一份热力图可视化代码使用教程
前言 特征图可视化与热力图可视化是论文中比较常用的两种可视化方法。上一篇文章《一份可视化特征图的代码》介绍了特征图可视化的代码,本篇将对如何进行热力图可视化做一个使用说明。
本文介绍了CAM、GradCAM的原理和缺陷,介绍了如何使用GradCAM算法实现热力图可视化,介绍了目标检测、语义分割、transformer模型等其它类型任务的热力图可视化。
本文来自公众号CV技术指南的技术总结系列
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
热力图可视化方法的原理
在一个神经网络模型中,图片经过神经网络得到类别输出,我们并不知道模型是根据什么来作出预测的,换言之,我们需要了解图片中各个区域对模型作出预测的影响有多大。这就是热力图的作用,它通过得到图像不同区域之间对模型的重要性而生成一张类似于等温图的图片。

热力图可视化方法经过了从CAM,GradCAM,到GradCAM++的过程,比较常用的是GradCAM算法。
CAM
CAM论文:Learning Deep Features for Discriminative Localization
CAM的原理是取出全连接层中得到类别C的概率的那一维权值,用W表示。然后对GAP前的feature map进行加权求和,由于此时feature map不是原图像大小,在加权求和后还需要进行上采样,即可得到Class Activation Map。
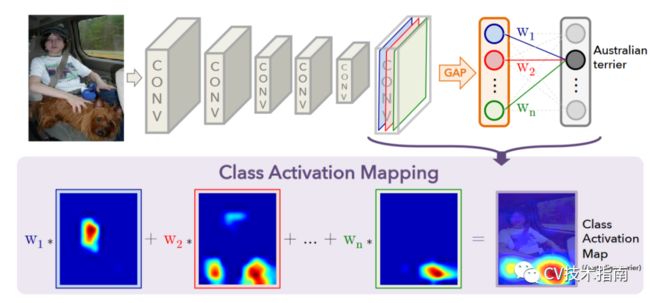
CAM有个很致命的缺陷,它的结构是由CNN + GAP + FC + Softmax组成。也就是说如果想要可视化某个现有的模型,对于没有GAP的模型来说需要修改原模型结构,并重新训练,相当麻烦,且如果模型很大,在修改后重新训练不一定能达到原效果,可视化也就没有意义了。
因此,针对这个缺陷,其后续有了改进版Grad-CAM。
GradCAM
Grad-CAM论文:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Grad-CAM的最大特点就是不再需要修改现有的模型结构了,也不需要重新训练了,直接在原模型上即可可视化。
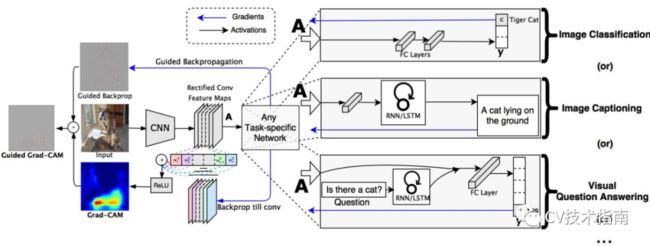
原理:同样是处理CNN特征提取网络的最后一层feature maps。Grad-CAM对于想要可视化的类别C,使最后输出的类别C的概率值通过反向传播到最后一层feature maps,得到类别C对该feature maps的每个像素的梯度值,对每个像素的梯度值取全局平均池化,即可得到对feature maps的加权系数alpha,论文中提到这样获取的加权系数跟CAM中的系数的计算量几乎是等价的。接下来对特征图加权求和,使用ReLU进行修正,再进行上采样。
使用ReLU的原因是对于那些负值,可认为与识别类别C无关,这些负值可能是与其他类别有关,而正值才是对识别C有正面影响的。
具体公式如下:

Grad-CAM后续还有改进版Grad-CAM++,其主要的改进效果是定位更准确,更适合同类多目标的情况,所谓同类多目标是指一张图像中对于某个类出现多个目标,例如七八个人。改进方法是对加权系数的获取提出新的方法,该方法很复杂,这里不介绍。
GradCAM的使用教程
这份代码来自GradCAM论文作者,原链接中包含了很多其它的CAM,这里将GradCAM摘出来对其做一个使用说明。
代码原链接:https://github.com/jacobgil/pytorch-grad-cam/tree/master/pytorch_grad_cam
本教程代码链接:https://github.com/CV-Tech-Guide/Visualize-feature-maps-and-heatmap
使用流程
使用起来比较简单,仅了解主函数即可。
if __name__ == "__main__":
imgs_path = "path/to/image.png"
model = models.mobilenet_v3_large(pretrained=True)
model.load_state_dict(torch.load('model.pth'))
model = model.cuda().eval()
#target_layers指的是需要可视化的层,这里可视化最后一层
target_layers = [model.features[-1]]
img, data = image_proprecess(imgs_path)
data = data.cuda()
cam = GradCAM(model=model, target_layers=target_layers)
#指定可视化的类别,指定为None,则按照当前预测的最大概率的类作为可视化类。
target_category = None
grayscale_cam = cam(input_tensor=data, target_category=target_category)
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(np.array(img) / 255., grayscale_cam)
plt.imshow(visualization)
plt.xticks()
plt.yticks()
plt.axis('off')
plt.savefig("path/to/gradcam_image.jpg")
如上代码所示,仅需要自主设置输入图片,模型,可视化层,可视化类别即可,其它的部分可完全照用。
下面介绍细节部分。
数据预处理
这里跟上次可视化特征图的代码一样,将图片读取,resize,转化为Tensor,格式化,若只有一张图片,则还需要将其扩展为四维。
def image_proprecess(img_path):
img = Image.open(img_path)
data_transforms = transforms.Compose([
transforms.Resize((384, 384), interpolation=3),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
data = data_transforms(img)
data = torch.unsqueeze(data,0)
img_resize = img.resize((384,384))
return img_resize,data
