参数 θ \theta θ的估计问题。
learning 问题。
找到这个最优模型参数 θ ^ \hat \theta θ^的底层逻辑是极大似然估计(Maximum Likelihood Estimate,MLE):
θ ^ = arg max θ log P ( X ∣ θ ) \hat \theta = \mathop{\arg\max}\limits_{\theta} \log P(\mathcal X \mid \theta) θ^=θargmaxlogP(X∣θ)
但通常情况是:如果将 P ( X ∣ θ ) P(\mathcal X \mid \theta) P(X∣θ)看成概率模型,那么该概率模型产生的真实样本 X \mathcal X X过于复杂,导致使用极大似然估计无法有效地求出最优解析解 θ ^ \hat \theta θ^。
针对这种情况,我们需要对 P ( X ∣ θ ) P(\mathcal X \mid \theta) P(X∣θ)做出一些假设:假设存在概率模型 P ( Z ) P(\mathcal Z) P(Z),真实样本 X \mathcal X X是以概率模型 P ( Z ) P(\mathcal Z) P(Z)的条件下产生出来的。数学符号表达即:
P ( X ∣ Z ) P(\mathcal X \mid \mathcal Z) P(X∣Z)
概率图表示为:
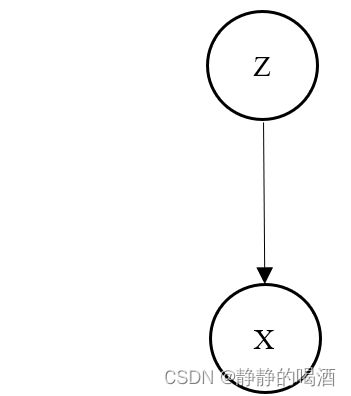
由于 P ( Z ) P(\mathcal Z) P(Z)是人为假设的概率分布,从而可以将原始的概率模型 P ( X ) P(\mathcal X) P(X)转化为关于真实样本 X \mathcal X X,隐变量 Z \mathcal Z Z的混合概率模型 P ( X , Z ) P(\mathcal X,\mathcal Z) P(X,Z):
P ( X , Z ) = P ( X ∣ Z ) P ( Z ) P(\mathcal X,\mathcal Z) = P(\mathcal X \mid \mathcal Z)P(\mathcal Z) P(X,Z)=P(X∣Z)P(Z)
从而可以通过概率模型 P ( Z ) P(\mathcal Z) P(Z)作为媒介,将复杂的样本分布 P ( X ∣ θ ) P(\mathcal X \mid \theta) P(X∣θ)求解出来:
P ( X ) = ∫ Z P ( X , Z ) d Z = E Z [ P ( X , Z ) ] P(\mathcal X) = \int_{\mathcal Z} P(\mathcal X,\mathcal Z)d\mathcal Z = \mathbb E_{\mathcal Z}\left[P(\mathcal X,\mathcal Z)\right] P(X)=∫ZP(X,Z)dZ=EZ[P(X,Z)]
狭义EM与广义EM
回顾:狭义EM算法
在确立了目标函数: log P ( X ∣ θ ) \log P(\mathcal X \mid \theta) logP(X∣θ)之后,我们将隐变量 Z \mathcal Z Z引入,对目标函数进行展开:
详细的展开过程见传送门,这里就不赘述了。
log P ( X ∣ θ ) = log P ( X , Z ∣ θ ) − log P ( Z ∣ X , θ ) = log P ( X , Z ∣ θ ) − log Q ( Z ) − [ log P ( Z ∣ X , θ ) − log Q ( Z ) ] = log P ( X , Z ∣ θ ) Q ( Z ) − log P ( Z ∣ X , θ ) Q ( Z ) \begin{aligned} \log P(\mathcal X \mid \theta) & = \log P(\mathcal X,\mathcal Z \mid \theta) - \log P(\mathcal Z \mid \mathcal X,\theta) \\ & = \log P(\mathcal X,\mathcal Z \mid \theta) - \log \mathcal Q(\mathcal Z) - [\log P(\mathcal Z \mid \mathcal X,\theta) - \log \mathcal Q(\mathcal Z)] \\ & = \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)} - \log \frac{P(\mathcal Z \mid \mathcal X,\theta)}{\mathcal Q(\mathcal Z)} \end{aligned} logP(X∣θ)=logP(X,Z∣θ)−logP(Z∣X,θ)=logP(X,Z∣θ)−logQ(Z)−[logP(Z∣X,θ)−logQ(Z)]=logQ(Z)P(X,Z∣θ)−logQ(Z)P(Z∣X,θ)
