基于可逆神经网络的图像隐藏技术 (ICCV 2021) - HiNet: Deep Image Hiding by Invertible Network
HiNet: Deep Image Hiding by Invertible Network

[pdf] [github]
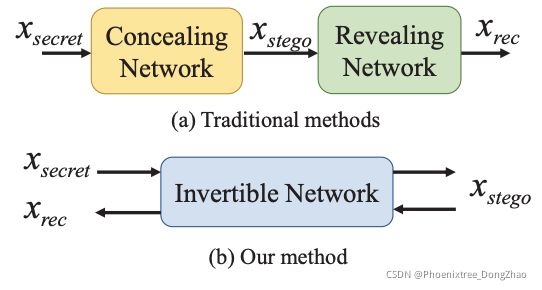
Figure 1. The illustration of difference between our image hiding method and the traditional methods [5, 23, 32].
目录
Abstract
1. Introduction
2. Related Work
2.1. Steganography and Image Hiding
2.2. Invertible Neural Network
3. Methods
3.1. Network architecture
3.2. Loss function
4. Experiments
4.1. Experimental Settings Datasets and settings
5. Conclusion
Abstract
Image hiding aims to hide a secret image into a cover image in an imperceptible way, and then recover the secret image perfectly at the receiver end. Capacity, invisibility and security are three primary challenges in image hiding task.
This paper proposes a novel invertible neural network (INN) based framework, HiNet, to simultaneously overcome the three challenges in image hiding.
For large capacity, we propose an inverse learning mechanism by simultaneously learning the image concealing and revealing processes. Our method is able to achieve the concealing of a full-size secret image into a cover image with the same size.
For high invisibility, instead of pixel domain hiding, we propose to hide the secret information in wavelet domain.
Furthermore, we propose a new low-frequency wavelet loss to constrain that secret information is hidden in high-frequency wavelet subbands, which significantly improves the hiding security.
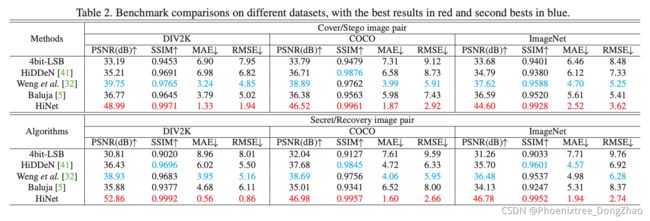
Experimental results show that our HiNet significantly outperforms other state-of-the-art image hiding methods, with more than 10 dB PSNR improvement in secret image recovery on ImageNet, COCO and DIV2K datasets.
图像隐藏的目的是将秘密图像(secret image)以一种不可察觉的方式隐藏到覆盖图像(cover image)中,然后在接收端完美地恢复秘密图像。容量、不可见性和安全性是图像隐藏的三大挑战。
本文提出了一种新的基于可逆神经网络 (INN) 的框架 HiNet,以同时克服图像隐藏中的三个挑战。
对于大容量的图像,提出了一种同时学习图像隐藏和揭示过程的可逆学习机制。该方法能够实现将全尺寸秘密图像隐藏到相同尺寸的覆盖图像中。
为了提高不可见性,提出在小波域中隐藏秘密信息,而不是像素域隐藏。
此外,提出了一种新的低频小波损耗来约束秘密信息被隐藏在高频小波子带中,大大提高了隐藏的安全性。
实验结果表明,在 ImageNet、COCO 和 DIV2K 数据集上,HiNet 秘密图像恢复性能显著优于其他先进的图像隐藏方法,PSNR 提高了 10 dB 以上。
1. Introduction
The task of image hiding is to conceal a secret image into a cover image to generate a stego image, which only allows the informed receivers to recover the secret image, but invisible to other people. For security concern, the stego image is usually required to be indistinguishable from the cover image. Different from bit-level message hiding or steganography [2, 20, 35, 36, 39–41], image hiding is more challenging, which requires large capacity, high invisibility and security. Image hiding has a wide range of applications, of which secret communication and privacy protection are the most significant ones. Compared to the well-known image cryptography, image hiding has a remarkable security advantage, i.e., the stego image with secret information inside is indistinguishable from the cover image, which makes it more suitable for secret communication. In addition, unlike image cryptography, image hiding focuses more on the capacity and invisibility of hidden information rather than robustness.
