python | 编译原理,语法分析——LR(1)文法实现
LR(1)文法的意思是从左向右扫描,最右推导,往前多看一个字符。
LR(1)文法也需要构造要给预测分析表,但是LR(1)的的预测分析表有两部分,分别是action表和goto表。
action表的横坐标是不同的状态标号,纵坐标是不同的终结符,goto表的横坐标也是不同状态标号,纵坐标是不同的非终结符。
action表中有si、rj、acc和空白,其中si表示推进至状态i,将当前输入符号和状态i入栈,rj按第j个产生式进行规约,栈首弹出,利用产生式生成,入栈,转移状态也同时入栈。acc表示接受,即算法结束。空白表示出错。
goto表中表示从某个状态规约后,遇到产生式左边某个非终结符后转移到的状态。
我们以下面这个预测分析表为例:
(这里是部分预测分析表)

《编译原理(第3版)》(陈意云等编著)这本书里把用预测分析表进行预测的方法用伪代码写了出来,我写在下方。
令a是w$的第一个符号
while(1){
令s是栈顶的状态
if(action[s,a] == 移进t){
把a和t依次压入栈
令a是下一个输入符号
}else if(action[s,a] == 规约 A -> beta){
栈顶退掉2 *|beta|个符号
令t是现在的栈顶状态
把A和goto[t,A]压入栈
输出产生式A -> beta
}else if(action[s,a] == 接受) break;
else 调用错误恢复例程
}
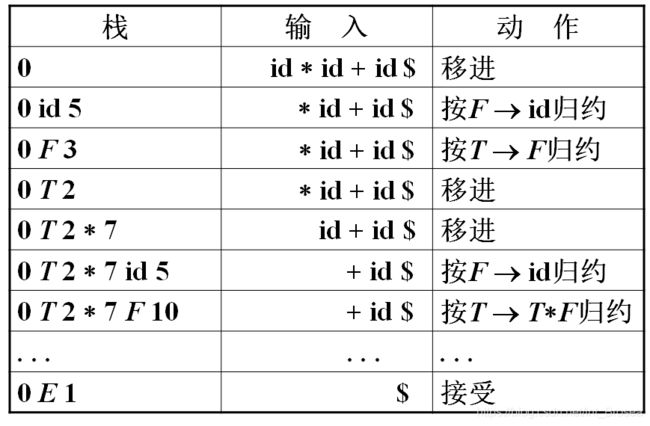
给大家一个表作为演示。
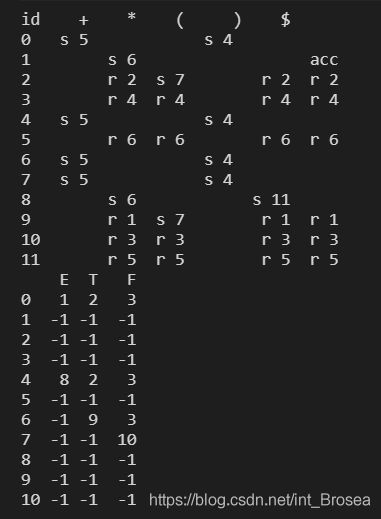
这里我是手动生成的预测分析表:
vt = ['id','+','*','(',')','$']
vn = ['E','T','F']
actionData = [['' for i in range(len(vt))] for j in range(12)]
Action = pd.DataFrame(data = actionData,index=range(12),columns=vt)
gotoData = [[-1 for i in range(len(vn))] for j in range(12)]
Goto = pd.DataFrame(data = gotoData,index=range(12),columns=vn)
Action.loc[0]['id'] = 's 5'
Action.loc[0]['('] = 's 4'
Action.loc[1]['+'] = 's 6'
Action.loc[1]['$'] = 'acc'
Action.loc[2]['+'] = 'r 2'
Action.loc[2]['*'] = 's 7'
Action.loc[2][')'] = 'r 2'
Action.loc[2]['$'] = 'r 2'
Action.loc[3]['+'] = 'r 4'
Action.loc[3]['*'] = 'r 4'
Action.loc[3][')'] = 'r 4'
Action.loc[3]['$'] = 'r 4'
Action.loc[4]['id'] = 's 5'
Action.loc[4]['('] = 's 4'
Action.loc[5]['+'] = 'r 6'
Action.loc[5]['*'] = 'r 6'
Action.loc[5][')'] = 'r 6'
Action.loc[5]['$'] = 'r 6'
Action.loc[6]['id'] = 's 5'
Action.loc[6]['('] = 's 4'
Action.loc[7]['id'] = 's 5'
Action.loc[7]['('] = 's 4'
Action.loc[8]['+'] = 's 6'
Action.loc[8][')'] = 's 11'
Action.loc[9]['+'] = 'r 1'
Action.loc[9]['*'] = 's 7'
Action.loc[9][')'] = 'r 1'
Action.loc[9]['$'] = 'r 1'
Action.loc[10]['+'] = 'r 3'
Action.loc[10]['*'] = 'r 3'
Action.loc[10][')'] = 'r 3'
Action.loc[10]['$'] = 'r 3'
Action.loc[11]['+'] = 'r 5'
Action.loc[11]['*'] = 'r 5'
Action.loc[11][')'] = 'r 5'
Action.loc[11]['$'] = 'r 5'
Goto.loc[0]['E'] = 1
Goto.loc[0]['T'] = 2
Goto.loc[0]['F'] = 3