同时对等式左右两端基于 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)求解期望:
等式左端:
E Q ( Z ) [ log P ( X ∣ θ ) ] = ∫ Z Q ( Z ) log P ( X ∣ θ ) d Z = log P ( X ∣ θ ) ∫ Z Q ( Z ) d Z = log P ( X ∣ θ ) \begin{aligned} \mathbb E_{\mathcal Q(\mathcal Z)} \left[\log P(\mathcal X \mid \theta)\right] & = \int_{\mathcal Z} \mathcal Q(\mathcal Z) \log P(\mathcal X \mid \theta)d\mathcal Z \\ & = \log P(\mathcal X \mid \theta) \int_{\mathcal Z} \mathcal Q(\mathcal Z)d\mathcal Z \\ & = \log P(\mathcal X \mid \theta) \end{aligned} EQ(Z)[logP(X∣θ)]=∫ZQ(Z)logP(X∣θ)dZ=logP(X∣θ)∫ZQ(Z)dZ=logP(X∣θ)
等式右端:
E Q ( Z ) [ log P ( X , Z ∣ θ ) Q ( Z ) − log P ( Z ∣ X , θ ) Q ( Z ) ] = E Q ( Z ) [ log P ( X , Z ∣ θ ) Q ( Z ) ] − E Q ( Z ) [ log P ( Z ∣ X , θ ) Q ( Z ) ] = ∫ Z Q ( Z ) log P ( X , Z ∣ θ ) Q ( Z ) d Z − ∫ Z Q ( Z ) log P ( Z ∣ X , θ ) Q ( Z ) d Z \begin{aligned} & \mathbb E_{\mathcal Q(\mathcal Z)}\left[\log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)} - \log \frac{P(\mathcal Z \mid \mathcal X,\theta)}{\mathcal Q(\mathcal Z)}\right] \\ & = \mathbb E_{\mathcal Q(\mathcal Z)} \left[\log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)}\right] - \mathbb E_{\mathcal Q(\mathcal Z)} \left[\log \frac{P(\mathcal Z \mid \mathcal X,\theta)}{\mathcal Q(\mathcal Z)}\right] \\ & = \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)}d \mathcal Z - \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal Z \mid \mathcal X,\theta)}{\mathcal Q(\mathcal Z)}d \mathcal Z \end{aligned} EQ(Z)[logQ(Z)P(X,Z∣θ)−logQ(Z)P(Z∣X,θ)]=EQ(Z)[logQ(Z)P(X,Z∣θ)]−EQ(Z)[logQ(Z)P(Z∣X,θ)]=∫ZQ(Z)logQ(Z)P(X,Z∣θ)dZ−∫ZQ(Z)logQ(Z)P(Z∣X,θ)dZ
称第一项为证据下界(Evidence Lower Bound,ELBO)
E L B O = ∫ Z Q ( Z ) log P ( X , Z ∣ θ ) Q ( Z ) d Z ELBO = \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)}d \mathcal Z ELBO=∫ZQ(Z)logQ(Z)P(X,Z∣θ)dZ
第二项(带负号)为表示 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)和 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)的 K L \mathcal K\mathcal L KL散度:
− ∫ Z Q ( Z ) log P ( Z ∣ X , θ ) Q ( Z ) d Z = K L [ Q ( Z ) ∣ ∣ P ( Z ∣ X , θ ) ] - \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal Z \mid \mathcal X,\theta)}{\mathcal Q(\mathcal Z)}d \mathcal Z = \mathcal K\mathcal L\left[\mathcal Q(\mathcal Z) || P(\mathcal Z \mid \mathcal X,\theta)\right] −∫ZQ(Z)logQ(Z)P(Z∣X,θ)dZ=KL[Q(Z)∣∣P(Z∣X,θ)]
