机器学习时间序列特征处理与构造,这篇我建议你收藏
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了 Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和 Feature construction(特征构造)等子问题,本章内容主要讨论特征构造的方法。

文章目录
-
- 技术交流
- 特征构造介绍
- 时间特征构造
-
- 1.连续值时间特征
- 2.离散值时间特征
-
- 1)时间特征拆解
-
- 程序实现
- 2)时间特征判断
-
- 程序实现
- 3.结合时间维度的聚合特征
-
- 1)首日聚合特征
- 2)最近时间聚合特征
- 3)区间内的聚合特征
- 时间序列特征构造
-
- 1.时间序列聚合特征
-
-
- 1)平均值
- 2)最小值
- 3)最大值
- 4)扩散值
- 5)离散系数值
- 6)分布性
-
- 2.时间序列历史特征
-
- 1)前一(或n)个窗口的取值
- 2)周期性时间序列前一(或n)周期的前一(或n)个窗口的取值
- 3.时间序列复合特征
-
- 1)趋势特征
- 2)窗口差异值特征
- 3)自相关性特征
- 总结
-
- 1.时间特征主要有两大类:
-
- 1)从时间变量提取出来的特征
- 2)对时间变量进行条件过滤,然后再对其他变量进行聚合操作所产生的特征
- 2. 时间序列数据可以从带有时间的流水数据统计得到,实际应用中可以分别从带有时间的流水数据以及时间序列数据中构造特征,这些特征可以同时作为模型输入特征。
- 参考文献
技术交流
技术要学会分享、交流,不建议闭门造车。 本文技术由粉丝群小伙伴分享汇总。源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88191,备注:来自CSDN +研究方向
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
特征构造介绍
时间特构造以及时间序列特征构造的具体方法:
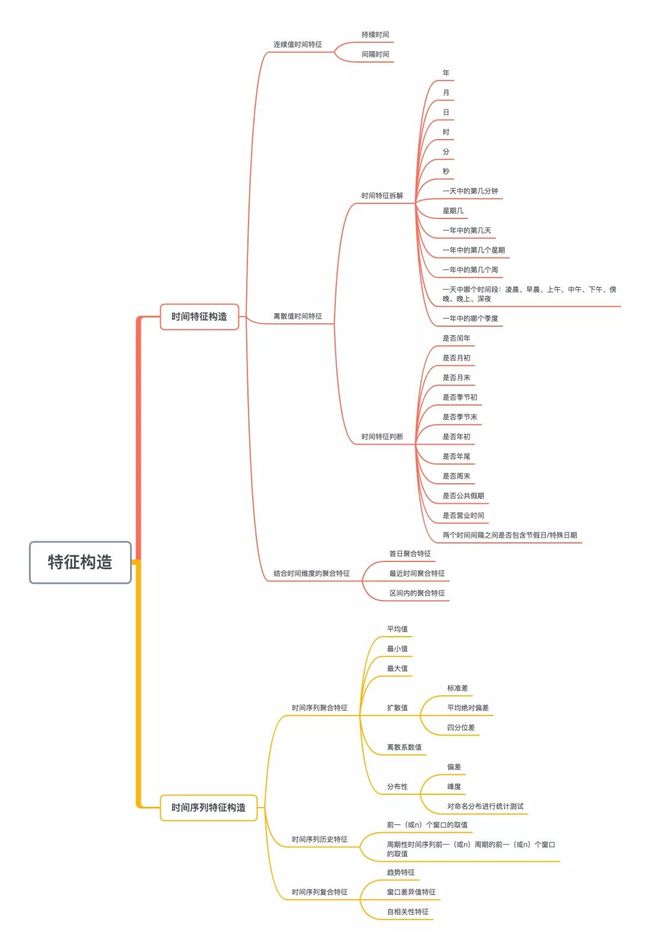
时间特征构造
对于时间型数据来说,即可以把它转换成连续值,也可以转换成离散值。
1.连续值时间特征
-
持续时间(单页浏览时长);
-
间隔时间;
-
上次购买/点击离现在的时长;
-
产品上线到现在经过的时长;
2.离散值时间特征
1)时间特征拆解
-
年;
-
月;
-
日;
-
时;
-
分;
-
数;
-
一天中的第几分钟;
-
星期几;
-
一年中的第几天;
-
一年中的第几个周;
-
一天中哪个时间段:凌晨、早晨、上午、中午、下午、傍晚、晚上、深夜;
-
一年中的哪个季度;
程序实现
import pandas as pd
# 构造时间数据
date_time_str_list = [
'2019-01-01 01:22:26', '2019-02-02 04:34:52', '2019-03-03 06:16:40',
'2019-04-04 08:11:38', '2019-05-05 10:52:39', '2019-06-06 12:06:25',
'2019-07-07 14:05:25', '2019-08-08 16:51:33', '2019-09-09 18:28:28',
'2019-10-10 20:55:12', '2019-11-11 22:55:12', '2019-12-12 00:55:12',
]
df = pd.DataFrame({'时间': date_time_str_list})
# 把字符串格式的时间转换成Timestamp格式
df['时间'] = df['时间'].apply(lambda x: pd.Timestamp(x))
# 年份
df['年']=df['时间'].apply(lambda x: x.year)
# 月份
df['月']=df['时间'].apply(lambda x: x.month)
# 日
df['日']=df['时间'].apply(lambda x: x.day)
# 小时
df['时']=df['时间'].apply(lambda x: x.hour)
# 分钟
df['分']=df['时间'].apply(lambda x: x.minute)
# 秒数
df['秒']=df['时间'].apply(lambda x: x.second)
# 一天中的第几分钟
df['一天中的第几分钟']=df['时间'].apply(lambda x: x.minute + x.hour*60)
# 星期几;
df['星期几']=df['时间'].apply(lambda x: x.dayofweek)
# 一年中的第几天
df['一年中的第几天']=df['时间'].apply(lambda x: x.dayofyear)
# 一年中的第几周
df['一年中的第几周']=df['时间'].apply(lambda x: x.week)
# 一天中哪个时间段:凌晨、早晨、上午、中午、下午、傍晚、晚上、深夜;
period_dict ={
23: '深夜', 0: '深夜', 1: '深夜',
2: '凌晨', 3: '凌晨', 4: '凌晨',
5: '早晨', 6: '早晨', 7: '早晨',
8: '上午', 9: '上午', 10: '上午', 11: '上午',
12: '中午', 13: '中午',
