基于TensorFlow的CNN模型——猫狗分类识别器(四)之创建CNN模型
注意:这是一个完整的项目,建议您按照完整的博客顺序阅读。
目录
三、创建CNN模型
1、构建权重和偏置
2、构建卷积层
3、构建池化层
4、构建扁平层
5、构建全连接层
6、构建CNN模型
三、创建CNN模型
1、构建权重和偏置
在搭建神经网络层前,我们先来看下如何初始化神经网络层的权重和偏置参数。这一项非常重要,因为卷积层、全连接层等基本都需要这一步,所以我们先单独拿出来说明。
def __create_weights(self,shape):
return tf.Variable(tf.truncated_normal(shape, stddev=0.05))
def __create_biases(self,size):
return tf.Variable(tf.constant(0.05, shape=[size]))
2、构建卷积层
卷积层的主要功能是进行特征提取。
卷积层的主要操作是使用一个固定尺寸的卷积核以Stride为间隔、以Padding为填充方式扫描输入图的每个通道得到一张新的特征图,一个卷积核完成地扫描一次输入图会得到一张单通道的特征图,所以如果该卷积层有多个卷积核,则生成一张有多个通道的特征图。如下图所示:
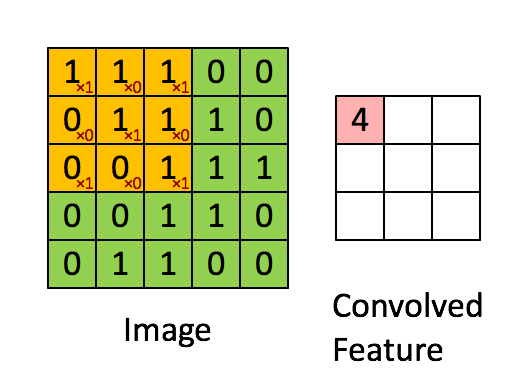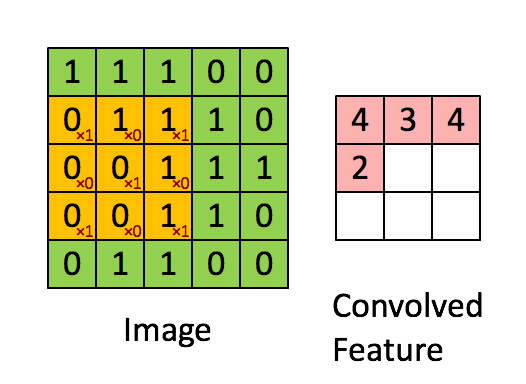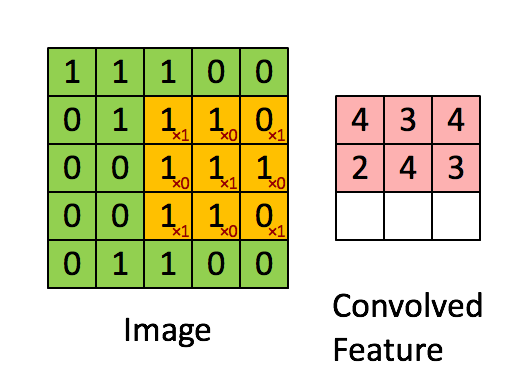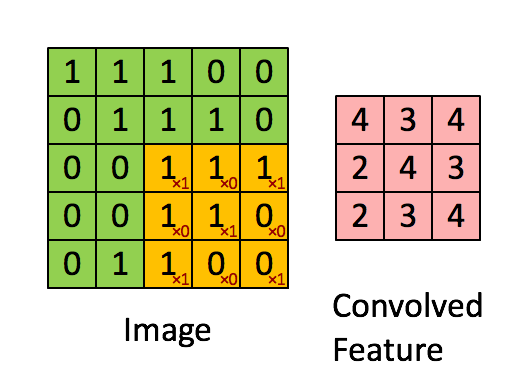
该过程涉及到的一些变量如下:
|
|
英文术语 |
中文释义 |
备注 |
功能 |
|
输入层 |
batch_size |
批大小,每次输入的图片数量 |
(1,64,64,3)表示输入层为一张64*64的3通道的图片 |
输出数据 |
|
image_size |
图片尺寸,一般长宽相等 |
|||
|
color_channel |
颜色通道,彩色图片一般为RGB的3通道 |
|||
|
卷积层 |
filter_size |
卷积核(滤波器)尺寸,一般长宽相等 |
(3,3,3,10)表示使用10个3*3的卷积核处理输入为3通道的图片/特征图,输出为10通道的特征图,根据stride和padding等可以计算特征图的大小 |
特征提取 |
|
stride |
步长,卷积核每次扫描的间隔 |
|||
|
padding |
边界扩充方式,卷积核扫描时可能会出界 |
|||
|
in_channel |
输入通道数,一般为上一层的通道数 |
|||
|
out_channel |
输出通道数,与卷积核的数量相等 |
TensorFlow中的常见卷积操作有如下几种类型:
|
卷积类型 |
对应函数名称 |
备注 |
|
卷积操作 |
tf.nn.conv2d |
返回一个简化张量,元素是每个窗口最大值 |
|
tf.nn.atrous_conv2d() |
创建一个空洞卷积层(trous是法语,表示有孔) |
|
|
tf.nn.depthwise_conv2d() |
创建一个深度卷积层,它独立地将每个滤波器应用到每个输入通道。 |
|
|
tf.nn.separable_conv2d() |
