pandas数据预处理---缺失值处理、重复数据处理、更改索引、行列删除
pandas数据预处理
1 缺失值查看与处理
缺失值就是由某些原因导致部分数据为空,对于为空的这部分数据我们一般有两种处理方式,
在pandas里缺失数据用NaT(Not a Time,时间缺失值)、NaN、nan等来表示,有时None值也会被当作缺失数据处理
一种是删除,即把含有缺失值的数据删除
另一种是填充,即把缺失的那部分数据用某个值代替
源数据如下:
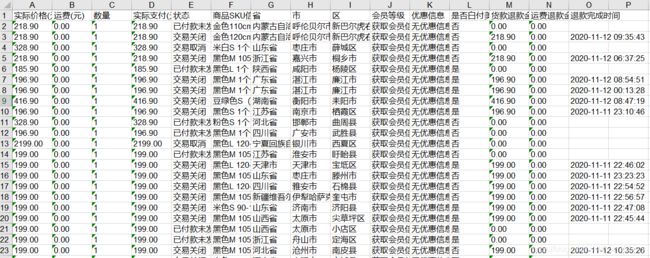
1.1 缺失值查看
1.1.1 infor()方法
直接调用 info()方法就会返回每一列的缺失情况
import pandas as pd
df = pd.read_excel(r"D:\testdata\data.xlsx")
df.info()
RangeIndex: 88 entries, 0 to 87
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 实际价格(元) 88 non-null float64
1 运费(元) 88 non-null float64
2 数量 88 non-null int64
3 实际支付(元) 88 non-null float64
4 状态 88 non-null object
5 商品SKU信息 88 non-null object
6 省 88 non-null object
7 市 88 non-null object
8 区 88 non-null object
9 会员等级 88 non-null object
10 优惠信息 88 non-null object
11 是否白付美支付 88 non-null object
12 货款退款金额 88 non-null float64
13 运费退款金额 88 non-null float64
14 退款完成时间 41 non-null object
dtypes: float64(5), int64(1), object(9)
memory usage: 10.4+ KB
Python中缺失值一般用NaN表示,从用info()方法的结果来看,退款完成时间这一列是41 non-null object ,表示有47个非空值,该列有47个空值
1.1.2 isnull()方法
用isnull()方法来判断哪个值是缺失值,如果是缺失值则返回True,如果不是缺失值则返回False
df.isnull()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | False | False | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False | False | True |
| 4 | False | False | False | False | False | False | False | False | False | False | False | False | False |
| 5 | False | False | False | False | False | False | False | False | False | False | False | False | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84 | False | False | False | False | False | False | False | False | False | False | False | False | True |
| 85 | False | False | False | False | False | False | False | False | False | False | False | False | False |
| 86 | False | False | False | False | False | False | False | False | False | False | False | False | True |
| 87 | False | False | False | False | False | False | False | False | False | False | False | False | True |
| 88 | False | False | False | False | False | False | False | False | False | False | False | False | True |
88 rows × 13 columns
1.1.3 notnull()方法
notnull()判断对象的元素是否不是缺失值,不是则对应返回值是True,是则对应返回值是False
df.notnull()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | True | True | True | True | True | True | True | True | True | True | True | True | True |
| 2 | True | True | True | True | True | True | True | True | True | True | True | True | True |
| 3 | True | True | True | True | True | True | True | True | True | True | True | True | False |
| 4 | True | True | True | True | True | True | True | True | True | True | True | True | True |
| 5 | True | True | True | True | True | True | True | True | True | True | True | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84 | True | True | True | True | True | True | True | True | True | True | True | True | False |
| 85 | True | True | True | True | True | True | True | True | True | True | True | True | True |
| 86 | True | True | True | True | True | True | True | True | True | True | True | True | False |