核心部分:至此, log P ( X ∣ θ ) \log P(\mathcal X \mid \theta) logP(X∣θ)分解成了两项:ELBO和 K L \mathcal K\mathcal L KL散度两项。
- 首先观察ELBO:将ELBO看成关于隐变量概率分布 Q ( Z ) \mathcal Q(\mathcal Z) Q(Z)和概率模型参数 θ \theta θ的函数:
L [ Q ( Z ) , θ ] = ∫ Z Q ( Z ) log P ( X , Z ∣ θ ) Q ( Z ) d Z \mathcal L\left[\mathcal Q(\mathcal Z),\theta\right] = \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\mathcal Q(\mathcal Z)}d \mathcal Z L[Q(Z),θ]=∫ZQ(Z)logQ(Z)P(X,Z∣θ)dZ - 观察 K L \mathcal K\mathcal L KL散度,由于 K L \mathcal K\mathcal L KL散度自身性质:大于等于0恒成立
K L [ Q ( Z ) ∣ ∣ P ( Z ∣ X , θ ) ] ≥ 0 \mathcal K\mathcal L\left[\mathcal Q(\mathcal Z) || P(\mathcal Z \mid \mathcal X,\theta)\right] \geq 0 KL[Q(Z)∣∣P(Z∣X,θ)]≥0
并且在 Q ( Z ) = P ( Z ∣ X , θ ) \mathcal Q(\mathcal Z) = P(\mathcal Z \mid \mathcal X,\theta) Q(Z)=P(Z∣X,θ)时, K L \mathcal K\mathcal L KL散度取得最小值0。因此,则有:
log P ( X ∣ θ ) ≥ L [ Q ( Z ) , θ ] \log P(\mathcal X \mid \theta) \geq \mathcal L[\mathcal Q(\mathcal Z),\theta] logP(X∣θ)≥L[Q(Z),θ]
从而引出狭义EM的朴素想法:
- Q ( Z ) = P ( Z ∣ X , θ ) \mathcal Q(\mathcal Z) = P(\mathcal Z \mid \mathcal X,\theta) Q(Z)=P(Z∣X,θ);
- 在步骤1条件下,通过调整模型参数 θ \theta θ,使得 L [ Q ( Z ) , θ ] \mathcal L[\mathcal Q(\mathcal Z),\theta] L[Q(Z),θ]最大;
θ ^ = arg max θ L [ Q ( Z ) ] \hat \theta = \mathop{\arg\max}\limits_{\theta} \mathcal L[\mathcal Q(\mathcal Z)] θ^=θargmaxL[Q(Z)]
狭义EM算法的问题
继续观察狭义EM的朴素想法,主要问题出现在步骤1:核心问题出现在: P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)可能无法求解。
P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)是否可以求解取决于生成模型的复杂程度,核心在于我们定义的隐变量 Z \mathcal Z Z它的复杂程度:
- 例如高斯混合模型(Gaussian Mixture Model,GMM),它对于隐变量 Z \mathcal Z Z的概率分布是 离散的分类分布(Categorical Distribution);
- 例如隐马尔可夫模型(Hidden Markov Model,HMM),它对于隐变量 Z \mathcal Z Z的概率分布 受齐次马尔可夫假设的约束;
因此,这些模型它们定义的隐变量 Z \mathcal Z Z的概率分布是结构化的、简单的,因而可以直接 求解 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ),最终使用狭义EM进行求解;
但是,更多模型隐变量 Z \mathcal Z Z的概率分布是复杂的,使得 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)无法求解,因而无法使用狭义EM算法求解。从而衍生出其他求解概率分布方法,如近似推断(主要有变分推断、马尔可夫链蒙特卡洛方法等)
广义EM想要表达的朴素思想:
既然无法求解 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ),就在当前迭代步骤中求解一个和 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)最接近的概率分布 Q ( Z ) ^ \hat {\mathcal Q(\mathcal Z)} Q(Z)^来替代 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)。
具体迭代过程如下。基于第 t + 1 t+1 t+1步迭代,有:
- 已知第 t t t步的最优参数结果 θ ( t ) \theta^{(t)} θ(t),则有: log P ( X ∣ θ ( t ) ) \log P(\mathcal X \mid \theta^{(t)}) logP(X∣θ(t))是确定的。
这意味着 ELBO + KL-Divergence 的结果是固定的,因此求解最小化的KL-Divergence等价于求解最大化的ELBO; - 在步骤1的条件下,求解第 t t t步最接近 P ( Z ∣ X , θ ( t ) ) P(\mathcal Z \mid \mathcal X,\theta^{(t)}) P(Z∣X,θ(t))的概率分布 Q ^ ( t + 1 ) ( Z ) \hat {\mathcal Q}^{(t+1)}(\mathcal Z) Q^(t+1)(Z)作为第 t + 1 t+1 t+1步的最优后验概率分布。数学语言表示如下:
此时的θ ( t ) \theta^{(t)} θ(t)是已知量,看做常数;虽然依然不知道P ( Z ∣ X , θ ( t ) ) P(\mathcal Z \mid \mathcal X,\theta^{(t)}) P(Z∣X,θ(t))的具体结果,但不影响我们求解K L [ Q ( Z ) ∣ ∣ P ( Z ∣ X , θ ( t ) ) ] \mathcal K\mathcal L[\mathcal Q(\mathcal Z) || P(\mathcal Z \mid \mathcal X,\theta^{(t)})] KL[Q(Z)∣∣P(Z∣X,θ(t))]
Q ^ ( t + 1 ) ( Z ) = arg min Q ( Z ) K L [ Q ( Z ) ∣ ∣ P ( Z ∣ X , θ ( t ) ) ] = arg max Q ( Z ) L [ Q ( Z ) , θ ( t ) ] \begin{aligned} \hat {\mathcal Q}^{(t+1)}(\mathcal Z) & = \mathop{\arg\min}\limits_{\mathcal Q(\mathcal Z)} \mathcal K\mathcal L[\mathcal Q(\mathcal Z) || P(\mathcal Z \mid \mathcal X,\theta^{(t)})] \\ & = \mathop{\arg\max}\limits_{\mathcal Q(\mathcal Z)} \mathcal L[\mathcal Q(\mathcal Z),\theta^{(t)}] \end{aligned} Q^(t+1)(Z)=Q(Z)argminKL[Q(Z)∣∣P(Z∣X,θ(t))]=Q(Z)argmaxL[Q(Z),θ(t)] - 基于步骤2中产生的最优概率分布 Q ^ ( t + 1 ) ( Z ) \hat {\mathcal Q}^{(t+1)}(\mathcal Z) Q^(t+1)(Z),继续使用狭义EM算法,将 t + 1 t+1 t+1步迭代的最优模型参数 θ ( t + 1 ) \theta^{(t+1)} θ(t+1)求解出来:
θ ( t + 1 ) = arg max θ L [ Q ^ ( t + 1 ) ( Z ) , θ ] \theta^{(t+1)} = \mathop{\arg\max}\limits_{\theta} \mathcal L[\hat {\mathcal Q}^{(t+1)}(\mathcal Z),\theta] θ(t+1)=θargmaxL[Q^(t+1)(Z),θ]
整理:广义EM的E部和M部分别表示如下:
{ Q ^ ( t + 1 ) ( Z ) = arg max Q ( Z ) ∫ Z Q ( Z ) log P ( X , Z ∣ θ ( t ) ) Q ( Z ) d Z θ ( t + 1 ) = arg max θ ∫ Z Q ^ ( t + 1 ) ( Z ) log P ( X , Z ∣ θ ) Q ^ ( t + 1 ) ( Z ) d Z \begin{cases} \hat {\mathcal Q}^{(t+1)}(\mathcal Z) = \mathop{\arg\max}\limits_{\mathcal Q(\mathcal Z)} \int_{\mathcal Z}\mathcal Q(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta^{(t)})}{\mathcal Q(\mathcal Z)}d \mathcal Z \\ \theta^{(t+1)} = \mathop{\arg\max}\limits_{\theta} \int_{\mathcal Z}\hat {\mathcal Q}^{(t+1)}(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)}d \mathcal Z \end{cases} ⎩ ⎨ ⎧Q^(t+1)(Z)=Q(Z)argmax∫ZQ(Z)logQ(Z)P(X,Z∣θ(t))dZθ(t+1)=θargmax∫ZQ^(t+1)(Z)logQ^(t+1)(Z)P(X,Z∣θ)dZ
