ML基本知识(十)分类器评价指标
衡量分类器好坏的指标
首先需要明确一下分类器的工作原理和评判分类器好坏的过程,这里只针对二分类问题,
第一,分类器经过训练后对测试样本进行预测时,会对每一个测试样本得出一个判定为正样本的概率,概率越大证明经过分类器的预测,这个测试样本被判定为正样本的概率越大,需要注意的是,这时我们还无法确定这个样本到底会不会被判定为正样本,之后会对这些测试样本进行排序,被判定为正样本的概率越大,则越靠前,这就是分类器所做的全部工作;
第二,经过上述操作,我们会得到一个测试样本的重新排序的序列,这时如果我们想得到最后结果,即判定出每个测试样本到底属于哪一类,这时我们就需要指定一个阈值,概率高于这个阈值的样本会被判定为正样本,而概率低于这个阈值的被判定为负样本,而对于二分类问题,一般都默认这个阈值为0.5, 即这个样本的概率高于0.5,则认定这个样本为正样本,否则为负样本。
而对于某一个分类器,到底如何评判这个分类器的好坏呢,可以有以下三种方式衡量,
1. 准确率和召回率
2. PR曲线
3. F1 score
4. ROC曲线
5. AUC
6. GAUC
准确率和召回率
对于二分类问题,常用的评价标准为准确率(precision)和召回率(recall), 通常以关注的类为正类(正样本),其他类为负类(负样本), 对于分对或者分错,有下列四种情况:
TP-> 把正类预测成正类
FN-> 把正类预测为负类
FP-> 把负类预测为正类
TN-> 把负类预测为负类
这里有两个概念,准确率和召回率,
准确率(查准率)为
P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
召回率(查全率)为
R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP
示意图如下所示,
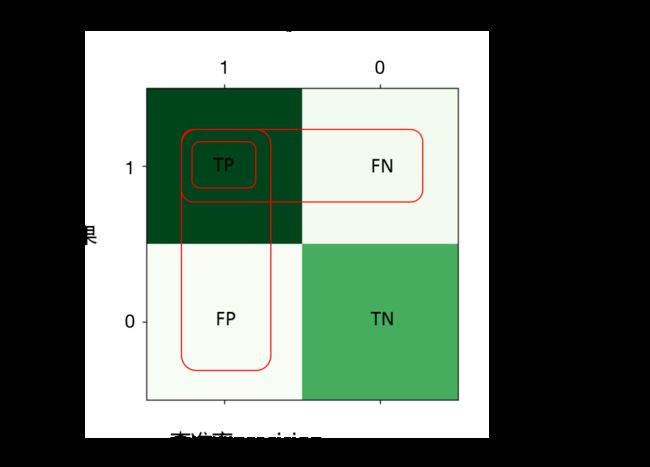
准确率与召回率之间的矛盾
我的个人理解是查准率为所有被判定为正样本的样本中真正为正样本的比例,而查全率为真正为正样本的样本中被判定为正样本的比例,这两个数值都是越高越好,
但是这两个数值却是一对矛盾体,比如说挑西瓜时,想把尽可能多的好瓜都挑出来,这时所做的就是尽可能多的调瓜,这时肯定有很多坏瓜也被判定为好瓜,因而FP很高,因而P就会很小,即准确率会很小,而如果我们希望在选出的瓜中好瓜最多,这时只去挑选最有把握的瓜,因而被错判为坏瓜的好瓜肯定比较多,因而查全率会很低。
一句话阐述准确率和召回率核心:
召回率:该类样本有多少识别正确了。
准确率:你认为的该类样本,有多少真正识别正确了。
准确率与召回率在实践中的应用
在推荐系统工程中,只说准确率和召回率是没有意义的,因为一般大家只关注头部数据,比如topN的准确率和召回率,具体而言,就是看模型预测得到的topN个数据的准确率和召回率如何,例如top7或者top20等。
如果想离线评估一个召回策略的好坏,评准召是一种方式。具体而言,基于历史上某15天中前14天的数据训练一个模型,用最后一天用户的实际点击行为评估该召回策略,假设最后一天用户总共点击了M个资源,且topK资源中有P个资源真正在最后一天被用户点过,这时topK资源的召回率为 P M \frac{P}{M} MP,准确率为 P K \frac{P}{K} KP。