| 87 | True | True | True | True | True | True | True | True | True | True | True | True | False |
| 88 | True | True | True | True | True | True | True | True | True | True | True | True | False |
88 rows × 13 columns
1.2 缺失值删除
缺失值分为两种,一种是一行中某个字段是缺失值;
另一种是一行中的字段全部为缺失值,即为一个空白行
1.2.1 dropna()方法
dropna(axis=0,how=“any”)
方法默认删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除
axis : 指定需要删除包含缺失值的行或列,当值为0或者index时,以行方向进行删除,当值为1或者columns时,以列方向进行删除;
how : 可选项有"any"与"all",默认值为"any"删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除,为"all"时,只有一行或一列的所有值都为缺失值时,才进行删除
df.dropna().head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 6 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 广东省 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 08:54:51 |
| 7 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 广东省 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 00:13:28 |
删除空白行,只要给dropna()方法传入一个参数how = "all"即可,这样就会只删除那些全为空值的行,不全为空值的行就不会被删除。
df.dropna(how="all").head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | NaN |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
1.3 缺失值填充
1.3.1 fillna()方法
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
value : 指定需要填充的值, 可以是变量, 字典, Series, or DataFrame,不能是列表
method :指定填充方法,可选项为{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, 默认值 None;(‘backfill’, ‘bfill’向前填充,‘pad’, ‘ffill’向后填充)
axis : 指定填充方向,可选项为{0 or‘index’, 1 or‘columns’}0 or‘index’为行方向,1 or‘columns’为列方向
inplace : 默认值 False。如果为Ture,则修改原数据
limit : 默认值 None; 如果指定了method,则这是连续的NaN值的前向/后向填充的最大数量。 换句话说,如果连续NaN数量超过这个数字,它将只被部分填充。 如果未指定方法,则这是沿着整个轴的最大数量,其中NaN将被填充。 如果不是无,则必须大于0。
downcast : dict, 默认是 None; 如果可能的话,把 item->dtype 的字典将尝试向下转换为适当的相等类型的字符串(例如,如果可能的话,从float64到int64)
方法对数据表中的所有缺失值进行填充,在fillna后面的括号中输入要填充的值即可
df.fillna(0).head() #将所有缺失值填充为0
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | 0 |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | 0 |
也可以按不同列填充,只要在 fillna()方法的括号中指明列名即可。
df.fillna({"退款完成时间":"2020"}).head() # 将退款完成时间列的缺失值填充为2020
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | 2020 |
同时对多列填充不同的值
df.fillna({"xx1":"yyy","xx2":"zzz"}) # 将xx1与xx2列的缺失值分别填充为yyy与zzz
1.4 缺失值替换
1.4.1通过索引位置替换
df.iloc[2,12] = "tihauntime" #对第三行的退款时间NaN替换为tihauntime
df.head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
1.4.2 replace()方法替换
replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method=‘pad’, axis=None)
to_replace :指定需要替换的原值,可以是字符型、正则表达式,列表,等;如用字典{"你":"我","一":"二"}表示用"我"、"二"来替换原值"你"、"一",这时value必须为None
value :指定用于替换to_replace的新值
inplace :值为Ture,则修改原数据,默认False
limit :当指定method方法时,限制向前向后的最大填充个数
method : 指定填充方法,可选项为{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, 默认值 None;(‘backfill’, ‘bfill’向前填充,‘pad’, ‘ffill’向后填充)
df.replace(218.9,666).head() #将表中所有为218.9的值替换为666
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 666.0 | 0.0 | 1 | 666.0 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 666.0 | 0.0 | 1 | 666.0 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 666.0 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 666.0 | 0.0 | 1 | 666.0 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 666.0 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