创建一个深度可分卷积层 |
|
|
卷积层 |
tf.layers.conv1d() |
创建一个1D输入的卷积层,这很有用,例如在NLP中,一个句子可以表示为一个1D的词数组,并且感受野包含几个相邻的词 |
|
tf.layers.conv3d() |
创建一个3D输入的卷积层 |
|
|
tf.layers.conv2d_transpose() |
创建一个转置卷积层,有时称为反卷积层,它对图像向上采样。 |
在本项目中,我们使用如下API来构建生成卷积层的方法:
def _conv2d(input,weights,stride,padding='SAME'):
layer = tf.nn.conv2d(input=input, # 输入的原始张量
filter=weights, # 卷积核张量,
strides=[1, stride, stride, 1],#步长
padding=padding)# 边缘填充形式
return layer
上述代码用了 tf.nn.conv2d() 函数来计算卷积,weights 作为滤波器,[1, 2, 2, 1] 作为 strides。TensorFlow 对每一个 input 维度使用一个单独的 stride 参数,[batch, input_height, input_width, input_channels]。我们通常把 batch 和 input_channels (strides 序列中的第一个第四个)的 stride 设为 1,所以我们将该函数进行下简单封装,让我们专注于修改 input_height 和 input_width, batch 和 input_channels 都设置成 1。
接下来我们继续对卷积操作的输出进行处理,整体代码如下:
weights = self.__create_weights(shape=[conv_filter_size, conv_filter_size, num_input_channels, num_filters])
biases = self.__create_biases(num_filters)
layer = _conv2d(input,weights, stride=1)
layer += biases # 添加偏置层
layer = tf.nn.relu(layer) # 对输出进行激活
tf.nn.bias_add() 函数对矩阵的最后一维加了偏置项。
tf.nn.relu() 函数输出进行了激活。
3、构建池化层
池化操作的过程如下:
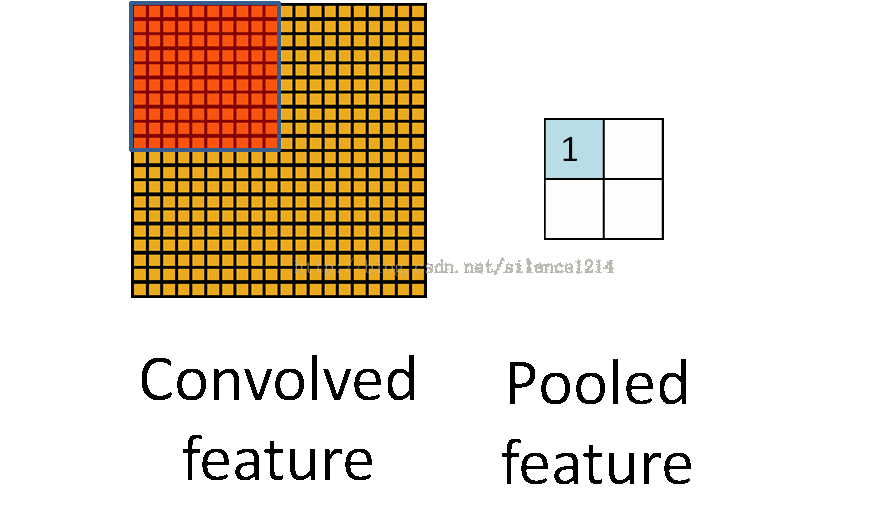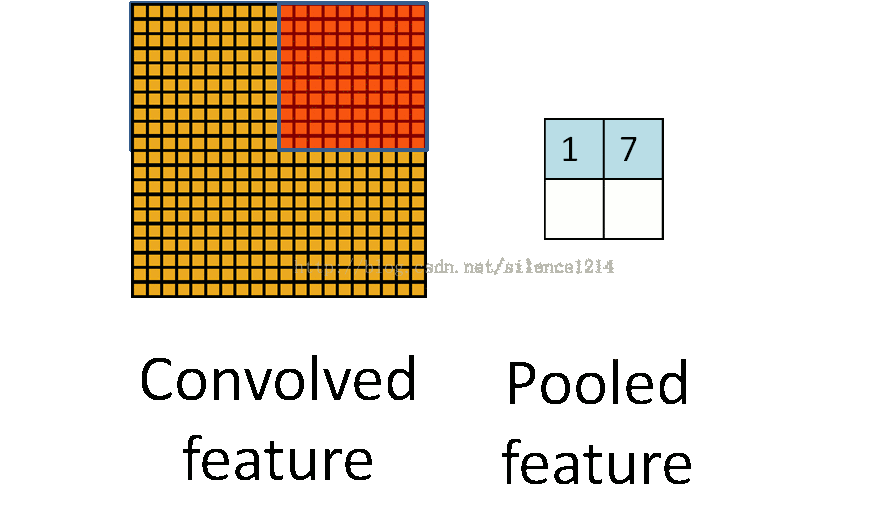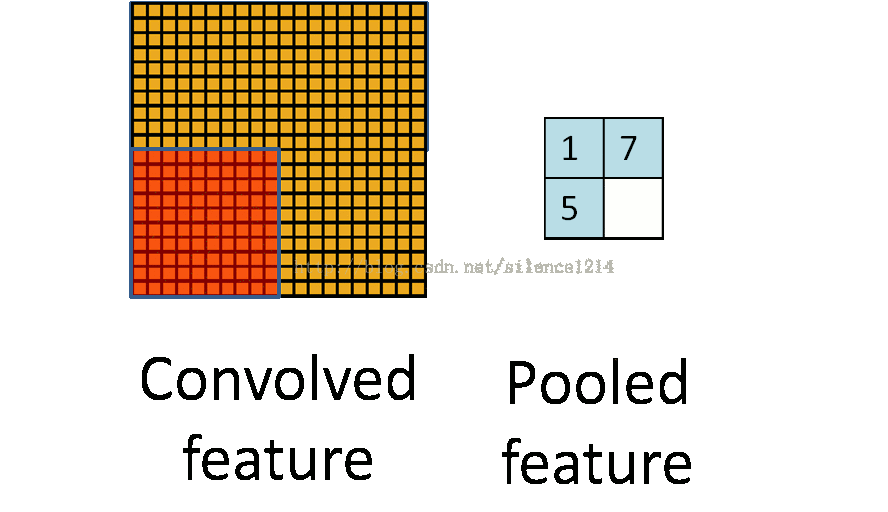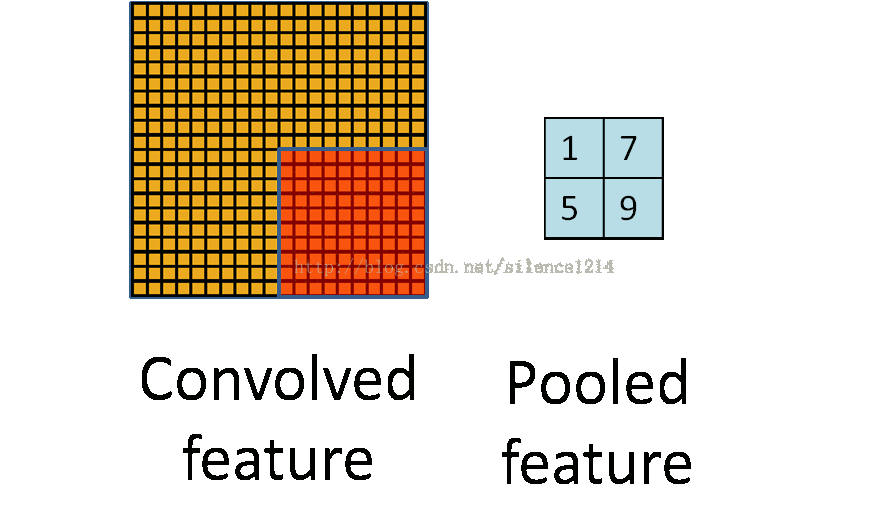
池化和卷积的操作很像,都是从原始图像中局部采样计算一个新的图像,但是两者的计算方式有很大不同,所以作用也不一样。池化层的主要功能是进行二次采样,减少计算量,避免过拟合。池化层的常用操作有最大池化和平均池化两种方式。
TensorFlow 提供了如下函数,用于对卷积层实现池化操作。
|
池化类型 |
对应函数名称 |
备注 |
|