14: '下午', 15: '下午', 16: '下午', 17: '下午',
18: '傍晚',
19: '晚上', 20: '晚上', 21: '晚上', 22: '晚上',
}
df['时间段']=df['时'].map(period_dict)
# 一年中的哪个季度
season_dict = {
1: '春季', 2: '春季', 3: '春季',
4: '夏季', 5: '夏季', 6: '夏季',
7: '秋季', 8: '秋季', 9: '秋季',
10: '冬季', 11: '冬季', 12: '冬季',
}
df['季节']=df['月'].map(season_dict)

2)时间特征判断
-
是否闰年;
-
是否月初;
-
是否月末;
-
是否季节初;
-
是否季节末;
-
是否年初;
-
是否年尾;
-
是否周末;
-
是否公共假期;
-
是否营业时间;
-
两个时间间隔之间是否包含节假日/特殊日期;
程序实现
import pandas as pd
# 构造时间数据
date_time_str_list = [
'2010-01-01 01:22:26', '2011-02-03 04:34:52', '2012-03-05 06:16:40',
'2013-04-07 08:11:38', '2014-05-09 10:52:39', '2015-06-11 12:06:25',
'2016-07-13 14:05:25', '2017-08-15 16:51:33', '2018-09-17 18:28:28',
'2019-10-07 20:55:12', '2020-11-23 22:55:12', '2021-12-25 00:55:12',
'2022-12-27 02:55:12', '2023-12-29 03:55:12', '2024-12-31 05:55:12',
]
df = pd.DataFrame({'时间': date_time_str_list})
# 把字符串格式的时间转换成Timestamp格式
df['时间'] = df['时间'].apply(lambda x: pd.Timestamp(x))
# 是否闰年
df['是否闰年'] = df['时间'].apply(lambda x: x.is_leap_year)
# 是否月初
df['是否月初'] = df['时间'].apply(lambda x: x.is_month_start)
# 是否月末
df['是否月末'] = df['时间'].apply(lambda x: x.is_month_end)
# 是否季节初
df['是否季节初'] = df['时间'].apply(lambda x: x.is_quarter_start)
# 是否季节末
df['是否季节末'] = df['时间'].apply(lambda x: x.is_quarter_end)
# 是否年初
df['是否年初'] = df['时间'].apply(lambda x: x.is_year_start)
# 是否年尾
df['是否年尾'] = df['时间'].apply(lambda x: x.is_year_end)
# 是否周末
df['是否周末'] = df['时间'].apply(lambda x: True if x.dayofweek in [5, 6] else False)
# 是否公共假期
public_vacation_list = [
'20190101', '20190102', '20190204', '20190205', '20190206',
'20190207', '20190208', '20190209', '20190210', '20190405',
'20190406', '20190407', '20190501', '20190502', '20190503',
'20190504', '20190607', '20190608', '20190609', '20190913',
'20190914', '20190915', '20191001', '20191002', '20191003',
'20191004', '20191005', '20191006', '20191007',
] # 此处未罗列所有公共假期
df['日期'] = df['时间'].apply(lambda x: x.strftime('%Y%m%d'))
df['是否公共假期'] = df['日期'].apply(lambda x: True if x in public_vacation_list else False)
# 是否营业时间
df['是否营业时间'] = False
df['小时']=df['时间'].apply(lambda x: x.hour)
df.loc[((df['小时'] >= 8) & (df['小时'] < 22)), '是否营业时间'] = True
df.drop(['日期', '小时'], axis=1, inplace=True)

3.结合时间维度的聚合特征
具体就是指结合时间维度来进行聚合特征构造,聚合特征构造的具体方法可以参考《聚合特征构造以及转换特征构造》中的《聚合特征构造》章节。
1)首日聚合特征
例如:注册首日投资总金额、注册首日页面访问时长、注册首日总点击次数等;
2)最近时间聚合特征
例如:最近N天APP登录天数、最近一个月的购买金额、最近购物至今天数等;