df.replace([1,"金色110cm 1个"],[666,888]).head() #将表中为1与金色110cm 1个分别替换为666与888
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 666 | 218.9 | 已付款未发货 | 888 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 666 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 666 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 666 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 666 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
1.5 缺失值插入
1.5.1 interpolate()方法用于对缺失值进行插值
**interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=‘forward’, limit_area=None, downcast=None, kwargs)
method : 指定插入方法,{linear:默认,线性插值,忽视索引所有值等距隔开;time:时间插值,索引为时间类型,按给定时间间隔插值;index、value:索引插值,按照数值化的插值进行插值}
axis :表示插入的轴,0表示横轴,1表示纵轴,默认为0
limit :表示遇到NaN插值的最大数
inplace :值为Ture,则修改原数据,默认False
2 重复值处理
2.1 drop_duplicates()方法用于去除一个或多个特征的重复记录
drop_duplicates(subset=None, keep=‘first’, inplace=False)
subset: 列名,默认所有的列
keep: 是否保留{‘first’, ‘last’, False},keep= 'first' 表示去重时每组重复数据保留第一条数据,其余数据丢弃; keep='last' 表示去重时每组重复数据保留最后一条数据,其余数据丢弃;keep=False 表示去重时每组重复数据全部丢弃,不保留
inplace: 是否替换{False, True},inplace=False表示去重之后不覆盖原表格数据,inplace=True表示去重之后原表格数据被覆盖
df.drop_duplicates().head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
针对某一列或某几列进行重复值删除的判断,只需要在drop_duplicates()方法中指明要判断的列名即可。
df.drop_duplicates(subset="市").head() #对市这一列去除重复值
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
| 6 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 广东省 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 08:54:51 |
多列去重,只需要把多个列名以列表的形式传给参数subset即可。
df.drop_duplicates(subset=["市","状态"]).head() #对市与状态这两列进行去重
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
可以自定义删除重复项时保留哪个,默认保留第一个,也可以设置保留最后一个,或者全部不保留。
通过传入参数keep进行设置,参数keep默认值是first,即保留第一个值;
也可以是last,保留最后一个值;
还可以是False,即把重复值全部删除。
df.drop_duplicates(subset=["市","状态"],keep="last").head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
| 7 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 广东省 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 00:13:28 |
df.drop_duplicates(subset=["市","状态"],keep=False).head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
| 8 | 416.9 | 0.0 | 1 | 416.9 | 交易关闭 | 豆绿色S(90-105斤) 1个 | 湖南省 | 衡阳市 | 获取会员信息失败! | 是 | 416.9 | 0.0 | 2020-11-12 08:47:19 |
3 异常值的检测与处理
异常值就是相比正常数据而言过高或过低的数据,和实际情况差距过大
要处理异常值首先要检测,也就是发现异常值,发现异常值的方式主要有以下三种。
● 根据业务经验划定不同指标的正常范围,超过该范围的值算作异常值。
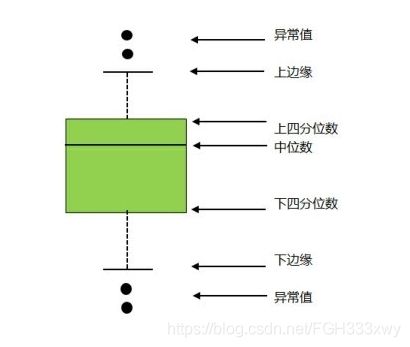
● 通过绘制箱形图,把大于(小于)箱形图上边缘(下边缘)的点称为异常值。
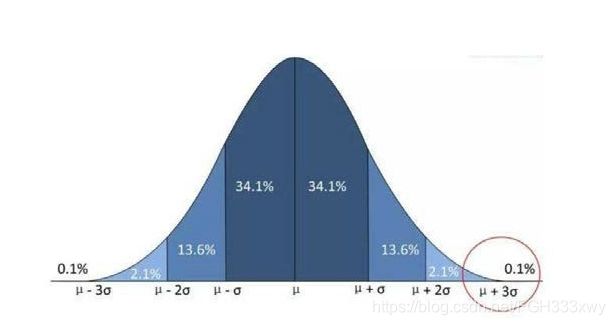
● 如果数据服从正态分布,则可以利用3σ 原则;如果一个数值与平均值之间的偏差超过3倍标准差,那么我们就认为这个值是异常值。
下图为正太分布图,我们把大于μ+3σ的值称为异常值
对于异常值一般有以下几种处理方式。
● 最常用的处理方式就是删除。
● 把异常值当作缺失值来填充。
● 把异常值当作特殊情况,研究异常值出现的原因
Python中是通过过滤的方法对异常值进行删除。比如 df 表中有年龄这个指标,要把年龄大于200的值删掉,你可以通过筛选把年龄不大于200的筛出来,筛出来的部分就是删除大于200的值以后的新表。
对异常值进行填充,就是对异常值进行替换,利用replace()方法可以对特定的值进行替换。
4 数据类型转换
4.1 数据类型
在 Python 中,不仅可以用 info()方法获取每一列的数据类型,还可以通过 dtype方法来获取某一列的数据类型。
df["实际价格(元)"].dtype
dtype('float64')
4.2 类型转换
在Python中,我们利用astype()方法对数据类型进行转换,astype后面的括号里指明要转换的目标类型即可
df["实际价格(元)"].astype("str")
0 218.9
1 218.9
2 328.9
3 218.9
4 185.9
...
