一、flag的提交格式
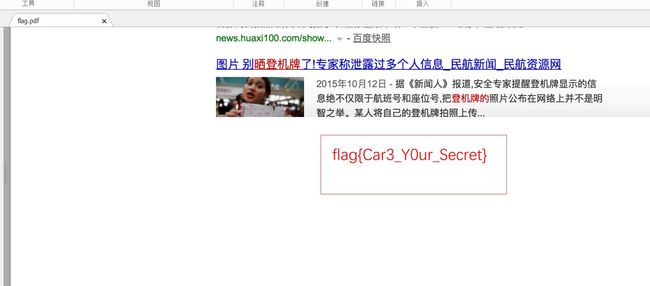
二、PDF隐写
三、GIF图片隐写一
File Format: 文件格式,这个主要是查看图片的具体信息
Data Extract: 数据抽取,图片中隐藏数据的抽取
Frame Browser: 帧浏览器,主要是对GIF之类的动图进行分解,动图变成一张张图片,便于查看
Image Combiner: 拼图,图片拼接

3.将静态图片截图保存下,使用phoshtop工具修复二维码图片,然后进行扫描
https://jiema.wwei.cn/(二维码在线识别工具)
四、jar隐写
writeup:
1.用 jd-gui 打开,直接搜索:flag
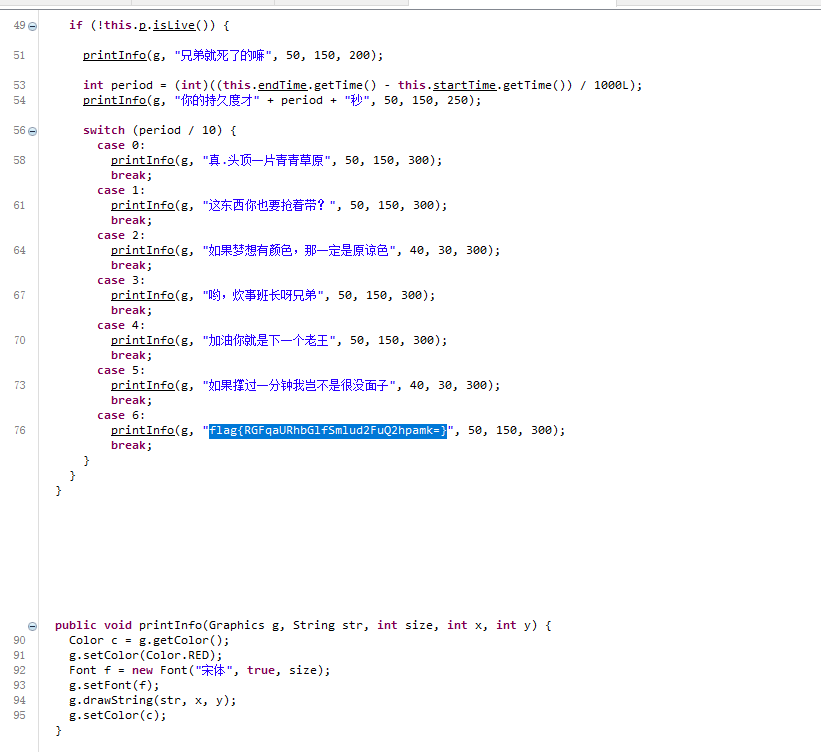
五、压缩包隐写之黑白图片
from PIL import Image
result = ""
for i in range(104):
img = Image.open(f"C:\\Users\\backlion\\Desktop\\ctf\\jpg\\gif\\{i}.jpg")
im_RGB = img.convert("RGB") # 将图片转换为RGB模式
r,g,b =im_RGB.getpixel((1,1)) #获得x,y坐标的rgb值
print(r,g,b)# 这题中白色图片rgb值:255,255,255 黑色图片rgb值:12,12,0
if r !=255: #255是白色
result +="1"
else:
result +="0"
#将二进制转换为ascii码
for i in range(0,len(result),8):
byte = result[i:i+8]
print(chr(int(byte,2)),end="")
"""
rusult:
flag{FuN_giF}
"""
六、十六进制转ascii
string = "c8e9aca0c6f2e5f3e8c4efe7a1a0d4e8e5a0e6ece1e7a0e9f3baa0e8eafae3f9e4eafae2eae4e3eaebfaebe3f5e7e9f3e4e3e8eaf9eaf3e2e4e6f2"
flag = ''
for i in range(0,len(string), 2):
s = "0x" + string[i] + string[i+1]
flag += chr(int(s, 16) - 128)
print(flag)2.得到:Hi, FreshDog! The flag is: hjzcydjzbjdcjkzkcugisdchjyjsbdfr
注:也可以用JPocketKnife进行进制转换
七、与佛论禅加解密
writeup:1.显示文字为:夜哆悉諳多苦奢陀奢諦冥神哆盧穆皤三侄三即諸諳即冥迦冥隸數顛耶迦奢若吉怯陀諳怖奢智侄諸若奢數菩奢集遠俱老竟寫明奢若梵等盧皤豆蒙密離怯婆皤礙他哆提哆多缽以南哆心曰姪罰蒙呐神。舍切真怯勝呐得俱沙罰娑是怯遠得呐數罰輸哆遠薩得槃漫夢盧皤亦醯呐娑皤瑟輸諳尼摩罰薩冥大倒參夢侄阿心罰等奢大度地冥殿皤沙蘇輸奢恐豆侄得罰提哆伽諳沙楞缽三死怯摩大蘇者數一遮
2.通过在线翻译工具http://www.keyfc.net/bbs/tools/tudoucode.aspx
开头上佛曰两字即可解密佛语的意思:

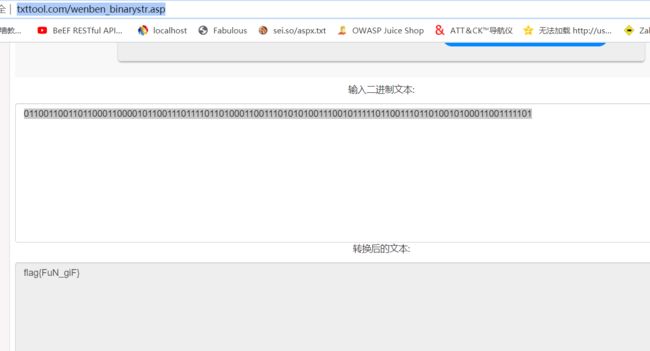
3.接着将解密后的MzkuM3gvMUAwnzuvn3cgozMlMTuvqzAenJchMUAeqzWenzEmLJW9使用rot-13工具(根据题目描述的“如来十三掌”)再一次进行解码,
得到ZmxhZ3tiZHNjamhia3ptbmZyZGhidmNraWpuZHNrdmJramRzYWJ9
https://rot13.com/(
在线工具 )
python解密:
#coding:utf-8
import string
def decoder(crypt_str,shift):
crypt_list = list(crypt_str)
plain_str = ""
num = int(shift)
for ch in crypt_list:
ch = ord(ch)
if ord('a') <= ch and ch <= ord('z'):
ch = ch + num
if ch > ord('z'):
ch -= 26
if ord('A') <= ch and ch <= ord('Z'):
ch = ch +num
if ch > ord('Z'):
ch -= 26
a=chr(ch)
plain_str += a
print(plain_str)
crypt_str = raw_input("Crypto_text:")
print "!------decode------!"
shift=13
decoder(crypt_str,shift)
注:rot13使用一个简单的替换加密算法,对前字符13个字符和后13字符对调
4.base64解密
flag{bdscjhbkzmnfrdhbvckijndskvbkjdsab}
八、pdf隐写之摩莫斯密码
writeup:
1.通过谷歌浏览器打开pdf文件,然后复制文字内容到text文字中

BABA BBB BA BBA ABA AB B AAB ABAA AB B AA BBB BA AAA BBAABB AABA ABAA AB BBA BBBAAA ABBBB BA AAAB ABBBB AAAAA ABBBB BAAA ABAA AAABB BB AAABB AAAAA AAAAA AAAAB BBA AAABB
2.一大段AABABA样式的东西,猜测是01但是这些有分割,能想到的只有摩斯密码有分割的,于是尝试改成摩斯密码
接下来我们把“A”换成“.”,把“B”换成“-”,得到
-.-. --- -. --. .-. .- - ..- .-.. .- - .. --- -. ... --..-- ..-. .-.. .- --. ---... .---- -. ...- .---- ..... .---- -... .-.. ...-- -- ...-- ..... ..... ....- --. ...--
3.通过ctfcraktools工具中莫斯解密工具得到
CONGRATULATIONSnullFLAGnull1NV151BL3M3554G3
4.转变成:
取flagnull 后面的内容,字母换成小写,套格式
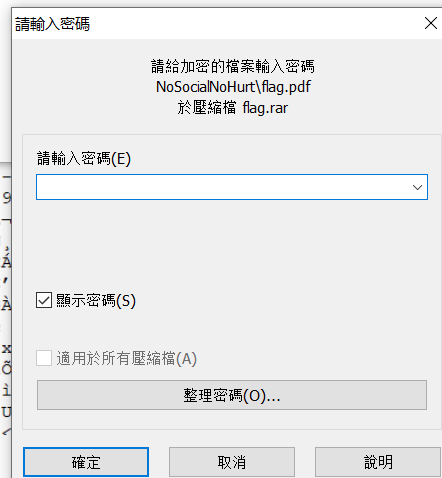
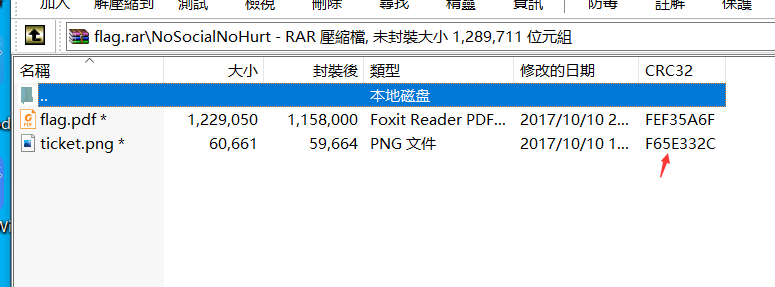
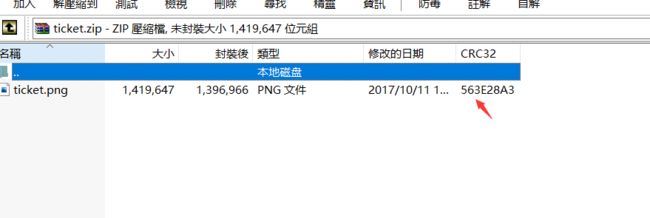
九、受损rar文件之GIF隐写

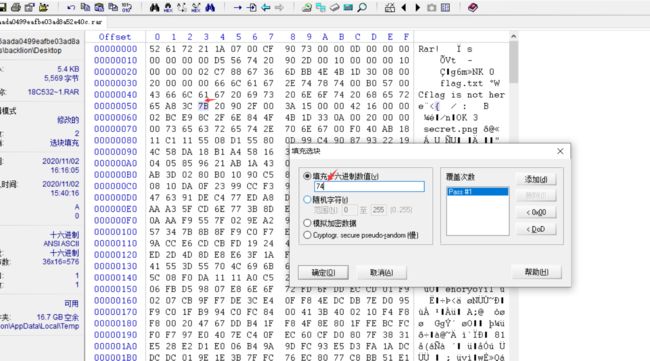
3.保存后解压,再把sercet.png丢到winhex里发现文件头为gif图,将图片后缀名改为.gif。
这里需要一些关于正常文件编码的知识:
jpg图像开始标志:FF D8 结束标志:FF D9
gif图像开始标志:47 49 46 38 39 61 结束标志:01 01 00 3B


4.修改后缀名为.gif,利用Stegsolve中的frame brower分解成两个图片然后用底下的左右箭头选择图层分离出二维码得到两张不全的二维码

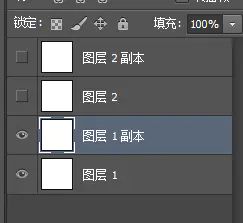
5.由题可知为双层图,用ps打开分离图层后保存
(具体步骤:点击图层 - 复制图层 - 确定,再点击文件 - 储存 - 保存)
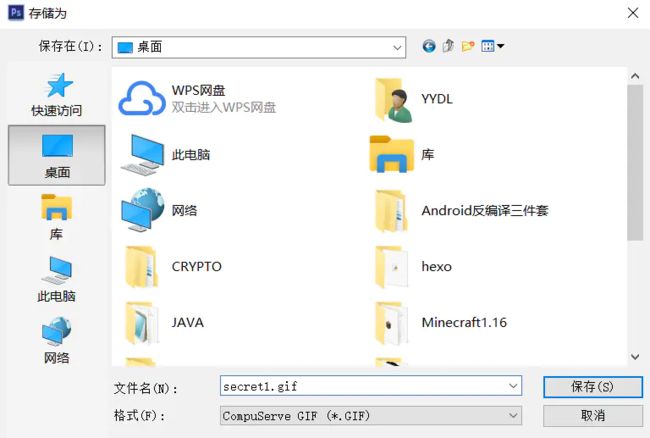
ps全二维码,扫描得到flag:flag{yanji4n_bu_we1shi}
6.在线PS工具:https://www.uupoop.com/ps/?hmsr=ps_menu(选择——色域,把色域调成1就能看的二维码了,然后就拼接)

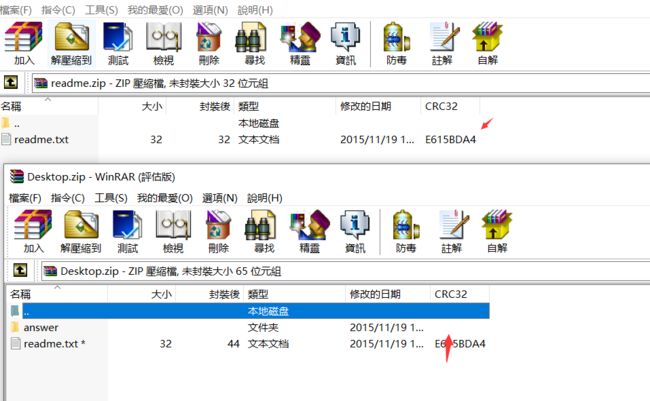
十、zip伪加密之base64隐写
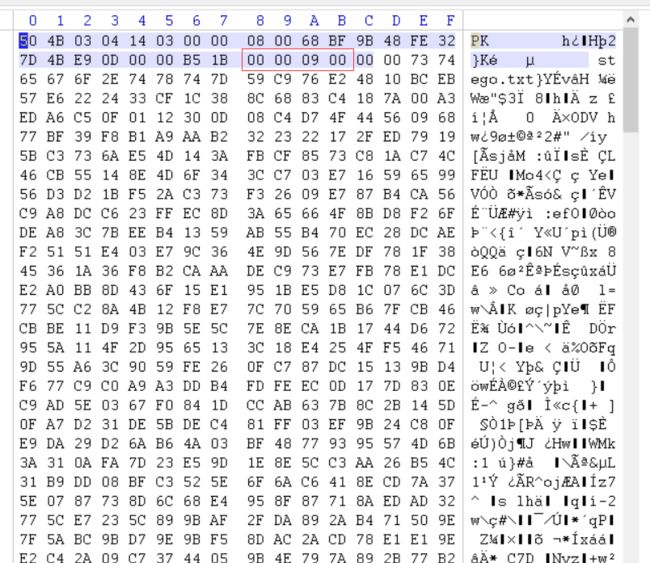
1.压缩源文件数据区:

50 4B 03 04:这是头文件标记(0x04034b50)
14 03:解压文件所需 pkware 版本
00 00:全局方式位标记(判断有无加密的重要标志)
08 00:压缩方式
68 BF:最后修改文件时间
9B 48:最后修改文件日期
FE 32 7D 4B:CRC-32校验
E9 0D 00 00:压缩后尺寸
B5 1B 00 00:未压缩尺寸
09 00:文件名长度
00 00:扩展记录长度
2.压缩源文件目录区:

50 4B 01 02:目录中文件文件头标记(0x02014b50)
3F 03:压缩使用的 pkware 版本
14 03:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密的重要标志,这个更改这里进行伪加密,改为09 00打开就会提示有密码了)
08 00:压缩方式
68 BF:最后修改文件时间
9B 48:最后修改文件日期
FE 32 7D 4B:CRC-32校验(1480B516)
E9 0D 00 00:压缩后尺寸(25)
B5 1B 00 00:未压缩尺寸(23)
09 00:文件名长度
24 00:扩展字段长度
00 00:文件注释长度
00 00:磁盘开始号
00 00:内部文件属性
20 80 ED 81:外部文件属性
00 00 00 00:局部头部偏移量
压缩源文件目录结束标志:

50 4B 05 06:目录结束标记
00 00:当前磁盘编号
00 00:目录区开始磁盘编号
01 00:本磁盘上纪录总数
01 00:目录区中纪录总数
5B 00 00 00:目录区尺寸大小
10 0E 00 00:目录区对第一张磁盘的偏移量
00 00:ZIP 文件注释长度
然后就是识别真假加密
1.无加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为00 00
2.假加密
压缩源文件数据区的全局加密应当为00 00
且压缩源文件目录区的全局方式位标记应当为09 00
3.真加密
压缩源文件数据区的全局加密应当为09 00
且压缩源文件目录区的全局方式位标记应当为09 00writeup:
1.这题全局为00 00 但是在结尾发现是09 00,所以为假加密,把09 00 改成00 00就能解压打开文件了。

# -*- coding: cp936 -*-
import base64
flag = 'Tr0y{Base64isF4n}' #flag
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('0.txt', 'rb') as f0, open('1.txt', 'wb') as f1: #'0.txt'是明文, '1.txt'用于存放隐写后的 base64
for line in f0.readlines():
rowstr = base64.b64encode(line.replace('\n', ''))
equalnum = rowstr.count('=')
if equalnum and len(bin_str):
offset = int('0b'+bin_str[:equalnum * 2], 2)
char = rowstr[len(rowstr) - equalnum - 1]
rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset])
bin_str = bin_str[equalnum*2:]
f1.write(rowstr + '\n')# -*- coding: cp936 -*-
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('1.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = ''.join(line.split())
rowb64 = ''.join(stegb64.decode('base64').encode('base64').split())
offset = abs(b64chars.index(stegb64.replace('=','')[-1])-b64chars.index(rowb64.replace('=','')[-1]))
equalnum = stegb64.count('=') #no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print ''.join([chr(int(bin_str[i:i + 8], 2)) for i in xrange(0, len(bin_str), 8)]) #8十一、linux系统文件隐写
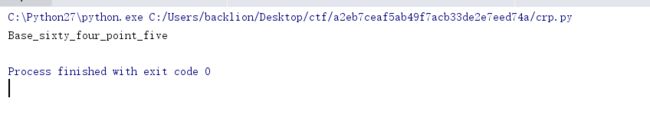
1.winHex打开压缩包,搜索文本flag,找到flag.txt和它的路径:/O7avZhikgKgbF/flag.txt







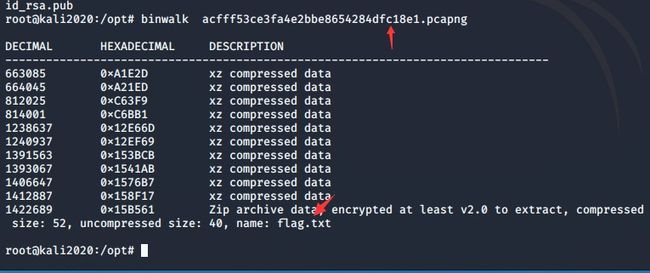


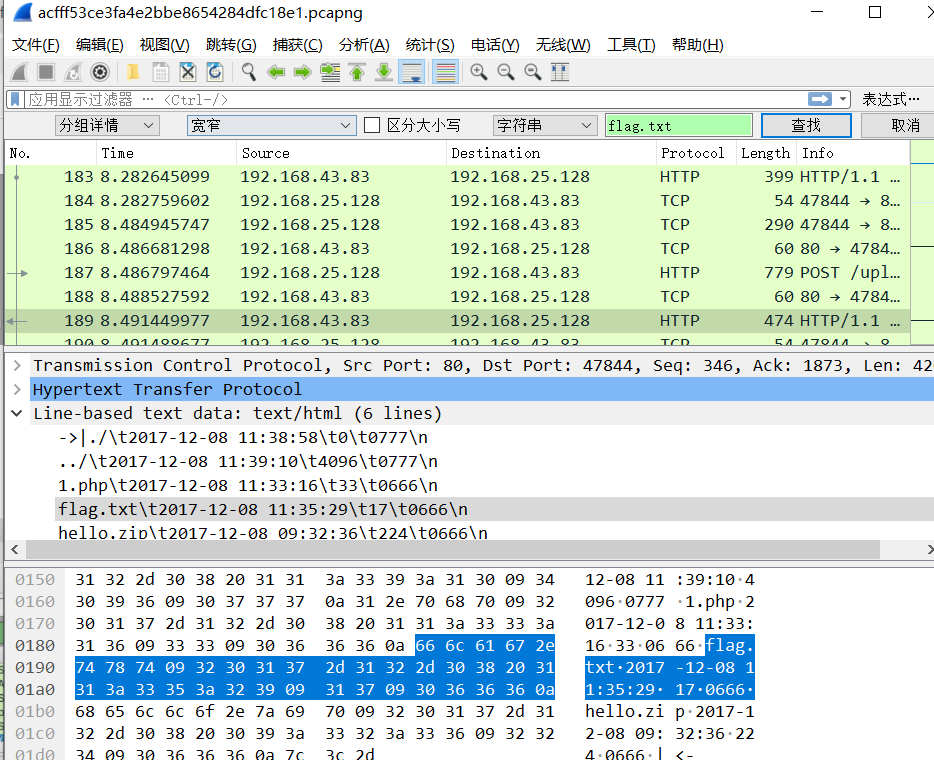
十二、流量包隐写之jpg
1.使用wireshark分析,在wieshark中的编辑---查找分组--分组详情,字符串,中搜索字符串,flag.txt,进行查找分析
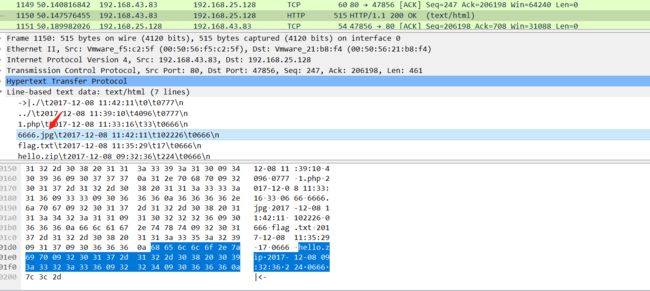
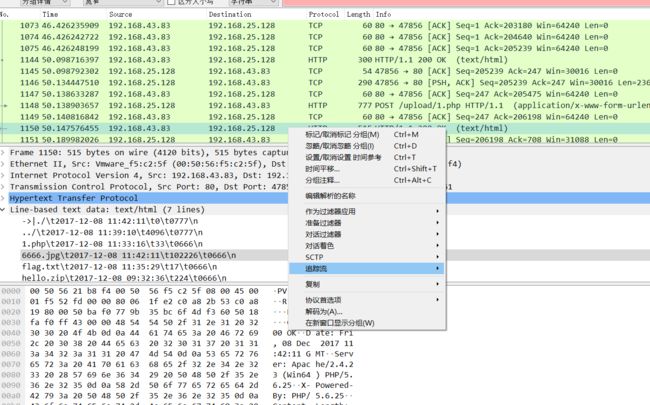
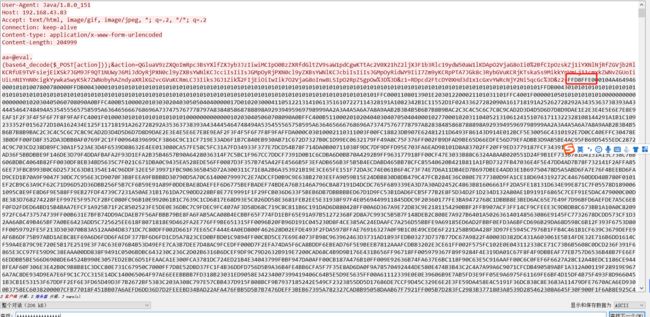