研究意义:干嘛的,有啥用。图像隐藏的任务是将秘密图像(secret image)隐藏到覆盖图像(cover image)中,生成隐写图像(stego image),只允许知情的接收方恢复秘密图像,而对其他人不可见。出于安全考虑,隐写图像通常要求与掩蔽图像难以区分。与位级消息隐藏或隐写术不同,图像隐藏更具挑战性,需要大容量、高不可见性和安全性。图像隐藏具有广泛的应用,其中秘密通信和隐私保护是最重要的应用。与众所周知的图像密码学相比,图像隐藏具有显著的安全性优势,即包含秘密信息的隐写图像与被隐图像难以区分,更适合进行秘密通信。此外,与图像密码学不同,图像隐藏更注重隐藏信息的容量和不可见性,而不是鲁棒性。
(关于三种图像的翻译,本博客暂时这么译了,还请专家们给予指正。)
Traditional steganographic approaches can only hide a small amount of information [6,11,13,16,19,24], which cannot meet the requirement of large capacity in image hiding task. Baluja [4] proposed the first convolutional neural network (CNN) to solve image hiding problem. This work was then extended in [5] by permuting the pixels of secret image to enhance the hiding security. Weng et al. [32] further proposed a deep network for video steganography by temporal residual modeling. However, all these methods adopt two sub-networks for image hiding: a concealing network to hide a secret image
into a cover image to generate a stego image xstego, and a revealing network to recover the secret image xrec from xstego, as shown in Fig. 1 (a). The concealing and revealing networks have two sets of parameters, which are linked through simple concatenation. This loose connection may cause color distortion and texture-copying artifacts. Besides, they barely consider the security issue, making hidden secret information easy to be detected.
研究现状:指出问题和挑战。传统的隐写方法只能隐藏少量的信息,不能满足图像隐藏任务大容量的要求。Baluja [4] 提出了第一个卷积神经网络 (CNN) 来解决图像隐藏问题。在 [5] 中,通过对秘密图像像素的排列来提高隐藏的安全性。Weng et al. [32] 进一步提出了一种基于时域残差建模的视频隐写深度网络。然而,所有这些方法都采用了两个子网络来进行图像隐藏:隐藏网络将秘密图像 ![]() 隐藏成覆盖图像来生成一个隐写图像
隐藏成覆盖图像来生成一个隐写图像 ![]() 和揭示网络恢复从
和揭示网络恢复从 ![]() 恢复秘密图像,如图 1(a) 所示,隐藏和揭示网络有两种参数,这是通过简单连接实现。这种松弛连接(loose connection)可能会导致颜色失真和纹理复用效应。此外,这些方法几乎不考虑安全问题,使得隐藏的秘密信息很容易被发现。
恢复秘密图像,如图 1(a) 所示,隐藏和揭示网络有两种参数,这是通过简单连接实现。这种松弛连接(loose connection)可能会导致颜色失真和纹理复用效应。此外,这些方法几乎不考虑安全问题,使得隐藏的秘密信息很容易被发现。
Fig.1
In this paper, we propose an invertible image hiding network, HiNet, in which the concealing and revealing processes share the same set of network parameters, as shown in Fig. 1 (b). To the best of our knowledge, our work is the first attempt to explore invertible network in image hiding task. The main novelty is that image revealing is modelled as the reverse process of image concealing in an invertible network architecture, which means the network only needs to be trained once to get all network parameters for both concealing and revealing. This is a radical difference from the existing methods [5, 23, 32] which treat the concealing and revealing processes independently. Consequently, our HiNet achieves state-of-the-art performance on recovery accuracy, hiding security and invisibility.
本文提出一个可逆的图像隐藏网络,HiNet,隐藏和揭示的过程中共享相同的网络参数,如图 1(b) 所示。本工作(应该是)是第一次尝试探索可逆网络在图像隐藏任务中的应用。其主要新颖之处在于,在一个可逆的网络结构中,将图像显式建模为图像隐藏的反向过程,这意味着只需对网络进行一次训练,就可以得到隐藏和揭示的所有网络参数。这与现有的方法 [5,23,32] 截然不同,现有方法独立处理隐藏和揭示过程。因此,HiNet 在恢复精度、隐藏安全和隐身方面达到了最先进的性能。
The main contributions of this paper are summarized as follows:
• We propose a novel image hiding network, namely HiNet, based on invertible neural network for the task of large-capacity image hiding.