Goto.loc[4]['E'] = 8
Goto.loc[4]['T'] = 2
Goto.loc[4]['F'] = 3
Goto.loc[6]['T'] = 9
Goto.loc[6]['F'] = 3
Goto.loc[7]['F'] = 10
print(Action)
print(Goto)
LR(1)预测
def getRes(lang):
V = lang.split(' ')
V.append('$')
print('V is ',V)
sta = Stack()
sta.push('0')
i = 0
a = V[0]
while True:
s = int(sta.top())
curAct = Action[a][s].split(' ')
if curAct[0] == 's':
sta.push(a)
sta.push(str(curAct[1]))
i = i+1
a = V[i]
print('移进')
elif curAct[0] == 'r':
curProd = productions[int(curAct[1])-1]
for j in range(2*(len(curProd)-1)):
sta.pop()
t = sta.top()
A = curProd[0]
sta.push(A)
sta.push(str(Goto[A][int(t)]))
print('输出 ', ' '.join(curProd),' 规约')
elif curAct[0] == 'acc':
print('分析完成')
break
else:
raise error()
print('栈中为 ',sta.show())
print('输入为 ',' '.join(V[i:]))
print()
运行结果为:
V is ['id', '*', 'id', '+', 'id', '$']
移进
输入为 * id + id $
栈中为 0 id 5
输出 F id 规约
输入为 * id + id $
栈中为 0 F 3
输出 T F 规约
输入为 * id + id $
栈中为 0 T 2
移进
输入为 id + id $
栈中为 0 T 2 * 7
移进
输入为 + id $
栈中为 0 T 2 * 7 id 5
输出 F id 规约
输入为 + id $
栈中为 0 T 2 * 7 F 10
输出 T T * F 规约
输入为 + id $
栈中为 0 T 2
输出 E T 规约
输入为 + id $
栈中为 0 E 1
移进
输入为 id $
栈中为 0 E 1 + 6
移进
输入为 $
栈中为 0 E 1 + 6 id 5
输出 F id 规约
输入为 $
栈中为 0 E 1 + 6 F 3
输出 T F 规约
输入为 $
栈中为 0 E 1 + 6 T 9
输出 E E + T 规约
输入为 $
栈中为 0 E 1
分析完成
完整代码:
import pandas as pd
sentence = "id * id + id"
# 读入文法
gramma = open("5_gramma1.txt",'r')
# 把文法中A->B|C 切分为A->B和A->C
def splitOr(gramma):
stack = []
for i in gramma:
i = i.split(' ')
ss = i[0]
j = 1
while j<len(i):
if i[j] == "->":
break
j+=1
j+=1
while j<len(i):
if i[j][-1] == '\n':
i[j] = i[j][0:-1]
if i[j] != '|':
ss+=" "+i[j]
else:
stack.append(ss.split(' '))
ss = i[0]
j+=1
stack.append(ss.split(' '))
return stack
productions = splitOr(gramma)
print(productions)
vt = ['id','+','*','(',')','$']
vn = ['E','T','F']
actionData = [['' for i in range(len(vt))] for j in range(12)]
Action = pd.DataFrame(data = actionData,index=range(12),columns=vt)
gotoData = [[-1 for i in range(len(vn))] for j in range(12)]
Goto = pd.DataFrame(data = gotoData,index=range(12),columns=vn)
Action.loc[0]['id'] = 's 5'
Action.loc[0]['('] = 's 4'