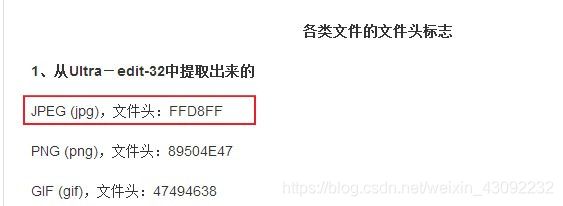
5.FFD8FF是jpg文件的文件头,附上各类图的文件头:
6.把以FF D8开头、FF D9结尾的这部分复制,并在winhex中新建文件并粘贴,注意粘贴格式选择为ASCII Hex(建议先全选复制到记事本然后删去头尾比较方便),放到winhex里面新建一个文件,以ASCII Hex的形式复制进去,保存为jpg文件
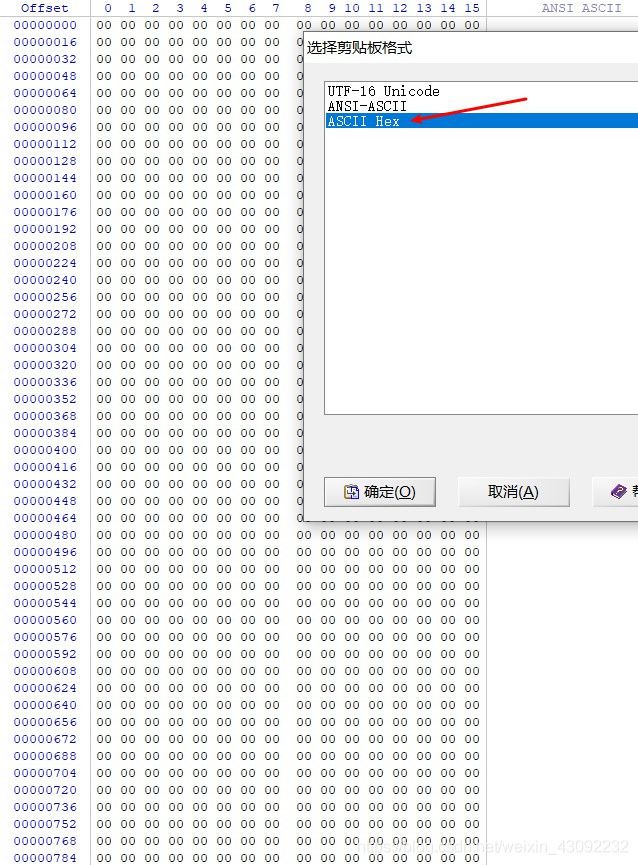
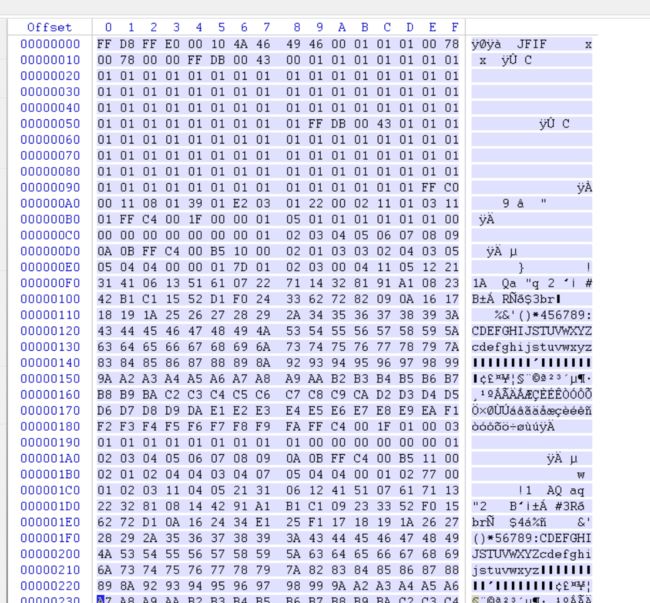
十三、gif图片隐写二

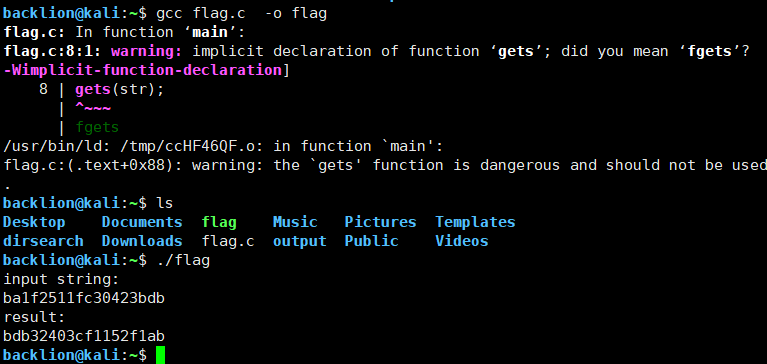
十四、C语言编译执行
$ gcc flag.c -o flag
$ ./flag
input string:
warning: this program uses gets(), which is unsafe.
ba1f2511fc30423bdb
result:
bdb32403cf1152f1ab
十五、flag格式取反
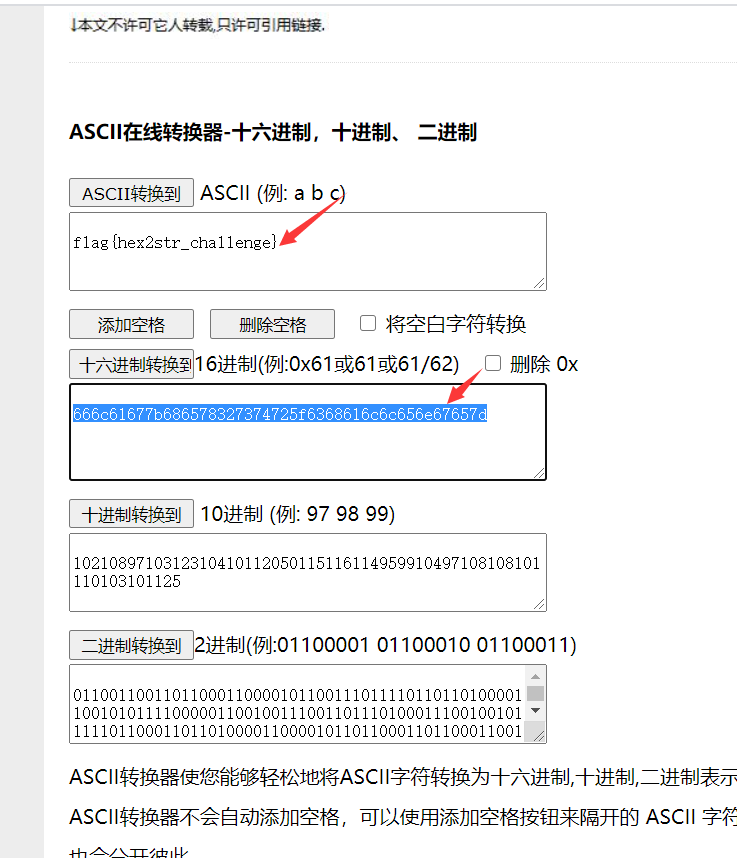
十六、十六进制转ASCII码
十七、rc4密码解密
题目:
rc4的key为, welcometoicqedu
加密密码为:UUyFTj8PCzF6geFn6xgBOYSvVTrbpNU4OF9db9wMcPD1yDbaJw== ,求明文
writetup:
1.通过python脚本解密
import random, base64from hashlib import sha1def crypt(data, key): x = 0 box = range(256) for i in range(256): x = (x + box[i] + ord(key[i % len(key)])) % 256 box[i], box[x] = box[x], box[i] x = y = 0 out = [] for char in data: x = (x + 1) % 256 y = (y + box[x]) % 256 box[x], box[y] = box[y], box[x] out.append(chr(ord(char) ^ box[(box[x] + box[y]) % 256])) return ''.join(out)def tdecode(data, key, decode=base64.b64decode, salt_length=16): if decode: data = decode(data) salt = data[:salt_length] return crypt(data[salt_length:], sha1(key + salt).digest())if __name__ =='__main__': data = 'UUyFTj8PCzF6geFn6xgBOYSvVTrbpNU4OF9db9wMcPD1yDbaJw ==' key = 'welcometoicqedu' decoded_data = tdecode(data=data, key=key) print decoded_data
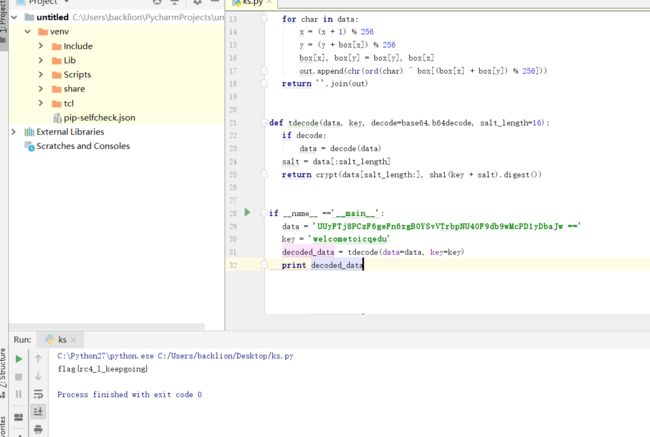

最终得到flag:flag{rc4_l_keepgoing}
十八、二进制隐写
1.使用winhex打开,查看前后没有什么信息,使用ctrl+f查找关键字flag,找到答案
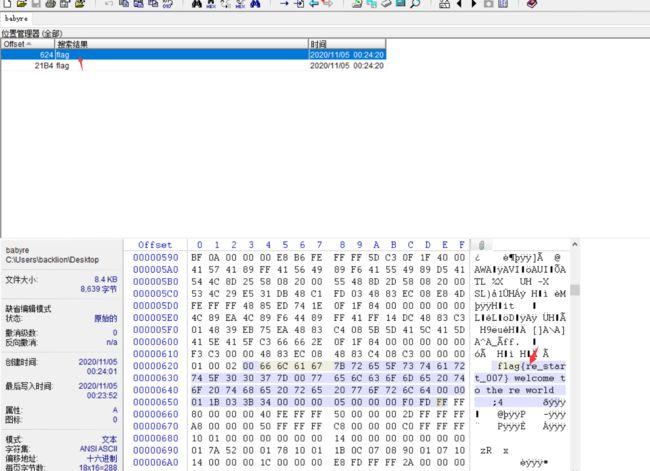
十九、MD5解密
题目:
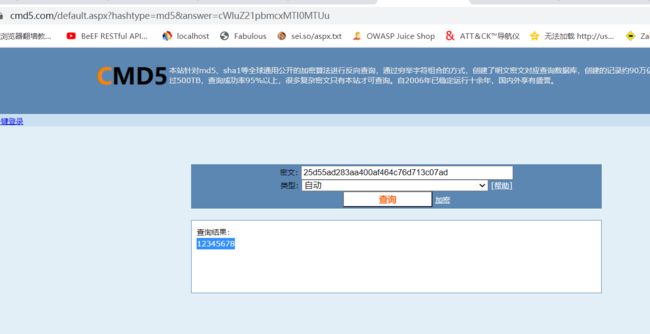
听说这是某个数据库的泄漏的重要数据,25d55ad283aa400af464c76d713c07ad,试着找出原始key吧。flag{key}
writeup:
1.数据库泄露的重要数据?那猜想应该是md5加密,且了解字符的话就会知道是MD5,所以在线MD5解密
http://www.cmd5.com/,得出答案12345678。
二十、凯撒密码
import pyperclip
message = 'gmbh{4d850d5c3c2756f67b91cbe8f046eebd}'
LETTERS = 'abcdefghijklmnopqrstuvwxyz'
for key in range(len(LETTERS)):
translated = ''
for symbol in message:
if symbol in LETTERS:
num = LETTERS.find(symbol)
num = num - key
if num < 0:
num = num + len(LETTERS)
translated = translated + LETTERS[num]
else:
translated = translated + symbol
print('Key #%s:%s'%(key,translated))2.使用工具解密: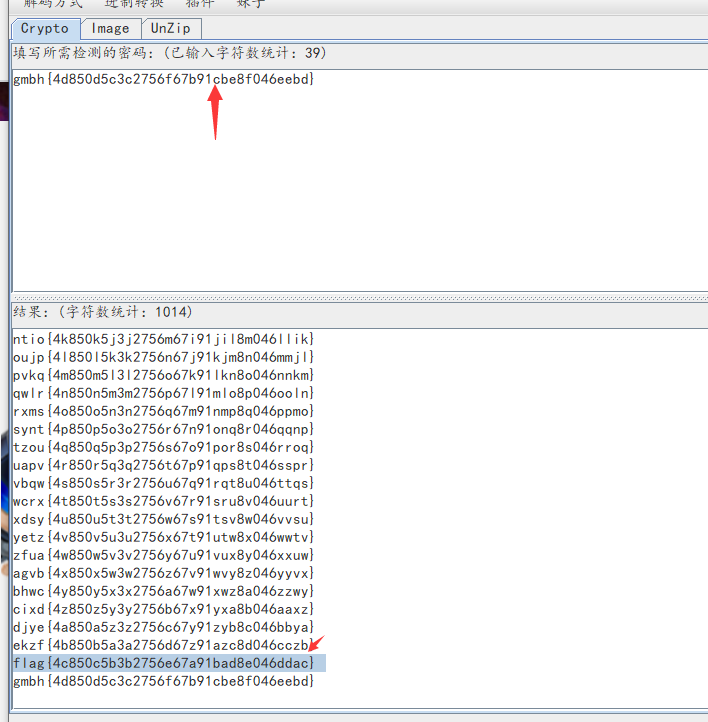
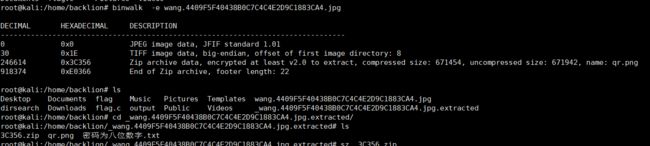
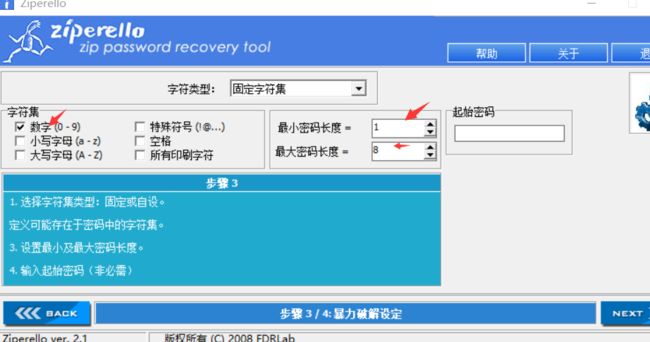
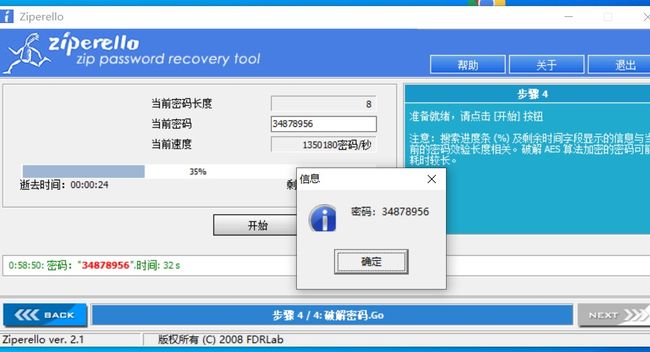
二十一、图片影写之zip爆破
binwalk -e 1.jpg 分出来一个含有密码的3c356.zip压缩包,其中里面含有一个Txt 和一个png 。


二十二、Rot13解密
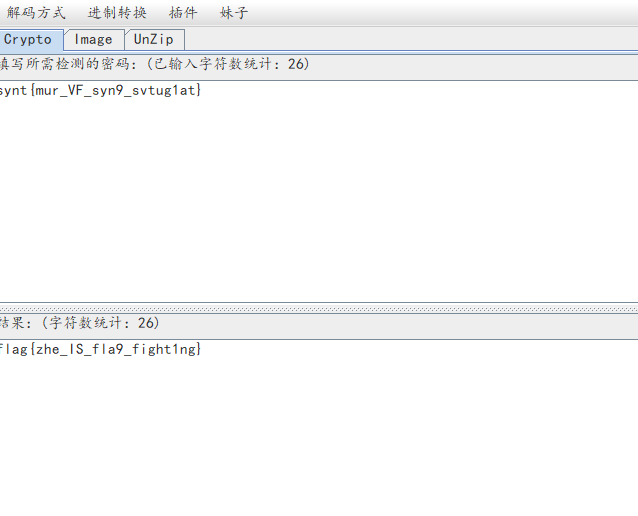
writeup:
1.根据题目内容,猜测是rot13解密,那么通过在线工具
https://rot13.com/

2.离线工具crackt00ls工具进行解密
#coding:utf-8
import string
def decoder(crypt_str,shift):
crypt_list = list(crypt_str)
plain_str = ""
num = int(shift)
for ch in crypt_list:
ch = ord(ch)
if ord('a') <= ch and ch <= ord('z'):
ch = ch + num
if ch > ord('z'):
ch -= 26
if ord('A') <= ch and ch <= ord('Z'):
ch = ch +num
if ch > ord('Z'):
ch -= 26
a=chr(ch)
plain_str += a
print(plain_str)
crypt_str = raw_input("Crypto_text:")
print "!------decode------!"
shift=13
decoder(crypt_str,shift)
二十三、莫斯密码解密
题目:
..-. .-.. .- --. . --... .---- -.-. .- ..... -.-. -.. -....- --... -.. -... ----. -....- ....- -... .- ...-- -....- ----. ...-- ---.. ...-- -....- .---- .- ..-. ---.. -.... --... ---.. ---.. .---- ..-. ----- --...

flage71ca5cd-7db9-4ba3-9383-1af867881f07二十四、栅栏密码
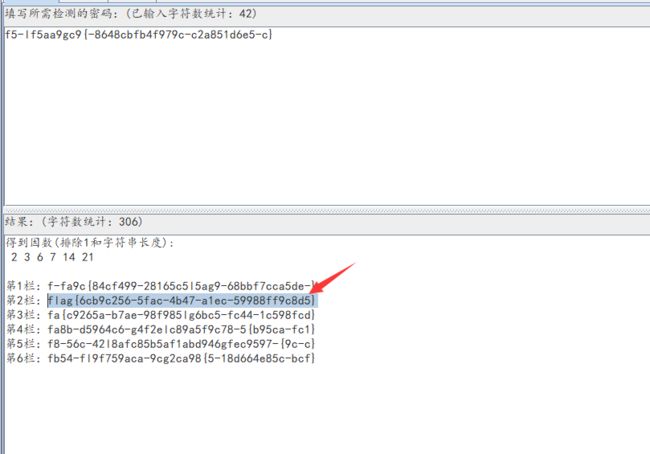
题目:
山岚,f5-lf5aa9gc9{-8648cbfb4f979c-c2a851d6e5-c}
writeup:
1.根据题目内容山岚和栅栏谐音,猜测是栅栏加密,通过crackt00ls工具进行解密,其中字符就包含了flag,那么确认猜测没错。
#!/usr/bin/env python
# -*- coding: utf_8 -*-
e = raw_input('pleas input sring\n')
elen = len(e)
field=[]
for i in range(2,elen):
if(elen%i==0):
field.append(i)
for f in field:
b = elen / f
result = {x:'' for x in range(b)}
for i in range(elen):
a = i % b;
result.update({a:result[a] + e[i]})
d = ''
for i in range(b):
d = d + result[i]
print 'while is\t'+str(f)+'\t'+'lan: '+d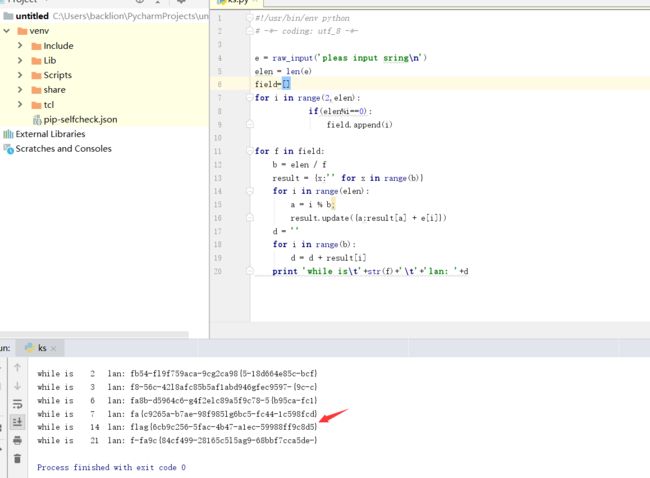
二十五、Unicode转ascii
题目:\u0066\u006c\u0061\u0067\u007b\u0074\u0068\u0031\u0073\u005f\u0069\u0073\u005f\u0055\u006e\u0031\u0063\u0030\u0064\u0065\u005f\u0079\u006f\u0075\u005f\u004b\u006e\u006f\u0077\u003f\u007dwriteup:1.根据编码格式,发现\u就是unicode编码,通过crackt00ls工具转换成ascii
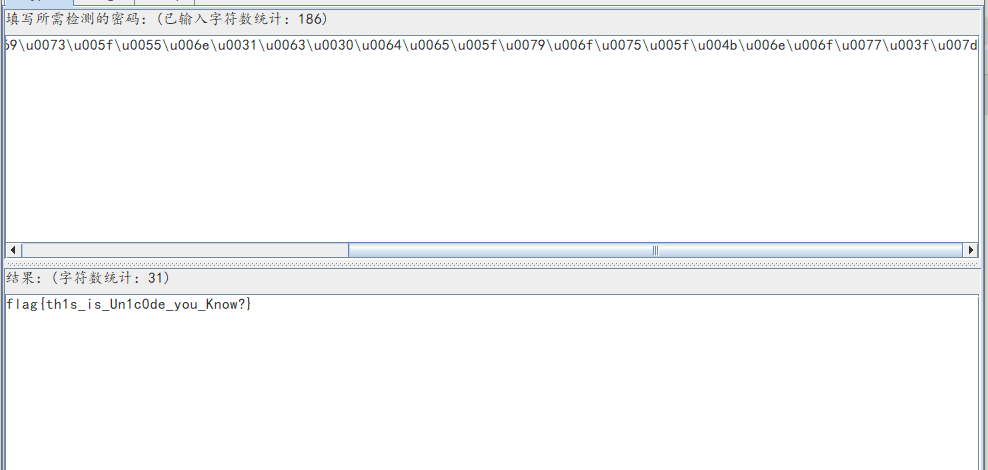 2.最终获得flag:
flag{th1s_is_Un1c0de_you_Know?}
2.最终获得flag:
flag{th1s_is_Un1c0de_you_Know?}
二十六、XXencode编码
题目:
XX?字符:
LNalVNrhIO4ZnLqZnLpVsAqtXA4FZTEc+
writeup:
基础知识:
XXEncode是一种二进制到文字的编码!它跟UUEncode以及Base64编码方法很类似。
它也是定义了用可打印字符表示二进制文字一种方法,不是一种新的编码集合。XXEncode将输入文本以每三个字节为单位进行编码,
如果最后剩下的资料少于三个字节,不够的部份用零补齐。三个字节共有24个Bit,
以6-bit为单位分为4个组,每个组以十进制来表示所出现的字节的数值。这个数值只会落在0到63之间。它64可打印字符固定字符范围及顺序!
包括大小写字母、数字以及+-字符。它较UUEncode编码优点在于它64字符是常见字符,没有任何特殊字符!
Xxencode编码原理:
XXencode将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6bit为单位分为4个组,每个组以十进制来表示所出现的数值只会落在0到63之间。以所对应值的位置字符代替。它所选择的可打印字符是:+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz,一共64个字符。跟base64打印字符相比,就是uuencode多一个“-” 字符,少一个”/” 字符。 但是,它里面字符顺序与Base64完全不一样。与UUencode比较,这里面所选择字符,都是常见字符,没有特殊字符。这也决定它当年流行使用原因!
每60个编码输出(相当于45个输入字节)将输出为独立的一行,每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“h”这个字符(45,刚好是64字符中,第45位'h'字符),最后一行的长度字符为剩下的字节数目 在64字符中位置所代表字符。
问题:uuencode编码转换为xxencode编码怎么样操作?从编码原理来看,几乎一样。就是所用的64个字符不一样。一次,简单对uuencode转换后字符,逐位(处理'`'字符)减去32,然后得到一个值。这个值在xxencode 64字符中所对应位置字符替换即可。
XXencode编码转换过程:
原始字符
C
a
t
原始ASCII码(十进制)
67
97
116
ASCII码(二进制)
0
1
0
0
0
0
1
1
0
1
1
0
0
0
0
1
0
1
1
1
0
1
0
0
新的十进制数值
16
54
5
52
编码后的XXencode字符
E
q
3
O
字符串:'Cat‘ 编码后是:Eq3O
writeup:
1.根据题目名称xx,可将xxencode编码转ascii
这里通过在线:http://web.chacuo.net/charsetxxencode,进行转码

