语音增强相关技术综述
1 非监督语音增强技术
2 监督语音增强技术
3 github上提供的源代码及分析
3.1 Dual-signal Transformation LSTM Network
简介
https://github.com/breizhn/DTLN
- 用于实时噪声抑制的堆叠双信号变换 LSTM 网络 (DTLN) 的 Tensorflow 2.x 实现。
- 这个存储库提供了在 python 中训练、推断和服务 DTLN 模型的代码。 它还提供了 SavedModel、TF-lite 和 ONNX 格式的预训练模型,可用作您自己项目的基线。 该模型能够在 RaspberryPi 上以实时音频运行。
- 如果你正在用这个 repo 做很酷的事情,请告诉我。 我总是很好奇你用这段代码或这个模型做什么。
DTLN 模型被提交给深度噪声抑制挑战(DNS-Challenge),论文在 Interspeech 2020 上发表。
该方法在参数少于一百万的堆叠网络方法中结合了短时傅立叶变换 (STFT) 及学习分析和合成基础。该模型接受了挑战组织者提供的 500 小时嘈杂语音的训练。 该网络能够实时处理(一帧输入,一帧输出)并达到有竞争力的结果。结合这两种类型的信号变换,DTLN 能够从幅度谱中稳健地提取信息,并从学习到的特征基础中结合相位信息。 该方法显示了最先进的性能,并且在平均意见得分 (MOS) 方面绝对优于 DNS-Challenge 基线 0.24 分。
有关更多信息,请参阅论文。 DNS-Challenge 的结果在此处发布。 在实时赛道上,我们在 17 支球队中获得了竞争激烈的第 8 名。
我们的实验
目前主要实验了DTLN模型对音频进行降噪处理之后,对于识别准确率的影响。我分别使用该模型对之前划分的高质量和低质量音频以及不做划分的音频进行降噪处理,处理后的音频测试结果如下:
| 降噪前 | 降噪后 | |
|---|---|---|
| 无划分 | 0.5699 | 0.5054 |
| 高质量 | 0.7241 | 0.6207 |
| 低质量 | 0.3143 | 0.1429 |
从表格中可以得出,使用DTLN模型对音频进行降噪之后,无论是针对高质量好还是低质量音频又或者是原始音频都会使准确率下降。
接下来还会继续调研其它降噪模型以及语音增强的方法。
3.2 Speech Enhancement based on DNN (TF-Masking, Spectral-Mapping), DNN-NMF, NMF
NMF based SE
非负矩阵分解 (NMF) 可用于从混合数据中分离目标源。 所有源的基矩阵是通过连接各个源的基矩阵来构建的,以便基矩阵和编码矩阵的相应部分的乘积成为分离的目标源。
DNN-NMF based SE
在 DNN-NMF 模型 [1] 中,使用深度神经网络 (DNN) 来估计编码向量,以提高具有源子空间重叠的目标数据提取算法的性能。
DNN based SE
使用DNN的语音增强主要有两组,即基于掩码的模型(TF-Masking)[2]和基于映射的模型(Spectral-Mapping)[3]。 TF-Masking 模型描述了干净语音与背景干扰的时频关系,而频谱映射模型对应于干净语音的频谱表示 [2]。
Statistical model based SE
https://github.com/eesungkim/Speech_Enhancement_MMSE-STSA
Implementations
- Settings
Sampling Rate : 16kHz
512-point Hamming window with 75% overlap. - Dataset
干净的语音数据取自 TIMIT 数据库。 我们为训练集选择了 62 个话语,为测试集选择了 10 个话语。 完整的 TIMIT 数据集将进一步增强 PESQ 性能。 NOISEX-92 数据库中的工厂、杂音、机枪噪声用于训练和测试。
来自 5 位男性和 5 位女性演讲者的 10 句话用于绩效评估。 所有模型都经过 3 种类型(工厂、嗡嗡声、机枪)噪声的训练,这些噪声汇集在一起,以检查所提出的算法是否可以同时学习各种类型的源特征。
References
[1] T. G. Kang, K. Kwon, J. W. Shin, and N. S. Kim, “NMF-based target source separation using deep neural network,” IEEE Signal Processing Letters, vol. 22, no. 2, pp. 229-233, Feb. 2015.
[2] Wang, DeLiang, and Jitong Chen. “Supervised speech separation based on deep learning: An overview.” IEEE/ACM Transactions on Audio, Speech, and Language Processing (2018).
[3] Xu, Yong, et al. “A regression approach to speech enhancement based on deep neural networks.” IEEE/ACM Transactions on Audio, Speech and Language Processing, Jan. 2015.
3.3 Speech-enhancement with Deep learning
简介
该项目旨在构建语音增强系统以减弱环境噪声。