最大池化 |
tf.nn.max_pool |
返回一个简化张量,元素是每个窗口最大值 |
|
tf.nn.max_pool_with_argmax |
返回max_pool张量和 一个展开max_value索引的张量 |
|
|
tf.nn.max_pool3d |
基于立方窗口执行max_pool操作,输入有一个额外的深度 |
|
|
平均池化 |
tf.nn.avg_pool |
返回一个简化张量,元素是每个窗口平均值 |
|
tf.nn.avg_pool3d |
基于立方窗口执行avg_pool操作,输入有一个额外的深度 |
在本项目中我们使用tf.nn.max_pool()函数进行池化操作,并对其进行了进一步封装:
def __maxpool2d(self,input, stride=2,padding='SAME'):
layer = tf.nn.max_pool(value=input,
ksize=[1, stride, stride, 1],
strides=[1, stride, stride, 1],
padding=padding) # VALID或SAME
return layer
tf.nn.max_pool() 函数实现最大池化时, ksize参数是滤波器大小,strides参数是步长。2x2 的滤波器配合 2x2 的步长是常用设定。ksize 和 strides 参数也被构建为四个元素的列表,每个元素对应 input tensor 的一个维度 ([batch, height, width, channels]),对 ksize 和 strides 来说,batch 和 channel 通常都设置成 1。
现在我们将池化层添加到上一小节的卷积层后面,为了让代码更加简洁,我们这里将池化操作也视为卷积层的一部分,共同封装为一个函数:
def __create_conv_pool_layer(self,input,
num_input_channels,
conv_filter_size,
num_filters):
weights = self.__create_weights(shape=[conv_filter_size, conv_filter_size, num_input_channels, num_filters])
biases = self.__create_biases(num_filters)
layer = self.__conv2d(input=input, weights=weights,stride=1) # 卷积操作
#layer += biases # 添加偏置
layer =tf.nn.bias_add(layer,bias=biases)
layer = tf.nn.relu(layer) # 对层进行激活
layer = self.__maxpool2d(input=layer,stride=2) # 进行池化操作
return layer
我们归纳这个过程,可以得出卷积池化层的构建步骤:
|
顺序 |
步骤说明 |
tf函数 |
备注 |
|
1 |
创建权重矩阵 |
tf.Variable() |
|
|
tf.truncated_normal() |
|
||
|
2 |
创建偏置矩阵 |
tf.Variable() |
|
|
tf.constant() |