Action.loc[1]['+'] = 's 6'
Action.loc[1]['$'] = 'acc'
Action.loc[2]['+'] = 'r 2'
Action.loc[2]['*'] = 's 7'
Action.loc[2][')'] = 'r 2'
Action.loc[2]['$'] = 'r 2'
Action.loc[3]['+'] = 'r 4'
Action.loc[3]['*'] = 'r 4'
Action.loc[3][')'] = 'r 4'
Action.loc[3]['$'] = 'r 4'
Action.loc[4]['id'] = 's 5'
Action.loc[4]['('] = 's 4'
Action.loc[5]['+'] = 'r 6'
Action.loc[5]['*'] = 'r 6'
Action.loc[5][')'] = 'r 6'
Action.loc[5]['$'] = 'r 6'
Action.loc[6]['id'] = 's 5'
Action.loc[6]['('] = 's 4'
Action.loc[7]['id'] = 's 5'
Action.loc[7]['('] = 's 4'
Action.loc[8]['+'] = 's 6'
Action.loc[8][')'] = 's 11'
Action.loc[9]['+'] = 'r 1'
Action.loc[9]['*'] = 's 7'
Action.loc[9][')'] = 'r 1'
Action.loc[9]['$'] = 'r 1'
Action.loc[10]['+'] = 'r 3'
Action.loc[10]['*'] = 'r 3'
Action.loc[10][')'] = 'r 3'
Action.loc[10]['$'] = 'r 3'
Action.loc[11]['+'] = 'r 5'
Action.loc[11]['*'] = 'r 5'
Action.loc[11][')'] = 'r 5'
Action.loc[11]['$'] = 'r 5'
Goto.loc[0]['E'] = 1
Goto.loc[0]['T'] = 2
Goto.loc[0]['F'] = 3
Goto.loc[4]['E'] = 8
Goto.loc[4]['T'] = 2
Goto.loc[4]['F'] = 3
Goto.loc[6]['T'] = 9
Goto.loc[6]['F'] = 3
Goto.loc[7]['F'] = 10
print(Action)
print(Goto)
class Stack(object):
def __init__(self):
self.__list = []
def push(self,item):
self.__list.append(item)
def pop(self):
return self.__list.pop()
def top(self):
if self.__list:
return self.__list[-1]
return None
def is_empty(self):
return self.__list == []
def size(self):
return len(self.__list)
def show(self):
return ' '.join(self.__list)
def getRes(lang):
V = lang.split(' ')
V.append('$')
print('V is ',V)
sta = Stack()
sta.push('0')
i = 0
a = V[0]
while True:
s = int(sta.top())
curAct = Action[a][s].split(' ')
if curAct[0] == 's':
sta.push(a)
sta.push(str(curAct[1]))
i = i+1
a = V[i]
print('移进')
elif curAct[0] == 'r':
curProd = productions[int(curAct[1])-1]
for j in range(2*(len(curProd)-1)):
sta.pop()
t = sta.top()
A = curProd[0]
sta.push(A)
sta.push(str(Goto[A][int(t)]))
print('输出 ', ' '.join(curProd),' 规约')
elif curAct[0] == 'acc':
print('分析完成')
break
else:
raise error()
print('栈中为 ',sta.show())
print('输入为 ',' '.join(V[i:]))
print()
getRes(sentence)