文本编码方式(词向量提取方式)
文章目录
- 1. 文本编码方式
-
- 1.1 one-hot
- 1.2 分布式表示
- 2. 分布式表示
-
- 2.1 基于矩阵的分布式表示
-
- 2.1.1 GloVe
-
- 步骤
- 共现关系的构建
- 训练方法
- 2.2 基于聚类的分布式表示
-
- 2.2.1 布朗聚类
- 2.3 基于神经网络的分布式表示
-
- 2.3.1 word2vec
-
- CBOW
- Skip-gram
- 加速技巧
- 2.3.2 Bert
-
- 网络架构
- 对比GPT、ELMo的优势
- 3. 小结
- 参考文献
1. 文本编码方式
1.1 one-hot
缺点:
- 维度大
- 词和词之间都是孤立的,无法表示词与词之间的语义信息
1.2 分布式表示
正所谓:“物以类聚,人以群分”,所以分布式表示的主要思想为:上下文相似的词,其语义也相似。其主要分为三种方法。
- 基于矩阵的分布式表示
- 基于聚类的分布式表示
- 基于神经网络的分布式表示
2. 分布式表示
如节1.2所述,分布式表示主要分为三种方式。这三种方式使用了不同的技术手段,但都是基于分布假说,核心思想由两部分组成:
- 选择一种方式描述上下文
- 选择一种模型刻画目标词与上下文的关系
2.1 基于矩阵的分布式表示
这类方法需要构建一个“词-上下文”矩阵,每行对应一个词,每列表示一种不同的上下文,矩阵中的每个元素对应相关词和上下文的共现次数。该方法分为以下三步:
| 步骤 | 内容 | 解释 |
|---|---|---|
| step1 | 选取上下文 | 法1:将词所在的文档作为上下文,形成“词-文档”矩阵 法2:将词附近的上下文中的词(例如上下文窗口中的5个词)作为上下午,形成“词-词”矩阵 法3:将词附近的n元词组作为上下文,形成“词-n元组”矩阵 |
| step2 | 确定矩阵中各元素的值 | 常用的有tf-idf、PMI和直接取log |
| step3 | 矩阵分解 | 奇异值分解(SVD)、非负矩阵分解(NMF)、典型关联分析(CCA)、HPCA |
LSA:使用“词-文档”矩阵,tf-idf作为元素值,并用SVD分解
Global Vector(GloVe):使用“词-词”矩阵进行分解从而得到词向量
2.1.1 GloVe
正如论文的标题而言,GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。总体上看,GloVe模型是一种对“词-词”矩阵进行分解从而得到词表示的方法。
步骤
GloVe的实现可以分为三步:
- 构建共现矩阵: 根据语料库构建共现矩阵 X X X,矩阵第 i 行与第 j 列的值为 v i v_i vi 与 v j v_j vj 在特定大小的上下文窗口的共现次数 x i j x_{ij} xij 。一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离d,提出了一个衰减函数: d e c a y = 1 / d decay = 1/d decay=1/d 用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小。
- 构建词向量和共现矩阵之间的共现关系: 论文作者提出下面的公式可以近似表达二者的关系。 l o g ( x i j ) = w i T w ~ j + b i ( 1 ) + b j ( 2 ) log(x_{ij})=w_i^T\tilde{w}_j+b_i^{(1)}+b_j^{(2)} log(xij)=wiTw~j+bi(1)+bj(2) 其中 w i w_i wi 为词 v i v_i vi 作为目标词时的词向量, w ~ j \tilde{w}_j w~j 为词 v j v_j vj 作为上下文时的词向量 b ( 1 ) b^{(1)} b(1) 、 b ( 2 ) b^{(2)} b(2)为针对词表中各词的偏移向量。
- 在矩阵分解步骤,GloVe模型借鉴了推荐系统中的基于隐因子分解(Latent Factor Model)的方法,在计算重构误差时,只考虑共现次数非零的矩阵元素,同时对矩阵中的行和列加入了偏移项。具体为最小化下式:
L o s s = ∑ i , j ∈ V , x i j ≠ 0 f ( x i j ) ( w i T w ~ j + b i ( 1 ) + b j ( 2 ) − l o g ( x i j ) ) 2 Loss=\sum_{i,j \in V,x_{ij} \neq 0}f(x_{ij})(w_i^T\tilde{w}_j+b_i^{(1)}+b_j^{(2)}-log(x_{ij}))^2 Loss=i,j∈V,xij=0∑f(xij)(wiTw~j+bi(1)+bj(2)−log(xij))2
其中, f ( x ) f(x) f(x)是一个加权函数,对低频的共现词对进行衰减,减少低频噪声带来的误差,定义为:
f ( x ) = { ( x x m a x ) α x < x m a x 1 其他情况 f(x) = \begin{cases} (\frac{x}{x_{max}})^\alpha& \text{$x
设计这个函数有三个要求:
(1)共现单词多的权重要大于共现次数少的权重
(2)这个权重不应该过大,所以大于某个值之后不应该再增加
(3)如果两个单词的共现次数为0,不应该参与到损失函数的计算当中。即 f ( 0 ) = 0 f(0)=0 f(0)=0。
共现关系的构建
首先定义三个概念。
- X i j X_ij Xij表示单词 j j j 出现在单词 i i i 的上下文中的次数;
- X i X_i Xi表示单词 i i i 的上下文中所有单词出现的总次数,即 X i = ∑ k X i k X_i = \sum_k X_{ik} Xi=∑kXik
- P i j = P ( j ∣ i ) = X i j / X i P_{ij}=P(j|i)=X_{ij}/X_i Pij=P(j∣i)=Xij/Xi ,即单词 j j j 出现在单词 i i i 的上下文中的概率。

理解这个表格的重点在最后一行,它表示的是两个概率的比值(ratio),我们可以使用它观察出两个单词 i i i 和 j j j 相对于单词 k k k 哪个更相关(relevant)。比如,ice和solid更相关,而stream和solid明显不相关,于是我们会发现 P ( s o l i d ∣ i c e ) / P ( s o l i d ∣ s t e a m ) P(solid|ice)/P(solid|steam) P(solid∣ice)/P(solid∣steam) 比1大更多。同样的gas和steam更相关,而和ice不相关,那么 P ( g a s ∣ i c e ) / P ( g a s ∣ s t e a m ) P(gas|ice)/P(gas|steam) P(gas∣ice)/P(gas∣steam) 就远小于1;当都有关(比如water)或者都没有关(fashion)的时候,两者的比例接近于1;这个是很直观的。因此,以上推断可以说明通过概率的比例而不是概率本身去学习词向量可能是一个更恰当的方法,因此下文所有内容都围绕这一点展开。
于是为了捕捉上面提到的概率比例,我们可以构造如下函数:
F ( w i , w j , w ~ k ) = P i k P j k F(w_i,w_j,\tilde{w}_k)=\frac{P_{ik}}{P_{jk}} F(wi,wj,w~k)=PjkPik
因为向量空间是线性结构的,所以要表达出两个概率的比例差,最简单的办法是作差,于是我们得到
F ( w i − w j , w ~ k ) = P i k P j k F(w_i-w_j,\tilde{w}_k)=\frac{P_{ik}}{P_{jk}} F(wi−wj,w~k)=PjkPik
这时我们发现公式5的右侧是一个数量,而左侧则是一个向量,于是我们把左侧转换成两个向量的内积形式:
F ( ( w i − w j ) T w ~ k ) = P i k P j k F((w_i-w_j)^T\tilde{w}_k)=\frac{P_{ik}}{P_{jk}} F((wi−wj)Tw~k)=PjkPik
我们知道 X X X 是个对称矩阵,单词和上下文单词其实是相对的,也就是如果我们做如下交换:
F ( ( w i − w j ) T w ~ k ) = F ( w i T w ~ k ) F ( w j T w ~ k ) F((w_i-w_j)^T\tilde{w}_k)=\frac{F(w_i^T\tilde{w}_k)}{F(w_j^T\tilde{w}_k)} F((wi−wj)Tw~k)=F(wjTw~k)F(wiTw~k)
所以
F ( w i T w ~ k ) = P i k = X i k X i F(w_i^T\tilde{w}_k)=P_{ik}=\frac{X_{ik}}{X_i} F(wiTw~k)=Pik=XiXik
令 F F F 为 e x p ( ) exp() exp() ,则上公式
w i T w ~ k = l o g ( P i k ) = l o g ( X i k ) − l o g ( X i ) w_i^T\tilde{w}_k = log(P_{ik})=log(X_{ik})-log(X_i) wiTw~k=log(Pik)=log(Xik)−log(Xi)
所以
w i T w ~ k + b i = l o g ( X i k ) w_i^T\tilde{w}_k +b_i=log(X_{ik}) wiTw~k+bi=log(Xik)
根据对称性
w i T w ~ k + b i + b k = l o g ( X i k ) w_i^T\tilde{w}_k +b_i+b_k=log(X_{ik}) wiTw~k+bi+bk=log(Xik)
训练方法