• We design two concealing and revealing modules with differentiable and invertible property, aiming to make the image hiding process fully reversible.
• We propose a low-frequency wavelet loss to control the distribution of secret information in different frequency bands, which significantly improves the hiding security.
本文贡献:
• 针对大容量图像隐藏任务,提出了一种基于可逆神经网络的图像隐藏网络 HiNet。
• 设计了两个具有可微和可逆性质的隐藏和揭示模块,目的是使图像隐藏过程完全可逆。
• 提出低频小波损耗,用以控制秘密信息在不同频段的分布,显著提高隐藏的安全性。
2. Related Work
2.1. Steganography and Image Hiding
(略)
2.2. Invertible Neural Network
Invertible neural network (INN) was first proposed by Dinh et al. [9]. Given a variable y and the forward computation x =
(y), one can recover y directly by y =
(x), where the inverse function
可逆神经网络简介:可逆神经网络 (INN) 最早由 Dinh et al. [9] 提出。给定变量 y 和正演计算 x = (y),可以通过 y = ![]() (x) 直接恢复 y,其中逆函数
(x) 直接恢复 y,其中逆函数 ![]() 与 共用相同的参数
与 共用相同的参数  。为了使 INN 更好地处理与图像相关的任务,Dinh et al.[10] 在耦合模型中引入了卷积层,并引入了多尺度层,以降低计算成本,提高正则化能力。Kingma et al. [15] 在 INN 中引入了可逆的 1 × 1 卷积,并提出了 Glow,该算法对图像的真实感合成和处理非常有效。
。为了使 INN 更好地处理与图像相关的任务,Dinh et al.[10] 在耦合模型中引入了卷积层,并引入了多尺度层,以降低计算成本,提高正则化能力。Kingma et al. [15] 在 INN 中引入了可逆的 1 × 1 卷积,并提出了 Glow,该算法对图像的真实感合成和处理非常有效。
Due to the excellent performance, INN has been utilized in many image-related tasks. Specifically, Ouderaa et al. [28] applied INN to image-to-image translation task. Ardizzone et al. [3] introduced conditional INN to guided image generation and colorization, in which the inverse process was guided by a conditional parameter. Xiao et al. [33] attempted to find a mapping between low and high resolution images using INN for image rescaling. Lugmayr et al. [18] proposed a normalizing flow-based method via INN on super-resolution, which attempted to directly account for the illposed nature of super-resolution, and learn to predict diverse photo-realistic high-resolution images. Most recently, Wang et al. [30] applied INN in digital image compression task. However, to the best of our knowledge, there is no work to explore INN in image hiding task.
可逆神经网络应用:由于其优异的性能,INN 被用于许多与图像相关的任务中。Ouderaa et al. [28] 将 INN 应用于图像到图像的转换任务。Ardizzone et al. [3] 将条件 INN 引入到引导图像生成和着色中,其中逆过程由条件参数引导。Xiao et al. [33] 试图通过 INN 进行图像缩放来寻找低分辨率和高分辨率图像之间的映射。Lugmayr et al. [18] 在超分辨率上提出了一种基于 INN 的归一化流方法,试图直接解释超分辨率的病态性质,并学习预测各种逼真的高分辨率图像。最近,Wang et al. [30] 将 INN 应用于数字图像压缩任务。然而,据我们所知,INN 在图像隐藏任务中并没有探索工作。
3. Methods
在本节中,提出了一种新的可逆隐藏-揭示网络 HiNet,以实现大容量、高安全性和高不可见性的图像隐藏。表 1 给出了本文使用的符号。

3.1. Network architecture
Fig. 2 shows the overall framework of the proposed HiNet.
In the forward concealing process, a pair of secret image
are accepted as inputs. They are first decomposed into low and high-frequency wavelet sub-bands through discrete wavelet transform (DWT), which are then fed into a sequence of concealing blocks. The outputs of the last concealing block go through an inverse wavelet transform (IWT) block to generate a stego image
, together with the lost information r.