3)区间内的聚合特征
例如:2018年至2019年的总购买金额、每天下午的平均客流量、在某公司工作期间加班的天数等;
时间序列特征构造
时间序列不仅包含一维时间变量,还有一维其他变量,如股票价格、天气温度、降雨量、订单量等。时间序列分析的主要目的是基于历史数据来预测未来信息。对于时间序列,我们关心的是长期的变动趋势、周期性的变动(如季节性变动)以及不规则的变动。
按固定时间长度把时间序列划分成多个时间窗,然后构造每个时间窗的特征。
1.时间序列聚合特征
按固定时间长度把时间序列划分成多个时间窗,然后使用聚合操作构造每个时间窗的特征。
1)平均值
例子:历史销售量平均值、最近N天销售量平均值。
2)最小值
例子:历史销售量最小值、最近N天销售量最小值。
3)最大值
例子:历史销售量最大值、最近N天销售量最大值。
4)扩散值
分布的扩散性,如标准差、平均绝对偏差或四分位差,可以反映测量的整体变化趋势。
5)离散系数值
离散系数是策略数据离散程度的相对统计量,主要用于比较不同样本数据的离散程度。
6)分布性
时间序列测量的边缘分布的高阶特效估计(如偏态系数或峰态系数),或者更进一步对命名分布进行统计测试(如标准或统一性),在某些情况下比较有预测力。
程序实现:洗发水销售数据
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)
# 平均值
mean_v = df['value'].mean()
print('mean: {}'.format(mean_v))
# 最小值
min_v = df['value'].min()
print('min: {}'.format(min_v))
# 最大值
max_v = df['value'].max()
print('max: {}'.format(max_v))
# 扩散值:标准差
std_v = df['value'].std()
print('std: {}'.format(std_v))
# 扩散值:平均绝对偏差
mad_v = df['value'].mad()
print('mad: {}'.format(mad_v))
# 扩散值:四分位差
q1 = df['value'].quantile(q=0.25)
q3 = df['value'].quantile(q=0.75)
irq = q3 - q1
print('q1={}, q3={}, irq={}'.format(q1, q3, irq))
# 离散系数
variation_v = std_v/mean_v
print('variation: {}'.format(variation_v))
# 分布性:偏态系数
skew_v = df['value'].skew()
print('skew: {}'.format(skew_v))
# 分布性:峰态系数
kurt_v = df['value'].kurt()
print('kurt: {}'.format(kurt_v))
# 输出:
mean: 312.59999999999997
min: 119.3
max: 682.0
std: 148.93716412347473
mad: 119.66666666666667
q1=192.45000000000002, q3=411.1, irq=218.65
variation: 0.47644646232717447
skew: 0.8945388528534595
kurt: 0.11622821118738624
注:
-
上面是单个时间序列的实现代码,多个时间序列的数据集构造特征时需要先进行分组再计算。如IJCAI-17口碑商家客流量预测比赛中,数据集中包含多个商家的历史销售数据,构造特征时需要先按商家分组,然后再构建特征。
-
上述代码都是使用所有历史数据来构造特征,实际项目中如果待预测目标为t时刻的值,则使用t时刻之前的值来构造特征,不同的t值都可以分别构造训练样本对应的特征。 如:使用t时刻的y值作为label,则使用t-1时刻之前的y值来构造特征;使用t-1时刻的y值作为label时,则使用t-2时刻之前的y值来构造特征。如此类推,我们可以得到多个训练样本,每个样本有多个特征。
2.时间序列历史特征
1)前一(或n)个窗口的取值
例子:昨天、前天和3天前的销售量。
2)周期性时间序列前一(或n)周期的前一(或n)个窗口的取值
例子:写字楼楼下的快餐店的销售量一般具有周期性,周期长度为7天,7天前和14天前的销售量。
程序实现:洗发水销售数据
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)
df['-1day'] = df['value'].shift(1)
df['-2day'] = df['value'].shift(2)
df['-3day'] = df['value'].shift(3)
df['-1period'] = df['value'].shift(1*12)
df['-2period'] = df['value'].shift(2*12)
display(df.head(60))

3.时间序列复合特征
1)趋势特征
趋势特征可以刻画时间序列的变化趋势。
例子:每个用户每天对某个Item行为次数的时间序列中,User一天对Item的行为次数/User三天对Item的行为次数的均值,表示短期User对Item的热度趋势,大于1表示活跃逐渐在提高;三天User对Item的行为次数的均值/七天User对Item的行为次数的均值表示中期User对Item的活跃度的变化情况;七天User对Item的行为次数的均值/ 两周User对Item的行为次数的均值表示“长期”(相对)User对Item的活跃度的变化情况。