二十七、base32解密
我喜欢贝丝,但是贝丝的表妹喜欢我
还给了我一封情诗
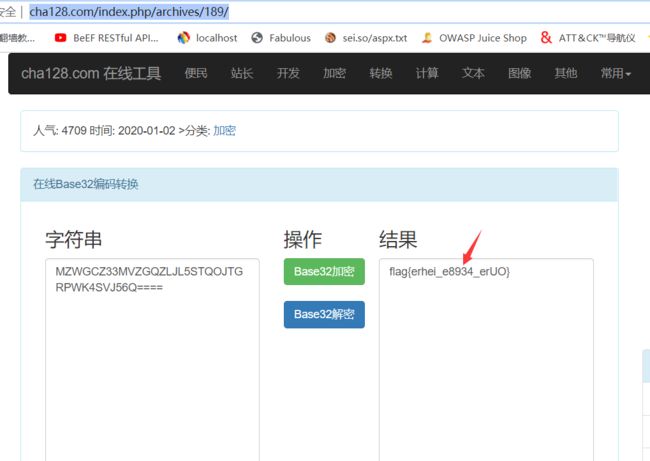
MZWGCZ33MVZGQZLJL5STQOJTGRPWK4SVJ56Q====
writeup:
base家族有base64,base32,base16
1.Base16编码是包含了数字(0~9)和大写字母(A~F),Base32编码与Base64编码最大区别是前者没有小写字母.Base32编码可以用于文件系统的名称(不区分大小情况).而Base64编码后数据量相比原先不是增加很多,可以用于网络传输.
2.根据特征是base32
3.那么可以通过在线工具进行解密
http://www.cha128.com/index.php/archives/189/
二十八、键盘布局加密
题目:
方方格格,不断敲击
“wdvtdz qsxdr werdzxc esxcfr uygbn”
flag格式为:flag{小写的字符串}
1.根据提示我们可以猜到这个是采用了键盘拼写方式得出的键盘布局图形样式:(这块最好用画按照键盘画好)
wdvtdz x
qsxdr v
werdzxc z
esxcfr o
uygbn c
2.最终组合起来为:xvzoc
flag为:flag{xvzoc}
二十九、十进制与十六进制转换
题目:
低频ID卡数据格式转换小常识
将下列16进制串中倒数第5,6位转换为3位十进制数,
将最后4位转换为5位十进制卡号,中间用“,”分开。
0000944664
writeup:
1.根据提示,先将十六进制94转换为十进制148,然后再将十六进制4664转换成十进制18020
它们之间以逗号分隔,最终组合得到,前面000需要去掉。
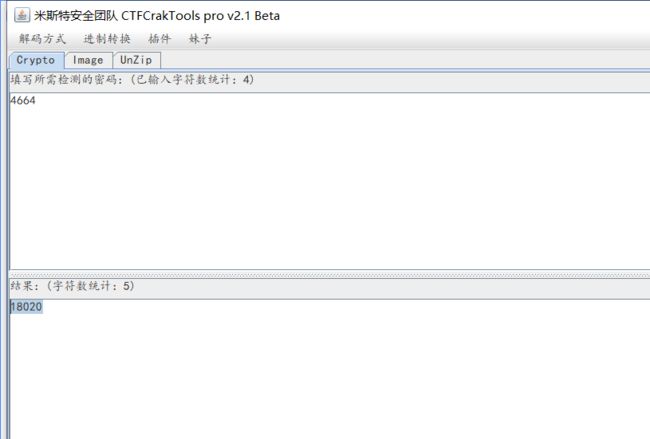
2.最终获得flag:
flag{148,18020}
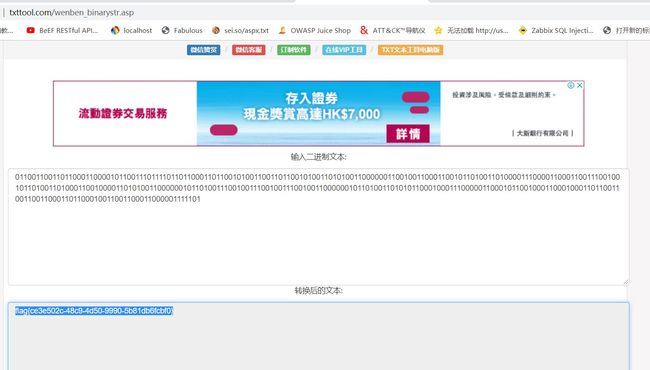
三十、二进制转ascii
题目:
让我们回到最开始的地方
011001100110110001100001011001110111101101100011011001010011001101100101001101010011000000110010011000110010110100110100001110000110001100111001001011010011010001100100001101010011000000101101001110010011100100111001001100000010110100110101011000100011100000110001011001000110001000110110011001100110001101100010011001100011000001111101
1.通过在线工具进行解密
http://www.txttool.com/wenben_binarystr.asp
三十一、base16解密
题目:
有一天,表姐的好朋友贝丝远房的表亲,一个16岁的少年
给表姐递了一封情书,表姐看不懂,你能帮忙翻译下吗?
666C61677B65633862326565302D336165392D346332312D613031322D3038616135666137626536377D
writeup:
1.根据题目含义16岁少年,并且是含有贝丝,猜测为base16解密
2.通过在线工具进行解密
http://www.atoolbox.net/Tool.php?Id=930
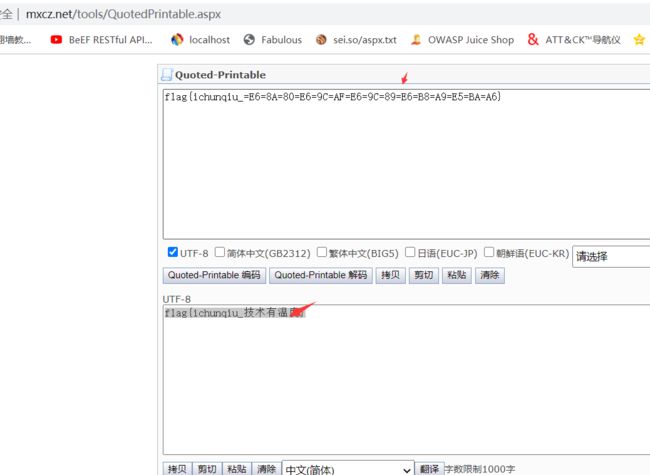
三十二、邮件头中的Quoted-printable编码
题目内容:
flag{ichunqiu_=E6=8A=80=E6=9C=AF=E6=9C=89=E6=B8=A9=E5=BA=A6}
基础知识:
Quoted-printable 可译为“可打印字符引用编码”、“使用可打印字符的编码”,我们收邮件,查看信件原始信息,经常会看到这种类型的编码!
任何一个8位的字节值可编码为3个字符:一个等号”=”后跟随两个十六进制数字(0–9或A–F)表示该字节的数值
writeup:
三十三、变形的培根密码
题目内容:
麻辣烫的标配。flag{abbab_babbb_baaaa_aaabb}
writeup:
1.根据题目内容包括abab循环,从特征上看是培根密码,这里需要将下划线去掉,最终得到:abbabbabbbbaaaaaaabb
2.通过在线解密工具,即可获得flag
三十四、jpg图片影写一
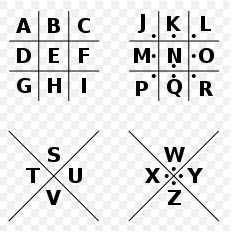
三十五、猪圈密码


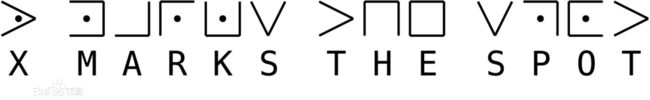
三十六、键盘坐标密码
题目内容:
哒哒哒哒,你知道什么是键盘坐标密码吗?
11 21 31 18 27 33 34
flag格式:flag{*****
基础知识:
我们注意到大键盘区所有的字母上面都有其对应的数字,这个位置几乎在所有的键盘都是相同的。所以我们可以利用这一点应用单表替换的方法进行加密[注2]:
1 2 3 4 5 6 7 8 9 0
Q W E R T Y U I O P
A S D F G H J K L
Z X C V B N M
我们根据上表可以得出,Q是1下面的第一个,A是1下面的第二个……以此类推,每一个字母都会有其对应的数字:
A 12 B 53 C 33
第一个数字代表横向(X坐标)的位置,第二个数字代表纵向(Y坐标)的位置
writeup:
根据上面对应表,可获得flag:
flag{QAZIJCV}
三十七、变形的莫斯密码
题目内容:
贝克街旁的圆形广场
·-· ·-· ·-· ·-· ·-· ·-· ·
writeup:
1.题目给的这种字符一般解不出 ·-· ·-· ·-· ·-· ·-· ·-· , 一般模式电码是点在下面, 横在上面.改成:
.-. .-. .-. .-. .-. .-. .
2.通过crackt00ls工具解密
三十八、brainfuck加密
题目内容:
例:
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook! Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook!
Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook.
Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook.
Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook! Ook.
Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook!
Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook?
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook?
Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook! Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook! Ook.
Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook!
Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook.
Ook. Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook.
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook.
Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook.
Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook.
为Ook!编码后如下图:
+++++ +++++ [->++ +++++ +++<] >++.+ +++++ .<+++ [->-- -<]>- -.+++ +++.< ++++[ ->+++ +<]>+ +++.< +++[- >---< ]>--- .---- .<+++ ++++[ ->--- ----< ]>--- ----- ----- .<+++ ++++[ ->+++ ++++< ]>+++ ++.<+ +++++ +[->- ----- -<]>. <++++ ++++[ ->+++ +++++ <]>++ .<+++ [->-- -<]>- ----. <++++ +++[- >---- ---<] >---- ----. +++++ +..++ +++.+ .<+++ [->-- -<]>- --.<+ +++++ +[->+ +++++ +<]>+ ++.++ +.+++ +++++ +.--- -.+++ ++.<+ ++[-> +++<] >++++ ++.<writeup:1.通过在线解密即可获得flag:http://splitbrain.org/services/ook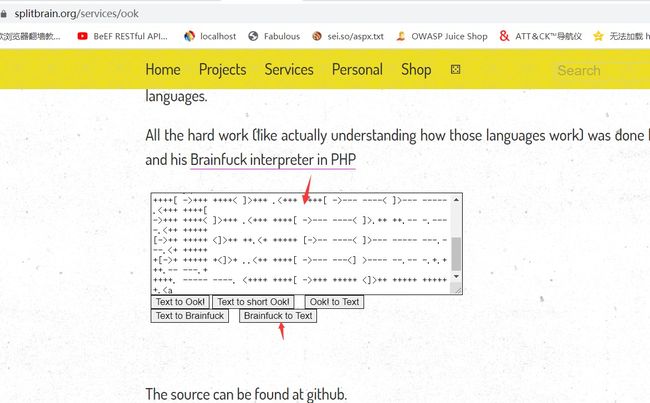
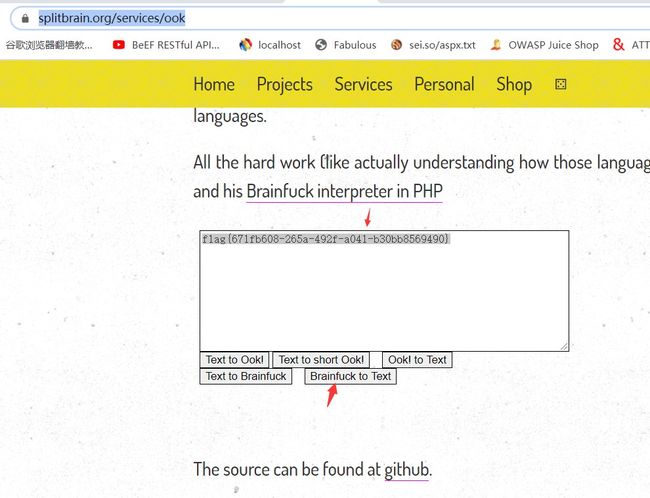 2.最终flag:flag{671fb608-265a-492f-a041-b30bb8569490}
2.最终flag:flag{671fb608-265a-492f-a041-b30bb8569490}三十九、压缩包多文件隐写之flag
题目内容:
压缩包中包含多个文件,且每个文件有一个字母
writeup:
1.通过notepad发现每个文件中含有一个字母
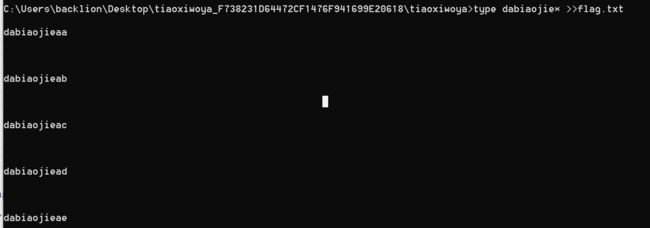
2.通过cmd命令和管道符合即可批量将文件中的内容输出到一个文件中
进入解压后的目录,然后输入cmd命令:
type dabiaojie* >>flag.txt
 3.通过notepad查看flag.txt,进行重新组合,
去掉后面没用的字母(中括号后面的字母)
3.通过notepad查看flag.txt,进行重新组合,
去掉后面没用的字母(中括号后面的字母)
 4.最终获得flag:
flag{0a47061d-0619-4932-abcd-5426f4ea34aa}
4.最终获得flag:
flag{0a47061d-0619-4932-abcd-5426f4ea34aa}
四十、zip明文加密
题目内容:
讲真的,才华已经枯竭
大家好好答题
也许这道题一点都不坑
也许。。。。。
wirteup:
1,先用zip伪加密破解,但是打开错误,也通过winhex查看zip文件政策
2.然后剩下zip破解了,这里有个提示是5句话,考虑5句话,可能就是密码字符长度为5位数,通过zip password tool对其破解,并且也说很简单不吭,说明是5位数字
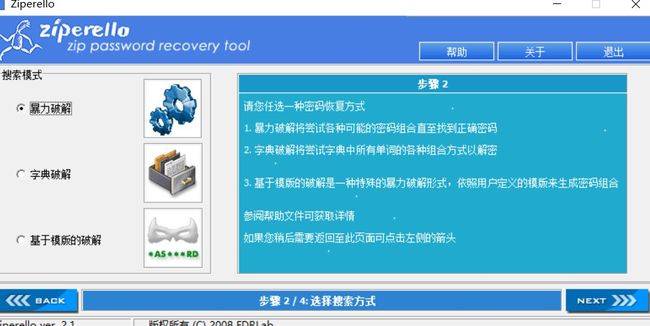
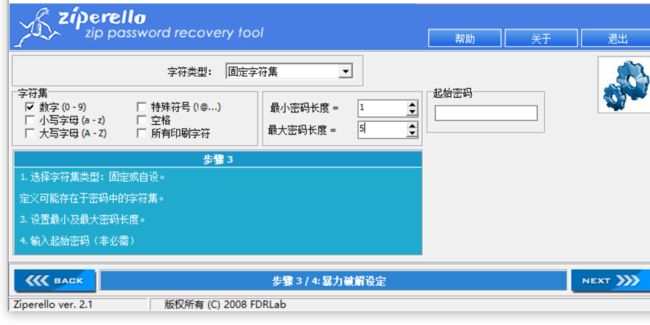
 3.最终破解为密码:12345,通过密码解压出文件并查看文件misc3.txt,最终获得flag:
flag{319b7f63-e17d-4ac5-8428-c2476c7ecce3}
3.最终破解为密码:12345,通过密码解压出文件并查看文件misc3.txt,最终获得flag:
flag{319b7f63-e17d-4ac5-8428-c2476c7ecce3}
四十一、波利比奥斯棋盘加密
题目内容:
需要帮助我将这个波斯传来的“波利比奥斯棋盘”上的秘密解决掉
华夜拿到该棋盘,只见棋盘盒上分布着一串十分奇异的数字:
“3534315412244543_434145114215_132435231542”
flag格式:flag{****} 全为小写字符串
基础知识:
波利比奥斯矩阵为排列顺序的一种数字与字母的密码表,当然每个国家的密码排布并不一样,这里只展示最常用的一种排布方式。如图所示,它是一个6行6列的矩阵,第一行为数字1~5,第一列也为数字1~5,表里是26个字母,除了I与J以外,每个字母都各占据一个格子,也就是每个字母都有它们的数字表示,类似于坐标。
它们的坐标读取并不是我们习惯的行列读取,而是与之列行读取。比如字母“B”,用数字表示它就是“12”,而不是“21”。比如要表达单词“HELP”,则写成密码就是23 15 31 35。
判断是否是用棋盘密码破解的方式页很简单,只要出现数字是成双出现的数组串,而且有出现最大数字大于26的,那是棋盘密码的可能性就很大。
writeup:
1.题目重要的部分是“波利比奥斯棋盘”和一串数字“3534315412244543_434145114215_132435231542”
2.百度波利比奥斯棋盘,简单的来说就是把字母排列好,用坐标的形式表现出来。字母是密文,明文便是字母的坐标。它是一个6行6列的矩阵,第一行为数字1~5,第一列也为数字1~5,表里是26个字母,除了I与J以外,每个字母都各占据一个格子,也就是每个字母都有它们的数字表示,类似于坐标。

3.把数字每两位分成一组,然后按照行列的方式找出字母,比如35就是第3行的第5列为P,以此类推
35 34 31 54 12 24 45 43_43 41 45 11 42 15_13 24 35 23 15 42
P O L Y B I/J U S S Q U A R E C I/J P H E R
4.题目提示小写字母,所以构造flag{polybius_square_cipher},注:这里的24有两个对应的字母,尝试i是正确的,而j是错误的,且和原来的格式要保持一致。
四十二、base64隐写之藏头诗
题目内容:
他将这首残诗刻在了通往第四层虚数空间的通关法诀上
只有填满句诗词,才能走出这层虚数空间
5LiD5pyI5Zyo6YeOICA=
5YWr5pyI5Zyo5a6HIA==
5Lmd5pyI5Zyo5oi3
writeup:
1.通过base64在线解密工具获得三个base64解密(本地解密工具会出现乱码,可能式编码问题)
https://base64.us/
2.解密出:
七月在野
八月在宇
九月在户
3.通过百度搜索,发现它的下一句是:十月蟋蟀入我床下

4.最终flag:
flag{十月蟋蟀入我床下}
四十三、特殊二进制转ascii
01001001 01100011 01100101 01000011 01010100 01000110 01111011 01100001 01101100 00110001 0101111101101101 01111001 01011111 01100010 01100001 01110011 01100101 01110011 01011111 01100001 0111001001100101 01011111 01111001 01101111 01110101 01110010 01110011 01011111 01100001 01101110 0110010001011111 01100001 01101100 01101100 01011111 01111001 00110000 01110101 01110010 01011111 0110001001100001 01110011 01100101 01110011 01011111 01100001 01110010 01100101 01011111 01101101 0110100101101110 01100101 011111011.下载flag.txt是二进制的文本

3.二进制转十六进制,在对照ASCII码转为相应的字符
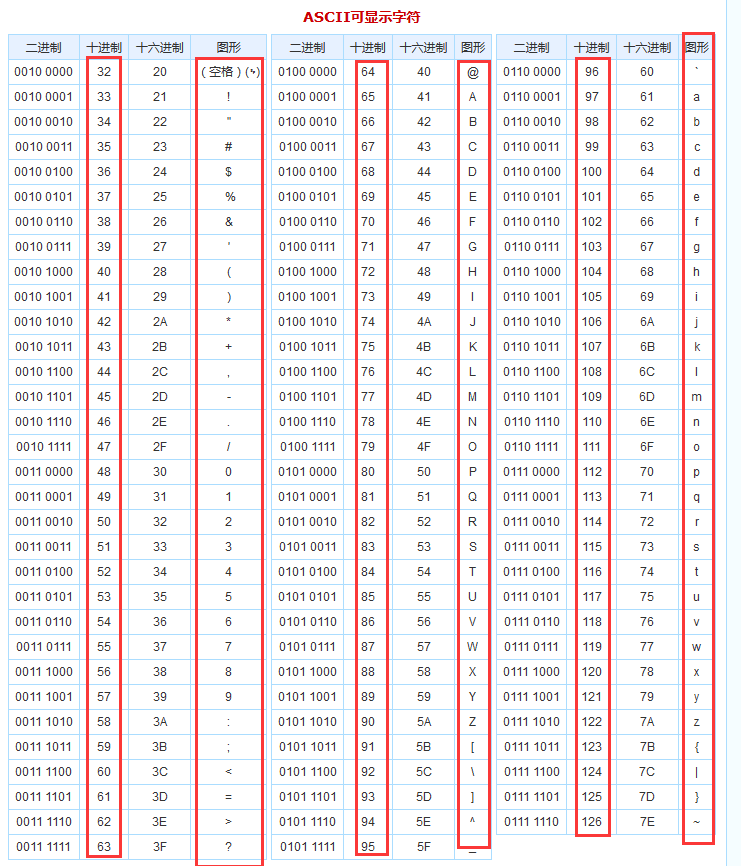
 4.最后答案将其下划线去掉,重新组合成flag:
4.最后答案将其下划线去掉,重新组合成flag:
四十四、PNG图片隐写一
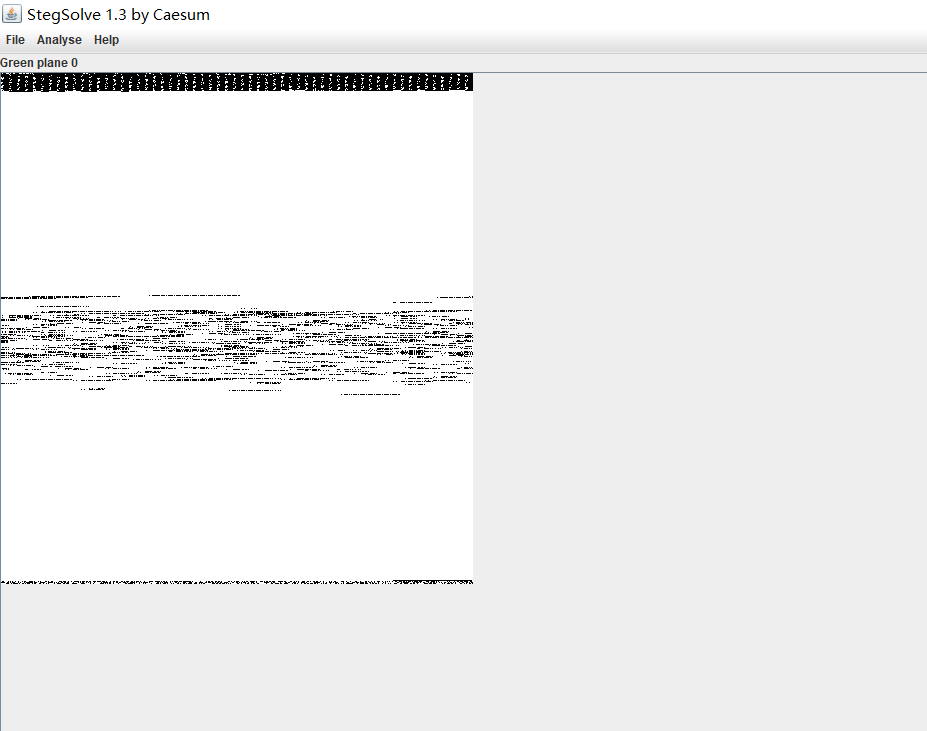
2.以用SetgSolve提取出图,点击Analyse -> Data Extract, 在弹出的窗口中把Rad, Green, Blue都勾上, 然后点击Preview