In the backward revealing process, the stego image
HiNet 总体框架:如图 2。
前向隐藏过程:输入为秘密图像 ![]() 和覆盖图像
和覆盖图像 ![]() 。
。
首先,通过离散小波变换 (DWT) 将其分解为低、高频小波子带;
然后,将其输入到隐藏块序列中;
最后,隐藏块的输出经过逆小波变换 (IWT) 块来生成一个隐写图像 ![]() , 和一起失去的信息 r。
, 和一起失去的信息 r。
逆向揭示过程:隐藏图像 ![]() 和一个辅助变量 z 通过 DWT 和一系列揭示模块恢复秘密图像
和一个辅助变量 z 通过 DWT 和一系列揭示模块恢复秘密图像 ![]() 。
。
Figure 2. The framework of HiNet. In the forward concealing process, a secret image is hidden in a cover image through several concealing blocks to generate a stego image, together with the lost information. In the backward revealing process, the stego image and an auxiliary variable z from Gaussian distribution are fed to a series of revealing blocks to recover the secret image. Note that in our HiNet, revealing is the inverse process of concealing, and thus they share the same network parameters.
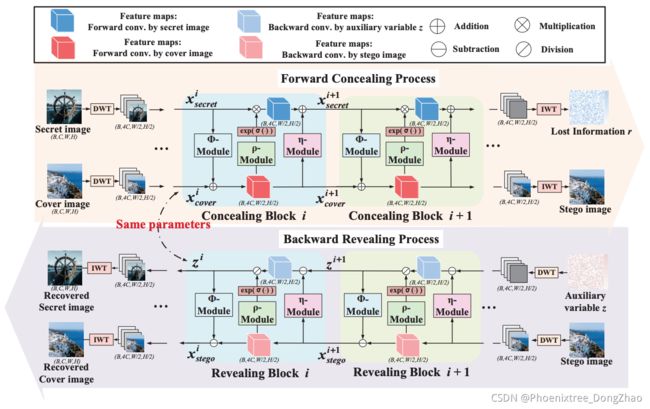
图2:HiNet 框架。注意,在 HiNet 中,揭示是隐藏的逆过程,因此它们共享相同的网络参数。
Wavelet domain hiding
Image hiding in pixel domain can easily lead to texture-copying artifacts and color distortion [11, 32]. Compared to pixel domain, the frequency domain, especially high-frequency domain, is more appropriate for image hiding.
In this paper, we adopt DWT to split image into low and high-frequency wavelet sub-bands before entering the invertible blocks, so that the network can better fuse the secret information into the cover image.
Moreover, the perfect reconstruction property of wavelets [21] can help decrease the information loss and improve the image hiding performance.
After DWT, the feature map of size (B, C, H,W) is turned into (B, 4C, H/2,W/2), in which B is batch size, H is height, W is width and C is channel number. As we can see, the computational cost can be reduced by DWT, which can help accelerate the training process.
Here, we adopt Haar wavelet kernel to perform DWT and IWT, for its simplicity and effectiveness. Note that wavelet transform is bidirectional symmetric, which means it will not affect the end-to-end training of our network.
解释:为什么要在小波域进行图像隐藏。
图像在像素域隐藏容易导致纹理复制伪影和颜色失真。相对于像素域,频率域,尤其是高频域更适合图像隐藏。
本文采用小波变换在进入可逆模块之前,将图像分成低高频小波子带,使网络能够更好地将秘密信息融合到覆盖图像中。
此外,小波具有良好的重构特性,有助于减少信息损失,提高图像隐藏性能。
DWT 后,size (B,C,H,W) 的 feature map 变为 (B,4C,H/2,W/2)。可以看到,DWT 可以降低计算成本,有助于加速训练过程。
本文采用 Haar 小波核进行小波变换和小波变换,简单有效。
注意小波变换是双向对称的,这意味着它不会影响网络的端到端训练。
(每一句都有用,把优点充分展开了说。为什么作者能想到这么多优点?)