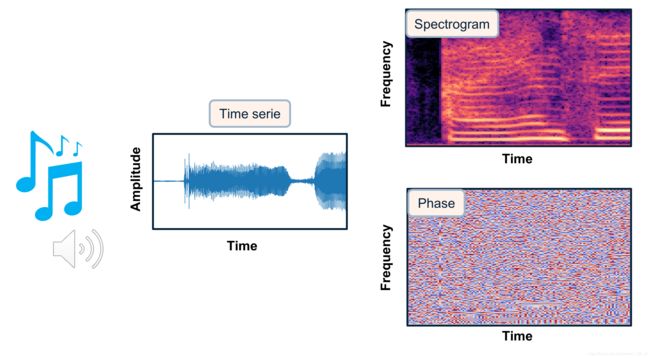
音频有许多不同的表示方式,从原始时间序列到时频分解。 表示的选择对于系统的性能至关重要。 在时频分解中,频谱图已被证明是音频处理的有用表示。 它们包括表示以时间和频率为轴的短时傅立叶变换 (STFT) 序列的 2D 图像,以及表示每个时间帧频率分量强度的亮度。 在这种情况下,它们似乎是将 CNNS 架构直接应用于声音的自然领域。 在幅度谱图和相位谱图之间,幅度谱图包含信号的大部分结构。 相位谱图似乎只显示出很少的时间和光谱规律。
在这个项目中,我将使用幅度谱图作为声音的表示(参见下图),以预测要减去噪声语音谱图的噪声模型。
该项目分解为三种模式:数据创建、训练和预测。
准备数据
为了创建训练数据集,我收集了来自不同来源的英语语音干净的声音和环境噪声。
干净的声音主要来自 LibriSpeech:一个基于公共领域有声读物的 ASR 语料库。 我也使用了一些来自 SiSec 的数据。 环境噪声来自 ESC-50 数据集或 https://www.ee.columbia.edu/~dpwe/sounds/。
在这个项目中,我专注于 10 类环境噪音:滴答声、脚步声、铃铛、手锯、闹钟、烟花、昆虫、刷牙、吸尘器和打鼾。 这些类如下图所示(我使用来自 https://unsplash.com 的图片创建了此图像)。
为了创建用于训练/验证/测试的数据集,音频以 8kHz 采样,我提取的窗口略高于 1 秒。 我对环境噪声进行了一些数据增强(在不同时间取窗口会产生不同的噪声窗口)。 噪音已经混合到干净的声音中,噪音水平随机化(20% 到 80%)。 最后,训练数据包括 10 小时嘈杂的声音和干净的声音,以及 1 小时的声音验证数据。
为了准备数据,我建议在与代码文件夹分开的位置创建 data/Train 和 data/Test 文件夹。 然后创建以下结构,如下图所示:

您将相应地修改 noise_dir、voice_dir、path_save_spectrogram、path_save_time_serie 和 path_save_sound 路径名称到采用程序默认参数的 args.py 文件中。
将您的噪音音频文件放入noise_dir 目录,将您干净的语音文件放入voice_dir。
在 args.py 中指定要创建为 nb_samples 的帧数(或将其作为参数从终端传递)我默认情况下让 nb_samples=50 用于演示,但对于生产,我建议使用 40 000 或更多。
然后运行 python main.py --mode=‘data_creation’。这将随机混合来自 voice_dir 的一些干净的声音和来自 noise_dir 的一些噪音,并将嘈杂的声音、噪音和干净的声音的频谱图以及复杂的相位、时间序列和声音保存到磁盘(用于 QC 或测试其他网络)。它采用 args.py 中定义的输入参数。 STFT、帧长度、hop_length 的参数可以在 args.py 中修改(或将其作为参数从终端传递),但使用默认参数,每个窗口将转换为大小为 128 x 128 的频谱图矩阵。
用于训练的数据集将是嘈杂声音的幅度谱图和干净声音的幅度谱图。
训练
用于训练的模型是 U-Net,一种具有对称跳过连接的深度卷积自动编码器。 U-Net 最初是为生物医学图像分割而开发的。 在这里,U-Net 已经适应去噪频谱图。
作为网络的输入,嘈杂声音的幅度谱图。 作为输出模型的噪声(嘈杂的语音幅度谱图 - 干净的语音幅度谱图)。 输入和输出矩阵都使用全局缩放进行缩放,以映射到 -1 和 1 之间的分布。

