python图像分类代码_Python遥感图像分类——监督分类
遥感图像分类就是以计算机系统为支撑环境,利用模式识别技术与人工智能技术相结合,根据遥感图像中目标地物的各种影像特征,结合专家知识库中目标地物的解译经验和成像规律等知识进行分析和推理,实现对遥感图像的理解,完成对遥感图像的解译。遥感图像分类的理论依据在于:在理想条件下,同类目标在遥感图像中具有相同或相似的光谱特征和空间特征;不同目标的光谱特征和空间特征不同。
遥感图像计算机分类方法可以分为:
监督分类法:选择具有代表性的典型实验区或训练区,用训练区中已知地面各类地物样本的光谱特性来“训练”计算机,获得识别各类地物的判别函数或模式,并以此对未知地区的像元进行分类处理,分别归入到已知的类别中。
非监督分类:是在没有先验类别(训练场地)作为样本的条件下,即事先不知道类别特征,主要根据像元间相似度的大小进行归类合并(即相似度的像元归为一类)的方法。
监督分类
在各种商业软件,例如ArcGIS、Envi等中有各种分类工具。Python中也有可以拿来做分类的工具,例如各种支持机器学习或深度学习等的包就可以用在遥感图像分类上。
我们前面用过一个scikit-learn库,里面有各种各样的机器学习模块,用着很方便。正好前两天有人问我随机森林的事,我也不太懂,就看了看,scikit-learn里面也有这个方法,今天就用这个库里面的随机森林说下遥感图像监督分类的问题。
下面是分类的基本代码:
import osfrom osgeo import gdal, gdal_arrayimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.ensemble import RandomForestClassifierfrom sklearn import svmos.chdir(r'D:/books/datas/chapter06/')imgds = gdal.Open('cutted.tif')roids = gdal.Open('roiraster.tif')xSize = imgds.RasterXSizeySize = imgds.RasterYSizebandCount = imgds.RasterCountimgDataTypeCode = gdal_array.GDALTypeCodeToNumericTypeCode(imgds.GetRasterBand(1).DataType)#分类后的数组classifiedImg = np.zeros((ySize, xSize, bandCount), imgDataTypeCode)#将初始数据读入到分类后的数组,建立三维数组for band in range(classifiedImg.shape[2]): classifiedImg[:, :, band] = imgds.GetRasterBand(band + 1).ReadAsArray() roi = roids.GetRasterBand(1).ReadAsArray()#训练样本的标注labels = np.unique(roi[roi < 255])#求出fit函数的参数建立训练样本和标注之间的关系X = classifiedImg[roi < 255, :]y = roi[roi < 255 ]#oob_score, 由于随机决策树生成过程采用的Boostrap,所以在一棵树的生成过程并不会使用所有的样本,未使用的样本就叫(Out_of_bag)袋外样本,通过袋外样本,可以评估这个树的准确度,其他子树叶按这个原理评估,最后可以取平均值,即是随机森林算法的性能;clf = RandomForestClassifier(n_estimators=500, oob_score=True)#训练样本clf = clf.fit(X, y)#将每个波段变换为一维,便于下一步分类,new_shape是变换后的数组的shapenew_shape = (classifiedImg.shape[0] * classifiedImg.shape[1], classifiedImg.shape[2] )transimg = classifiedImg[:, :, :7].reshape(new_shape)# 根据训练情况对数据进行分类predictedClass = clf.predict(transimg)# 分类后的predictedClass是一维向量,现在再将其变换回二维图像predictedClass = predictedClass.reshape(classifiedImg[:, :, 0].shape)#将各个波段归一化到(0,1)的范围便于matplotlib显示normalizeImg = classifiedImg[:,:,[3, 2, 1]].astype(np.float64)for n in range(normalizeImg.shape[2]): maxval = np.max(normalizeImg[:, :, n])*0.7 minval = np.min(normalizeImg[:, :, n]) normalizeImg[:,:,n] = (normalizeImg[:, :, n] - minval) / (maxval - minval) n = predictedClass.max()#为分类后显示分类后的图像建立颜色表colorTable = dict(( (1, (255, 211, 155)), # 黄河 (2, (34, 139, 34)), # 植被 (3, (30, 144, 255)), # 河流 (4, (205, 201, 201)), # 村庄 (5, (255, 0, 0)), # 道路 (255, (0, 0, 0)) # Nodata))# 将颜色归一化到0,1for key in colorTable: ct = colorTable[key] ctval = [ctval / 255.0 for ctval in ct] colorTable[key] = ctval colorsIndex = [colorTable[key] if key in colorTable else (255, 255, 255, 0) for key in range(1, n + 1)]cmap = plt.matplotlib.colors.ListedColormap(colorsIndex, 'Classification', n)plt.subplot(121)plt.imshow(normalizeImg)plt.axis('off')plt.title('原始图像')plt.subplot(122)plt.imshow(predictedClass, cmap=cmap, interpolation='none')plt.title('分类图像')plt.axis('off')plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.show()下图是分类结果。
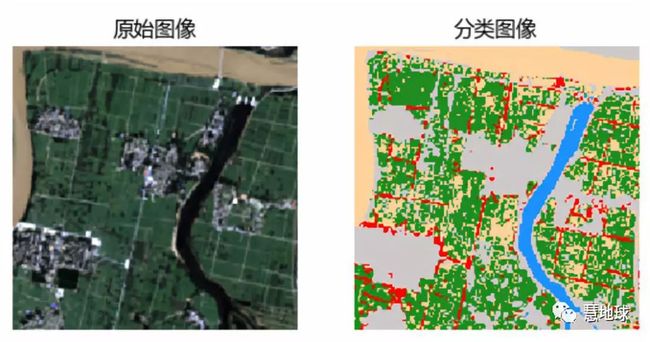
在代码中,与分类有关的关键行是第32行,35行和42行,前两行是对样本进行训练,42行是对数据进行分类。如果不想用随机森林,比如想用支持向量机方法,则最简单的就是修改32行,换个方法即可。
clf =svm.LinearSVC()当然,每种方法都有自己的参数,具体可以参照帮助文件。