Invertible concealing and revealing blocks
As shown in Fig. 2, the concealing and revealing blocks have the same sub-modules and share the same network parameters, but with reverse information flow directions. There are M concealing blocks with the same architecture, which is constructed as follows. For the i-th concealing block in the forward process, the inputs are
and
, and the outputs
and
are formulated as follows,

(1)
where α is a sigmoid function multiplied by a constant factor served as a clamp, and
indicates the dot product operation. Here, ρ(·), φ(·) and η(·) are arbitrary functions and we adopt the widely used dense block in [29] to represent them for its good representation ability. The influence of different architectures for ρ(·), φ(·), and η(·) is discussed in ablation study in Section 4.4. After the last concealing block, we can obtain the outputs
and
, which are then fed into two IWT blocks to generate the stego image
模型介绍:可逆隐藏和揭示模块网络结构。
如图 2 所示,隐藏块和揭示模块具有相同的子模块,共享相同的网络参数,但信息流方向相反。该模型有 M 个相同结构的隐藏模块。
隐藏模块:
对于前向过程中的第 i 个隐藏模块,输入为 ![]() and
and ![]() ,输出
,输出 ![]() and
and ![]() 表示为 (1)。
表示为 (1)。
其中,α 是一个 s 型函数乘以一个作为 clamp 的常数因子,表示点积运算。
其中 ρ(·)、φ(·) 和 η(·) 是任意函数,本文采用 [29] 中广泛使用的 dense blocks 来表示它们,因为它具有良好的表示能力。不同体系结构对 ρ(·)、φ(·) 和 η(·) 的影响在 4.4 节的消融研究中进行了讨论。
在最后一个隐藏模块之后,可以得到输出 ![]() and
and ![]() ,然后将输出送入两个 IWT 块,分别生成隐写图像
,然后将输出送入两个 IWT 块,分别生成隐写图像 ![]() 和丢失信息 r。
和丢失信息 r。
In the revealing process, the information flow direction is from the (i+1)-th revealing block to the i-th revealing block, which is in reverse order to the concealing process, as shown in Fig. 2. Specifically, for the M-th revealing block, the inputs are
and
which are generated by the stego image
and
. For the i-th revealing block, the inputs are
and
, and the outputs are
and
. Their relationship is modelled as follows,
(2)
After the last revealing block, i.e., the revealing block 1, the output
is fed into an IWT block to generate the recovery image
.
揭示模块:
在揭示过程中,信息流的方向是从 第 (i+1) 个揭示模块到第 i 个揭示模块,与隐藏过程的顺序相反,如图 2 所示。具体来说,对于第 M 个揭示模块,输入是由隐写图像 ![]() 和辅助变量 z 通过 DWT 生成的
和辅助变量 z 通过 DWT 生成的 ![]() and
and ![]() 。这里,z 是从高斯分布中随机抽样的。第 M 个揭示块的输出是
。这里,z 是从高斯分布中随机抽样的。第 M 个揭示块的输出是 ![]() and
and ![]() 。对于第 i 个揭示模块,输入是
。对于第 i 个揭示模块,输入是 ![]() and
and ![]() ,输出是
,输出是 ![]() and 。他们的关系如 (2) 所示。在最后一个揭示模块,即揭示模块 1 之后,输出
and 。他们的关系如 (2) 所示。在最后一个揭示模块,即揭示模块 1 之后,输出 ![]() 被送入 IWT 模块,生成恢复图像
被送入 IWT 模块,生成恢复图像 ![]() 。
。
The lost information r and auxiliary variable z
The lost information r is one of the outputs in the forward concealing process, and z is one input to the backward revealing process. In the concealing process, the network tries to hide the secret image into the cover image. However, it is difficult to hide such a large capacity in the cover image, which inevitably leads to the loss of secret information. In addition, the intrusion of secret image may destroy the original information in the cover image. The lost secret information and destroyed cover information make up the lost information r.
Here, r is assumed to be case-agnostic for the reasons below. Suppose that the distribution of all images in dataset is
. The inputs in the forward process are
. Due to the strict equivalence of Eqs. (1) and (2), and the reversible constraint of INN, the mixed distribution of the outputs
. For stego image
. Thus, it is reasonable to assume the remained r to be case-agnostic.
丢失的信息 r 是前向隐藏过程的一个输出,z 是后向揭示过程的一个输入。
在隐藏过程中,网络试图将秘密图像隐藏到覆盖图像中。然而,如此大的容量很难隐藏在封面图像中,不可避免地导致秘密信息的丢失。另外,秘密图像的入侵可能会破坏封面图像中的原始信息。丢失的秘密信息和被破坏的掩护信息构成了丢失的信息 r。
这里,r 被假定为个例无关的 case- notistic,原因如下:
假设数据集中所有图像的分布为 。前向过程的输入是 ![]() 和
和 ![]() ,它们从相同的数据集采样,因此遵循相同的分布:
,它们从相同的数据集采样,因此遵循相同的分布: ![]() 。由于方程 (1) 和 (2) 的严格等价性,以及 INN 的可逆约束,输出
。由于方程 (1) 和 (2) 的严格等价性,以及 INN 的可逆约束,输出 ![]() 和 r 的混合分布应服从与输入相同的分布,即
和 r 的混合分布应服从与输入相同的分布,即 ![]() 。对于隐写图像
。对于隐写图像![]() ,第 3.2 节中的隐藏损失推动其分布与覆盖图像匹配,即
,第 3.2 节中的隐藏损失推动其分布与覆盖图像匹配,即 ![]() 。因此,可以合理地假设剩下的 r 是个案无关的。
。因此,可以合理地假设剩下的 r 是个案无关的。
In backward revealing, the recovery image
.