83 2199.0
84 658.9
85 328.9
86 328.9
87 328.9
Name: 实际价格(元), Length: 88, dtype: object
5 索引设置
索引是查找数据的依据,设置索引的目的是便于我们查找数据。
5.1 为无索引表添加索引
在Python中,如果表没有索引,会默认用从0开始的自然数做索引
df.index = range(1,89)
df.head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
5.2 重新设置索引
5.2.1 set_index()方法重新设置索引列
在Python中可以利用set_index()方法重新设置索引列,在set_index()里指明要用作行索引的列的名称即可
set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
keys:label 或 array-like 或 list of labels/arrays,此参数可以是单个列键,长度与调用DataFrame相同的单个数组,也可以是包含列键和数组的任意组合的列表。在这里,“array”包含Series,Index,np.ndarray和Iterator。
drop:bool, 默认为 True,删除要用作新索引的列。
append:bool, 默认为 False,是否将列追加到现有索引。
verify_integrity:bool, 默认为 False,检查新索引是否重复。否则,将检查推迟到必要时进行。设置为False将提高此方法的性能。
df.set_index("省").head() #将省列设置为索引列
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 省 | ||||||||||||
| 内蒙古自治区 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 内蒙古自治区 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 山东省 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 浙江省 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 陕西省 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
5.2.2 reindex()方法重建索引
reindex()方法重建索引是Pandas的一个重要方法,主要用于创建一个符合我们需要索引内容的新对象。如果某个索引的值并之前不存在,则会被赋予一个缺失值
reindex(self, labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
labels:类似数组,新标签/索引, 可选参数,新标签/索引与‘axis’指定的轴一致。
index, columns:array-like, 可选参数,要使用的新标签/索引应符合规定。最好是一个Index对象,以避免重复数据。
axis:int 或 str, 可选参数,轴到目标。可以是轴名称(‘index’,‘columns’)或数字(0,1)。
method:{None, ‘backfill’/’bfill’, ‘pad’/’ffill’, ‘nearest’},用于在重新索引的DataFrame中填充孔的方法。请注意:这仅适用于索引单调递增/递减的DataFrames /Series。
copy:bool, 默认为 True,即使传递的索引相同,也返回一个新对象。
level:int 或 name,在一个级别上广播,在传递的MultiIndex级别上匹配索引值。
fill_value:scalar, 默认为 np.NaN,用于缺失值的值。默认为NaN,但可以是任何“compatible”值。
limit:int, 默认为 None,向前或向后填充的连续元素的最大数量。
tolerance: 可选参数,不完全匹配的原始标签和新标签之间的最大距离。匹配位置处的索引值最满足方程abs(index[indexer] - target) <= tolerance。
dyn=pd.Series([405,319,289,276],index=['一','二','三','四'])
print(dyn)
print("="*30)
dy=dyn.reindex(['一','二','三','四','五']) #如果某个索引的值并之前不存在,则会被赋予一个缺失值。
print(dy)
一 405
二 319
三 289
四 276
dtype: int64
==============================
一 405.0
二 319.0
三 289.0
四 276.0
五 NaN
dtype: float64
data=[['晴','阴','雨'],['多云','雨','雨'],['多云','晴','阴']]
wx=pd.DataFrame(data,index=['周一','周二','周三'],columns=['北京','上海','广州'])
print(wx)
print("="*30)
wxr=wx.reindex(['周一','周二','周三','周四'],columns=['北京','上海','广州','深圳'])
print(wxr)
print("="*30)
wxr=wx.reindex(['北京','上海','广州','深圳'],axis="columns")
print(wxr)
北京 上海 广州
周一 晴 阴 雨
周二 多云 雨 雨
周三 多云 晴 阴
==============================
北京 上海 广州 深圳
周一 晴 阴 雨 NaN
周二 多云 雨 雨 NaN
周三 多云 晴 阴 NaN
周四 NaN NaN NaN NaN
==============================