GradCAM
GradCAM这个类是按照前面第一节中介绍的原理封装的,因此了解原理后再了解这个类的代码就比较简单了。
class GradCAM:
def __init__(self, model, target_layers, reshape_transform=None):
self.model = model.eval()
self.target_layers = target_layers
self.reshape_transform = reshape_transform
self.cuda = use_cuda
self.activations_and_grads = ActivationsAndGradients(
self.model, target_layers, reshape_transform)
""" Get a vector of weights for every channel in the target layer.
Methods that return weights channels,
will typically need to only implement this function. """
@staticmethod
def get_cam_weights(grads):
return np.mean(grads, axis=(2, 3), keepdims=True)
@staticmethod
def get_loss(output, target_category):
loss = 0
for i in range(len(target_category)):
loss = loss + output[i, target_category[i]]
return loss
def get_cam_image(self, activations, grads):
weights = self.get_cam_weights(grads)
weighted_activations = weights * activations
cam = weighted_activations.sum(axis=1)
return cam
@staticmethod
def get_target_width_height(input_tensor):
width, height = input_tensor.size(-1), input_tensor.size(-2)
return width, height
def compute_cam_per_layer(self, input_tensor):
activations_list = [a.cpu().data.numpy()
for a in self.activations_and_grads.activations]
grads_list = [g.cpu().data.numpy()
for g in self.activations_and_grads.gradients]
target_size = self.get_target_width_height(input_tensor)
cam_per_target_layer = []
# Loop over the saliency image from every layer
for layer_activations, layer_grads in zip(activations_list, grads_list):
cam = self.get_cam_image(layer_activations, layer_grads)
cam[cam < 0] = 0 # works like mute the min-max scale in the function of scale_cam_image
scaled = self.scale_cam_image(cam, target_size)
cam_per_target_layer.append(scaled[:, None, :])
return cam_per_target_layer
def aggregate_multi_layers(self, cam_per_target_layer):
cam_per_target_layer = np.concatenate(cam_per_target_layer, axis=1)
cam_per_target_layer = np.maximum(cam_per_target_layer, 0)
result = np.mean(cam_per_target_layer, axis=1)
return self.scale_cam_image(result)
@staticmethod
def scale_cam_image(cam, target_size=None):
result = []
for img in cam:
img = img - np.min(img)
img = img / (1e-7 + np.max(img))
if target_size is not None:
img = cv2.resize(img, target_size)
result.append(img)
result = np.float32(result)
return result
def __call__(self, input_tensor, target_category=None):
# 正向传播得到网络输出logits(未经过softmax)
output = self.activations_and_grads(input_tensor)
if isinstance(target_category, int):
target_category = [target_category] * input_tensor.size(0)
if target_category is None:
target_category = np.argmax(output.cpu().data.numpy(), axis=-1)
print(f"category id: {target_category}")
else:
assert (len(target_category) == input_tensor.size(0))
self.model.zero_grad()
loss = self.get_loss(output, target_category)
loss.backward(retain_graph=True)