在向后揭示中,恢复图像 ![]() 要求只从隐写图像
要求只从隐写图像 ![]() 中提取,而不访问 r。这实际上是一个不适定的问题,因为可以从同一个
中提取,而不访问 r。这实际上是一个不适定的问题,因为可以从同一个 ![]() 中恢复数百万个
中恢复数百万个 ![]() 。为了获得精确的
。为了获得精确的 ![]() ,在反示过程中采用了一个辅助变量 z。变量 z 是从一个 case- notistic 分布中随机抽取的,该分布与 r 的分布相同。该分布是在训练时通过 3.2 节的揭示损失来学习的,确保分布中的每个样本都能很好地恢复秘密信息。在不失一般性的前提下,假设分布为高斯分布,即
,在反示过程中采用了一个辅助变量 z。变量 z 是从一个 case- notistic 分布中随机抽取的,该分布与 r 的分布相同。该分布是在训练时通过 3.2 节的揭示损失来学习的,确保分布中的每个样本都能很好地恢复秘密信息。在不失一般性的前提下,假设分布为高斯分布,即 ![]() 。
。
Why INN works for image hiding?
The image hiding task is composed of two reverse procedures: the concealing procedure aims to hide a secret image xsecret in a cover image xcover, to generate a new container called stego image xstego; while the revealing procedure attempts to recover the secret image from the stego image as high-fidelity as possible. In previous works [5, 23, 32], the concealing and revealing procedures are sequentially achieved by two forward networks, i.e., one network for concealing and the other for revealing. However, for perfect concealing and revealing performance, these two processes should be fully reversible. Based on this, we innovatively treat the image concealing and revealing as the forward and backward processes of the same INN, i.e, they are invertible. As a result, they can coordinate with each other to improve the hiding and revealing performance simultaneously. As demonstrated in the experiments, our network with INN architecture significantly advances the state-of-the-art image hiding performance.
一句话:隐藏过程 和 揭示过程 应该是可逆的关系。
图像隐藏任务由两个反向过程组成:隐藏过程旨在将秘密图像 ![]() 隐藏到覆盖图像
隐藏到覆盖图像 ![]() 中,生成一个新的容器称为 stego 图像
中,生成一个新的容器称为 stego 图像 ![]() ;而揭示程序则试图从隐写图像中恢复出尽可能高保真的秘密图像。
;而揭示程序则试图从隐写图像中恢复出尽可能高保真的秘密图像。
在前人的工作中,隐藏和揭示过程是由两个前向网络依次完成的,一个是隐藏网络,另一个是揭示网络。
然而,为了完美的隐藏和揭示性能,这两个过程应该是完全可逆的。
在此基础上,本文创新性地将图像的隐藏和揭示视为同一 INN 的正向和反向过程,即可逆过程。
因此,它们可以相互协调,同时提高隐藏和显示性能。
正如在实验中证明的,本文的网络与 INN 体系结构显著提高了最先进的图像隐藏性能。
3.2. Loss function
The total loss function is composed of three different losses: the concealing loss to guarantee the concealing performance, the revealing losses to ensure the recovering performance, and a new low-frequency wavelet loss to enhance the hiding security.
总损耗函数由三种不同的损耗组成:保证隐藏性能的隐藏损耗、保证恢复性能的揭示损耗和增强隐藏安全性的低频小波损耗。
Concealing loss
The forward concealing process aims to hide
is defined as follows,
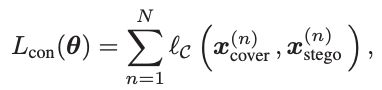
(3)
where
is equal to
, with θ indicating the network parameters. In addition, N is the number of training samples, and C measures the difference between cover and stego images, which can be 1 or 2 norm.