虽然很多人声称GloVe是一种无监督(unsupervised learing)的学习方式(因为它确实不需要人工标注label),但其实它还是有label的,这个label就是公式2中的 l o g ( X i j ) log(X_{ij}) log(Xij),而公式2中的向量 w w w 和 w ~ \tilde{w} w~ 就是要不断更新/学习的参数,所以本质上它的训练方式跟监督学习的训练方法没什么不一样,都是基于梯度下降的。具体地,这篇论文里的实验是这么做的:采用了AdaGrad的梯度下降算法,对矩阵 X X X 中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。最终学习得到的是两个vector是 w w w 和 w ~ \tilde{w} w~,因为 X X X 是对称(symmetric),所以从原理上讲 w w w 和 w ~ \tilde{w} w~ 是也是对称的,他们唯一的区别是初始化的值不一样,而导致最终的值不一样。所以这两者其实是等价的,都可以当成最终的结果来使用。但是为了提高鲁棒性,我们最终会选择两者之和 w + w ~ w+\tilde{w} w+w~ 作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
2.2 基于聚类的分布式表示
这类方法通过聚类手段构建词与其上下文之间的关系。其中最经典的方法就是布朗聚类(Brown clustering).
2.2.1 布朗聚类
布朗聚类是一种层级聚类方法,聚类结果为每个词的多层类别体系。因此可以根据两个词的公共类别判断这两个词的语义相似度。具体而言,布朗聚类需要最大化以下似然,其中, c i c_i ci 为词 w i w_i wi 对应的类别:
P ( w i ∣ w i − 1 ) = P ( w i ∣ c i ) P ( c i ∣ c i − 1 ) P(w_i|w_{i-1})=P(w_i|c_i)P(c_i|c_{i-1}) P(wi∣wi−1)=P(wi∣ci)P(ci∣ci−1)
布朗聚类只考虑了相邻词之间的关系,也就是说,每个词只使用它的上一个词,作为上下文信息
2.3 基于神经网络的分布式表示
同样基于分布假说,核心为上下文的表示以及上下文与目标词之间关系的建模。
使用语言模型是构建上下文与目标词之间关系的常用思路。早期的词向量只是神经网络语言模型的副产品。同时,神经网络语言模型对后期词向量的发展方向有着决定性的左右。
神经网络词向量表示技术主要有以下几种
| 模型 | 上下文的表示 | 目标词与其上下文关系 |
|---|---|---|
| skip-gram | 上下文中某一个词的词向量 | 目标词预测上下文 |
| CBOW | 上下文各词词向量的平均值 | 上下文预测目标词 |
| Order | 上下文各词词向量的拼接 | 上下文预测目标词 |
| LBL | 上下文各词的语义组合 | 上下文预测目标词 |
| NNLM | 上下文各词的语义组合 | 上下文预测目标词 |
| C&W | 上下文各词与目标词的语义组合 | 上下文和目标词联合打分 |
除此之外,还有RNN语言模型等。
2.3.1 word2vec
如果 x x x 是一个单词, y y y 是这个单词的上下文,那么判断 x , y x,y x,y 是否符合人类语言规律的模型 f ( x , y ) f(x,y) f(x,y) 便称为语言模型。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量。

首先说明一点:隐层的激活函数其实是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处),我们要训练这个神经网络,用反向传播算法,本质上是链式求导,在此不展开说明了,
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个 x 的 one-hot encoder: [1,0,0,…,0],对应刚说的那个词语『吴彦祖』,则在输入层到隐含层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐含层节点数是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
- 如果是用一个词语作为输入,来预测它周围的上下文,那这个模型叫做『Skip-gram 模型
- 而如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 『CBOW 模型』
CBOW
输入上下文单词,然后对特征进行平均,输入output layer进行分类

Skip-gram
输入目标单词,将特征送入output layer 预测一个单词是否为它的上下文

加速技巧
-
负采样(negative sampling):本质是预测总体类别的一个子集。把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本。优化目标变为了:最大化正样本的概率,同时最小化负样本的概率。
