机器学习-SVM-SMO与SGD求解(附鸢尾花数据集实战,含代码)
代码SMO部分参考书籍为《机器学习实践》
原理的整体认知:
首先,我们认识到SVM其实就是求一个最优(超)平面的过程,说svm有三宝,间隔,对偶,核技巧
间隔就是说要求得的平面距离所有点间隔最大,这是一个最优化问题,可以用拉格朗日乘数法,解决。
化为这个形式后,求它的对偶问题,
求解的对偶问题的答案,按照以下公式反推到原问题的答案
两种常用的求解算法:
1.SGD
将原问题转变为一个最小损失函数的问题,用梯度下降的方法,优化参数,减小损失
2.SMO
每次只从参数中挑去两个进行优化,这样能使问题简化成很多个二次凸优化问题

虽然在这里两种方法都用高斯映射,但是SMO方法其实可以通过核函数直接求解,并不需要进行映射,而SGD则必须要映射后进行求解,无法使用核函数。从他们要优化的公式里可以看出这一点。
SGD算法
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as datasets
def relu(x):
if x>0:
return x
else:
return 0
def gradient_descent(loss,w,b,exp_loss,x,y,lr=0.0001,lambda0=0.1):#这里没有加lambda
C=1000
if exp_loss==0:
b=b-lr*0
w=w-lr*0#2*w*lambda0
else:
b=b-lr*(-y)*C
w=w-lr*(-y*x)*C
return w,b
def Hingeloss_gradient_descent(y_pre,y_label,weight,x,b,lr=0.000001):
lam=1
loss=relu(1-y_label * y_pre)+np.linalg.norm(weight)*lam
weight,b=gradient_descent(loss,weight,b,relu(1-y_label*(y_pre)),x,y_label,lr=lr,lambda0=lam)
return weight,b
def svm(data,label,epoch):
w=np.zeros((np.shape(data)[1],1)).T
b=0
for i in range(epoch):
for j in range(np.shape(data)[0]):
y_pre=np.matmul(w,data[j,:])+b
w,b=Hingeloss_gradient_descent(y_pre,label[j],w,data[j],b)
return w,b
def get_data():
fig = plt.figure()
x, y1 =datasets.make_circles(n_samples=100, factor=0.1, noise=0.1)
plt.scatter(x[:, 0], x[:, 1], marker='o', c=y1)
plt.pause(2)
for i in range(len(y1)):
if y1[i]==0:
y1[i]=-1
return x,y1
def process(_x):
'''
映射到高维核空间
:param data_point:
:param data_noise:
:return:
'''
Z = np.zeros([100, 3])
# 高斯核映射
Z[:, 0] = np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 1] = 2 * _x[:, 0] * _x[:, 1] * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 2] = 2 * _x[:, 0] ** 2 * _x[:, 1] ** 2 * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
return Z
X,y=get_data()
x=process(X)
# x=X
print(X,y)
w,b=svm(x,y,700)
for i in range(np.shape(X)[0]):
if np.matmul(w,x[i])+b > 0:
plt.scatter(X[i,0],X[i,1],c='red')
print(np.matmul(w,x[i])+b)
elif np.matmul(w,x[i])+b < 0:
plt.scatter(X[i, 0], X[i, 1], c='blue')
plt.pause(8)
print(b,w)
SMO算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import torch
import time
iris =datasets.load_iris()
def get_data():
fig = plt.figure()
x, y1 =datasets.make_circles(n_samples=100, factor=0.1, noise=0.1)
plt.scatter(x[:, 0], x[:, 1], marker='o', c=y1)
plt.pause(2)
return x,y1
def process(_x):
'''
映射到高维核空间
:param data_point:
:param data_noise:
:return:
'''
Z = np.zeros([100, 3])