3.会发现头部是PNG, 表示这是一张PNG图片, 然后点击Save Bin, 把图片提取出来打开, 就出现了flag


四十六、jpg图片隐写二
四十七、流量包隐写
2.找一个正常的pcapng文件对比文件头,对kill.pacpng的文件头进行对应修改,修改后仍然无法打开
3.使用strings.exe对kill.pcapng中的可打印字符进行提取,保存到strings.txt文件中,命令
strings kill.pcapng >kill.txt

4.打开strings.txt,搜索flag,即可获得flag:
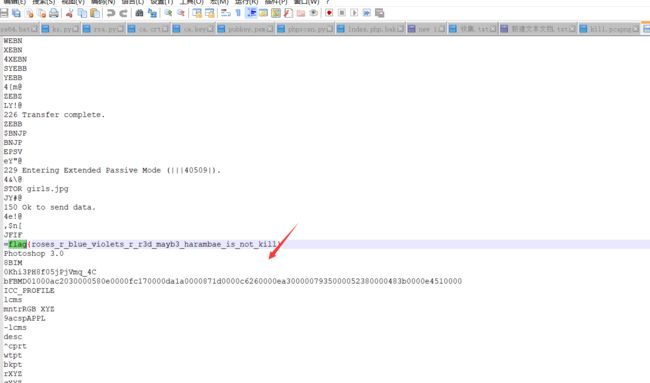
5.实际上直接notepad++打开搜索kill或者flag,更快找到答案,但因为文件有2M多,肯能会有点卡。
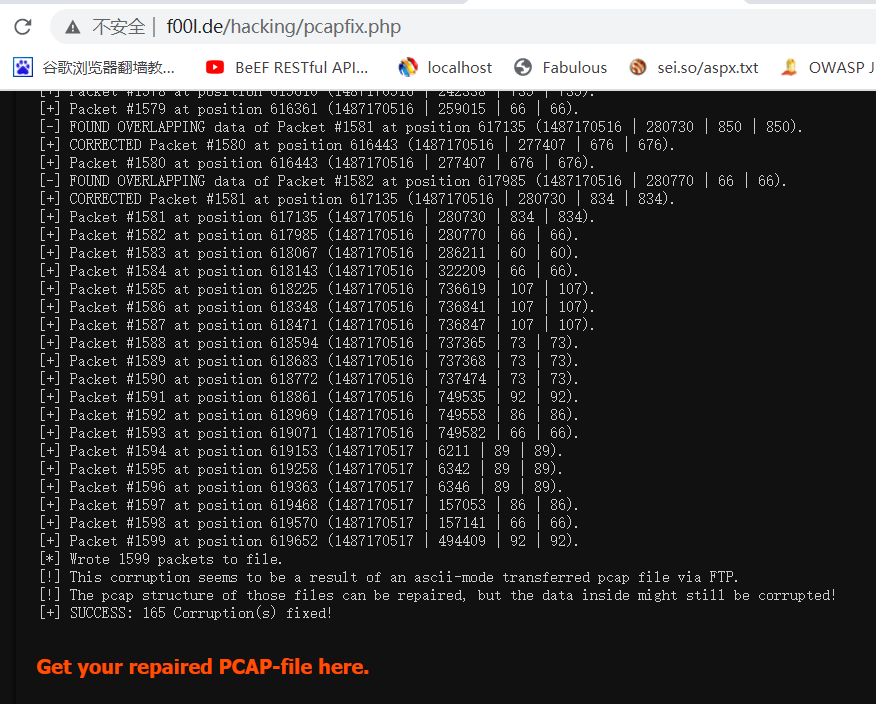
四十八、破损的流量包隐写

2.将cap包修复为pcap包,通过地址:http://f00l.de/hacking/pcapfix.php
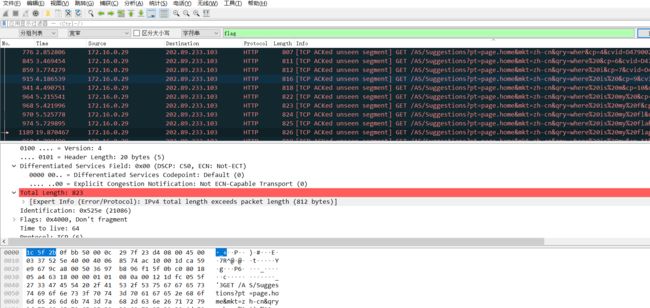
3.进行在线修复,修复完毕后用wireshark打开,查找分组字节流-字符串-flag:
4.或者通过notepad,搜索flag关键字,发现提示where is the flag

四十九、Bubble Babble Binary Data Encoding 编码
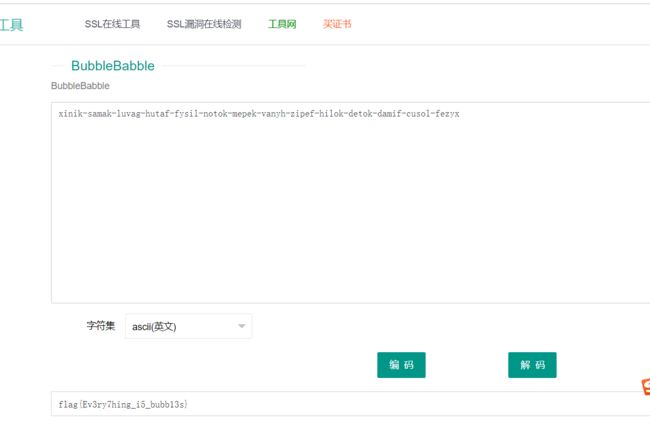
from bubblepy import BubbleBabble
str='xinik-samak-luvag-hutaf-fysil-notok-mepek-vanyh-zipef-hilok-detok-damif-cusol-fezyx'
bb = BubbleBabble()
print (bb.decode(str))
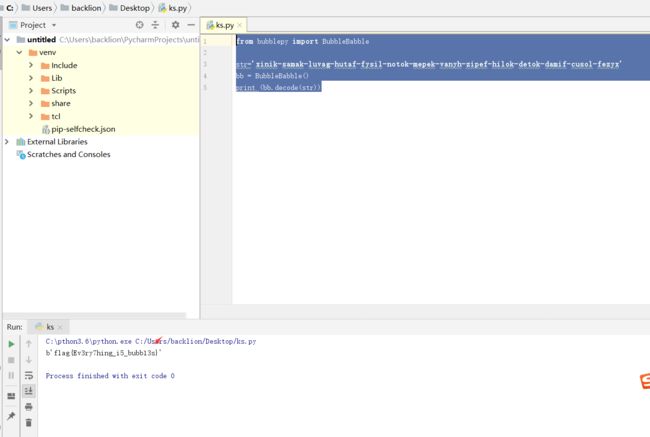
flag{Ev3ry7hing_i5_bubb13s}五十、lzip文件隐写
1.下载文件,打开看到如下,通过winhex软件打开的界面

2.利用linux下面的命令xxd,可以将类似文本转换为文件
cat thor.txt |xxd -r >thorfile //查看thor.txt十六进输出,并通过xxd -r 转换成二进制文件

3.使用winhex打开文件thorfile,发现文件头为LZIP
5.在linux下使用lzip命令对文件进行解压
lzip -d thorfile //对lzip文件进行解压,得到thorfile.out文件
6.使用winhex打开文件thorfile.out,文件头为有JFIF,文件头格式为:文件头:FFD8FFE0(JPEG (jpg))

7.将文件名后缀修改为jpeg,打开文件看到图片,看到答案

8.最终得到flag
五十一、mid音乐文件隐写
1.附件下载,然后使用winhex查看文件信息,发现文件头是mid格式

五十二、十六进制转二维码
题目内容:
0x00000000
0xff71fefe
0x83480082
0xbb4140ba
0xbb6848ba
0xbb4a80ba
0x83213082
0xff5556fe
0xff5556fe
0x00582e00
0x576fb9be
0x707ef09e
0xe74b41d6
0xa82c0f16
0x27a15690
0x8c643628
0xbfcbf976
0x4cd959aa
0x2f43d73a
0x5462300a
0x57290106
0xb02ace5a
0xef53f7fc
0xef53f7fc
0x00402e36
0xff01b6a8
0x83657e3a
0xbb3b27fa
0xbb5eaeac
0xbb1017a0
0x8362672c
0xff02a650
0x00000000
writeup:
1.like to approach problems with a fresh perspective and try to visualize the problem at hand,意思是将其内容转换成图像化
2.根据上面内容可知道是十六进制,我们可以将16进制数转化为图像,这里先尝试将16进制转换为二进制
000000000000000000000000000000000
011111111011100011111111011111110
010000011010010000000000010000010
010111011010000010100000010111010
010111011011010000100100010111010
010111011010010101000000010111010
010000011001000010011000010000010
011111111010101010101011011111110
000000000010110000010111000000000
001010111011011111011100110111110
001110000011111101111000010011110
011100111010010110100000111010110
010101000001011000000111100010110
000100111101000010101011010010000
010001100011001000011011000101000
010111111110010111111100101110110
001001100110110010101100110101010
000101111010000111101011100111010
001010100011000100011000000001010
001010111001010010000000100000110
010110000001010101100111001011010
011101111010100111111011111111100
000000000010000000010111000110110
011111111000000011011011010101000
010000011011001010111111000111010
010111011001110110010011111111010
010111011010111101010111010101100
010111011000100000001011110100000
010000011011000100110011100101100
011111111000000101010011001010000
000000000000000000000000000000000
3.这里看起来有点像一个二维码,可将0转化为白色,1转化为黑色,通过以下python脚本进行转换成二维码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from PIL import Image
import numpy as np
def hex2bin(hexmat):
binmattemp = [bin(m)[2:] for m in hexmat] # 全转成二进制
rowlen = max([len(m) for m in binmattemp]) # 取最宽的值
binmat = [[0] + [int(b) for b in row.zfill(rowlen)] for row in binmattemp] # 用0补齐
print rowlen + 1, 'x', len(binmat)
for i in xrange(len(binmat)):
print ''.join([str(b) for b in binmat[i]])
return binmat, rowlen + 1, len(binmat)
def rm_col(binmat, col): # 移除指定的列
return [row[:col] + row[col + 1:] for row in binmat]
def make_bw_img(binmat, w, h, outfilename, blackbit=0):
bwmat = [[0 if b == blackbit else 255 for b in row] for row in binmat] # 用255表示白,0表示黑
imagesize = (w, h)
img = Image.fromarray(np.uint8(np.array(bwmat)))
img.save(outfilename)
if __name__ == '__main__':
hexmat = [0x00000000,
0xff71fefe,
0x83480082,
0xbb4140ba,
0xbb6848ba,
0xbb4a80ba,
0x83213082,
0xff5556fe,
0x00582e00,
0x576fb9be,
0x707ef09e,
0xe74b41d6,
0xa82c0f16,
0x27a15690,
0x8c643628,
0xbfcbf976,
0x4cd959aa,
0x2f43d73a,
0x5462300a,
0x57290106,
0xb02ace5a,
0xef53f7fc,
0x00402e36,
0xff01b6a8,
0x83657e3a,
0xbb3b27fa,
0xbb5eaeac,
0xbb1017a0,
0x8362672c,
0xff02a650,
0x00000000]
binmat, w, h = hex2bin(hexmat)
binmat = rm_col(binmat, 22) # 发现第七行和第22行多余,故删除
binmat = rm_col(binmat, 7)
make_bw_img(binmat, w, h, 'matrix_rmcol.png', blackbit=1)4.最终会生成一张二维码图片以及显示转换成的二进制
 5.通过在线扫描二维码识别
https://jiema.wwei.cn/
5.通过在线扫描二维码识别
https://jiema.wwei.cn/
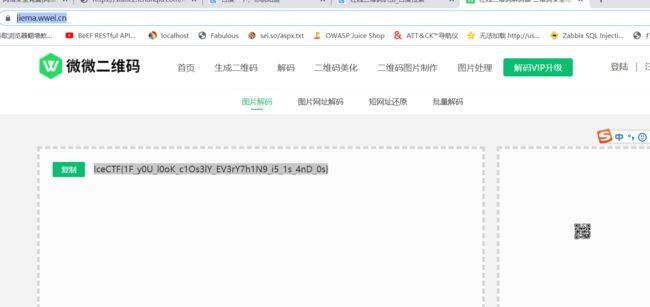
6.最终扫描获得flag:
IceCTF{HAck1n9_mU5Ic_W17h_mID15_L3t5_H4vE_a_r4v3}
五十三、流量文件隐写之数据包序号sha256解密
writeup:
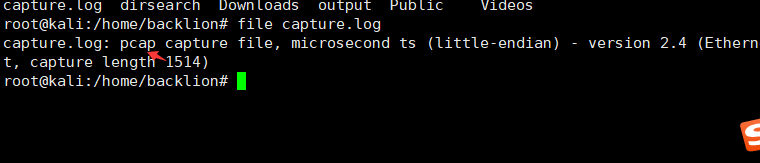
1.通过附件下载文件,获得capture.log文件,然后通过linux下的命令file查看文件类型,发现是pcap文件


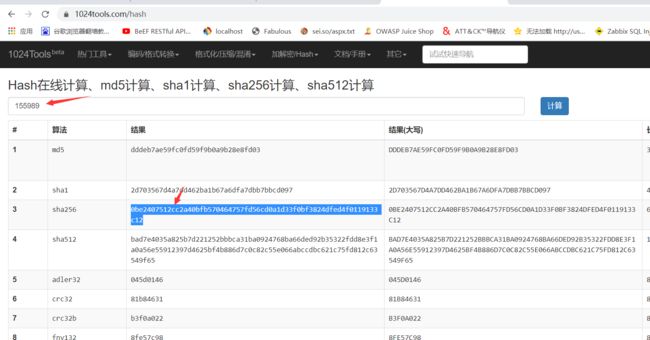
192.168.0.9发起第1次攻击数据包序号:1
192.168.0.9第2次攻击数据包序号:148007
192.168.0.9第3次攻击数据包序号:150753
192.168.0.199第4次攻击数据包序号:155989
6.通过在线sha256生成
https://1024tools.com/hash
五十四、apk文件隐写

五十五、zip明文攻击与盲水印
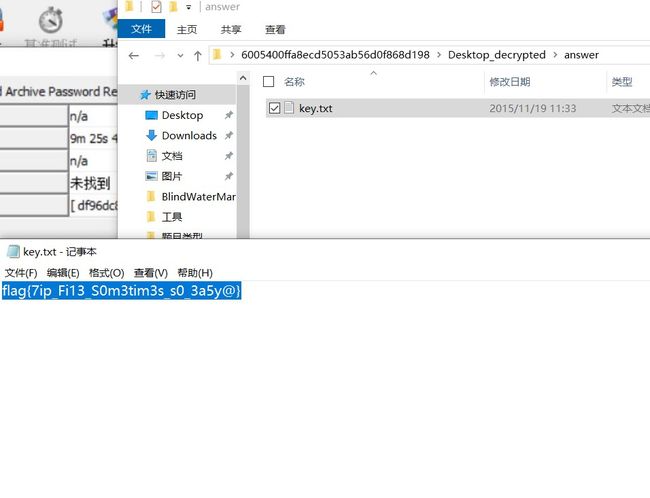
writeup:
1.解压出来是这样的
2.warmup里是这样的
:
3.用winrar软件对图片raopen_forum.png压缩成open_forum.zip文件

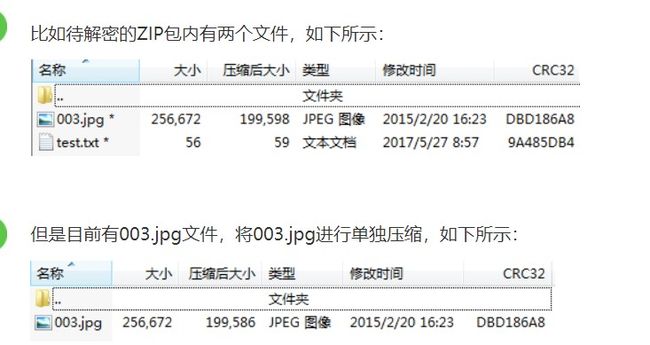
4.比较两个文件的是否为同一文件,这里比较CRC32的值

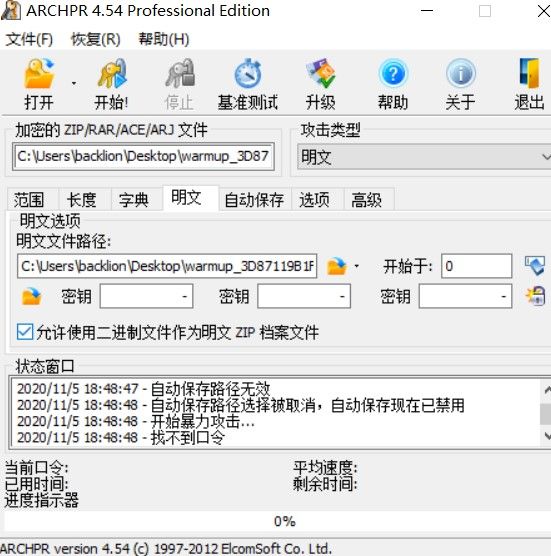
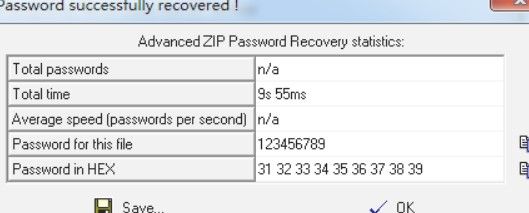
5.使用工具Advanced Archive Password Recover进行明文攻击


9.合成盲水印图:
盲水印用到的py脚本可以在github上下载,https://github.com/chishaxie/BlindWaterMark,使用时需要安装前置opencv-python库
python bwm.py decode fuli.png fuli2.png wm_out.png

10.成功拿到flag:

五十六、流量文件隐写之length序号转ascii
1.先下载压缩文件,然后解压文件,得到一个wireshark的数据包文件,用wireshark打开。并且题目提示ping,那么ping属于icmp协议,过滤icmp协议
按照时间顺序排序,发现包的长度有规律,并且都是request和reply一对应答和响应包
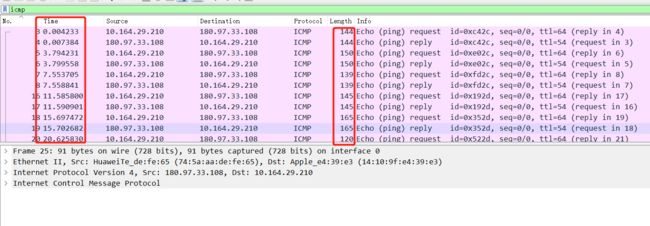

五十七、音频的隐写
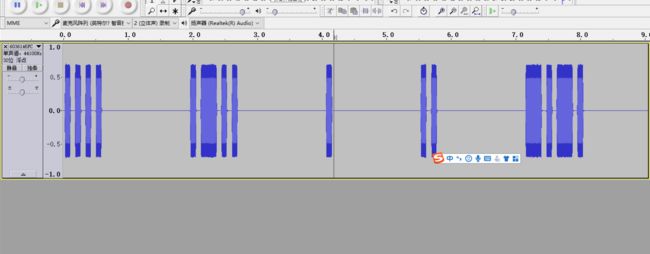
五十八、zip的明文攻击

五十九、png图片隐写之bmp图片

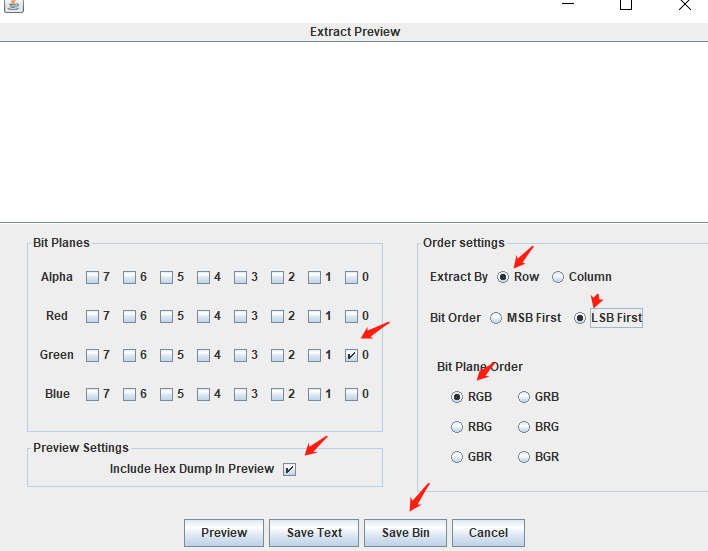


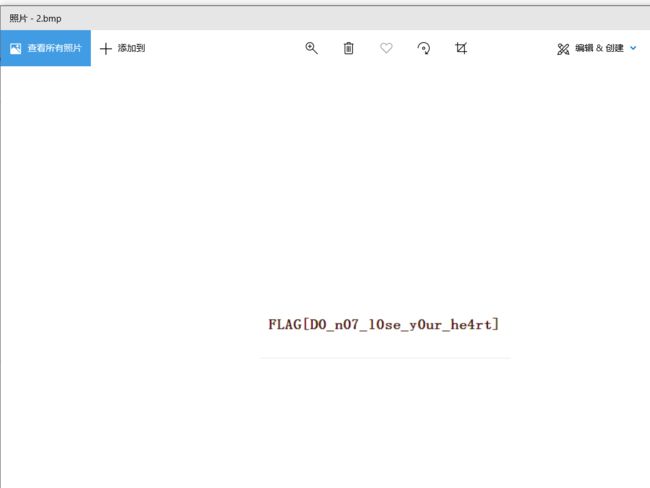
六十、反转pyc文件隐写之zip伪加密包含的mp3文件
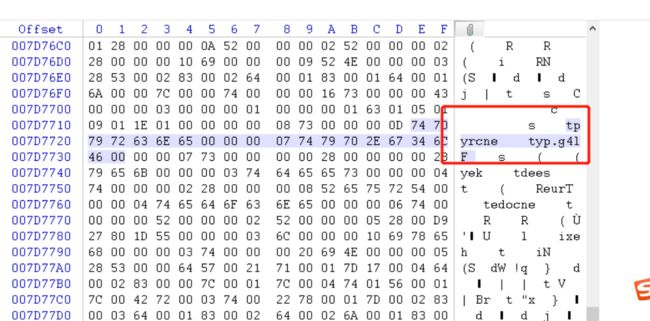
f = open('Py.py','wb')
with open('PyHaHa.pyc','rb') as g:
f.write(g.read()[::-1])
f.close()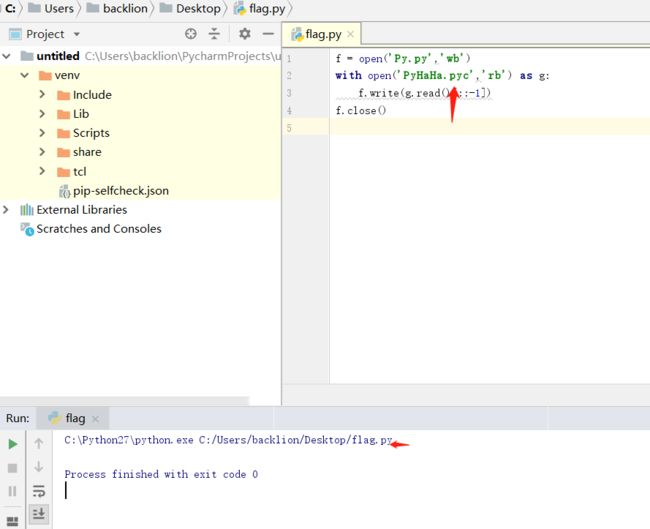