北京 上海 广州 深圳
周一 晴 阴 雨 NaN
周二 多云 雨 雨 NaN
周三 多云 晴 阴 NaN
在重建索引后,如果出现缺失值数据会很不连贯,所以需要根据需要进行填入值。这个功能就由reindex里的fill_value=参数提供。
Series/Dataframe对象.reindex( [ 新索引 ] , fill_value='填充值' )
wxr=wx.reindex(['周一','周二','周三','周四'],columns=['北京','上海','广州','深圳'],fill_value="雪")
wxr
| 北京 | 上海 | 广州 | 深圳 | |
|---|---|---|---|---|
| 周一 | 晴 | 阴 | 雨 | 雪 |
| 周二 | 多云 | 雨 | 雨 | 雪 |
| 周三 | 多云 | 晴 | 阴 | 雪 |
| 周四 | 雪 | 雪 | 雪 | 雪 |
根据前后数据值自动填充
如果对象索引是一个有序的排列,日期、数值等。那么可以使用method参数自动根据前后的数据填写缺少的值。ffill是使用前面的值填充,bfill是使用后面的值填充。这个有序的含义要是机器可以识别的有序
dyn1 = pd.Series([405,319,289,276],index=[0,2,4,6])
print(dyn1)
print("="*30)
dyn2 = dyn1.reindex([0,1,2,3,4,5,6],method='ffill')
print(dyn2)
print("="*30)
dyn3 = dyn1.reindex([0,1,2,3,4,5,6],method='bfill')
print(dyn3)
0 405
2 319
4 289
6 276
dtype: int64
==============================
0 405
1 405
2 319
3 319
4 289
5 289
6 276
dtype: int64
==============================
0 405
1 319
2 319
3 289
4 289
5 276
6 276
dtype: int64
5.3 重命名行列名称
5.3.1 rename()方法重命名列索引
在Python中重命名索引,我们利用的是rename()方法,在rename后的括号里指明要修改的行索引及列索引名。
rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)
mapper, index, columns : 映射的规则。
axis:指定轴,可以是轴名称('index','columns')或数字(0,1),默认为index。
copy:布尔值,默认为True,复制底层数据。
inplace:布尔值,默认为False。指定是否返回新的DataFrame。如果为True,则在原df上修改,返回值为None。
level:int或level name,默认为None。如果是MultiIndex,只重命名指定级别的标签。
df.rename(columns = {"实际价格(元)":"xin实际价格(元)"}).head()
| xin实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
5.3.2 rename()方法重命名列索引重命名行索引
df.rename(index={1:"yi",2:"bashiba"}).head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| yi | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| bashiba | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
5.3.1 rename()方法同时命名行列索引
df.rename (columns={"实际价格(元)":"shijijiage"},index = {2:"er"}).head()
| shijijiage | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| er | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | tihauntime |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
5.4 重置索引
重置索引主要用在层次化索引表中,重置索引是将索引列当作一个columns进行返回。
在下图左侧的表中,Z1、Z2是一个层次化索引,经过重置索引以后,Z1、Z2这两个索引以columns的形式返回,变为常规的两列。
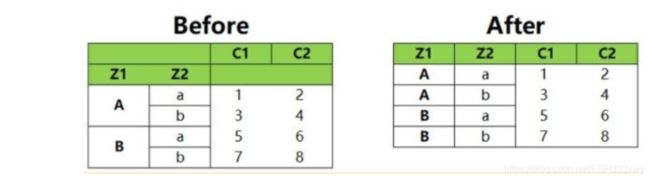
Python利用的是reset_index()方法,reset_index()方法常用的参数如下:
reset_index(level=None,drop =False,inplace = False)
level参数用来指定要将层次化索引的第几级别转化为columns,第一个索引为0级,第二个索引为1级,默认为全部索引,即默认把索引全部转化为columns。
drop参数用来指定是否将原索引删掉,即不作为一个新的columns,默认为False,即不删除原索引。
inplace参数用来指定是否修改原数据表
6 数据删除
6.1 删除列
pandas 提供了两种删除数据的方法:del 和 drop。
del 可以删除某列
drop 可以删除某行或某列
6.1.1 del 删除列
方法一:直接del(DF[‘column-name’]) 或 del DF[‘column-name’]
del df["区"]