我们和狭义EM做一个对比:
核心区别在于E部:狭义EM默认 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)可求解,并令 Q ( Z ) = P ( Z ∣ X , θ ) \mathcal Q(\mathcal Z) = P(\mathcal Z \mid \mathcal X,\theta) Q(Z)=P(Z∣X,θ)作为条件;而广义EM在 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)无法求解的情况下,先求出 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)的近似解 Q ( Z ) ^ \hat {\mathcal Q(\mathcal Z)} Q(Z)^,并令 Q ( Z ) = Q ( Z ) ^ \mathcal Q(\mathcal Z) = \hat {\mathcal Q(\mathcal Z)} Q(Z)=Q(Z)^。
实际上从狭义和广义的M部求解公式中观察出区别。
- 将广义EM算法的M部公式展开:
θ ( t + 1 ) = arg max θ ∫ Z Q ^ ( t + 1 ) ( Z ) log P ( X , Z ∣ θ ) Q ^ ( t + 1 ) ( Z ) d Z = arg max θ { E Q ^ ( t + 1 ) ( Z ) [ log P ( X , Z ∣ θ ) Q ^ ( t + 1 ) ( Z ) ] } = arg max θ { E Q ^ ( t + 1 ) ( Z ) [ log P ( X , Z ∣ θ ) ] − E Q ^ ( t + 1 ) ( Z ) [ log Q ^ ( t + 1 ) ( Z ) ] } \begin{aligned} \theta^{(t+1)} & = \mathop{\arg\max}\limits_{\theta} \int_{\mathcal Z}\hat {\mathcal Q}^{(t+1)}(\mathcal Z) \log \frac{P(\mathcal X,\mathcal Z \mid \theta)}{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)}d \mathcal Z \\ & = \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)} \left[\frac{\log P(\mathcal X,\mathcal Z \mid \theta)}{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)}\right] \right\} \\ & = \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)}[\log P(\mathcal X,\mathcal Z \mid \theta)] - \mathbb E_{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)} [\log \hat {\mathcal Q}^{(t+1)}(\mathcal Z)] \right\} \end{aligned} θ(t+1)=θargmax∫ZQ^(t+1)(Z)logQ^(t+1)(Z)P(X,Z∣θ)dZ=θargmax{EQ^(t+1)(Z)[Q^(t+1)(Z)logP(X,Z∣θ)]}=θargmax{EQ^(t+1)(Z)[logP(X,Z∣θ)]−EQ^(t+1)(Z)[logQ^(t+1)(Z)]}
观察大括号内第二项,它就是关于 Q ^ ( t + 1 ) ( Z ) \hat {\mathcal Q}^{(t+1)}(\mathcal Z) Q^(t+1)(Z)分布的信息熵:
E Q ^ ( t + 1 ) ( Z ) [ log Q ^ ( t + 1 ) ( Z ) ] = ∫ Z Q ^ ( t + 1 ) ( Z ) log [ Q ^ ( t + 1 ) ( Z ) ] d Z = H [ Q ^ ( t + 1 ) ( Z ) ] \begin{aligned} \mathbb E_{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)} [\log \hat {\mathcal Q}^{(t+1)}(\mathcal Z)] & = \int_{\mathcal Z} \hat {\mathcal Q}^{(t+1)}(\mathcal Z) \log \left[\hat {\mathcal Q}^{(t+1)}(\mathcal Z)\right] d\mathcal Z \\ & = \mathcal H [\hat {\mathcal Q}^{(t+1)}(\mathcal Z)] \end{aligned} EQ^(t+1)(Z)[logQ^(t+1)(Z)]=∫ZQ^(t+1)(Z)log[Q^(t+1)(Z)]dZ=H[Q^(t+1)(Z)]
因此,关于M部,广义EM比狭义EM多了一项:
无论是狭义EM中的 P ( Z ∣ X , θ ( t ) ) P(\mathcal Z \mid \mathcal X,\theta^{(t)}) P(Z∣X,θ(t))还是广义EM中的 Q ^ ( t + 1 ) ( Z ) \hat {\mathcal Q}^{(t+1)}(\mathcal Z) Q^(t+1)(Z),均视为当前迭代步骤关于隐变量后验概率的最优解,统一用· Q ^ ( Z ) \hat {\mathcal Q}(\mathcal Z) Q^(Z)表示。
{ arg max θ { E Q ^ ( Z ) [ log P ( X , Z ∣ θ ) ] } arg max θ { E Q ^ ( Z ) [ log P ( X , Z ∣ θ ) ] + H [ Q ^ ( Z ) ] } \begin{cases} \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}(\mathcal Z)}[\log P(\mathcal X,\mathcal Z \mid \theta)]\right\} \\ \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}(\mathcal Z)}[\log P(\mathcal X,\mathcal Z \mid \theta)] + \mathcal H [\hat {\mathcal Q}(\mathcal Z)]\right\} \end{cases} ⎩ ⎨ ⎧θargmax{EQ^(Z)[logP(X,Z∣θ)]}θargmax{EQ^(Z)[logP(X,Z∣θ)]+H[Q^(Z)]}
如果 Q ^ ( Z ) \hat {\mathcal Q}(\mathcal Z) Q^(Z)未知,广义EM的M部需要多求解一项;但如果 Q ^ ( Z ) \hat {\mathcal Q}(\mathcal Z) Q^(Z)是已知项,那么 H [ Q ^ ( Z ) ] \mathcal H [\hat {\mathcal Q}(\mathcal Z)] H[Q^(Z)]相当于常数,和 θ \theta θ无关。从而将上式进行如下变换:
arg max θ { E Q ^ ( Z ) [ log P ( X , Z ∣ θ ) ] + H [ Q ^ ( Z ) ] } = arg max θ { E Q ^ ( Z ) [ log P ( X , Z ∣ θ ) ] } \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}(\mathcal Z)}[\log P(\mathcal X,\mathcal Z \mid \theta)] + \mathcal H [\hat {\mathcal Q}(\mathcal Z)]\right\} = \mathop{\arg\max}\limits_{\theta} \left\{\mathbb E_{\hat {\mathcal Q}(\mathcal Z)}[\log P(\mathcal X,\mathcal Z \mid \theta)]\right\} θargmax{EQ^(Z)[logP(X,Z∣θ)]+H[Q^(Z)]}=θargmax{EQ^(Z)[logP(X,Z∣θ)]}
因此,可以得出这样一个结论:狭义EM可看作后验概率 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)已知条件下的广义EM,狭义EM是广义EM的一种特殊情况。
实际上,上式实际上对一个情况加深了印象:广义EM中对于 P ( Z ∣ X , θ ) P(\mathcal Z \mid \mathcal X,\theta) P(Z∣X,θ)的近似解: Q ^ ( t + 1 ) ( Z ) \hat {\mathcal Q}^{(t+1)}(\mathcal Z) Q^(t+1)(Z)即便是近似解,但该解与 θ \theta θ有明确的关联关系。
相关参考:
机器学习-EM算法5(广义EM)