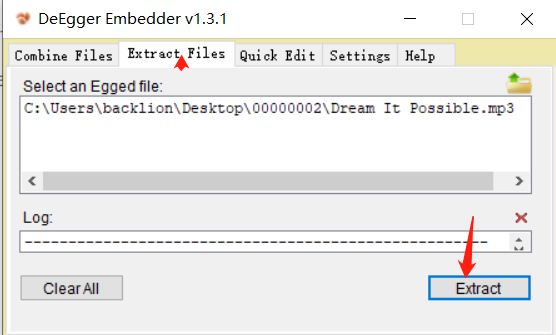

图片:
![]()
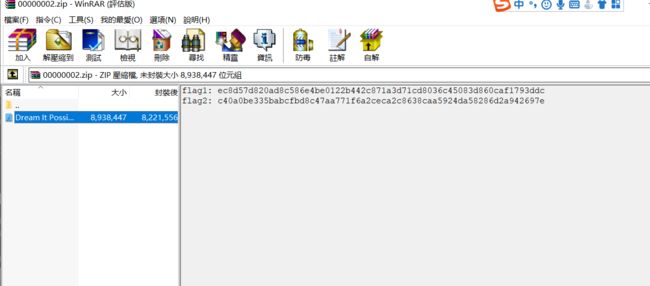
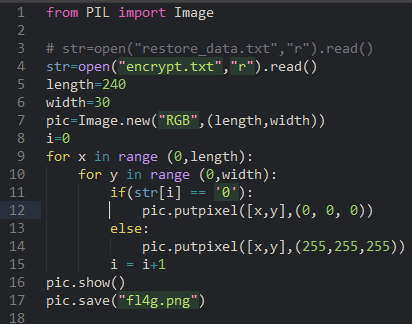
12.对py.pyc进行分析,发现.pyc的文件头03F30D0A缺少,以及该文件中添加隐藏了一个zip文件。这里通过winhex打开我们解压得到对00000000002.zip文件分析,发现是PK字符串开头(50 4B 0304)
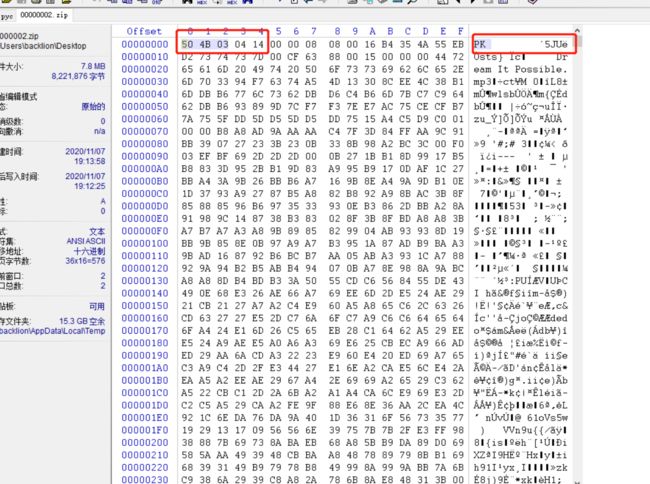

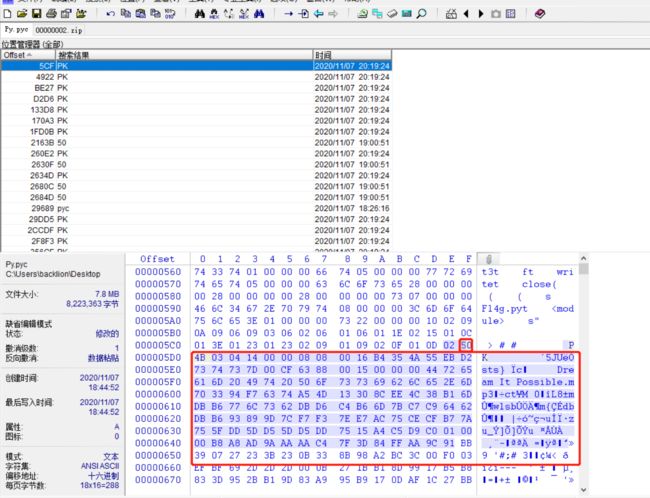
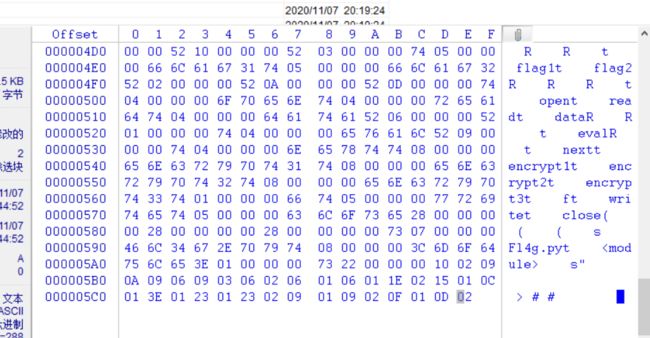
15.然后另存为flag.pyc.通过在线反编译可发编译出源代码出来:
https://tool.lu/pyc/
#!/usr/bin/env python
# visit http://tool.lu/pyc/ for more information
from os import urandom
def generate(m, k):
result = 0
for i in bin(m ^ k)[2:]:
result = result << 1
if int(i):
result = result ^ m ^ k
if result >> 256:
result = result ^ P
continue
return result
def encrypt(seed):
key = int(urandom(32).encode('hex'), 16)
while True:
yield key
key = generate(key, seed) + 0x3653C01D55L
def convert(string):
return int(string.encode('hex'), 16)
P = 0x10000000000000000000000000000000000000000000000000000000000000425L
flag1 = 'ThIs_Fl4g_Is_Ri9ht'
flag2 = 'Hey_Fl4g_Is_Not_HeRe'
key = int(urandom(32).encode('hex'), 16)
data = open('data.txt', 'r').read()
result = encrypt(key)
encrypt1 = bin(int(data, 2) ^ eval('0x' + hex(result.next())[2:-1] * 22))[2:]
encrypt2 = hex(convert(flag1) ^ result.next())[2:-1]
encrypt3 = hex(convert(flag2) ^ result.next())[2:-1]
print 'flag1:', encrypt2
print 'flag2:', encrypt3
f = open('encrypt.txt', 'w')
f.write(encrypt1)
f.close()
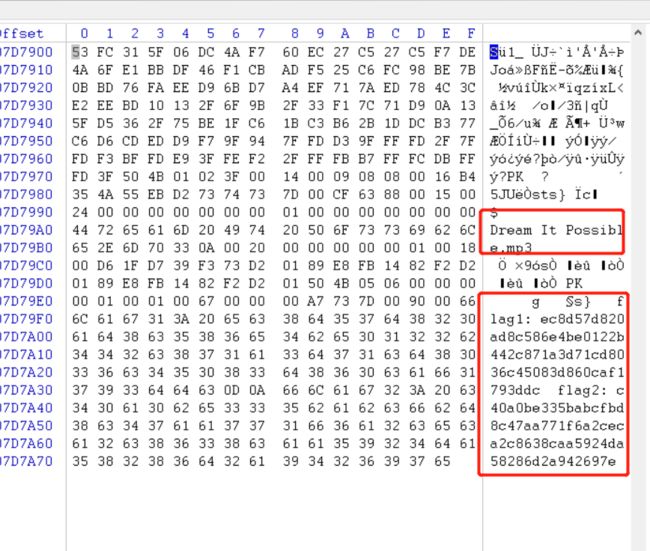
16.分析脚本发现flag1和flag2的密文在前面的zip注释信息已给出,脚本对三段明文使用了同个Seed做了加密,其中后两段明文和密文还有第一段的密文已知,考虑OTP加密。
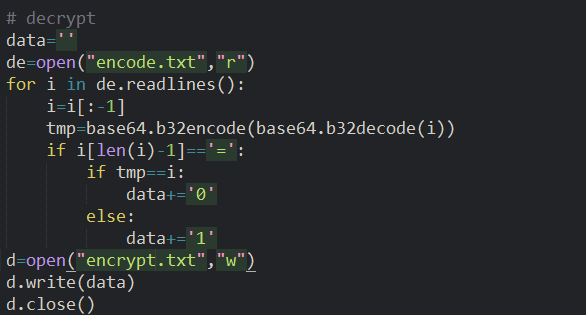
其中encrypt实现的是一个256bit随机数生成器的功能,generate实现的是在有限域GF(2^256)下的平方运算:new_key=(old_key+seed)^2
因此,先由后两段明文和密文算出key2和key3,再在GF(2^256)下进行开方即可得到seed,key3 = (key2+seed)^2
再由第一段密文(即base32隐藏的数据)key1和seed解得key1
Key2= (key1+seed)^2
17.最后写脚本通过上面的加密过程写出解码脚本如下:(最后对第一段密文(即base32隐藏的数据)和22次叠加的key1做异或得到原始二进制数据)

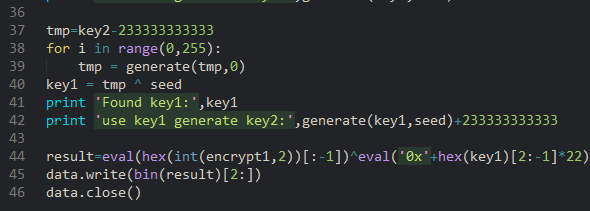
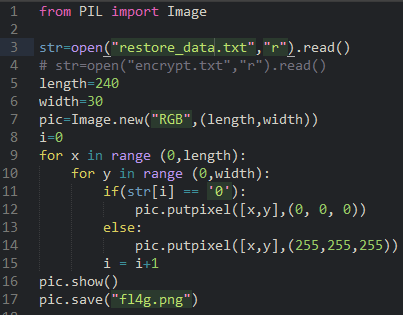
六十一、虚拟vmem磁盘文件隐写
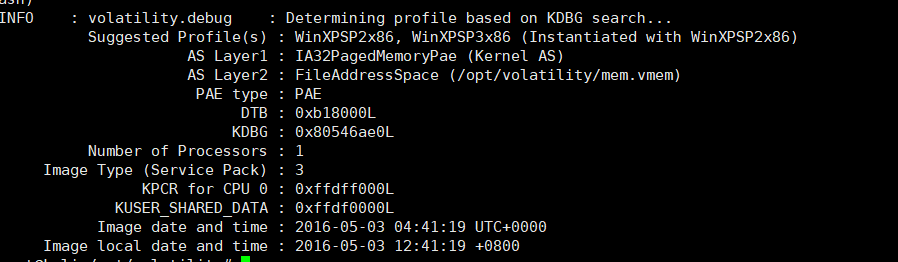
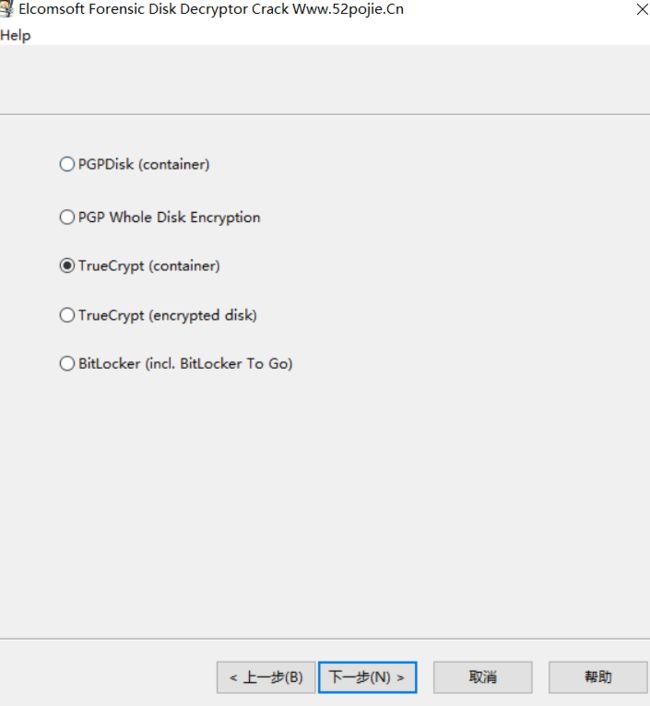
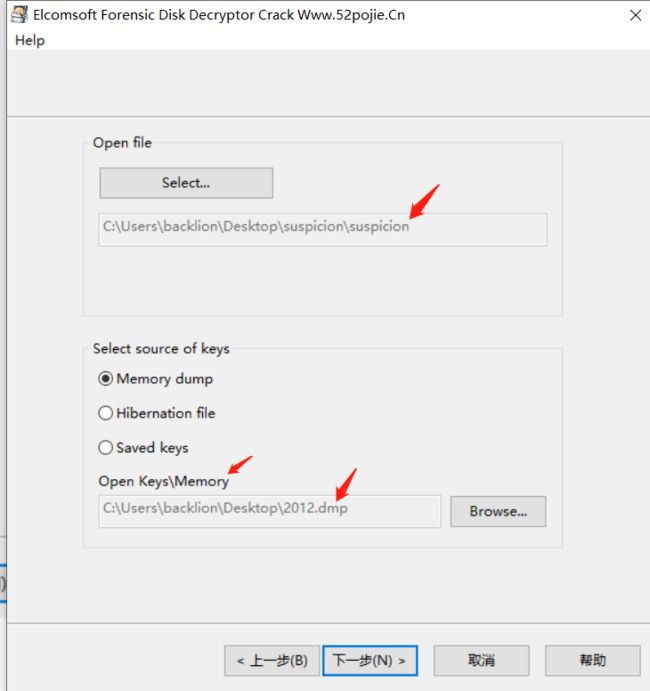
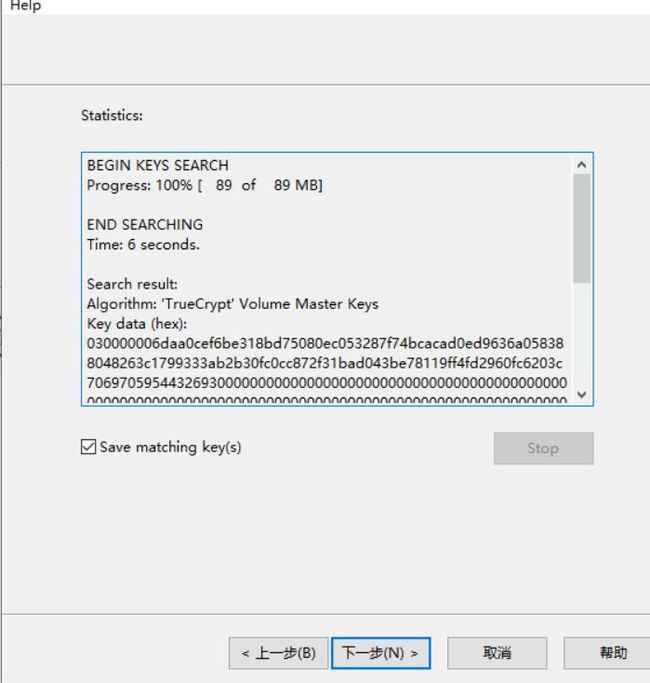
1.使用volatility imageinfo -f mem.vmem查看内存映像
python vol.py imageinfo -f mem.vmem


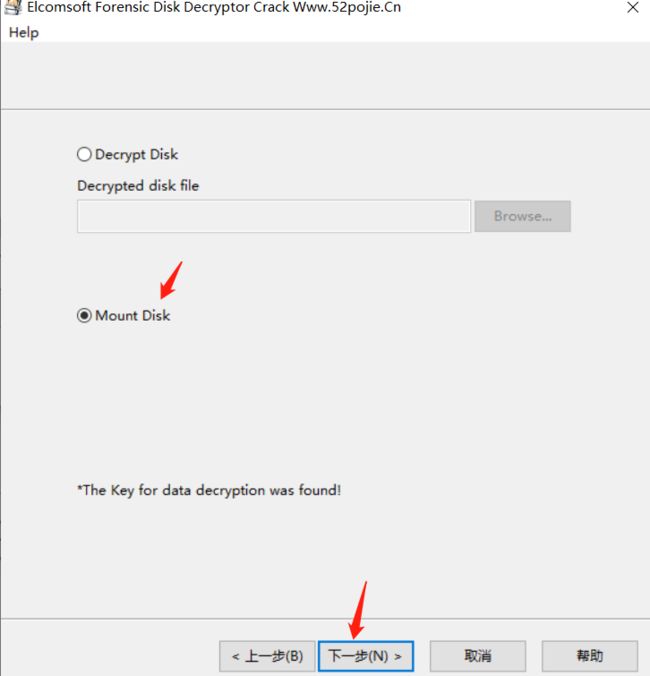

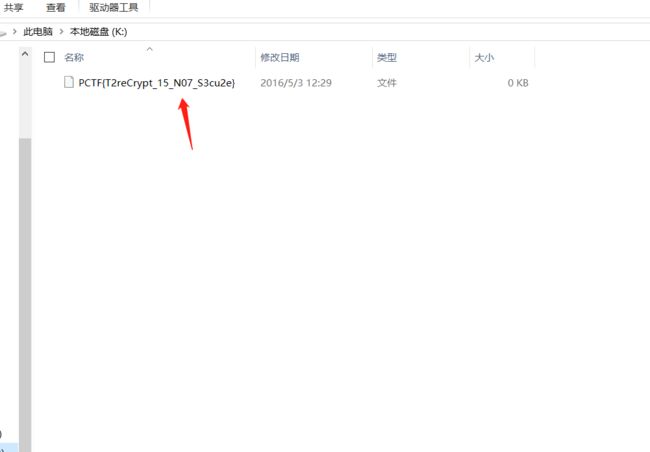
六十二、维吉尼亚密码
提交:flag格式:flag{} 基础知识:
维吉尼亚密码是在凯撒密码基础上产生的一种加密方法,它将凯撒密码的全部25种位移排序为一张表,与原字母序列共同组成26行及26列的字母表。另外,维吉尼亚密码必须有一个密钥,这个密钥由字母组成,最少一个,最多可与明文字母数量相等。维吉尼亚密码加密方法示例如下:
明文:I've got it.
密钥:ok
密文:W'fs qcd wd.
首先,密钥长度需要与明文长度相同,如果少于明文长度,则重复拼接直到相同。本例中,明文长度为8个字母(非字母均被忽略),密钥会被程序补全为“okokokok”。现在根据如下维吉尼亚密码表格进行加密:

明文第一个字母是“I”,密钥第一个字母是“o”,在表格中找到“I”列与“o”行相交点,字母“W”就是密文第一个字母;同理,“v”列与“k”行交点字母是“F”;“e”列与“o”行交点字母是“S”……
在维吉尼亚密码中,发件人和收件人必须使用同一个关键词(或同一段字母),这个关键词告诉他们怎么样才能前后改变字母的位置来获得该段信息中的每个字母的正确对应位置。比如:如果关键字为“BIG”,发件人将把明文中的第一个字母按“B”行来加密(向后移动1个位置,因为B是排在A后面的第1个字母),明文中的第二个字母按“I”行来加密(向后移动8个位置,因为I是排在A后面的第8个字母),明文中的第三个字母按“G”行加密(向后移动6个位置,因为G是排在A后面的第6个位置),后面再循环操作即可完成加密任务。
例如:
明文:THE BUTCHER THE BAKER AND THE CANDLESTICK MAKER。
密钥:BIG
密文:UPK CCZDPKS BNF JGLMX BVJ UPK DITETKTBODS SBSKS
- 维吉尼亚密码只对字母进行加密,不区分大小写,若文本中出现非字母字符会原样保留。
- 如果输入多行文本,每行是单独加密的。
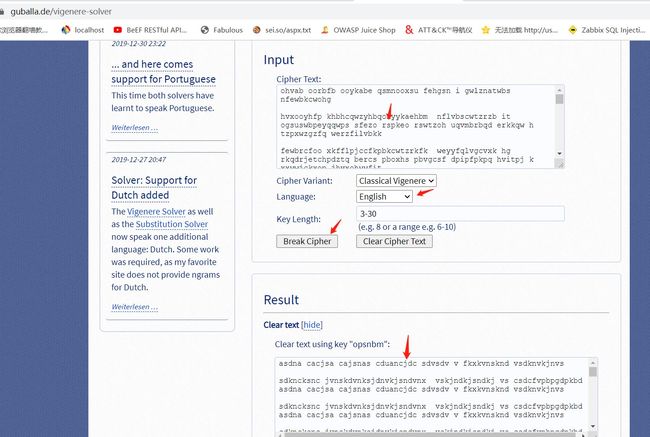
发现有重复的字母映射,猜测为维吉尼亚密码加密

