stata F值缺失_手把手教你用Stata的Network包实现分类变量网状Meta分析
Stata是一款非常强大的统计和作图软件,本文中用的版本是Stata14.2。网上目前存在的教程多半是用mvmeta包来做网状Meta,但mvmeta相对繁琐,需要打不少的代码去转换数据格式,Network包本质上是mvmeta,不过对用户更加友好,只需要执行简单的代码就可以数据处理。本文将介绍用Stata的Network包实现分类变量的网状Meta分析。
1. 假设我们已经安装好了Stata,在命令栏敲入:net from http://www.mtm.uoi.gr,然后点击network_graphs,下载network包。
2. 将要处理的数据在Excel中整理成下图所示:

其中id代表研究,t代表治疗,r是反应数(本例中是每组因副作用脱落的数目),n是样本量;注意每一行代表一个研究的一个臂(组),如果一个研究有三臂,那么就占三行。分析时需将id以数字来依次编号Study。同样,依次以数字来编号t。特别注意的是,同一研究中从上到下,治疗的编码只能增大,不能降低。一般来说,将安慰剂编码为1。
3. 点击Stata菜单栏Data->Data Editor-> Data Editor(Edit),将整理好的数据直接拷贝到里面,注意拷贝的时候选择首行为变量名;Excel中第1列Study不用拷贝;如下图所示:
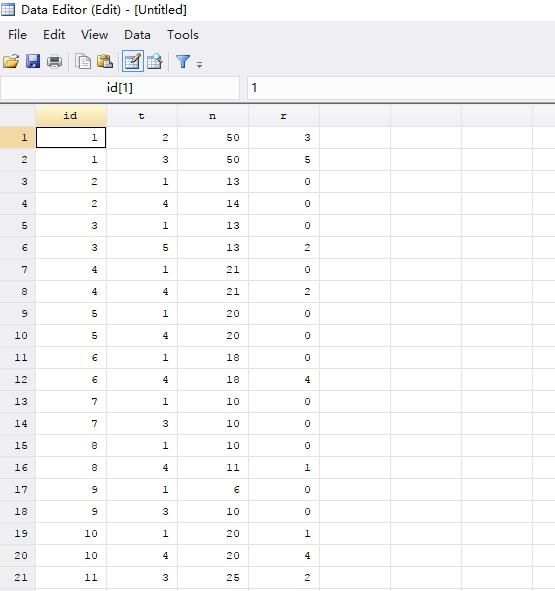
4. 返回Stata的首界面,在命令栏敲入:
network setup r n, studyvar(id) trtvar(t) format(augment) or
以上代码效应量为OR,如果是用RR作为效应量,则敲入:
network setup r n, studyvar(id) trtvar(t) format(augment) rr
结果如下图所示:
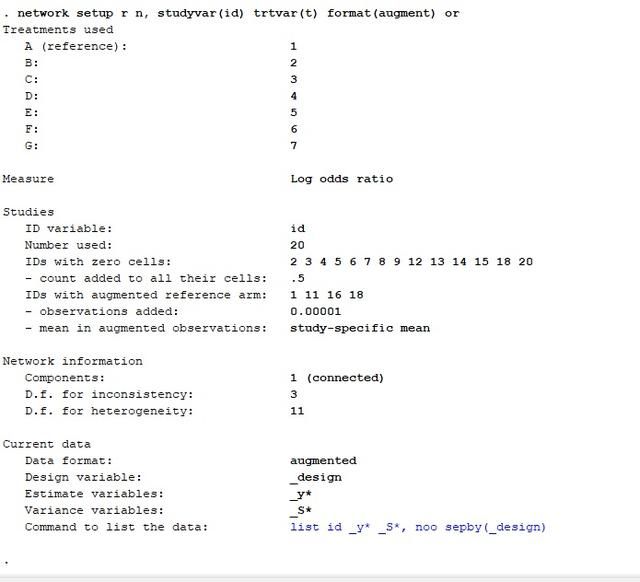
继续点击Stata菜单栏Data->Data Editor-> Data Editor(Edit),发现数据变成如下模样:
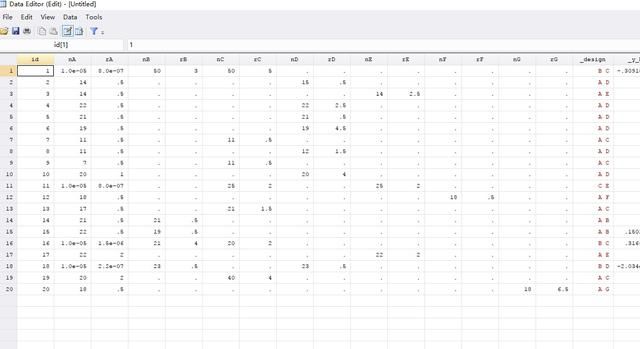
右边还有很长,实在截图不下了。
现在我们的数据就准备成可以进行网状Meta分析的格式了。
5. 制作网状图,在命令栏敲入:
network map
就会跳出如下图形:

或者敲入:
network map, improve
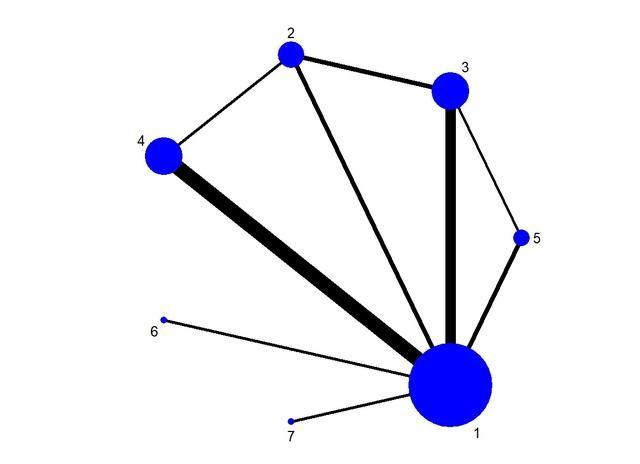
线条以及节点的颜色、比例、以及将数字换成治疗名称,均可以在图形上点击右键,开启start graph editor后进一步编辑;或者以命令行的形式编辑;留给读者探索,在此不再赘述。
6. 首先用不一致性模型进行检验,在命令栏敲入:
network meta i
成功的话会看到:
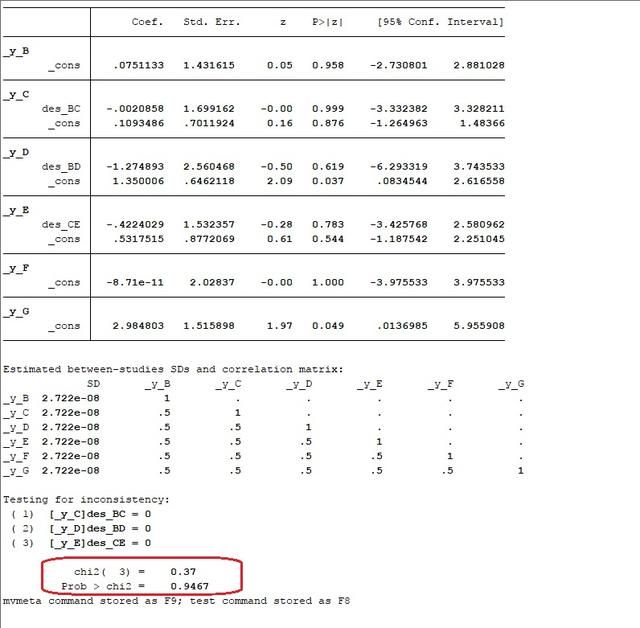
前面一堆东西不重要,主要是看红色方框里面的P值是否大于0.05;若小于0.05,则不一致性模型显著;对于这批数据不能直接用接下来的一致性模型分析。在本例中不一致性检验不显著,说明可以使用一致性模型进行分析。
7. 用一致性模型进行分析,在命令栏敲入:
network meta c
结果如下所示:
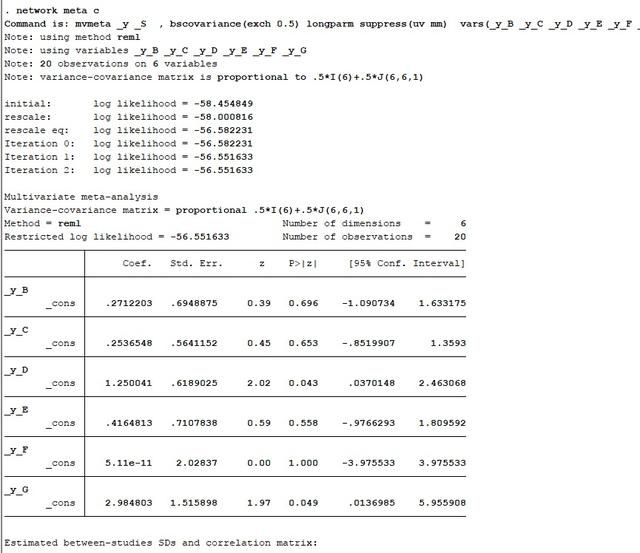
B,C,D,E,F,G分别对应编码为2,3,4,5,6,7的干预,Coef就是这些干预与1(安慰剂)对比的效应量,最后三列是P值以及95%可信区间。
8. 至此,一致性模型与不一致性模型的结果均已算出,在命令栏敲入:
network forest
出现如下所示的森林图,最底部是不一致性检验:

9. 上面进行的不一致性检验是Global inconsistency;对于网状Meta,光做Global是不够的,还有Local inconsistency;为了做局部不一致检验,我们通常使用节点劈裂法(node-splitting method);在命令栏敲入如下代码:
network sidesplit all, tau
结果如下所示:
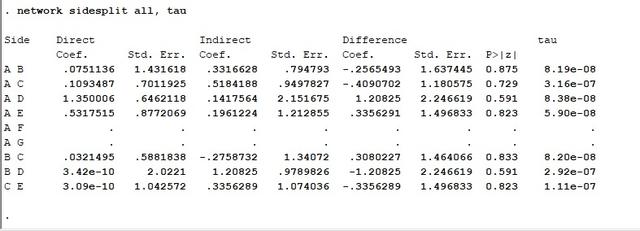
若P小于0.05,则认为局部存在不一致性。
10. 在这一步,命令栏敲入clear;然后重复第3、4、7步;为了计算每个干预的SUCRA,在命令栏敲入以下代码:
network rank min, all zero reps(5000) gen(prob)
注意,在本例中MD越小说明排名越靠前,所以这里用min,如果效应量越大排名越靠前,那么代码应该改成"network rank max, all zero reps(5000) gen(prob)"。出现如下结果:

这个图表示每个治疗排行第几的概率。如编码为1的治疗(安慰剂)排行第2的概率最大(35.1%),以此类推。
接下来计算我们通常比较关心的SUCRA,以及顺便把编码还原为我们的治疗名称,敲入以下代码:
sucra prob*, lab(Placebo Aripiprazole Risperidone Quetiapine Olanzapine Haloperidol Paliperidone)
这里lab是label(标签)的意思,括号里按照1234567编码的顺序把治疗名称写出,以空格相隔。结果如下所示:
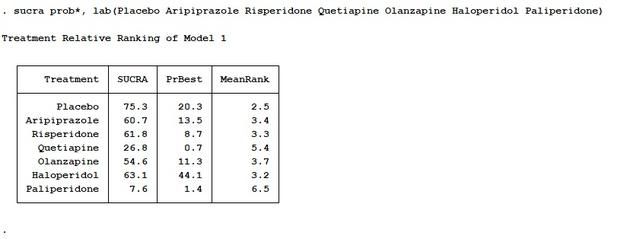
SUCRA值越高的排名越靠前,同时可以跳出SUCRA的图:
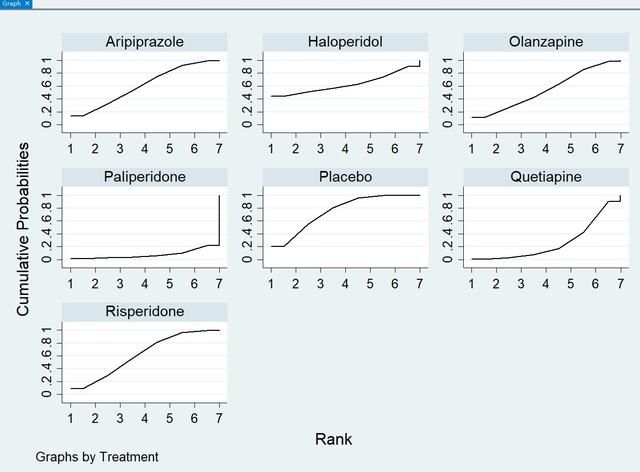
11. 制作文献中常见的联赛表,敲入以下代码:
netleague, lab(Placebo Aripiprazole Risperidone Quetiapine Olanzapine Haloperidol Paliperidone) sort(Placebo Haloperidol Risperidone Aripiprazole Olanzapine Quetiapine Paliperidone) export ("D:etwork.xlsx") eform
其中lab还是按照1234567的顺序依次写上治疗的名称;sort是按照SUCRA的大小排序,排行第一的写在最前面;export可要可不要,它的作用是将联赛表导出到指定的路径。eform很重要,因STATA默认对分类变量的输出为对数形式,eform的作用就是把它还原为OR或者RR。结果如下:

注意如果没有export的话,这个联赛表是个临时文件,必须再次复制保存;最后一句话提示联赛表在数据视图的最末尾,也就是最右边。即点击Stata菜单栏Data->Data Editor-> Data Editor(Edit),将下面的滚动条拉至最右边,就可以看到蜷缩在角落里瑟瑟发抖的联赛表。
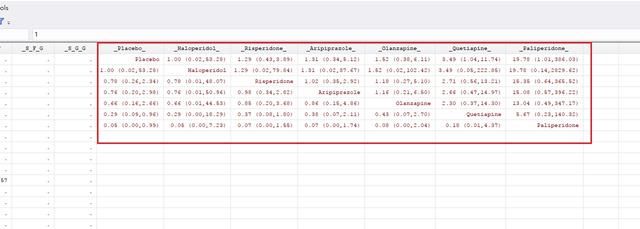
将结果复制到Excel里面,尽情美化吧骚年!
12. 制作两两比较的森林图,在命令栏敲入以下代码:
intervalplot, null(1) lab(PLA ARI RIS QUE OLA HAL PAL) eform
eform很重要;其中,null(1)设置无效线为1,还可以加入pred可以输出预测区间,留给读者自行尝试;本例跳出如下森林图:
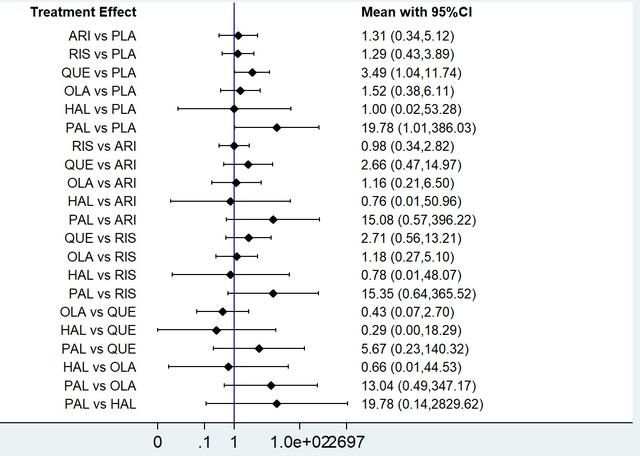
不得不说Stata的作图真的是棒棒的。
13. 制作漏斗图,首先将数据格式转换,敲入如下代码:
network convert pairs
可将数据转换成如下格式(瞬间感觉清爽了许多)
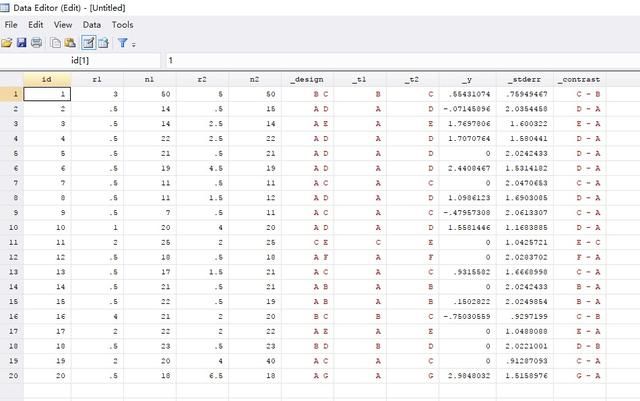
然后敲入如下代码:
netfunnel _y _stderr _t1 _t2 , random bycomp add(lfit _stderr _ES_CEN) noalpha
结果如图所示:

其实不用敲入这么多代码,你只敲入"netfunnel _y _stderr _t1 _t2"一样可以出结果;Stata里DIY的地方很多,读者可以敲入"help netfunnel"自行查阅帮助文档;对于其他的任何命令,都可以help一下。
14. 环不一致性检测(loop inconsistency),所谓的环就是指治疗与治疗之间构成了封闭的环形。运行以下命令同样需要先将数据格式转换为清爽的格式(network convert pairs):
ifplot _y _stderr _t1 _t2 id, tau2(loop)
结果如下所示:
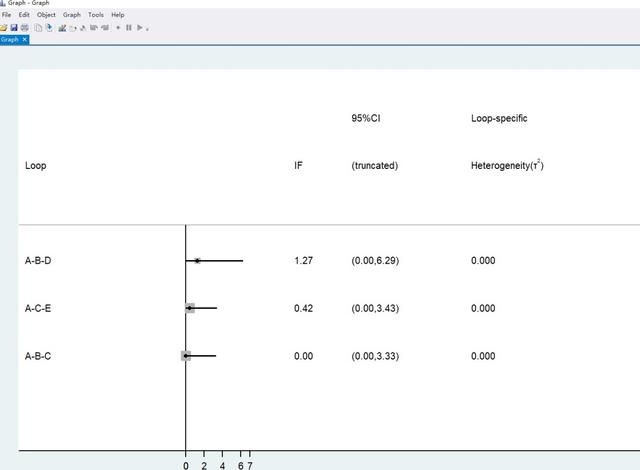
如果可信区间包括0,说明环不一致性不显著,但如果IF很大,说明直接比较结果和间接比较结果相差有点大……结果解释需谨慎,或者做亚组分析和回归分析找异质性来源,或者做敏感性分析等等。
15. 贡献图(即观察直接比较与间接比较对最终估计结果的贡献)的制作,在命令栏敲入以下命令(需要清爽格式):
netweight _y _stderr _t1 _t2
结果如图所示:

祝大家数据处理顺利。
私信作者可获得本例中所使用数据的Excel文件。