|
||
|
3 |
添加卷积操作 |
tf.nn.conv2d() |
|
|
4 |
添加偏置部分 |
tf.nn.bias_add() |
也可使用layer += biases代替 |
|
5 |
添加激活函数 |
tf.nn.relu() |
|
|
6 |
添加池化操作 |
tf.nn.max_pool() |
|
4、构建扁平层
扁平层的主要功能是降低维度。例如输入一个四维数组,我们最终输出一个二维数组。
def __create_flatten_layer(self,layer):
layer_shape = layer.get_shape()#(?, 8, 8, 64)
num_features = layer_shape[1:4].num_elements()# 4096
re_layer = tf.reshape(layer, [-1, num_features])#(?, 4096)
return re_layer
我们归纳这个过程,可以得出扁平层的构建步骤:
|
顺序 |
步骤说明 |
tf函数 |
备注 |
|
1 |
获取旧shape |
tensor.get_shape() |
|
|
2 |
计算新shape |
tensor_shape.num_elements() |
|
|
3 |
修改shape |
tf.reshape() |
|
5、构建全连接层
CNN模型中的全连接层的主要功能大多是进行分类输出,最后输出层进行估计概率。
|
层 |
英文术语 |
中文释义 |
备注 |
功能 |
|
全连接层 |
num_input |
输入数,一般为上一层的输出数,如果是卷积层则是输出通道数 |
|
分类输出 |
|
num_output |
输出数,与该层的神经元数量相同 |
|||
|
ReLU |
常用激活函数 |
|||
|
输出层 |
num_input |
输入数,一般为上一层的输出数,如果是卷积层则是输出通道数 |
输出层本质上也是一个全连接层,但是其激活函数与其他全连接层又有所区别,所以单独拿出来。 |
估计概率 |
|
num_output |
输出数,与该层的神经元数量相同 |
|||
|
softmax |
针对分类问题的专用激活函数 |
我们直接看下全连接层的构建步骤:
weights = self.__create_weights(shape=[num_inputs, num_outputs])
biases = self.__create_biases(num_outputs)
layer = tf.matmul(input, weights) + biases
layer = tf.nn.dropout(layer, keep_prob=0.7)
if use_relu:
layer = tf.nn.relu(layer)
我们归纳这个过程,可以得出全连接层的构建步骤:
|
顺序 |
步骤说明 |
tf函数 |
备注 |
|
1 |
创建权重矩阵 |
tf.Variable() |
|
|
tf.truncated_normal() |
|
||
|
2 |
创建偏置矩阵 |
tf.Variable() |
|
|
tf.constant() |
|
||
|
3 |
组合权重偏置 |
tf.matmul() |