由密文-->明文:(列为明文,行为密钥,交叉点为密文)
xybsxaxy -->flagjlfl
x-->f,推出第一个密钥为s
y-->l,推出第二个密钥为n
b-->a,推出第三个密钥为b
s-->g,推出第四个密钥为m
x-->j,推出第五个密钥为o
a-->l,推出第六个密钥为p
x-->f,推出密钥为s
y-->l,推出密钥为n
第7位后,密钥开始循环,所以
推出密钥:snbmop
4.根据在线工具可以获得xybs:xaxybs{W_Zf0j_o0fvxft}的明文:
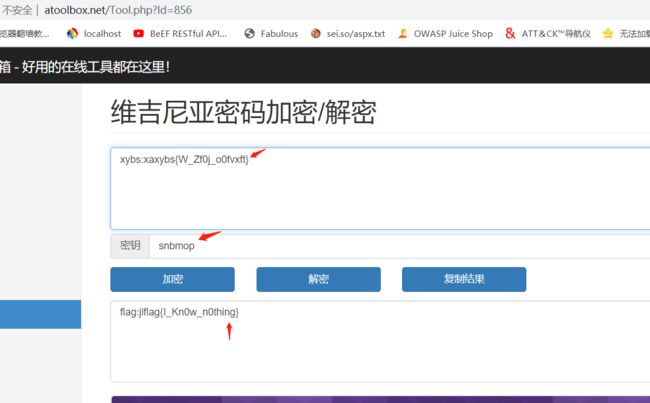
flag{I_Kn0w_n0thing}
六十三、二维码修复
1.看到二维码,第一件事就是先扫一下。发现扫不了,那么就肯定是码有问题了。
左下角的小狗挡住了呢,通过ps修复工具对其进行修复。(修复了定位点)
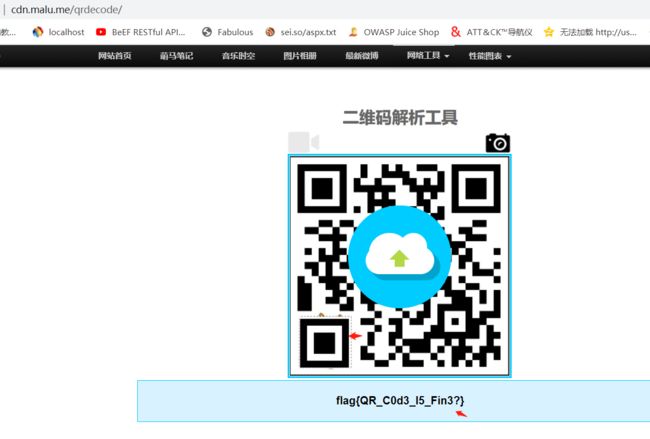
2.然后保存,通过现在QR识别工具即可识别出二维码
http://cdn.malu.me/qrdecode/
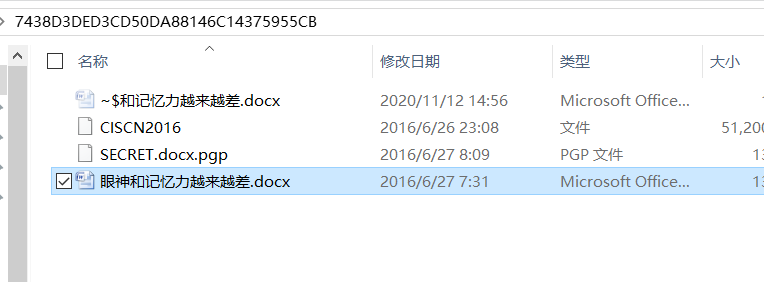
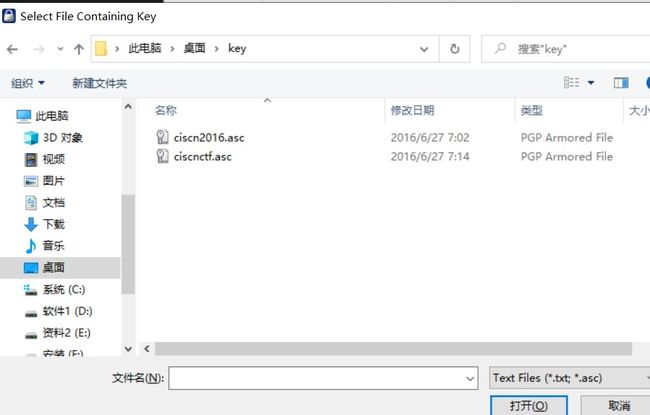
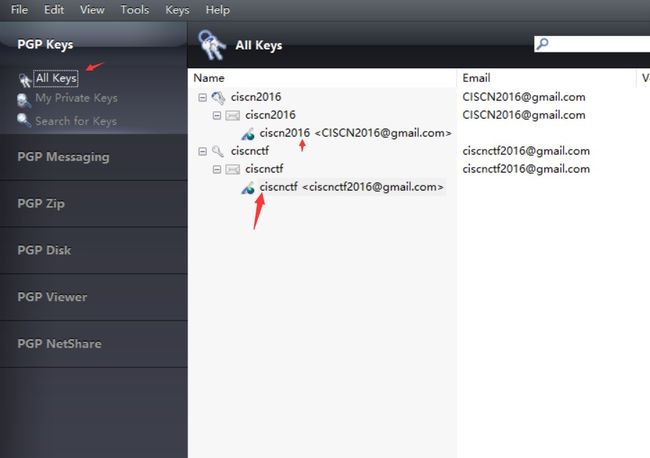
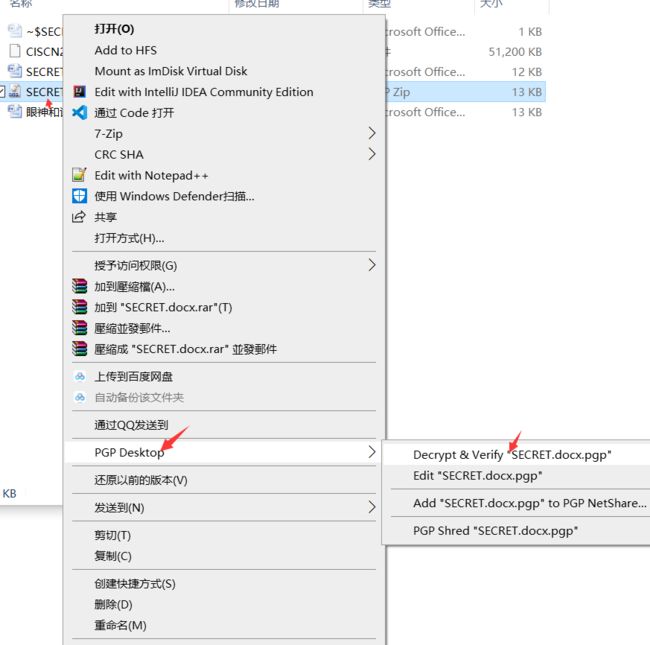
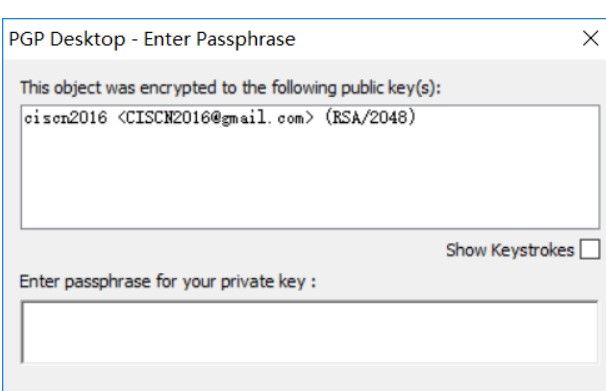
六十四、word隐写之pgp解密
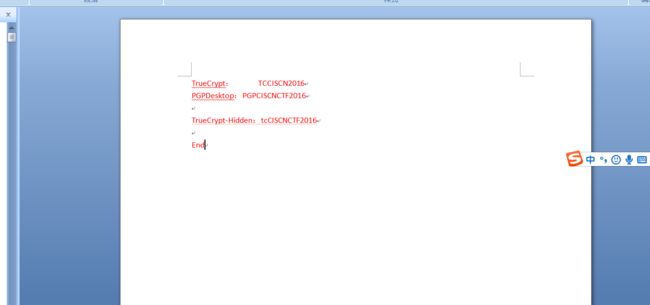
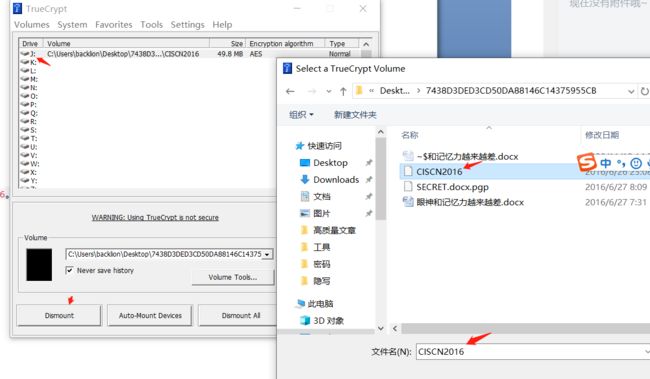
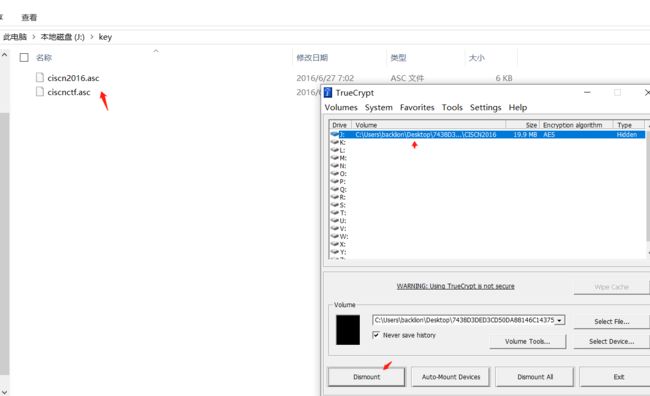
5.使用第二个密钥tcCISCNCTF2016重新挂载,发现了PGP的私钥:

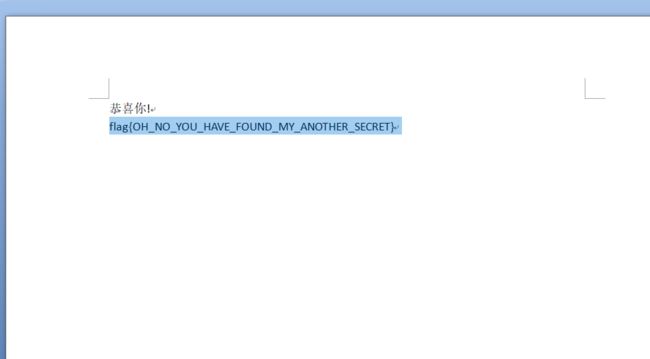
六十五、PNG图片隐写二


六十六、vmdk虚拟磁盘之mp3文件隐写多次编码解码
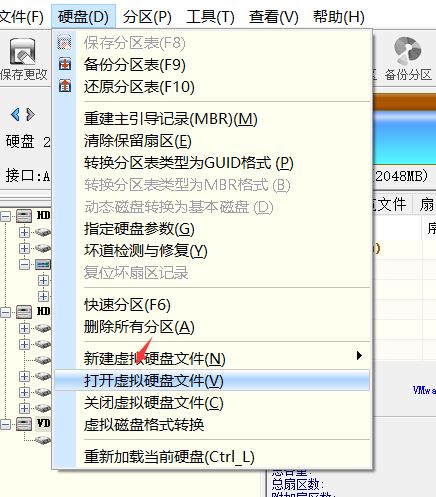
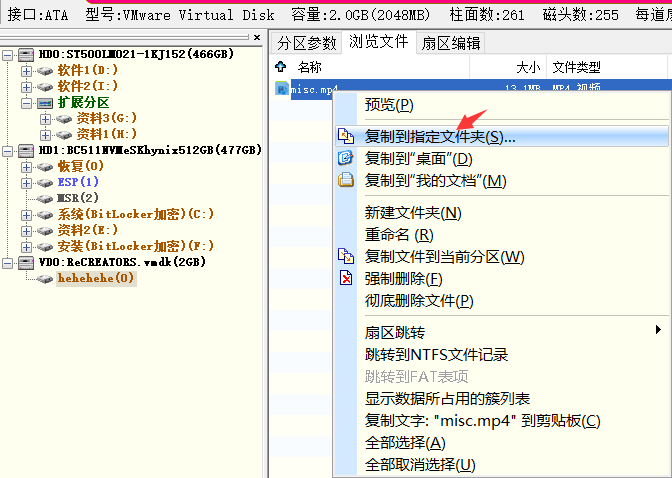

6.打开这个文件的文档,发现一段可疑的数据,分别复制出来


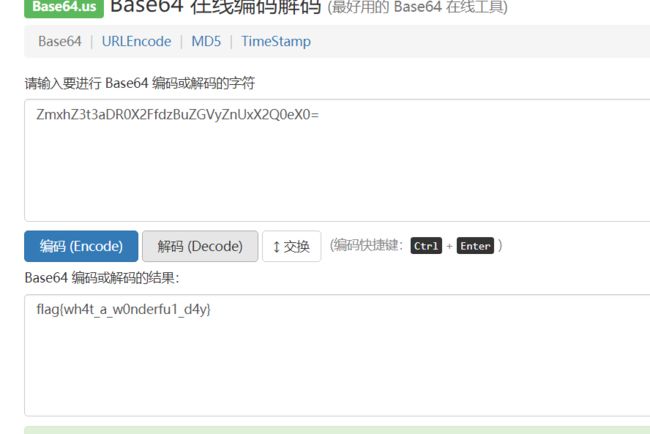
六十七、曼彻斯特编码
题目内容:
5555555595555A65556AA696AA6666666955,提示:曼联
基础知识:
在最初信号的时候,即第一个信号时:如果中间位电平从低到高,则表示0;如果中间位电平从高到低,则表示1。
后面的信号(从第二个开始)就看每个信号位开始时有没有跳变来决定:在信号位开始时改变信号极性,表示逻辑"0";在信号位开始时不改变信号极性,表示辑"1"。

writeup:
1.根据题目提示曼联,可猜测是曼彻斯特编码
2.通过python脚本进行解密:
#!/user/bin/env python2# -*-coding:utf-8 -*-n=0x5555555595555A65556AA696AA6666666955flag=''bs='0'+bin(n)[2:]r=''def conv(s): return hex(int(s,2))[2:]for i in range(0,len(bs),2): if bs[i:i+2]=='01': r+='1' else: r+='0'for i in range(0,len(r),8): tmp=r[i:i+8][::-1] flag+=conv(tmp[:4]) flag+=conv(tmp[4:])print flag.upper()
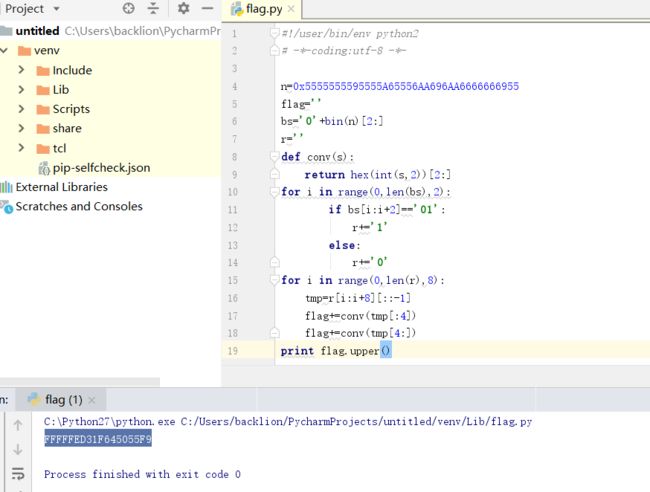
六十八、pyo文件反编译之反推flag字符
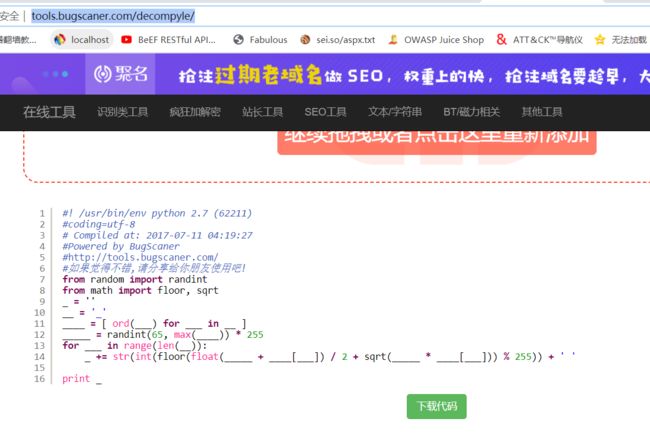
#! /usr/bin/env python 2.7 (62211)
#coding=utf-8
from random import randint
from math import floor, sqrt
passwd = ''
flag= '_'
ordflag = [ ord(i) for i in flag ] #ordflag是flag中字符对应的ascii码
randI = randint(65, max(ordflag)) * 255 #randI是区间[65,flag中字符最大ascii码)内产生的随机数*255
for i in range(len(flag)): #循环次数为flag中字符个数
passwd += str(int(floor(float(randI + ordflag[i]) / 2 + sqrt(randI * ordflag[i])) % 255)) + ' '
print passwd #串用空格分隔的数字5.代码分析:(1)获取flag字符串的ascii值
(2)在下限为65上线为flag的ascii码最大值之间取随机数,乘上255
(3)循环flag字符串,经过这个加减乘除开方的混合计算
(4)输出结果
那么flag.enc里面的数字就是最后输出的结果,需要反推flag字符
python代码输出格式是一串用空格分隔的数字。得到的这一串数字应该是用flag输出的。那么flag应该是19位(数字串中19个数字)。
因为变量falg是代表flag,那么flag中字符一定是字母大小写、0~9、{} 这些字符组成的。
那么ordflag中ascii码最大是125(flag中的‘}’字符),就让randI从65到125遍历一遍。
最后得到的19个数字,每个数字对应一个字符,就把每个字符对应的数字都获取到,然后再跟正确的19个数字进行比对查看是哪19个字符。
核心思想是65-127的acil码的范围内,for每一个字符,每个字符都做 tmpInt = int(floor(float(k + ANSInum[i]) / 2 + sqrt(k * ANSInum[i])) % 255)处理,处理出来与flag的数字逐一比较,并且以字典的方式保存取值,最终就可推出flag的每个字符
6.把另一个文件flag.enc文件用notepad打开:
208 140 149 236 189 77 193 104 202 184 97 236 148 202 244 199 77 122 113
7.根据以上脚本写出解密flag,如下:
from random import randint
from math import floor, sqrt
ANSInum = [i for i in range(33, 127)]
flagEnc = [208, 140, 149, 236, 189, 77, 193, 104, 202, 184, 97, 236, 148, 202, 244, 199, 77, 122, 113]
for k in range(65 * 255, 127 * 255, 255):
tmpDict = {}
for i in range(len(ANSInum)):
tmpInt = int(floor(float(k + ANSInum[i]) / 2 + sqrt(k * ANSInum[i])) % 255)
tmpDict[tmpInt] = chr(ANSInum[i])
try:
flag = ''.join([tmpDict[i] for i in flagEnc])
print 'flag{' + flag + '}'
except:
pass
 8.最终得到flag:
flag{ThisRandomIsNotSafe}
8.最终得到flag:
flag{ThisRandomIsNotSafe}
六十九、流量文件隐写之zip加密分析
writeup:
1.下载附件,然后解压,发现有一个流量包
2.通过wireshark打开流量包后,按照协议进行分类,发现了存在以下几种协议类型:
ARP / DNS / FTP / FTP-DATA / ICMP / ICMPv6 / IGMPv3 / LLMNR / NBNS / SSDP / SSL / TCP / TLSv1.2 / UDP
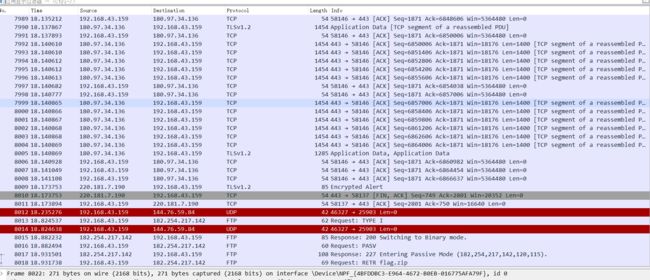
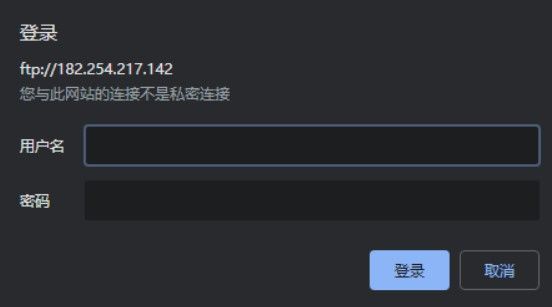
3.按照协议类型诸葛数据包进行读取,发现只有FTP协议是由用的,但是同时注意到TLS协议是进行加密的,其他的协议并没有什么作用。然后使用wireshark的过滤器将FTP和FTP-DATA筛选出来。发现了ftp的用户名和密码,尝试登陆,发现不能登录
服务器地址:182.254.217.142
用户名:ftp
密码:codingay