df.head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 优惠信息 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 无优惠信息 | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 无优惠信息 | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 无优惠信息 | 否 | 0.0 | 0.0 | NaN |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 无优惠信息 | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 无优惠信息 | 是 | 0.0 | 0.0 | NaN |
6.1.2 drop()方法
drop(lables=None,axis=0,index=None,columns=None,level=None,inplace=None,errors=“raise” )
labels : 指行或列名(必须和axis一起使用)
axis :指定维度方向
index :指定列索引值
columns :指定行索引值
level :指定行多层级索引情况下的层级
inplace :指定是否对原数据进行修改
error :出错提示
df.drop("优惠信息",axis=1,inplace=True) #删除列,必须与axis=1一起使用,删除多列用列表形式([ ,])
df.head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 省 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 2 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 内蒙古自治区 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 3 | 328.9 | 0.0 | 1 | 328.9 | 交易取消 | 米白S 1个 | 山东省 | 枣庄市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | NaN |
| 4 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 浙江省 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 5 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 陕西省 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
df.drop(columns=["",""],inplace=True) #指定columns不须与axis=1一起使用
df.head()
6.2 删除行
df.set_index("省").drop("山东省").head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 省 | ||||||||||||
| 内蒙古自治区 | 218.9 | 0.0 | 1 | 218.9 | 已付款未发货 | 金色110cm 1个 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 0.0 | 0.0 | tihauntime |
| 内蒙古自治区 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 金色120cm 1个 | 呼伦贝尔市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 09:35:43 |
| 浙江省 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 陕西省 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
| 广东省 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 08:54:51 |
df.set_index("省").drop(["山东省","内蒙古自治区"]).head()
| 实际价格(元) | 运费(元) | 数量 | 实际支付(元) | 状态 | 商品SKU信息 | 市 | 会员等级 | 是否白付美支付 | 货款退款金额 | 运费退款金额 | 退款完成时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 省 | ||||||||||||
| 浙江省 | 218.9 | 0.0 | 1 | 218.9 | 交易关闭 | 黑色M 105-120斤 1个 | 嘉兴市 | 获取会员信息失败! | 否 | 218.9 | 0.0 | 2020-11-12 06:37:25 |
| 陕西省 | 185.9 | 0.0 | 1 | 185.9 | 已付款未发货 | 黑色L 1个 | 咸阳市 | 获取会员信息失败! | 是 | 0.0 | 0.0 | NaN |
| 广东省 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 08:54:51 |
| 广东省 | 196.9 | 0.0 | 1 | 196.9 | 交易关闭 | 黑色M 1个 | 湛江市 | 获取会员信息失败! | 是 | 196.9 | 0.0 | 2020-11-12 00:13:28 |
| 湖南省 | 416.9 | 0.0 | 1 | 416.9 | 交易关闭 | 豆绿色S(90-105斤) 1个 | 衡阳市 | 获取会员信息失败! | 是 | 416.9 | 0.0 | 2020-11-12 08:47:19 |