隐藏损失:
前向隐藏过程的目的是将 ![]() 隐藏到
隐藏到 ![]() 中,生成
中,生成 ![]() 图像。隐写图像要求与覆盖图像难以区分。为此,隐藏损失 的定义如下:
图像。隐写图像要求与覆盖图像难以区分。为此,隐藏损失 的定义如下:
其中 ![]() 等于
等于 ![]() , θ 表示网络参数。N 为训练样本个数,C 为覆盖图像和隐写图像的差值,可以是1个或2个范数。
, θ 表示网络参数。N 为训练样本个数,C 为覆盖图像和隐写图像的差值,可以是1个或2个范数。
Revealing loss
In the backward revealing process, given the stego image
as follows,
(4)
where the recovery image
is equal to
, with
indicating the backward revealing process. Similar to C, R measures the difference between recovered secret images
用高斯分布 p(z) 中的任意 z 样本恢复秘密图像。为此,将揭示损失 ![]() 定义如 (4)。其中恢复图像
定义如 (4)。其中恢复图像 ![]() 等于
等于 ![]() ,其中
,其中 ![]() 表示后显过程。与 C 类似,R 测量恢复的秘密图像
表示后显过程。与 C 类似,R 测量恢复的秘密图像 ![]() 与 GT 的秘密图像
与 GT 的秘密图像 ![]() 之间的差异。
之间的差异。
Low-frequency wavelet loss
In addition to the above two losses, we propose a low-frequency wavelet loss
to enhance the network’s anti-steganalysis ability. The motivation of this loss is from [4], which verifies that the information hidden in high-frequency components is less likely to be detected than that in low-frequency components. Here, in order to ensure most information is hidden in the highfrequency sub-bands, the low frequency sub-bands of stego image are required to be similar to those of cover image after wavelet decomposition. Suppose that
indicates the operation of extracting low-frequency sub-bands after wavelet decomposition, the low-frequency wavelet loss

(5)
Here, F measures the difference between the low-frequency sub-bands of cover and stego images.
低频小波损失:
除了上述两种损失外,作者还提出了低频小波损失 ![]() 来增强网络的抗隐写分析能力。这种损失的动机来自 [4],它证实了隐藏在高频分量中的信息比在低频分量中的信息更不容易被检测到。这里,为了保证大部分信息隐藏在高频子带中,要求隐写图像的低频子带经过小波分解后与覆盖图像的低频子带相似。设
来增强网络的抗隐写分析能力。这种损失的动机来自 [4],它证实了隐藏在高频分量中的信息比在低频分量中的信息更不容易被检测到。这里,为了保证大部分信息隐藏在高频子带中,要求隐写图像的低频子带经过小波分解后与覆盖图像的低频子带相似。设 ![]() 表示小波分解后提取低频子带的操作,则低频小波损耗
表示小波分解后提取低频子带的操作,则低频小波损耗 ![]() 定义为 (5)。其中,F 测量覆盖和隐写图像的低频子带之间的差异。
定义为 (5)。其中,F 测量覆盖和隐写图像的低频子带之间的差异。
Total loss function
The total loss function
is a weighted sum of concealing loss
Here, λc, λr and λf are weights for balancing different loss terms. In the training process, we firstly pre-train the network by minimizing
总损失函数:
总损耗函数Ltotal是隐藏损耗 、揭示损耗 ![]() 和低频小波损耗
和低频小波损耗 ![]() 的加权和,如 (6)。
的加权和,如 (6)。
这里,λc, λr, λf 是平衡不同损失项的权重。在训练过程中,首先通过最小化 和 ![]() 对网络进行预训练,即设置 λf 为 0。然后,添加
对网络进行预训练,即设置 λf 为 0。然后,添加 ![]() 以端到端方式训练网络。
以端到端方式训练网络。
4. Experiments
4.1. Experimental Settings Datasets and settings
The DIV2K [1] training dataset is used for training our HiNet. The testing datasets include DIV2K [1] testing dataset with 100 images at resolution 1024 × 1024, ImageNet [25] with 50,000 images at resolution 256 × 256, and COCO [17] dataset with 5,000 images at resolution 256 × 256. Note that the testing images are cropped using center-cropping strategy, to make sure the cover and secret images are with the same resolution. The number of concealing and revealing blocks M is set to 16. The training patch size is 256 × 256, and the number of total iteration is 80K. The parameters λc, λr and λf are set to 10.0, 1.0, 10.0, respectively. The mini-batch size is set to 16, in which half is randomly selected as cover patches and the remained are secret patches. The Adam [14] optimizer is adopted with standard parameters and an initial learning rate of 1 × 10−4.5 , which is halved every 10K iterations.