4.统计有哪些协议可用,这里主要是ftp-data

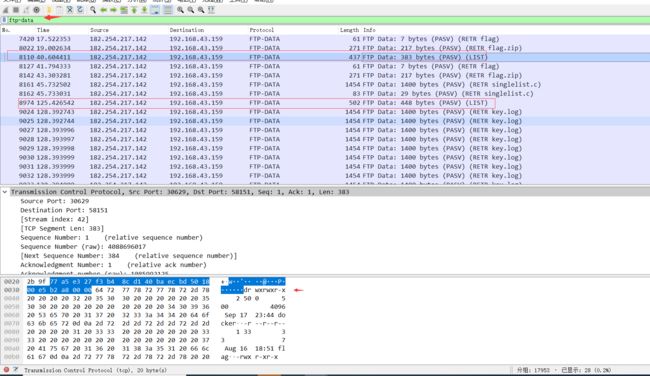
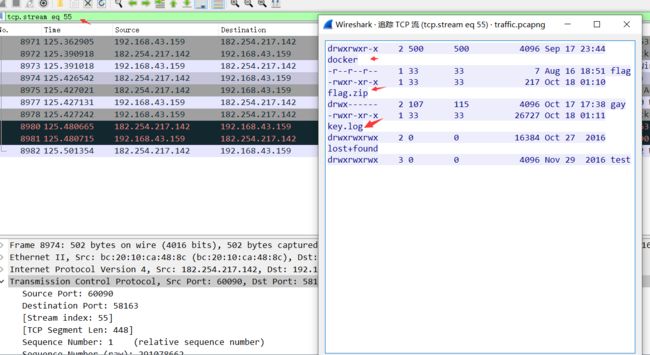
5.但是通过分析数据包我发现了一些有价值的东西,发现了ftp的目录结构,追踪一下TCP流,查看目录结构。
目录包含了,flag.zip和key.log
6.先过滤"ftp-data",然后ctrl+F 查找【字符串】关键字为flag,其中分组详情只是在info标题里搜索关键词,分组字节流在详细内容中搜索关键字
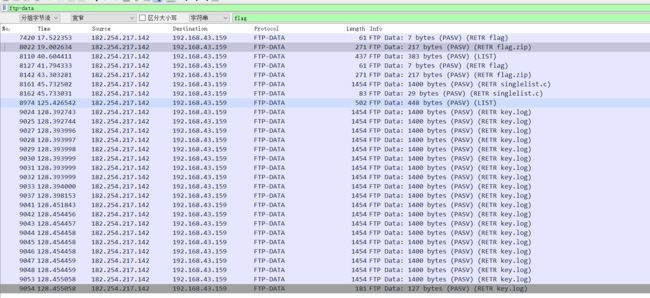 7.可搜索8022,flag.zip的压缩包中包含了flag.txt
7.可搜索8022,flag.zip的压缩包中包含了flag.txt
 8.通过追踪tcp流导出以原始数据流保存为8022.zip文件
8.通过追踪tcp流导出以原始数据流保存为8022.zip文件
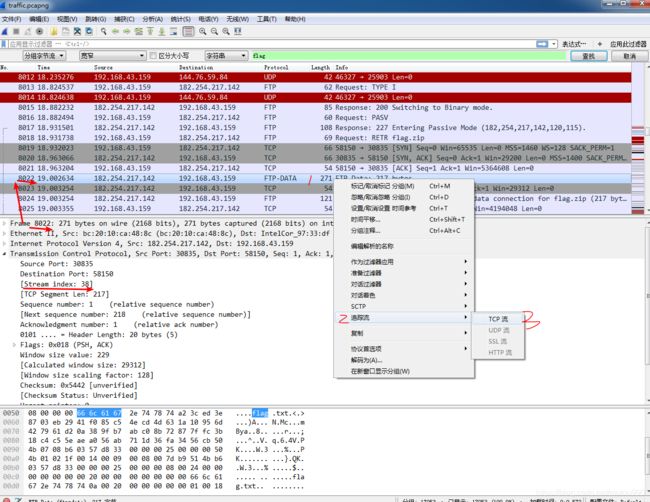
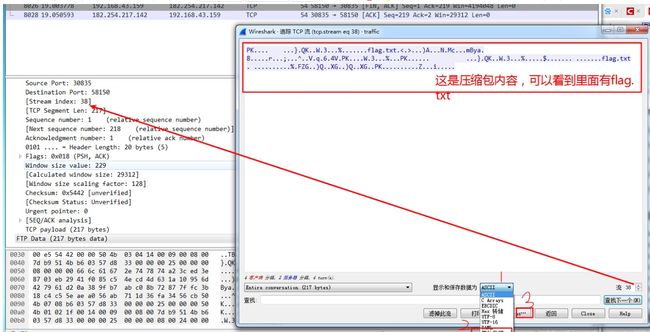
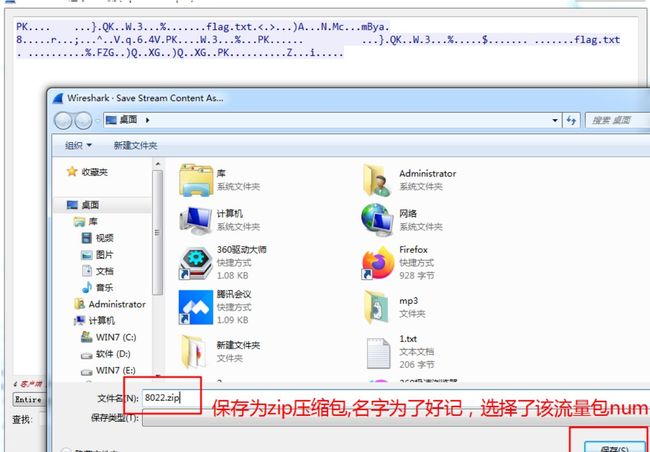
 9.同理,也可以搜索8142,然后
通过追踪tcp流导出以原始数据流保存为8142.zip文件
9.同理,也可以搜索8142,然后
通过追踪tcp流导出以原始数据流保存为8142.zip文件
 10.怀疑这2个压缩文件是伪加密,这里我们都使用伪解密工具进行解密,其中8142.zip的伪解密出来的明文不是真正的flag
10.怀疑这2个压缩文件是伪加密,这里我们都使用伪解密工具进行解密,其中8142.zip的伪解密出来的明文不是真正的flag
 11.而8022.zip解压出错,说明它才是真正需要解密的压缩包(推测)
11.而8022.zip解压出错,说明它才是真正需要解密的压缩包(推测)
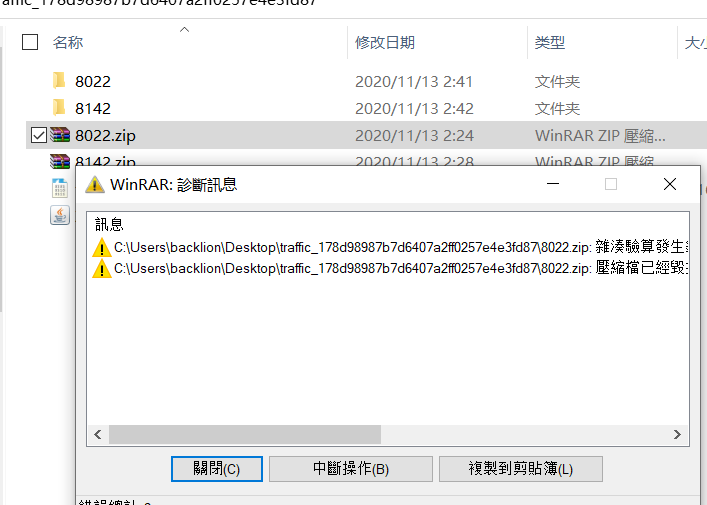
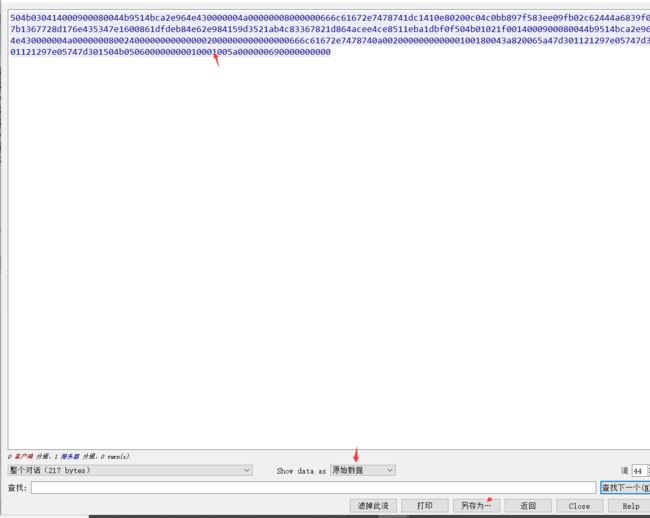
12.加密的数据包?那就应该是TLS协议没跑了,又想到key.log这个文件还没有用,然后使用key.log对TLS协议进行解密,下面提取key.log文件
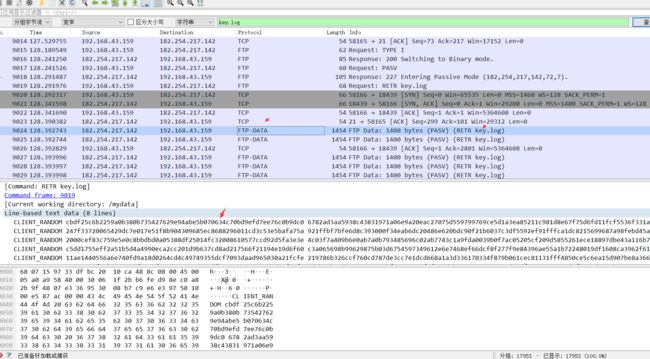
发现里面的是一份 NSS Key Log Format 的文件,而这个文件是能解密出 Wireshark 里面的 https 流量的,也就是key.log
 13.追踪tcp流,然后以ascii格式保存为key.log
13.追踪tcp流,然后以ascii格式保存为key.log
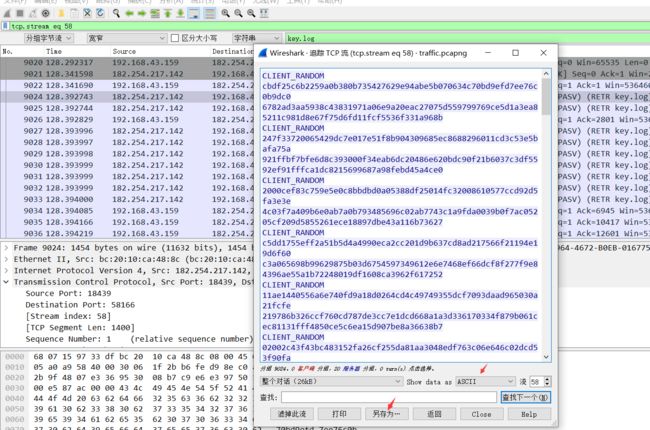
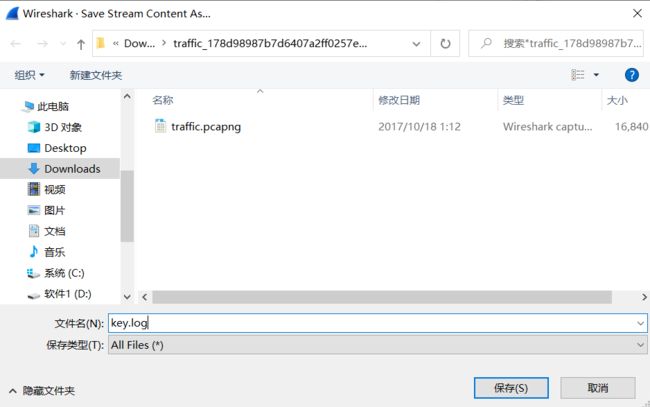
14.现在使用key.log对TLS协议进行解密。(操作步骤:编辑→首选项→Protocols→TLS,然后在下面导入key.log文件)
 15.然后回到数据包刷新一下就可以看到揭秘之后的数据了。因为TLS加密的是http协议,所以解密之后直接过滤http协议就可以了。
15.然后回到数据包刷新一下就可以看到揭秘之后的数据了。因为TLS加密的是http协议,所以解密之后直接过滤http协议就可以了。
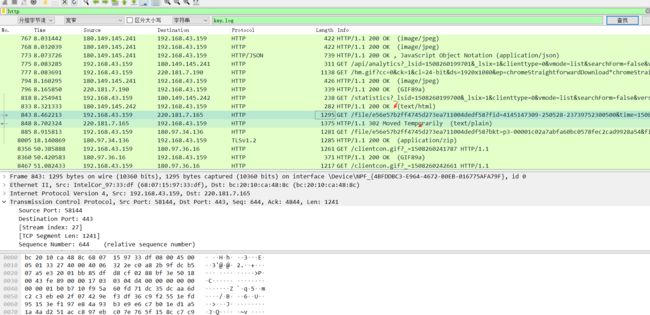
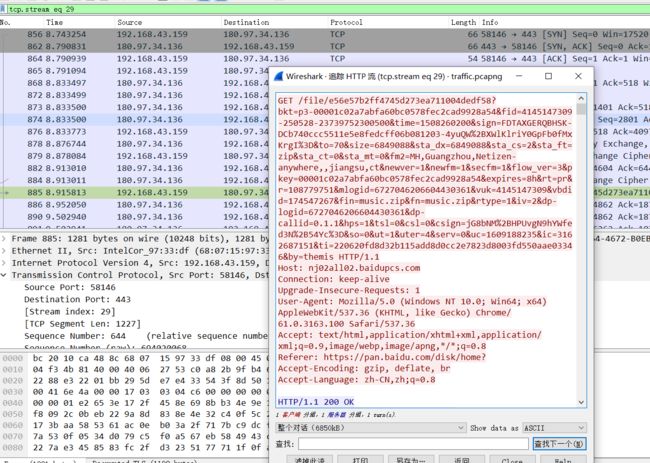 16.查看后可以大致分析出,是用百度网盘下了一个文件,把这个文件导出。(文件→导出对象→HTTP)
16.查看后可以大致分析出,是用百度网盘下了一个文件,把这个文件导出。(文件→导出对象→HTTP)

 17.切换到频谱图分析
17.切换到频谱图分析
 18.视图--放大查看
18.视图--放大查看
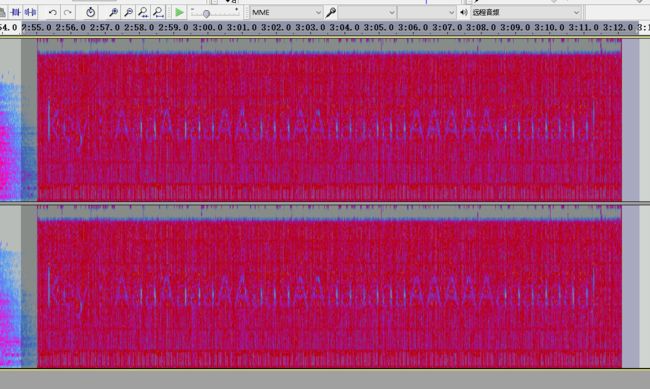 19.隐约能看到写着
19.隐约能看到写着
Key:AaaAaaaAAaaaAAaaaaaaAAAAAaaaaaaa!
20.回到一开始解不开的 zip 文件,使用 AaaAaaaAAaaaAAaaaaaaAAAAAaaaaaaa! 作为密码,成功解出来了 flag.txt
 21.最终得到flag:
flag{4sun0_y0zora_sh0ka1h@n__#>>_<<#}
21.最终得到flag:
flag{4sun0_y0zora_sh0ka1h@n__#>>_<<#}
七十、py脚本之zip伪加密解密出RSA破解
writeup:
1.点击Download下载了一个压缩包,解压后有两个文件,crypto.zip和jiami.py
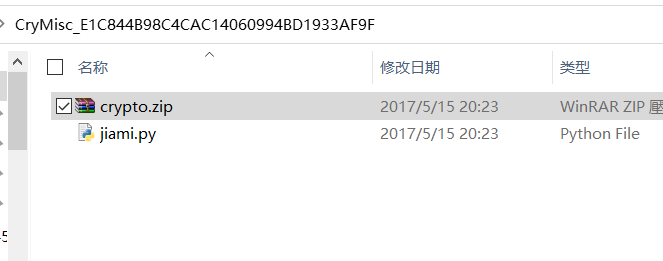
2.打开jiami.py文件内容如下:
# -*- coding:utf8 -*-
import pyminizip
from hashlib import md5
import os
def create(files, zfile):
password = os.urandom(15)#随机产生一个15字节的字符串
password = md5(password).hexdigest()#获取这个字符串的md5值
pyminizip.compress_multiple(files, zfile, password, 0)#这是一个压缩文件的方法把files参数中文件压缩成zfile指定的文件,压缩密码是password,0可以理解为复杂程度值为1~9,默认是0
pass
if __name__ == '__main__':
files = ['jiami.py','gogogo.zip']
zfile = 'crypto.zip'#就是把jiami.py和gogogo.zip两个文件压缩成crypto.zip密码是上面随机字符串的md5值
create(files, zfile)
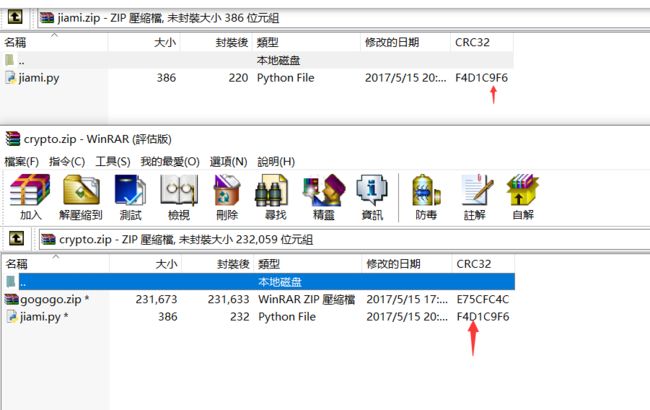
3.接下来打开crypto.zip提示有密码,也就是上述md5值,这个密码我们是不知道的。因为crypto.zip压缩包中有jiami.py文件,而jiami.py这个文件是已知的,因此我们可以用zip明文进行攻击。
明文攻击需要利用两个压缩包(已知文件的压缩包,和加密的需要破解的压缩包),这两个压缩包压缩方式要相同,直接对jiami.py文件进行压缩是不行的,也要用python 的pyminizip模块进行压缩,脚本如下:
# -*- coding: cp936 -*-
import pyminizip
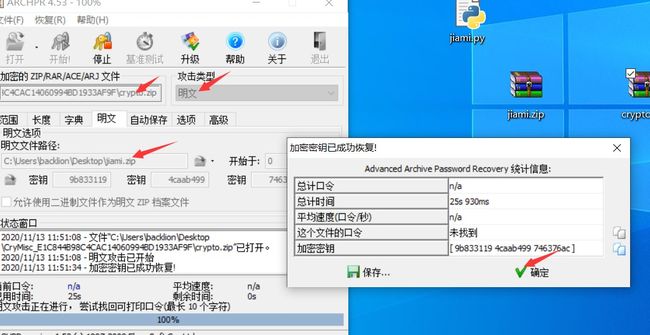
pyminizip.compress(r"jiami.py","",r"jiami.zip","",0)#没有密码

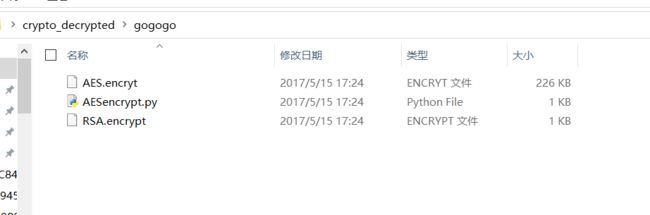
4.然后进行明文攻击,利用Advanced Archive Password Recovery 4.53 进行利用,这里的crc32相同。
5.爆破成功保存为压缩包UnEncrypted.zip解压后得到gogogo.zip,解压得到AES.encryt、AESencrypt.py和RSA.encrypt三个文件
6.打开AESencrypt.py文件如下:
# -*- coding:utf8 -*-
from Crypto.Cipher import AES
s=open('next.zip','rb').read()
BS=16
pad_len=BS-len(s)%BS
padding=chr(pad_len)*pad_len
s+=padding#把最后不满16个字节的用所缺字节个数值ASCII码对应的字符补足16个字节,如缺5个字节就补5个ascii码为5的字符,因为AES明文是128bit的倍数
key='我后来忘了'#AES秘钥(未知)
n=0x48D6B5DAB6617F21B39AB2F7B14969A7337247CABB417B900AE1D986DB47D971#两个大素数p与q乘积
e=0x10001#RSA公钥65537
m=long(key.encode('hex'),16)#秘钥key转16进制转整型,作为RSA的明文
c=pow(m,e,n)#c是RSA加密后的密文
c='0{:x}'.format(c).decode('hex')
with open('RSA.encrypt','wb') as f:
f.write(c)
#RSA.encrypt文件的16进制就是RSA的密文,即就是AES秘钥key加密后的密文,已知
obj=AES.new(key,AES.MODE_ECB)
with open('AES.encryt','wb') as f:
f.write(obj.encrypt(s))#对next.zip进行AES加密,秘钥为key,AES.encryt文件中的内容即为AES加密后的密文已知。
7.整合已有信息就是,已知AES加密后的密文要解出AES的明文;但是AES秘钥不知道,要先求出AES秘钥key
key就是RSA的明文,已知RSA的密文c,两个大素数乘积n也已知可以求出p,q,然后求出RSA私钥,然后根据私钥,密文,n可以求出RSA明文(就是AES的秘钥key),然后根据AES密文和秘钥key就能解除AES的明文。
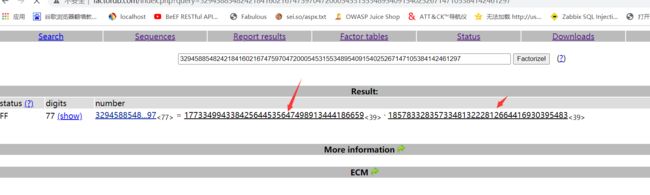
首先十六进的n转成10进制为:32945885482421841602167475970472000545315534895409154025267147105384142461297
https://tool.lu/hexconvert/

8.登录网站http://factordb.com/,对n进行因数分解,解出p和q
 都转换成十进制,进行计算
都转换成十进制,进行计算
p=177334994338425644535647498913444186659
q=185783328357334813222812664416930395483
n=32945885482421841602167475970472000545315534895409154025267147105384142461297
e=65537
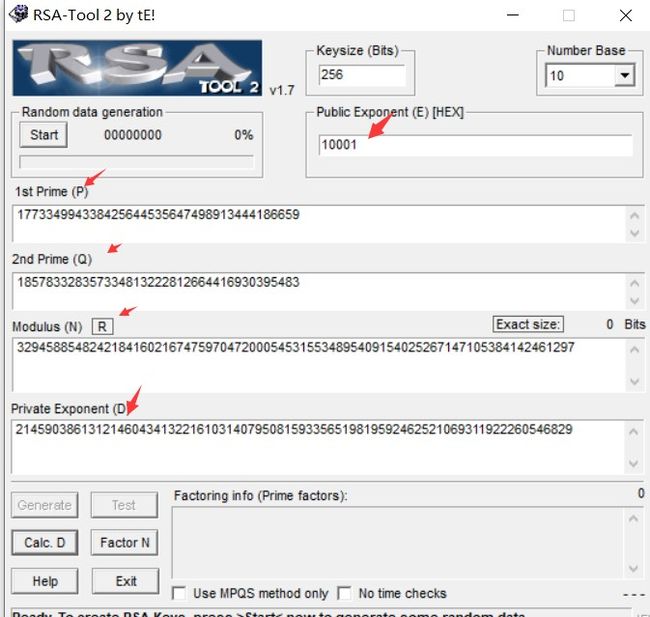
9.通过RSA-Tool2解出d = 21459038613121460434132216103140795081593356519819592462521069311922260546829
10.通过脚本先打开读取RSA.encrypt文件,并转换成16进制,然后通过RAS的公钥和私钥,解密出RSA的密钥,也就是AES.encryt的key,AES秘钥key加密后的密文就是RSA密文,通过AES.encryt的key值解密出next.zip文件
脚本如下:
# -*- coding: cp936 -*-
from Crypto.PublicKey import RSA
from Crypto.Cipher import AES
def egcd(a,b):
if a==0:
return (b,0,1)
else:
g,y,x=egcd(b%a,a)
return (g,x-(b//a)*y,y)
def modinv(a,m):
g,x,y=egcd(a,m)
if g!=1:
raise Exception('modular inverse does not exist')
else:
return x%m
p=177334994338425644535647498913444186659
q=185783328357334813222812664416930395483
n=32945885482421841602167475970472000545315534895409154025267147105384142461297
e=65537#公钥
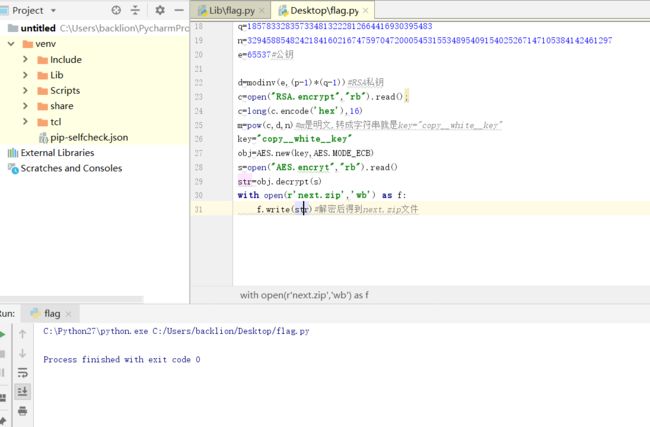
d=modinv(e,(p-1)*(q-1))#RSA私钥
c=open("RSA.encrypt","rb").read();
c=long(c.encode('hex'),16)
m=pow(c,d,n)#m是明文,转成字符串就是key="copy__white__key"
key="copy__white__key"
obj=AES.new(key,AES.MODE_ECB)
s=open("AES.encryt","rb").read()
str=obj.decrypt(s)
with open(r'next.zip','wb') as f:
f.write(str)#解密后得到next.zip文件
11.解压next.zip文件得到encrypt.py、first、second三个文件。
12.打开encrypt.py内容:
# -*- coding:utf8 -*-
from base64 import *
s=open('flag.jpg','rb').read()
s='-'.join(map(b16encode,list(s)))
#list(s)每个字节(一个字符)作为列表的一项
#map(b16encode,list(s)),列表的每一项都执行b16encode(这个函数其实是得到字符对应的十六进制值),并将结果作为新列表中的项
#'-'.join(),列表中的每项都用‘-’分隔。
#最终的执行结果是flag.jpg文件的用‘-’分隔字节的十六进制数据
s=map(''.join,zip(*(s.split('-'))))
#zip(*(s.split('-')))得到两个元组,一个是每个字节的第一个16进制值组成的,一个是每个字节的第二个16进制值组成的
#然后作为一个新列表
with open('first','wb') as f:
f.write(b16decode(s[0]))#把第一个列表元素转成字符串写入first文件
with open('second','wb') as f:
f.write(b16decode(s[1]))#把第二个列表元素转成字符串写入second文件
13.通过代码分析完也就是把flag.jpg文件的16进制值分成了两部分,每个字节的前4位组合成first文件,后4位组合成second文件。通过脚本合并生成flag.jpg:
# -*- coding: cp936 -*-
from base64 import *
s1=open(r'first','rb').read()
s2=open(r'second','rb').read()
s1=''.join(map(b16encode,list(s1)))#获取16进制数据
s2=''.join(map(b16encode,list(s2)))
str=""
for i in range(0,len(s1)):
str+=s1[i]+s2[i];#得到flag.jpg16进制数据
str=str.decode('hex')
with open(r'flag.jpg','wb') as f:
f.write(str)
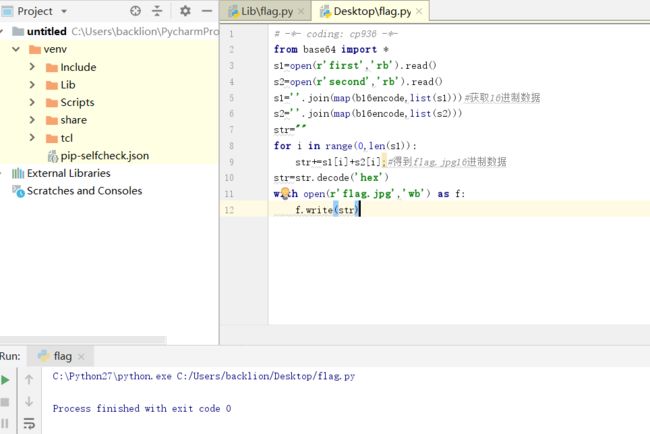
14.得到flag.jpg图片
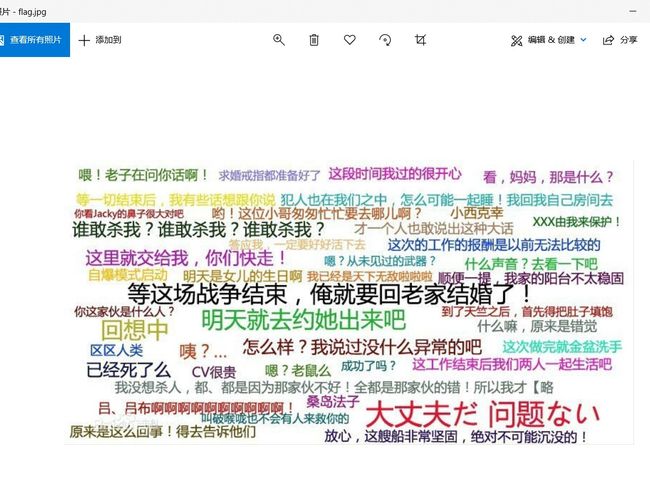
15.打开图片没有flag信息,用winhex(或010 Editor)打开查看16进制数据,在图片结尾(FFD9)后面还有内容