这里再多说一句,如果是排序任务,且在离线调研模型性能好坏时,跑出来的准确率或者召回率有可能天然就没有baseline(线上模型或者策略)的效果好,举个例子说明问题:
假如baseline产出数据为 [ i t e m 1 , i t e m 2 , i t e m 3 , i t e m 4 , i t e m 5 , i t e m 6 , i t e m 7 ] [item_1, item_2, item_3, item_4, item_5, item_6, item_7] [item1,item2,item3,item4,item5,item6,item7],且用户点击了 [ i t e m 1 , i t e m 2 , i t e m 7 ] [item_1, item_2, item_7] [item1,item2,item7],离线调研排序模型的产出是 [ i t e m 8 , i t e m 9 , i t e m 1 , i t e m 2 , i t e m 4 , i t e m 5 , i t e m 6 ] [item_8, item_9, item_1, item_2, item_4, item_5, item_6] [item8,item9,item1,item2,item4,item5,item6],且 [ i t e m 8 , i t e m 9 ] [item_8, item_9] [item8,item9]用户没有看过,这个时候只能默认这两个资源用户不喜欢,但实际上我们并不知道这两个资源用户是否喜欢,因而离线调研产出数据中用户没有看过的资源本身就会被划分到用户不喜欢的集合中。
准确率&召回率与损失函数之间的关系
有一种损失函数叫做weighted_log_loss,函数形式如下:
L = ∑ i [ w i y i l o g ( p i ) + ( 1 − y i ) l o g ( 1 − p i ) ] L = \sum_i [w_i y_i log(p_i) + (1-y_i) log(1-p_i)] L=i∑[wiyilog(pi)+(1−yi)log(1−pi)]
这种损失函数的目的在于指导模型对正样本的学习过程:
- 如果 w i > 1 w_i > 1 wi>1,则表示如果把正样本预测成负样本,则模型的损失函数会上升很多,而如果把负样本预测成正样本,则模型的损失函数不会上升很多,这时模型更倾向于把输入样本预测成正样本,即尽可能多的把好瓜挑出来,这样会导致很多坏瓜也被判定为好瓜,这样召回率会上升,准确率可能会下降。
- 如果 w i < 1 w_i < 1 wi<1,模型更倾向于将输入样本预测为负样本,这时预测的正样本都是比较置信的正样本,即挑选出来的好瓜大部分都是真的好瓜,因而准确率会上升,召回率可能下降。
具体可以参考这里。
hitrate
推荐系统中评估召回效果好坏时,经常用到的评估指标还有hitrate,具体含义为用户如果点了推荐列表中topK资源的其中一个,hitrate@topK=1,否则为0,而后可以根据用户所有的点击行为反推推荐列表,从而计算出平均hitrate。
PR曲线
经过上文的介绍,可以发现<准确率,召回率>这一对数值是成反比的,对于一个分类器的预测结果,按被预测为正样本的概率从前到后排好序后,逐个把样本作为正样本进行预测,每次都会得到一个[P,R]对,画在坐标系下如下图所示,即P-R曲线,
而如果想评判不同的分类器的好坏,就需要把不同的分类器的P-R曲线放到一起,如下图所示,