# 高斯核映射
Z[:, 0] = np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 1] = 2 * _x[:, 0] * _x[:, 1] * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 2] = 2 * _x[:, 0] ** 2 * _x[:, 1] ** 2 * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
return Z
def selectJ(i,samples_num):
j=i
while j==i:
j=int(np.random.uniform(0,samples_num))
return j
def clipAlpha(L,H,alpha):
if alpha>H:
alpha= H
if alpha toler and alpha[i] > 0): # 和书上kkt不一样为什么?
j = selectJ(i, m)
gx_j = float(np.multiply(alpha, labelMat).T * (dataMat * dataMat[j, :].T)) + b
Ej = gx_j - float(labelMat[j])
alpha_i_old = alpha[i].copy()
alpha_j_old = alpha[j].copy()
print(i, itera, gx_i, gx_j,b,np.sum(alpha))
time.sleep(0.01)
if labelMat[i] != labelMat[j]:
L = max(0, alpha[j] - alpha[i])
H = min(C, C + alpha[j] - alpha[i])
else:
L = max(0, alpha[j] + alpha[i] - C)
H = min(C, alpha[j] + alpha[i])
if L==H:
print('L==H')
continue
eta=2.0*dataMat[i,:]*dataMat[j,:].T-dataMat[i,:]*dataMat[i,:].T-dataMat[j,:]*dataMat[j,:].T#什么东西这是?epsilon
print(eta)
if eta>=0:
print('eta>=0')#why????????????
continue
alpha[j] -= labelMat[j] * (Ei - Ej) / eta # +or->>>>
alpha[j] = clipAlpha(L, H, alpha[j])
if abs(alpha[j] - alpha_j_old) < 0.00001:
print('j not moving enough')
continue
alpha[i] += labelMat[j] * labelMat[i] * (alpha_j_old - alpha[j])
b1 = b - Ei - labelMat[i] * (alpha[i] - alpha_i_old) * dataMat[i, :] * dataMat[i, :].T - labelMat[
j] * (alpha[j] - alpha_j_old) * dataMat[i, :] * dataMat[j, :].T
b2 = b - Ej - labelMat[i] * (alpha[i] - alpha_i_old) * dataMat[i, :] * dataMat[j, :].T - labelMat[
j] * (alpha[j] - alpha_j_old) * dataMat[j, :] * dataMat[j, :].T
if alpha[i] > 0 and alpha[i] < C:
b = b1
elif alpha[j] > 0 and alpha[j] < C:
b=b2
else:
b=(b1+b2)/2.0
alphaPairChange+=1
print(("iter{},i:{},pairchange{}".format(itera,i,alphaPairChange)))
if (alphaPairChange==0):
itera+=1
else:
itera=0
print('iteration{},m{}'.format(itera,i))
return b,alpha
np.random.seed(0)
x=np.random.random((100,2))
x[:50,:]+=0.8
x[50:,:]-=0.8
print
y=np.array([0]*100)
y[:50]+=1
y[50:]-=1
print('y{}'.format(y))
plt.scatter(x[:50,0],x[:50,1],c='r')
plt.scatter(x[50:,0],x[50:,1],c='g')
# plt.pause(3)
b,alpha=smo(dataIn=x,classLabel=y,C=0.6,toler=0.001,maxIter=40)
print(b,alpha)
# w=alpha*y*x.T
#画出分割面
for i in range(100):
if alpha[i]>0.0:
print(x[i],y[i])
plt.scatter(x[i,0], x[i, 1], c='y')
plt.pause(10)
鸢尾花数据集实战
正常人眼里的鸢尾花:

计算机人眼里的鸢尾花

import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets as datasets
import math
from sklearn.preprocessing import MinMaxScaler
import sklearn.utils as utils
def relu(x):
if x>0:
return x
else:
return 0
def gradient_descent(loss,w,b,exp_loss,x,y,lr=0.01,lambda0=0.1):#这里没有加lambda
C=10
if exp_loss==0:
b=b-lr*0
w=w-lr*0#2*w*lambda0
else:
b=b-lr*(-y)*C
w=w-lr*(-y*x)*C
return w,b
def Hingeloss_gradient_descent(y_pre,y_label,weight,x,b,lr=0.001):
lam=1
loss=relu(1-y_label * y_pre)+np.linalg.norm(weight)*lam
weight,b=gradient_descent(loss,weight,b,relu(1-y_label*(y_pre)),x,y_label,lr=lr,lambda0=lam)
return weight,b
def svm(data,label,epoch):
w=np.zeros((np.shape(data)[1],1)).T
b=0
for i in range(epoch):
for j in range(np.shape(data)[0]):
y_pre=np.matmul(w,data[j,:])+b
w,b=Hingeloss_gradient_descent(y_pre,label[j],w,data[j],b)
return w,b
def get_iris_data():
iris=datasets.load_iris()
print(iris.data,iris.target)
scaler=MinMaxScaler()
data=scaler.fit_transform(iris.data)
print(data)
x,y=utils.shuffle(data,iris.target)
train_size=int(x.shape[0]*5/10)
train_x,train_y,test_x,test_y=x[:train_size,:],y[:train_size],x[train_size:,:],y[train_size:]
return train_x,train_y,test_x,test_y
def get_data():
fig = plt.figure()
x, y1 =datasets.make_circles(n_samples=100,noise=0.5 )
# x, y1 = datasets.make_moons(n_samples=100, noise=0.0)
plt.scatter(x[:, 0], x[:, 1], marker='o', c=y1)
plt.pause(2)
for i in range(len(y1)):
if y1[i]==0:
y1[i]=-1
return x,y1
def process(_x):
Z = np.zeros([100, 3])
# # 二项式映射
# X[:,0] = _x[:,0]**2
# X[:, 1] = math.sqrt(2)*_x[:,0]*_x[:,1]
# X[:,2] = _x[:,1]**2
# 高斯核映射
Z[:, 0] = np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 1] = 2 * _x[:, 0] * _x[:, 1] * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
Z[:, 2] = 2 * _x[:, 0] ** 2 * _x[:, 1] ** 2 * np.exp(-(_x[:, 0] ** 2)) * np.exp(-(_x[:, 1] ** 2))
return Z
train_x,train_y,test_x,test_y=get_iris_data()
svm_list=[]
w_list,b_list=[],[]
pre_out=[]
y_pre=[]
label_y=np.zeros_like(train_y)
for i in range(3):
for j in range(train_x.shape[0]):
if train_y[j]==i:
label_y[j]=1
else:
label_y[j]=-1
# print(label_y)
w, b = svm(train_x, label_y, 700)
w_list.append(w)
b_list.append(b)
correct_n=0
for i in range(test_x.shape[0]):
for j in range(3):
pre_out.append(float(np.matmul(w_list[j],test_x[i,:])+b_list[j]))
y_pre.append(pre_out.index(max(pre_out)))
if pre_out.index(max(pre_out))==test_y[i]:
correct_n+=1
print(pre_out.index(max(pre_out)),test_y[i],pre_out)
pre_out.clear()
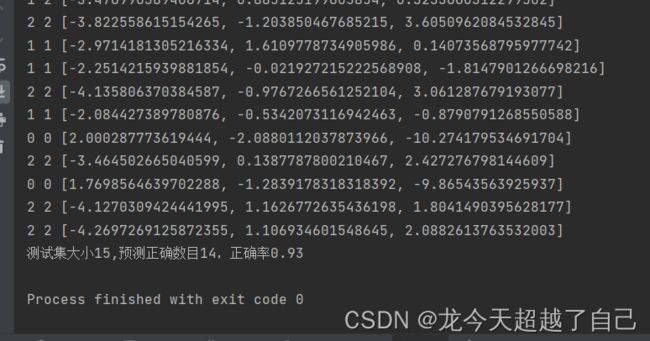
print("测试集大小{:},预测正确数目{},正确率{:.2f}".format(test_y.shape[0],correct_n,correct_n/test_y.shape[0]))
手撕原理:
看完了代码和大体原理,我们再来细细了解详细原理,此处主要参考李航的《统计学习方法》
1.首先清楚要找到这样一个平面将样本完全分开,且最大化 最小的“几何间隔”最大。几何间隔定义为图1。(至于为什么定义成这样书上有写,此处为连贯性略)。

图1
2.这样一个最大化问题,可以等价转化为下面这样一约束最大化问题(证明略书上有)
3.用拉格朗日乘数法,又可以等价转化为下式子,alpha为拉格朗日乘子向量,由解满足KKT条件可证(此略),alpha与w,b的关系下图二。


4.根据拉格朗日对偶性,(白板推导里有讲,此略)原问题的对偶问题为下,求出alpha则求的出原问题解

两种优化算法
SGD:1.可证(此略),下面两个最优化问题是等价的,第二个称为 合页损失函数+正则项


所以,我们可以通过梯度下降的 方法优化损失函数,直接求偏导就行,可以参照上面给出的代码学习。
SMO:1.为了进一步求解 maxminL(w,b,a),先求minL(w,b,a),对w,b求偏导,问题等价化为:

ps:核技巧就是将xi*xj化为了K(xi,xj),K是核函数,表示映射到高维的xi,xj的乘积的值。
2.SMO算法全名叫序列最小最优化(Sequential minimal optimization),因为KKT条件是该最优化问题的充分必要条件(证明略),即当所有样本均满足KKT条件时,为最优化问题的解。首先,从所有α中选择两个变量α1,α2,固定其他变量,针对这两个变量构建一二次规划问题,此子问题可通过解析方法求解。重复这一步骤不断优化,直到所有变量都满足KKT条件得到最终解。
2.1 解析方法求解二次规划问题
子问题可以写作以下形式

未完待续