16.16进制头为38 42 50 53(Adobe Photoshop (psd),文件头:38 42 50 53),根据文件头可以知道这是psd(Photoshop Document)文件(原理是用copy命令把jpg文件和psd文件合并在一起)
先选择块起始,然后再选择块结束,全部复制出来

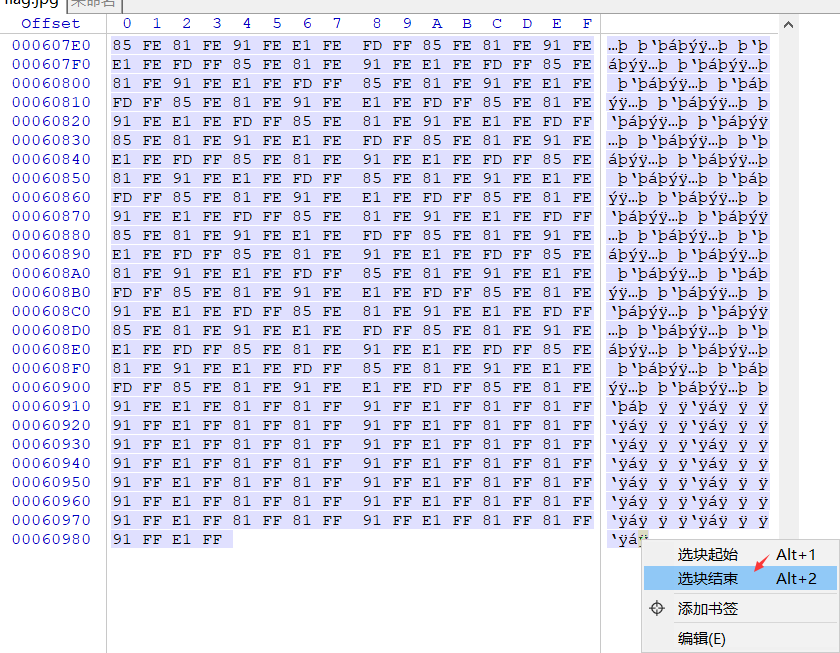 17.然后再新建一个文件,复制到里面
17.然后再新建一个文件,复制到里面
 18.最后另存为flag.psd,并
用photoshop打开flag.psd文件,打开后图片上有一行字flag{少年,我看好你!},我以为这是flag,提交好几遍都错误
18.最后另存为flag.psd,并
用photoshop打开flag.psd文件,打开后图片上有一行字flag{少年,我看好你!},我以为这是flag,提交好几遍都错误
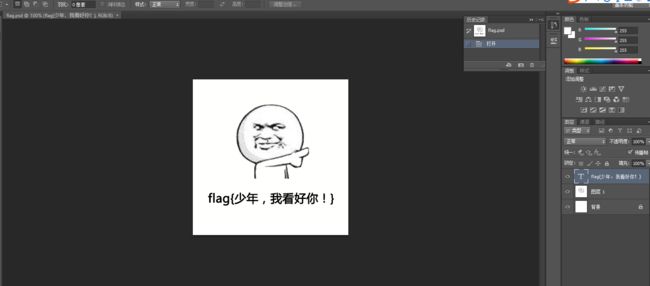 19.再观察图层发现有一个空白的背景,其实最顶层的文字是假的,这里关键在于锁定的“背景”层,看似是新建图片时所留下的默认背景图,而本题就是把flag隐藏在里面,
把上面2层隐藏掉,然后对背景色另存为gif格式(这样才能完好的保留颜色)
19.再观察图层发现有一个空白的背景,其实最顶层的文字是假的,这里关键在于锁定的“背景”层,看似是新建图片时所留下的默认背景图,而本题就是把flag隐藏在里面,
把上面2层隐藏掉,然后对背景色另存为gif格式(这样才能完好的保留颜色)
20..使用stegsolve打开,并按下向左的按钮 得到一个二维码
 21.通过在线二维码扫描,扫描获得flag
http://cdn.malu.me/qrdecode/
21.通过在线二维码扫描,扫描获得flag
http://cdn.malu.me/qrdecode/
 22.最终得到flag:
flag{409d7b1e-3932-11e7-b58c-6807154a58cf}
22.最终得到flag:
flag{409d7b1e-3932-11e7-b58c-6807154a58cf}
七十一、wav文件隐写之曼彻斯特编码
writeup:
1.通过Audacity 打开godwave.wav文件,并查看时域波形,如下:
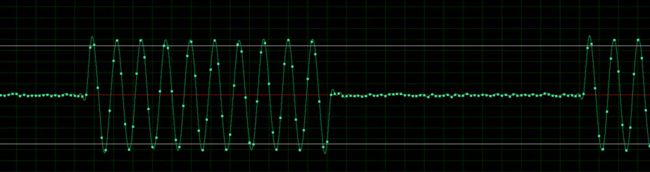
2.发现波形明显别修改过,赋值差异很明显,数出周期为64个点。写个脚本把它提取成01序列:
写的过程中值得注意的是:横轴改成smpl,即采样点,每个单位对应一个实心点;纵轴改成norm,表示幅值。这样在编程时,每个点就是横轴对应waveData[i],纵轴对应norm。
另外,判断每周期的值时,本来采用的是计算平均值。后来简化计算改成全部求和,先看了一下低赋值周期最大值不超过0.035,那么64个点最多也就2.24。在输出文件中写了一行01串。
脚本如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import wave
import matplotlib.pyplot as plt
import numpy
import os
path = 'C:\\Users\\backlion\\Desktop\\'
wav = wave.open(path+'godwave.wav','rb')
params = wav.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
strData = wav.readframes(nframes) #读取音频,字符串格式
waveData = numpy.fromstring(strData, dtype=numpy.int16) #上述字符串转int
waveData = waveData*1.0/(max(abs(waveData))) #wave幅值归一化,与Cool edit的norm纵轴数值一致
#将音频转化为01串
string = ''
norm = 0
for i in range(1735680):
norm = norm+abs(waveData[i])
if (i+1) % 64 == 0:
if norm > 10:
string += '1'
else:
string += '0'
norm = 0
with open('01output.txt','w') as output:
output.writelines(string)
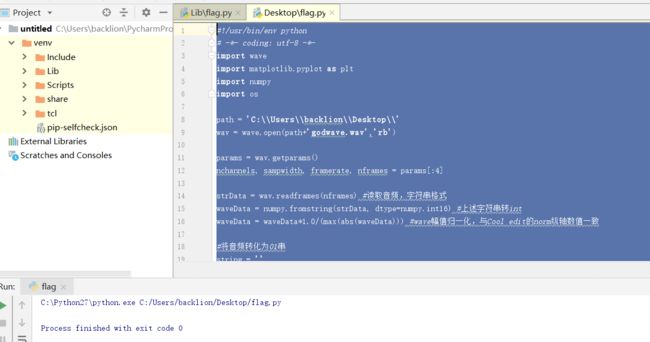
# -*- coding: utf-8 -*-
file_in = open('01output.txt','r')
code = file_in.readline()
file_in.close()
le = len(str(code))
print le
print code
result = ''
count = 0
res = 0
while code != '':
cp = code[:2]
if cp != '':
if cp[0] == '0' and cp[1] == '1':
res = (res<<1)|0
count +=1
if cp[0] == '1' and cp[1] == '0':
res = (res<<1)|1
count +=1
if count == 8:
result += chr(res)
count = 0
res = 0
else:
print 'Unexpected cp, exit!' # found '00' or '11', stop the script directly
break
code = code[2:]
with open('result.png','wb') as file_out:
file_out.write(result)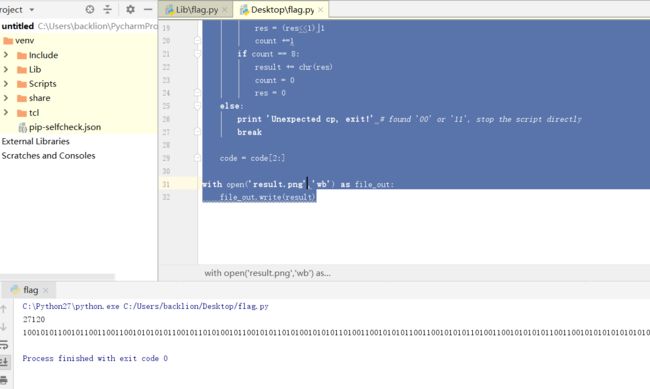

七十二、压力传感器报文之曼彻斯特编码
现有某ID为0xFED31F的压力传感器,已知测得压力为45psi时的未解码报文为:
5555555595555A65556A5A96AA666666A955
压力为30psi时的未解码报文为:
5555555595555A65556A9AA6AA6666665665
请给出ID为0xFEB757的传感器在压力为25psi时的解码后报文,提交hex。
注:其他测量读数与上一个传感器一致。
1.根据题目可知45pis和35psi的报文,这里都是16进制
压力45psi的报文 5555555595555A65556A5A96AA666666A955
35psi报文:5555555595555A65556A9AA6AA6666665665
2.需要上面的报文都转换成十进制
#45psi
>>>bin(0x5555555595555A65556A5A96AA666666A955)
'0b10101010101010101010101010101011001010101010101010110100110010101010101011010100101101010010110101010100110011001100110011001101010100101010101'

#30psi
>>>bin(0x5555555595555A65556A9AA6AA6666665665)
'0b10101010101010101010101010101011001010101010101010110100110010101010101011010101001101010100110101010100110011001100110011001100101011001100101'

3.再对其进行曼彻斯特编码:
45psi:10101010101010101010101010101011001010101010101010110100110010101010101011010100101101010010110101010100110011001100110011001101010100101010101
曼切斯特是从低到高跳变表示“1”,从高到低跳变表示“0”,即01->1,10->0,11>1,将编码进行曼切斯特解码
11111111 11111111 01111111 11001011 11111000 11000110 00001010 10101010 00011111
反转:
11111111 11111111 11111110 11010011 00011111 01100011 01010000 01010101 11111000
将其转换成十六进制
>>>hex(0b111111111111111111111110110100110001111101100011010100000101010111111000)
'0xfffffed31f635055f8' #其中包含了ID值0xFED31F,与题目所给ID:0xFED31F契合
经反转处理后Hex:FFFFFED31F635055F8

30psi:10101010101010101010101010101011001010101010101010110100110010101010101011010101001101010100110101010100110011001100110011001100101011001100101
曼切斯特是从低到高跳变表示“1”,从高到低跳变表示“0”,即01->1,10->0,11>1,将编码进行曼切斯特解码
11111111 11111111 01111111 11001011 11111000 01000010 00001010 10101010 11101011
反转:(每8位都进行一次反转)
11111111 11111111 11111110 11010011 00011111 01000010 01010000 01010101 11010111
将其转换成十六进制:
>>>hex(0b111111111111111111111110110100110001111101000010010100000101010111010111)
'0xfffffed31f425055d7'
经反转处理后Hex:FFFFFED31F425055D7

FFFF FED31F 63 5055 F8(45psi)
FFFF FED31F 42 5055 D7(30psi)
发现唯一差别:一个是63和42(这个应该是压力值),一个是F8和D7(这个应该是校验位),转成10进制,可以看出:63和42相差33
又因为压力相差15psi,猜测是否每5psi增加11,所以猜测25psi应该是在42和D7的基础上减去11得到37,那么得到 FFFF FEB757 37 5055
然后发现校验值为从ID开始每字节相加的和模256的十六进制值即为校验值
即:
例如:FFFF FED31F 63 5055 F8
FE+D3+1F+63+50+55=2F8(F8即校验值)
再例如:FFFF FED31F 42 5055 D7
FE+D3+1F+42+50+55=2D7(D7即校验值)
那么同理:
对于题目中的25psi:FFFF FEB757 37 5055
FE+B7+57+37+50+55=2E8
校验值应该为E8
即得到flag:flag{FFFFFEB757375055E8}
5.观察到给定的两组数据只有两个字节有差异,其中前面一个字节代表压力值,后一个字节猜想是校验值,同时注意到二者的差是相同的,于是初步确定校验算法是前面字节的和,但是每次都差 2,于是去掉开头的两个字节 FFFF,得到的校验值低 8 位匹配。通过脚本如下:
def decode(a):
t = bin(a)[2:].rjust(144, '0')
counter = 0
res = []
temp = []
for i in range(0, len(t), 2):
if t[i] == '0':
temp.append('1')
else:
temp.append('0')
if len(temp) == 8:
temp.reverse()
res.append(int(''.join(temp), 2))
temp = []
fin = ""
for t in res:
fin += hex(t)[2:].rjust(2, '0').upper()
return fin
def check(m):
sum = 0
sum += (m >> 8) & 0xff
sum += (m >> 16) & 0xff
sum += (m >> 24) & 0xff
sum += (m >> 32) & 0xff
sum += (m >> 40) & 0xff
sum += (m >> 48) & 0xff
return sum & 0xff
t = 0xfffffeb75700505500
i = 0x20
while i < 0x43:
m = t + (i << 24)
code = check(m)
m += code
i += 1
print "flag{" + hex(m)[2:-1].upper() + "}"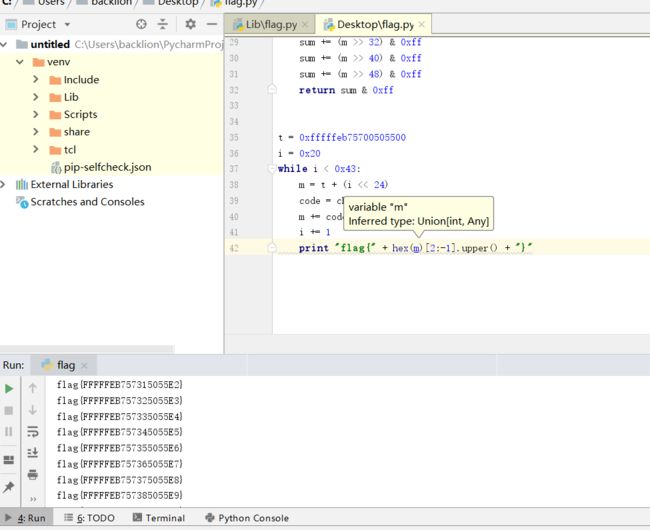
七十三、流量文件隐写之jsfuck编码
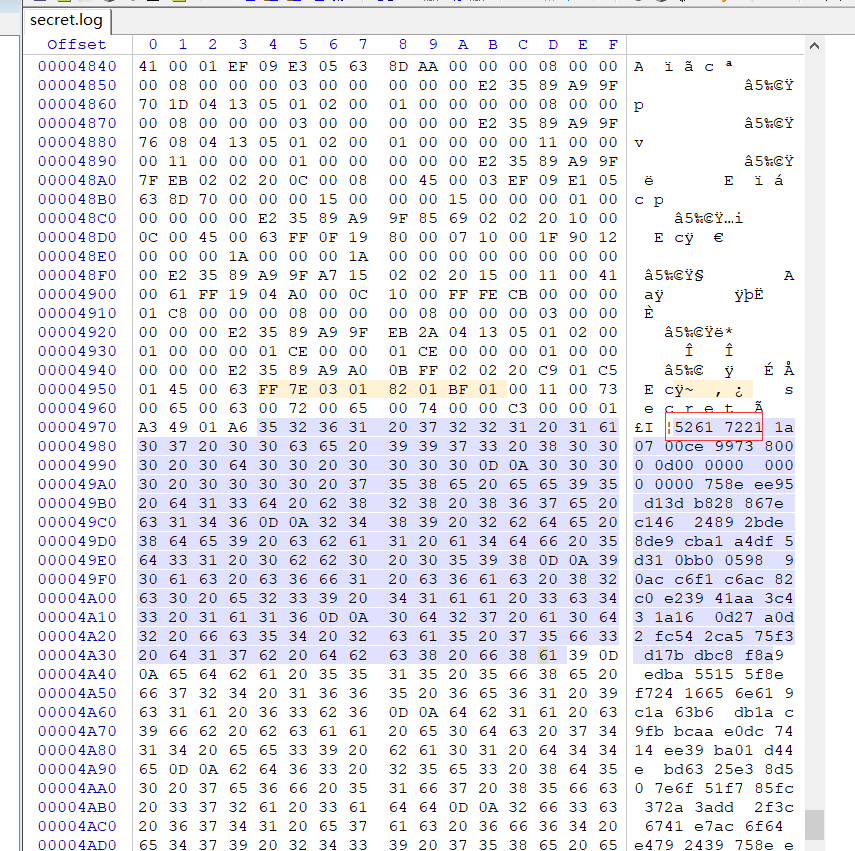
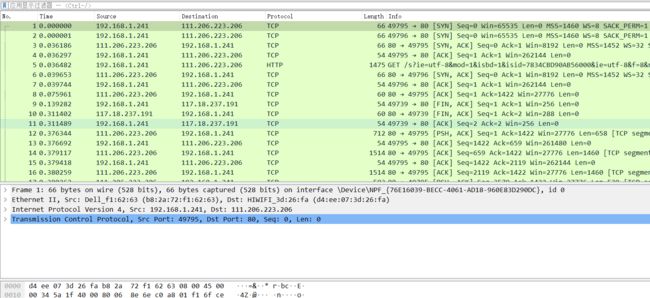
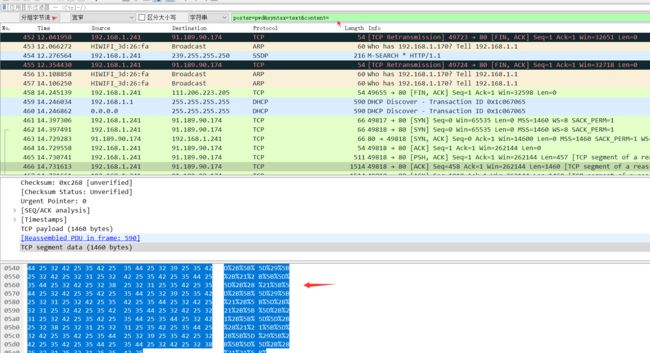
3.将文件保存为 .rar (压缩文件)即可


七十四、流量文件之unicode编码
writeup:
1.通过wireshark打开流量文件,并通过过滤post数据包 http.request.method =="POST",可以看到upload/example1.php
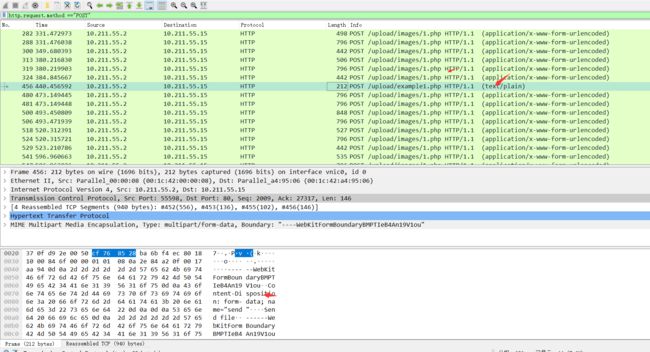
2.追踪http流可得上传的文件内容为unicode编码

4.同样对/upload/images/1.php进行http流分析

5.可以看到是传了webshell然后进行文件操作,一般是传webshell然后菜刀连接,参数进行base64位加密,先解密参数
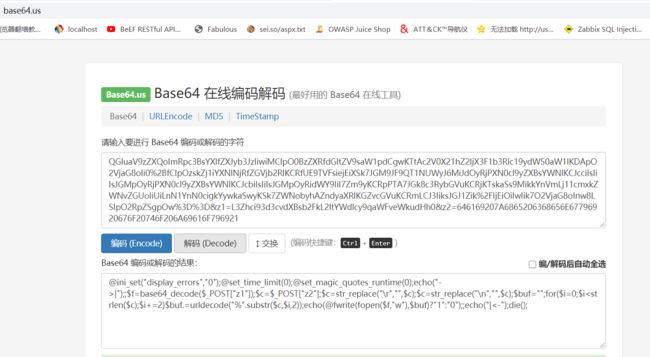
6.没发现可利用的,然后对上面传输的编码进行unicode转成ascii
http://tool.chinaz.com/tools/unicode.aspx
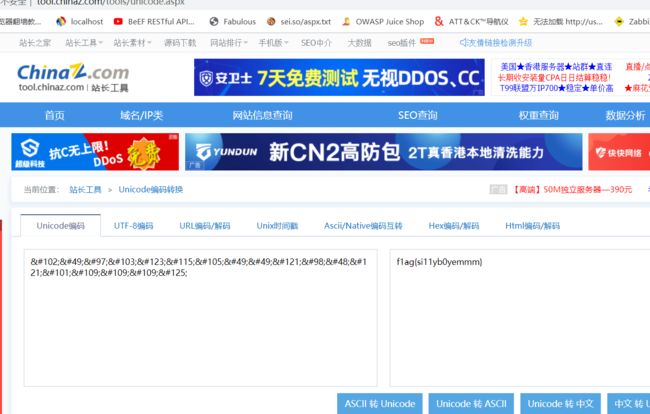
7.最终得到flag:
flag{si11yb0yemmm}
七十五、不完整的二维码隐写之条形码扫描
writeup:
1.在其他地方找来一张完整的二维码,然后通过ps截取定位矩阵框,进行修复,最终得到



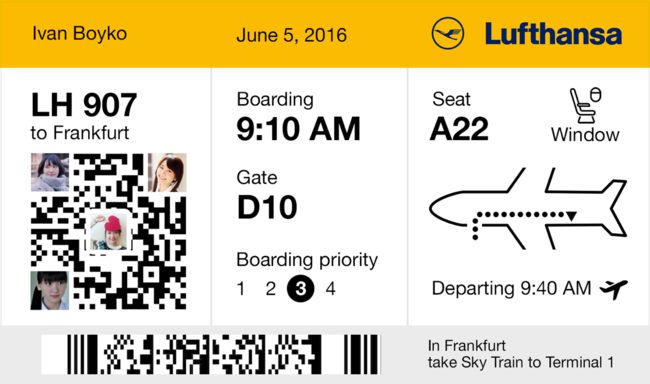

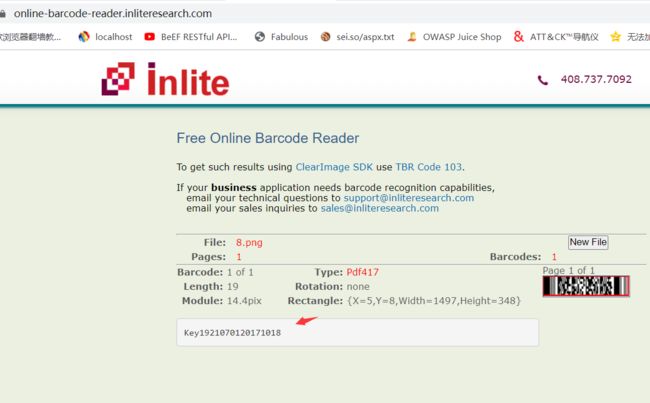
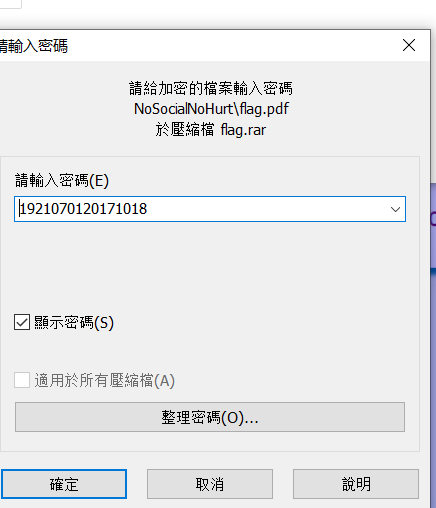
Key1921070120171018