DIV2K 训练数据集用于训练 HiNet。测试数据集包括 DIV2K 测试数据集,分辨率为1024 × 1024,包含100张图像;ImageNet 测试数据集,分辨率为 256 × 256,包含 50,000 张图像;COCO 测试数据集,分辨率为 256 × 256,包含 5,000 张图像。
测试图像是使用中心裁剪策略裁剪的,以确保封面和秘密图像具有相同的分辨率。隐藏和显示块M的数量设置为16。训练 patch 大小为 256 × 256,总迭代次数为 80K。λc、λr、λf 分别设为 10.0、1.0、10.0。mini batch 大小设置为 16,其中随机选取一半作为 cover patches,其余为 secret patches。采用 Adam 优化器,采用标准参数,初始学习率为 1 × 10−4.5,每 10K 次迭代减半。
Benchmarks
To verify the effectiveness of our method, we compare it with several state-of-the-art (SOTA) image hiding methods, including one traditional image steganography method named 4bit-LSB, and three deep learning based methods: HiDDeN [41], Weng et al. [32], and Baluja [5]. For fair comparison, we re-trained the models of Weng et al. [32], Baluja [5], and HiDDeN [41] using the same training dataset as ours. Note that the original HiDDeN [41] model can only hide messages, which is not consistent with the image hiding configuration in this paper. To make it able to hide images, we slightly modified its output dimension and then re-trained the network.
为了验证方法的有效性,将其与几种最先进的 (SOTA) 图像隐藏方法进行了比较,包括一种传统的图像隐藏方法 4bit-LSB,以及三种基于深度学习的方法:HiDDeN[41]、Weng et al. [32] 和Baluja[5]。为了比较公平,使用与我们相同的训练数据集对 Weng et al. [32]、Baluja [5] 和 HiDDeN 的模型进行了重新训练。注意,原来的 HiDDeN 模型只能隐藏消息,这与本文的图像隐藏配置不一致。为了使它能够隐藏图像,稍微修改了它的输出维数,然后重新训练了网络。
Evaluation metrics
There are four metrics adopted to measure the quality of cover/stego and secret/recovery pairs, including Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) [31], Root Mean Square Error (RMSE), and Mean Absolute Error (MAE). The larger value of PSNR, SSIM and smaller value of RMSE, MAE indicate higher image quality. In addition, we use the statistical steganalysis tool named StegExpose [7] and SRNet [8] to evaluate the security performance of our method.
本文采用峰值信噪比 (PSNR)、结构相似性指数 (SSIM)、均方根误差 (RMSE) 和平均绝对误差 (MAE) 4个指标来衡量掩蔽/隐写和秘密/恢复对的质量。PSNR、SSIM 值越大,RMSE、MAE 值越小,图像质量越好。此外,本文使用统计隐写分析工具 StegExpose [7] 和 SRNet [8] 来评估我们的方法的安全性能。
5. Conclusion
In this paper, we propose a novel invertible neural network named HiNet for image hiding, which drastically increases both the hiding security and recovering accuracy. Our HiNet models the image concealing and revealing as the forward and backward processes of an invertible network, which means that they share the same network parameters. As a consequence, the network only needs to be trained once to get all network parameters for both image concealing and revealing processes. In network training, a new lowfrequency wavelet loss is proposed to improve the security of image hiding. Extensive experimental results show that our method can achieve image hiding with large capacity and high security, which significantly outperforms other SOTA methods both quantitatively and qualitatively.
本文提出了一种新的用于图像隐藏的可逆神经网络 HiNet,它大大提高了隐藏的安全性和恢复的准确性。HiNet 将图像的隐藏和揭示建模为可逆网络的前向和后向过程,这意味着它们共享相同的网络参数。因此,在图像隐藏和揭示过程中,只需对网络进行一次训练,即可获得所有的网络参数。在网络训练中,为了提高图像隐藏的安全性,提出了一种新的低频小波损失算法。大量的实验结果表明,该方法能够实现大容量、高安全性的图像隐藏,在定量和定性上都明显优于其他 SOTA 方法。