这时可以看到,对于每一个固定的R来说,B的P都比A的P要大,对于每一个固定的P来说B的R也都比A的大,因而B的性能要好于A的性能,这就是通过P-R曲线来判断分类器的好坏的方法,
这里值得注意的是,上述图只是一个示意图,在PR曲线里面P=1时R不一定为0,R为1时P不一定为0, 可以通过举例或者公式推导可得。
F1 score
但是有时上述两个曲线会相交,这样无法很好地判断两个分类器的好坏,这时就引入了F1 score,当默认上述的阈值为0.5时, 那么如下公式中的F1 score就成为判别分类器好坏的标准,
2 F 1 = 1 P + 1 R \frac{2}{F_1}=\frac{1}{P}+\frac{1}{R} F12=P1+R1
F1越高,证明分类器的效果越好,
ROC曲线
这里提出两个概念,假正例率和真正例率,
真正例率为
T P R = T P T P + F N = T P P TPR=\frac{TP}{TP+FN}=\frac{TP}{P} TPR=TP+FNTP=PTP
假正例率为
F P R = F P T N + F P = F P N FPR=\frac{FP}{TN+FP}=\frac{FP}{N} FPR=TN+FPFP=NFP
通过公式可以看出,ROC曲线描述的是模型在真实样本分布的表现,所看问题的角度和召回率是一样的,和准确率不一样。
这时,对于同样一个分类器,以假正例率为横轴,真正例率为纵轴画出曲线如下,
可以看到,如果把分类的阈值设到最大,则所有的样本都被判定为负样本,因而不管是假正例率还是真正例率,都会被判定为0, 而如果分类的阈值设为最小,则所有的样本都被判定为正样本,可得假正例率和真正例率都是1,
而对于随机猜测而言,即随便划分一下阈值,都会发现被判定为正样本的样本集中真正的正样本和真正的负样本是一样多的,即TP=FP, 被判定为负样本的样本集中真正的正样本和真正的负样本也是一样多的,即FN=TN,通过上述两个式子可得,随机猜测的假正例率和真正例率相同,因而随机猜测的ROC曲线从(0,0)出发到(1,1)的对角线,即如下图所示,
对于二分类问题,任何分类器的效果一般都不会差于随机猜测,因而ROC曲线与X轴围成的面积一般大于0.5,通过上述条件的限制,ROC曲线一定是一个递增曲线,
AUC
一般情况下,样本的数量是有限的,因而对应到ROC曲线中,曲线一定是阶跃型的,而不是平滑的,这时的曲线与X轴围成的面积被称为AUC(Area Under ROC Curve),这时AUC的物理意义为正例排在负例前面的概率,AUC越大,就能够说明分类器把更多的正例排在了负例的前面,因而分类器的效果越好,
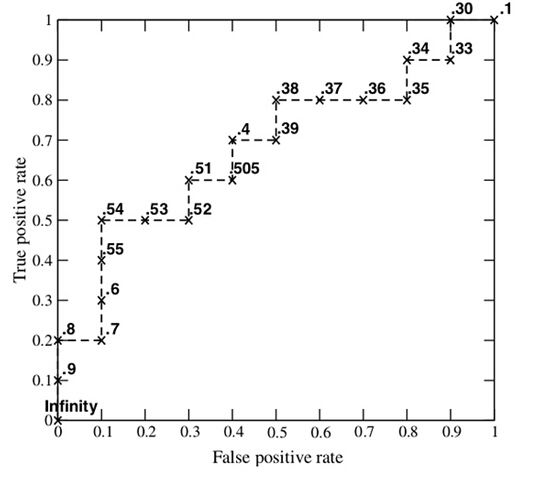
而绘出AUC的方法为从原点开始,每遇到1便向y轴正方向移动y轴最小步长( 1 N o . P \frac{1}{No.P} No.P1)1个单位;每遇到0则向x轴正方向移动x轴最小步长( 1 N o . N \frac{1}{No.N} No.N1)1个单位,
现在假设有一个训练好的二分类器对10个正负样本(正例5个,负例5个)预测,得分按高到低排序得到的最好预测结果为[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],即5个正例均排在5个负例前面,正例排在负例前面的概率为100%。然后绘制其ROC曲线,由于是10个样本,除开原点我们需要描10个点如下:
这时AUC=1,如果预测结果序列为[1, 1, 1, 0, 1, 0, 1, 0, 0, 0], AUC如下所示,AUC=0.88, 这时效果就不如之前分类器的效果好。
AUC计算过程
假设正例有 M M M个,负例有 N N N个,对于正例 p i p_i pi统计有多少个负例根据模型的打分排在了这个正例的前面( r a n k _ a b o v e i rank\_above_i rank_abovei), 1 − r a n k _ a b o v e i N 1- \frac{rank\_above_i}{N} 1−Nrank_abovei即为该正例的 a u c i auc_i auci,即这个正例排在负例之前的概率, ∑ i a u c i \sum_iauc_i ∑iauci即为最终的auc。示例代码如下:
import numpy as np
def rank(pos_scores, neg_scores):
pos_scores = np.array(pos_scores)
rank_above = np.zeros(len(pos_scores))
pos_scores_len = len(pos_scores)
for score in neg_scores:
for pos_ind in range(pos_scores_len):
if pos_scores[pos_ind] <= score:
rank_above[pos_ind] += 1
return rank_above
# 计算AUC总入口
def compute(pos_scores, neg_scores):
rank_above = rank(pos_scores, neg_scores)
negative_num = len(neg_scores)
return np.mean(1 - rank_above / (negative_num + 1e-2))
tf中AUC计算过程
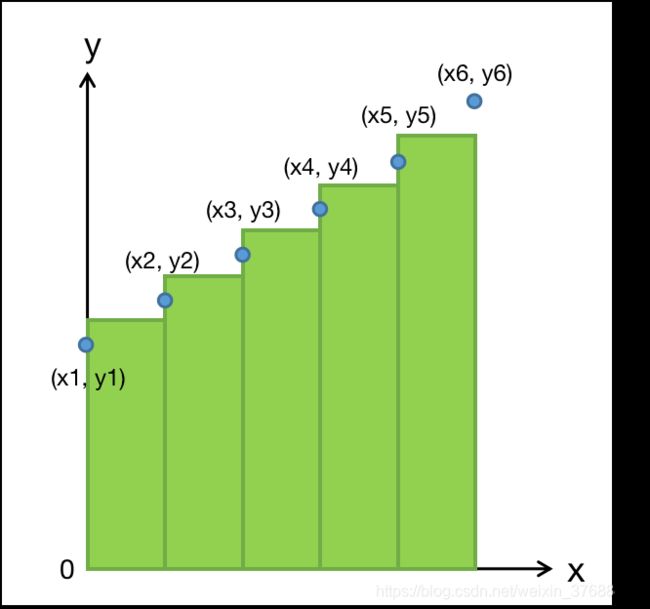
- [0, 1]之间划分num_thresholds个阈值,以此对predictions进行0/1划分,进而找到不同的
- 计算x[:x_len - 1] - x[1:]和(y[:y_len - 1] + y[1:]) / 2的乘积,计算结果即为auc。
具体计算示意图如下所示,图中绿色区域的面积为auc取值。
GAUC
考虑到每个用户的auc计算取值不同,gauc的目标为计算用户粒度下auc的加权平均,具体公式如下,这里 w u w_u wu指的是用户的点击量,
∑ u w u ∗ a u c u ∑ u w u \frac{\sum _u w_u * auc_u}{\sum _u w_u} ∑uwu∑uwu∗aucu
在通常情况下需要考虑将全正和全负样本的用户(真实场景下只有正反馈或者只有负反馈的用户)过滤掉后继续计算。具体代码可以参考这里。
当模型的auc偏高gauc偏低,这个时候个人理解应该从样本层面改进,比如在train的过程中一个batch内尽量保持一个用户的一个session内所有的训练样本,这样能够保证一个session内的训练数据不会被batch断开,而且还能够保证线上计算的auc和线下计算的auc保持一致。这样操作的结果在于auc和gauc就变成了一个指标了。
参考
- tf中计算auc方式