transformer细节及代码实现1-Positional Encoding and Mask
Transformer
transformer是google提出的attention机制的升级版,不使用以往神经网络里面的CNN和RNN。目前大火的BRET也是基于transformer。transformer这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。
其总体结构为:
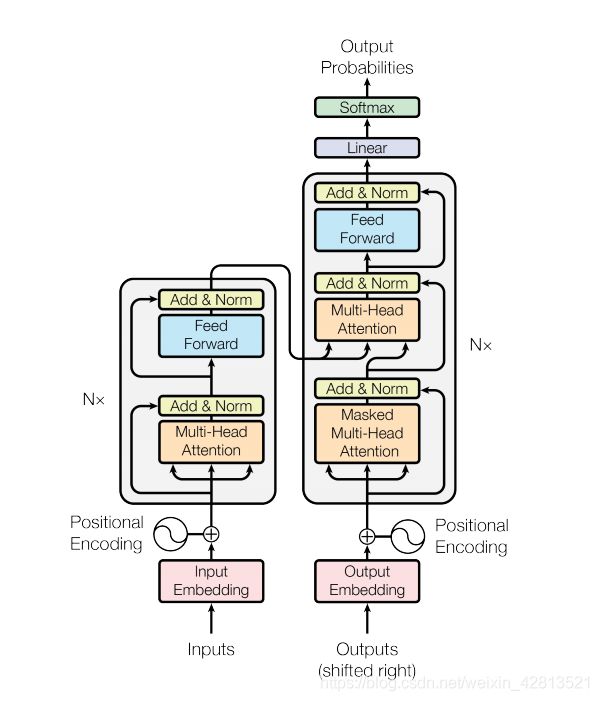
首先从输入来看:input层首先进入input Embedding,然后进入Positional Encoding进行编码
1.Positional Encoding 位置编码
因为该模型并不包括任何的循环(recurrence)或卷积,所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。
位置编码向量被加到嵌入(embedding)向量中。嵌入表示一个 d 维空间的标记,在 d 维空间中有着相似含义的标记会离彼此更近。但是,嵌入并没有对在一句话中的词的相对位置进行编码。因此,当加上位置编码后,词将基于它们含义的相似度以及它们在句子中的位置,在 d 维空间中离彼此更近。

import tensorflow as tf
import time
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 将 sin 应用于数组中的偶数索引(indices);2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 将 cos 应用于数组中的奇数索引;2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
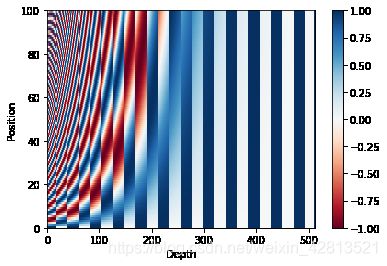
测试:
pos_encoding = positional_encoding(100, 512)
print (pos_encoding.shape)
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0, 512))
plt.ylabel('Position')
plt.colorbar()
plt.show()
结果:
2.Mask方法
对于transformer来说,会用到两种Mask方法:
Padding Mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# 添加额外的维度来将填充加到
# 注意力对数(logits)。
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
测试:
x = tf.constant([[7, 6, 0, 0, 1], [1, 2, 3, 0, 0], [0, 0, 0, 4, 5]])
create_padding_mask(x)
输出:
<tf.Tensor: id=207727, shape=(3, 1, 1, 5), dtype=float32, numpy=
array([[[[0., 0., 1., 1., 0.]]],
[[[0., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 0.]]]], dtype=float32)>
import numpy as np
def softmax(x):
"""Compute the softmax in a numerically stable way."""
x = x - np.max(x)
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x)
return softmax_x
测试:
softmax([1,2,3,4,5*-1e9])
结果:
array([0.0320586 , 0.08714432, 0.23688282, 0.64391426, 0. ])
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
def create_look_ahead_mask(size):
"""
tf.linalg.band_part(
input,
num_lower,
num_upper,
name=None
)
input:输入的张量.
num_lower:下三角矩阵保留的副对角线数量,从主对角线开始计算,相当于下三角的带宽。取值为负数时,则全部保留。
num_upper:上三角矩阵保留的副对角线数量,从主对角线开始计算,相当于上三角的带宽。取值为负数时,则全部保留。
"""
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
测试:
x = tf.random.uniform((1, 3))
temp = create_look_ahead_mask(x.shape[1])
结果:
<tf.Tensor: id=207742, shape=(3, 3), dtype=float32, numpy=
array([[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]], dtype=float32)>