tf.matmul(input, weights) + biases |
|
4 |
添加dropout |
tf.nn.dropout() |
|
|
5 |
添加激活函数 |
tf.nn.relu() |
|
|
tf.nn.softmax |
|
6、构建CNN模型
我们有了上面的各个层的搭建方法,我们就可以直接将它们串联起来组合成创建CNN模型的方法,但是只有这个是不够的,我们要创建成TensorFlow可以训练的模型,就需要添加一些细节:
|
顺序 |
步骤说明 |
tf函数 |
备注 |
|
1 |
创建占位符 |
tf.placeholder() |
|
|
2 |
创建模型结构 |
tf.Variable() |
|
|
3 |
创建损失函数 |
tf.nn.softmax_cross_entropy_with_logits_v2 |
计算 softmax(logits) 和 labels 之间的交叉熵 |
|
tf.reduce_mean |
计算平均值 |
||
|
4 |
创建优化器 |
tf.train.AdamOptimizer().minimize() |
学习率,损失函数 |
|
5 |
创建会话并初始化 |
tf.Session() |
|
|
tf.global_variables_initializer() |
|
||
|
tf.Session().Run |
|
在本项目中我们的代码如下:
# 定义输入数据结构
self.x = tf.placeholder(tf.float32, shape=[None, self.img_size, self.img_size, self.num_channels], name='x')
self.y_true = tf.placeholder(tf.float32, shape=[None, self.num_classes], name='y_true')
y_true_cls = tf.argmax(self.y_true, axis=1)
# 创建CNN模型,返回输出
layer_fc2 = self.__create_cnn(self.x)
y_pred = tf.nn.softmax(layer_fc2, name='y_pred')
y_pred_cls = tf.argmax(y_pred, axis=1, name='y_pred_cls')
# 定义损失函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=layer_fc2, labels=self.y_true)
self.cost = tf.reduce_mean(cross_entropy)
# 选择优化器
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(self.cost)
# 定义检测数据
correct_prediction = tf.equal(y_pred_cls, y_true_cls)
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量
self.session = tf.Session()
self.session.run(tf.global_variables_initializer())