-
hierarchical softmax:本质是把 N 分类问题变成 log(N)次二分类。使用softmax进行分类,对于大规模预料来说计算代价太高,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。
2.3.2 Bert
BERT(Bidirectional Encoder Representations from Transformers)近期提出之后,作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度,可以说是近年来自残差网络最优突破性的一项技术了。论文的主要特点以下几点:
- 使用了 Transformer 作为算法的主要框架,Transformer 能更彻底的捕捉语句中的双向关系;
- 使用了Mask Language Model(MLM) [3] 和 Next Sentence Prediction(NSP) 的多任务训练目标;
- 使用更强大的机器训练更大规模的数据,使BERT的结果达到了全新的高度,并且Google开源了BERT模型,用户可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
BERT的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。在以后特定的NLP任务中,我们可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。
网络架构
BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构,其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
Transformer的网络架构如下图所示,Transformer是一个encoder-decoder的结构,由若干个编码器和解码器堆叠形成。图的左侧部分为编码器,由Multi-Head Attention和一个全连接组成,用于将输入语料转化成特征向量。右侧部分是解码器,其输入为编码器的输出以及已经预测的结果,由Masked Multi-Head Attention, Multi-Head Attention以及一个全连接组成,用于输出最后结果的条件概率。

上图中的左侧部分是一个Transformer Block,对应到下图中的一个“Trm”
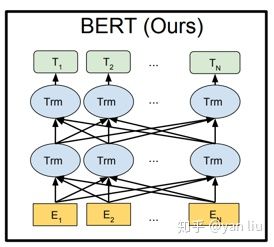
BERT提供了简单和复杂两个模型,对应的超参数分别如下:
- B e r t b a s e Bert_{base} Bertbase: L=12,H=768,A=12,参数总量110M;
- B e r t l a r g e Bert_{large} Bertlarge: L=24,H=1024,A=16,参数总量340M;
在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量,filter的尺寸是4H。
对比GPT、ELMo的优势
GPT、ELMo的网络结构图如下所示:
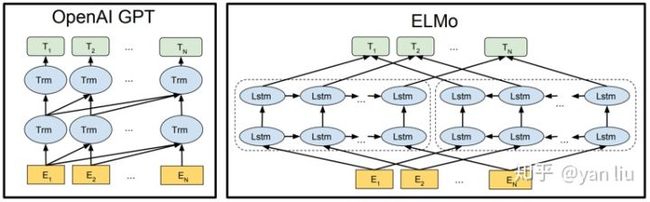
BERT对比这两个算法的优点是只有BERT表征会基于所有层中的左右两侧语境。BERT能做到这一点得益于Transformer中Attention机制将任意位置的两个单词的距离转换成了1。
3. 小结
- 选择一个合适领域的语料,再次前提下,语料的规模越大越好。使用大规模的语料进行训练,可以普遍提升词向量的性能,如果使用领域内的语料,对同领域的任务才会有显著的提升。
- 选择一个合适的模型。复杂的模型相比简单的模型,在较大的语料中才有优势。简单的模型在绝大多数情况下已经够好。预测目标词的模型比目标词与上下文呈组合关系的模型在多个任务中拥有更好的性能。
- 训练时,迭代优化的终止条件最好根据具体任务的验证集来判断,或者近似的选取其他类似的任务作为指标,但是不应该选用训练词向量时的损失函数。
- 词向量的维度一般需要选择50维及以上,特别衡量词向量的语言学特性时,词向量的维度越大,效果越好。
- 做NLP任务用到词向量的时候,要么选择使用别人训练好的同语料内容领域的词向量,要么训练自己的词向量,个人认为,前者效果更好。
参考文献
参考链接1:一只松鼠,词向量表示方法梳理,https://zhuanlan.zhihu.com/p/46026058
参考链接2:来斯惟,基于神经网络的词和文档语义向量表示方法研究, https://arxiv.org/ftp/arxiv/papers/1611/1611.05962.pdf
参考链接3:穆文,[NLP] 秒懂词向量Word2vec的本质,https://zhuanlan.zhihu.com/p/26306795
参考链接4:大师兄,词向量之BERT,https://zhuanlan.zhihu.com/p/48612853