在训练期间测试了许多配置。对于首选配置,编码器由 10 个卷积层组成(使用 LeakyReLU、maxpooling 和 dropout)。解码器是具有跳跃连接的对称扩展路径。最后一个激活层是一个双曲正切 (tanh),输出分布在 -1 和 1 之间。为了从头开始训练,初始随机权重设置为 He 法线初始化器。
模型使用 Adam 优化器编译,使用的损失函数是 Huber 损失,作为 L1 和 L2 损失之间的折衷。
在现代 GPU 上训练需要几个小时。
如果您的本地计算机中有用于深度学习计算的 GPU,则可以使用以下命令进行训练:python main.py --mode=“training”。它采用 args.py 中定义的输入参数。默认情况下,它将从头开始训练(您可以通过将 training_from_scratch 设置为 false 来更改此设置)。您可以从 weights_folder 和 name_model 中指定的预训练权重开始训练。我让可用的 model_unet.h5 带有我在 ./weights 中训练的权重。 epochs 和 batch_size 指定训练的 epoch 数和批大小。最佳权重在训练期间自动保存为 model_best.h5。您可以调用 fit_generator 在训练时仅将部分数据加载到磁盘。
就个人而言,我使用 Google colab 提供的免费 GPU 进行训练。我在 ./colab/Train_denoise.ipynb 放了一个笔记本示例。如果您的驱动器上有很大的可用空间,您可以将所有训练数据加载到驱动器,并在训练时使用 tensorflow.keras 的 fit_generator 选项加载其中的一部分。就我个人而言,我的 Google 驱动器上的可用空间有限,因此我预先准备了 5Gb 的高级批次以加载到驱动器进行培训。定期保存重量并为下一次训练重新加载。
最后,我获得了 0.002129 的训练损失和 0.002406 的验证损失。在其中一次训练中制作的损失图下方。

预测
对于预测,嘈杂的语音音频被转换为略高于 1 秒的 numpy 时间序列窗口。 每个时间序列通过 STFT 变换转换为幅度谱图和相位谱图。 嘈杂的语音频谱图被传递到 U-Net 网络,该网络将预测每个窗口的噪声模型(参见下图)。 使用经典 CPU,一旦转换为幅度谱图,一个窗口的预测时间约为 80 毫秒。

然后从嘈杂的语音频谱图中减去模型(这里我应用了直接减法,因为它足以完成我的任务,我们可以想象训练第二个网络来适应噪声模型,或应用匹配滤波器,例如在信号处理中执行的 )。 “去噪”幅度谱图与初始相位相结合,作为逆短时傅立叶变换 (ITFT) 的输入。 然后可以将我们的降噪时间序列转换为音频(参见下图)。

让我们来看看在验证数据上的表现!
下面我展示了一些来自警报/昆虫/吸尘器/铃铛噪声的验证示例的结果。 对于它们中的每一个,我都显示了初始的嘈杂语音频谱图、网络预测的去噪频谱图以及真正干净的语音频谱图。 我们可以看到,该网络能够很好地概括噪声建模,并生成略微平滑的语音频谱图,非常接近真正的干净语音频谱图。
更多关于验证数据的频谱图降噪示例显示在存储库顶部的初始 gif 中。
References
Jansson, Andreas, Eric J. Humphrey, Nicola Montecchio, Rachel M. Bittner, Aparna Kumar and Tillman Weyde.Singing Voice Separation with Deep U-Net Convolutional Networks. ISMIR (2017).
https://ejhumphrey.com/assets/pdf/jansson2017singing.pdf
Grais, Emad M. and Plumbley, Mark D., Single Channel Audio Source Separation using Convolutional Denoising Autoencoders (2017).
https://arxiv.org/abs/1703.08019
Ronneberger O., Fischer P., Brox T. (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab N., Hornegger J., Wells W., Frangi A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science, vol 9351. Springer, Cham
https://arxiv.org/abs/1505.04597
K. J. Piczak. ESC: Dataset for Environmental Sound Classification. Proceedings of the 23rd Annual ACM Conference on Multimedia, Brisbane, Australia, 2015.
DOI: http://dx.doi.org/10.1145/2733373.2806390