# In most of the saliency attribution papers, the saliency is
# computed with a single target layer.
# Commonly it is the last convolutional layer.
# Here we support passing a list with multiple target layers.
# It will compute the saliency image for every image,
# and then aggregate them (with a default mean aggregation).
# This gives you more flexibility in case you just want to
# use all conv layers for example, all Batchnorm layers,
# or something else.
cam_per_layer = self.compute_cam_per_layer(input_tensor)
return self.aggregate_multi_layers(cam_per_layer)
def __del__(self):
self.activations_and_grads.release()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, exc_tb):
self.activations_and_grads.release()
if isinstance(exc_value, IndexError):
# Handle IndexError here...
print(
f"An exception occurred in CAM with block: {exc_type}. Message: {exc_value}")
return True
简要说明一下整体在做什么,先通过下方的ActivationsAndGradients获取模型推理过程中的梯度和激活函数值,计算要可视化的类的loss(其它类的都忽略),通过这个loss计算可视化类对应的梯度图,将其进行全局平均池化获得每个feature maps通道的加权系数,与feature maps进行通道上加权,并在通道上做均值获得单通道图,再ReLU即输出对应的图。注:此图还不是热力图,还需要与原图相加才能获得最终的热力图。
GradCAM这个类主要就是先定义,再调用执行。定义须输入网络和需要可视化的层,执行则需要输入图片和可视化的类别。
执行返回的是区域重要性图。
cam = GradCAM(model=model, target_layers=target_layers)
#指定可视化的类别,指定为None,则按照当前预测的最大概率的类作为可视化类。
target_category = None
grayscale_cam = cam(input_tensor=data, target_category=target_category)
获取推理过程中的梯度主要是通过以下这个类来完成。这里不多介绍。
class ActivationsAndGradients:
""" Class for extracting activations and
registering gradients from targeted intermediate layers """
def __init__(self, model, target_layers, reshape_transform):
self.model = model
self.gradients = []
self.activations = []
self.reshape_transform = reshape_transform
self.handles = []
for target_layer in target_layers:
self.handles.append(
target_layer.register_forward_hook(
self.save_activation))
# Backward compatibility with older pytorch versions:
if hasattr(target_layer, 'register_full_backward_hook'):
self.handles.append(
target_layer.register_full_backward_hook(
self.save_gradient))
else:
self.handles.append(
target_layer.register_backward_hook(
self.save_gradient))
def save_activation(self, module, input, output):
activation = output
if self.reshape_transform is not None:
activation = self.reshape_transform(activation)
self.activations.append(activation.cpu().detach())
def save_gradient(self, module, grad_input, grad_output):
# Gradients are computed in reverse order
grad = grad_output[0]
if self.reshape_transform is not None:
grad = self.reshape_transform(grad)
self.gradients = [grad.cpu().detach()] + self.gradients
def __call__(self, x):
self.gradients = []
self.activations = []
return self.model(x)
def release(self):
for handle in self.handles:
handle.remove()
然后就是将GradCAM输出的重要性图在原图上显示,通过下面这个函数完成。
def show_cam_on_image(img: np.ndarray,
mask: np.ndarray,
use_rgb: bool = False,
colormap: int = cv2.COLORMAP_JET) -> np.ndarray:
""" This function overlays the cam mask on the image as an heatmap.
By default the heatmap is in BGR format.
:param img: The base image in RGB or BGR format.
:param mask: The cam mask.
:param use_rgb: Whether to use an RGB or BGR heatmap, this should be set to True if 'img' is in RGB format.
:param colormap: The OpenCV colormap to be used.
:returns: The default image with the cam overlay.
"""
heatmap = cv2.applyColorMap(np.uint8(255 * mask), colormap)
if use_rgb:
heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB)
heatmap = np.float32(heatmap) / 255
if np.max(img) > 1:
raise Exception(
"The input image should np.float32 in the range [0, 1]")
cam = heatmap + img
cam = cam / np.max(cam)
return np.uint8(255 * cam)
前面介绍的仅仅是分类任务的热力图可视化,但对于目标检测,语义分割等这些包含多任务的应用如何做?
其它类型任务的热力图可视化
在gradCAM论文作者给出的代码中还介绍了如何可视化目标检测、语义分割、transformer的代码。由于作者提供了使用方法,这里不多介绍,直接给出作者写得教程。
-
Notebook tutorial: Class Activation Maps for Object Detection with Faster-RCNN
-
Notebook tutorial: Class Activation Maps for Semantic Segmentation
-
How it works with Vision/SwinT transformers
地址:https://github.com/jacobgil/pytorch-grad-cam
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV技术指南创建了一个交流氛围很不错的群,除了太偏僻的问题,几乎有问必答。关注公众号添加编辑的微信号可邀请加交流群。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章
一份可视化特征图的代码
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(一)数据读取
工业图像异常检测研究总结(2019-2020)
用什么tricks能让模型训练得更快?模型训练慢的可能原因总结
小样本学习研究综述(中科院计算所)
目标检测中正负样本区分策略和平衡策略总结
模型量化技巧及在低功耗IOT设备的应用实践
NeurIPS 2021 | 从进化算法角度解释Transformer架构,并提出针对多模态任务的统一序列模型范式
CVPR2022 | 单GPU每秒76帧,重叠对象也能完美分割,多模态Transformer用于视频分割效果惊艳
目标检测中的框位置优化总结
目标检测、实例分割、多目标跟踪的Anchor-free应用方法总结
Soft Sampling:探索更有效的采样策略
如何解决工业缺陷检测小样本问题
机器学习、深度学习面试知识点汇总
深度学习图像识别的未来:机遇与挑战并存
关于快速学习一项新技术或新领域的一些个人思维习惯与思想总结