程序实现:
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)
df['last 3 day mean'] = (df['value'].shift(1) + df['value'].shift(2) + df['value'].shift(3))/3
df['最近3天趋势'] = df['value'].shift(1)/df['last 3 day mean']
display(df.head(60))

2)窗口差异值特征
一个窗口到下一个窗口的差异。例子:商店销售量时间序列中,昨天的销售量与前天销售量的差值。
程序实现:
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)
df['最近两月销量差异值'] = df['value'].shift(1) - df['value'].shift(2)
display(df.head(60))

3)自相关性特征
原时间序列与自身左移一个时间空格(没有重叠的部分被移除)的时间序列相关联。
程序实现:
import statsmodels.tsa.api as smt
import pandas as pd
# 加载洗发水销售数据集
df = pd.read_csv('shampoo-sales.csv')
df.dropna(inplace=True)
df.rename(columns={'Sales of shampoo over a three year period': 'value'}, inplace=True)
print('滞后数为1的自相关系数:{}'.format(df['value'].autocorr(1)))
print('滞后数为2的自相关系数:{}'.format(df['value'].autocorr(2)))
# 输出:
滞后数为1的自相关系数:0.7194822398024308
滞后数为2的自相关系数:0.8507433352850972
除了上面描述的特征外,时间序列还有历史波动率、瞬间波动率、隐含波动率、偏度、峰度、瞬时相关性等特征。
总结
1.时间特征主要有两大类:
1)从时间变量提取出来的特征
- 如果每条数据为一条训练样本,时间变量提取出来的特征可以直接作为训练样本的特征使用。
例子:用户注册时间变量。对于每个用户来说只有一条记录,提取出来的特征可以直接作为训练样本的特征使用,不需要进行二次加工。
- 如果每条数据不是一条训练样本,时间变量提取出来的特征需要进行二次加工(聚合操作)才能作为训练样本的特征使用。
例子:用户交易流水数据中的交易时间。由于每个用户的交易流水数量不一样,从而导致交易时间提取出来的特征的数据不一致,所以这些特征不能直接作为训练样本的特征来使用。我们需要进一步进行聚合操作才能使用,如先从交易时间提取出交易小时数,然后再统计每个用户在每个小时(1-24小时)的交易次数来作为最终输出的特征。
2)对时间变量进行条件过滤,然后再对其他变量进行聚合操作所产生的特征
主要是针对类似交易流水这样的数据,从用户角度进行建模时,每个用户都有不定数量的数据,因此需要对数据进行聚合操作来为每个用户构造训练特征。而包含时间的数据,可以先使用时间进行条件过滤,过滤后再构造聚合特征。
2. 时间序列数据可以从带有时间的流水数据统计得到,实际应用中可以分别从带有时间的流水数据以及时间序列数据中构造特征,这些特征可以同时作为模型输入特征。
例如:美团的商家销售量预测中,每个商家的交易流水经过加工后可以得到每个商家每天的销售量,这个就是时间序列数据。
参考文献
- [1] https://machinelearning-notes.readthedocs.io/zh_CN/latest/feature/%E7%89%B9%E5%BE%81%E5%B7%A5%E7%A8%8B%E2%80%94%E2%80%94%E6%97%B6%E9%97%B4.html
- [2] https://www.cnblogs.com/nxf-rabbit75/p/11141944.html#_nav_12 \
- [3] https://gplearn.readthedocs.io/en/stable/examples.html#symbolic-classifier
- [4] 利用 gplearn 进行特征工程. https://bigquant.com/community/t/topic/120709
- [5] Practical Lessons from Predicting Clicks on Ads at Facebook. https://pdfs.semanticscholar.org/daf9/ed5dc6c6bad5367d7fd8561527da30e9b8dd.pdf
- [6] Feature Tools:可自动构造机器学习特征的Python库. https://www.jiqizhixin.com/articles/2018-06-21-2
- [7] 各种聚类算法的系统介绍和比较. https://blog.csdn.net/abc200941410128/article/details/78541273