(很全面)综述---图像处理中的注意力机制
原文链接:https://blog.csdn.net/xys430381_1/article/details/89323444
重磅好文:微软亚研:对深度神经网络中空间注意力机制的经验性研究
论文:An Empirical Study of Spatial Attention Mechanisms in Deep Networks
论文阅读: 图像分类中的注意力机制(attention)
介绍了Spatial transformer networks、Residual Attention Network、Two-level Attention、SENet、Deep Attention Selective Network
计算机视觉中的注意力机制(Visual Attention)
快速理解图像处理中注意力机制的应用
主要讲解了2017CPVR文章:Residual Attention Network for Image Classification
Attention机制的文章总结
计算机视觉技术self-attention最新进展
ECCV2018–注意力模型CBAM
【论文复现】CBAM: Convolutional Block Attention Module
BAM: Bottleneck Attention Module算法笔记
基于注意力机制的细腻度图像分类
讲解RACNN
此外还有MACNN等方法。
目录
- 概要
-
- 为什么需要视觉注意力
- 注意力分类与基本概念
- 软注意力
-
- The application of two-level attention models in deep convolutional neural network for fine-grained image classification---CVPR2015
-
- 1. Spatial Transformer Networks(空间域注意力)---2015 nips
- 2. SENET (通道域)---2017CPVR
- 3. Residual Attention Network(混合域)---2017
- Non-local Neural Networks, CVPR2018
- Interaction-aware Attention, ECCV2018
- CBAM: Convolutional Block Attention Module(通道域+空间域), ECCV2018
- DANet:Dual Attention Network for Scene Segmentation(空间域+通道域), CPVR2019
-
- CCNet
- OCNet
- GCNet:Non-local Networks Meet Squeeze-Excitation Networks and Beyond
- 注意增强型卷积
- PAN: Pyramid Attention Network for Semantic Segmentation(层域)---CVPR2018
- Multi-Context Attention for Human Pose Estimation
- Tell Me Where to Look: Guided Attention Inference Network
- 硬注意力
-
- 一种通过引入硬注意力机制来引导学习视觉回答任务的研究
- 1. Diversified visual attention networks for fine-grained object classification---2016
- 2. Deep networks with internal selective attention through feedback connections (通道域)---NIPS 2014
- 3.Fully Convolutional Attention Networks for Fine-Grained Recognition
- 4 . 时间域注意力(RNN)
- 自注意力
-
-
- RelatedWorks
- 自注意力的缺点和改进策略
- 自注意力小结
-
概要
为什么需要视觉注意力
计算机视觉(computer vision)中的注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。为什么要忽略无关信息呢?
注意力分类与基本概念
神经网络中的「注意力」是什么?怎么用?这里有一篇详解
该文分为: 硬注意力、软注意力、此外,还有高斯注意力、空间变换
就注意力的可微性来分:
- Hard-attention,就是0/1问题,哪些区域是被 attentioned,哪些区域不关注.硬注意力在图像中的应用已经被人们熟知多年:图像裁剪(image cropping)
硬注意力(强注意力)与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。(参考文章:Mnih, Volodymyr, Nicolas Heess, and AlexGraves. “Recurrent models of visual attention.” Advances inneural information processing systems. 2014.)
硬注意力可以用Python(或Tensorflow)实现为:
g = I[y:y+h, x:x+w]
- 1
上述存在的唯一的问题是它是不可微分的;你如果想要学习模型参数的话,就必须使用分数评估器(score-function estimator)关于这一点,我的前一篇文章中有对其的简要介绍。
- Soft-attention,[0,1]间连续分布问题,每个区域被关注的程度高低,用0~1的score表示.

软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
然而,这种类型的软注意力在计算上是非常浪费的。输入的黑色部分对结果没有任何影响,但仍然需要处理。同时它也是过度参数化的:实现注意力的sigmoid 激活函数是彼此相互独立的。它可以一次选择多个目标,但实际操作中,我们经常希望具有选择性,并且只能关注场景中的一个单一元素。由DRAW和空间变换网络(Spatial Transformer Networks)引入的以下两种机制很好地别解决了这个问题。它们也可以调整输入的大小,从而进一步提高性能。
就注意力关注的域来分:
- 空间域(spatial domain)
- 通道域(channel domain)
- 层域(layer domain)
- 混合域(mixed domain)
- 时间域(time domain):还有另一种比较特殊的强注意力实现的注意力域,时间域(time domain),但是因为强注意力是使用reinforcement learning来实现的,训练起来有所不同
一个概念:Self-attention自注意力,就是 feature map 间的自主学习,分配权重(可以是 spatial,可以是 temporal,也可以是 channel间)
软注意力
The application of two-level attention models in deep convolutional neural network for fine-grained image classification—CVPR2015
1. Spatial Transformer Networks(空间域注意力)—2015 nips
Spatial Transformer Networks(STN)模型[4]是15年NIPS上的文章,这篇文章通过注意力机制,将原始图片中的空间信息变换到另一个空间中并保留了关键信息。
这篇文章认为之前pooling的方法太过于暴力,直接将信息合并会导致关键信息无法识别出来,所以提出了一个叫空间转换器(spatial transformer)的模块,将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。
spatial transformer其实就是注意力机制的实现,因为训练出的spatial transformer能够找出图片信息中需要被关注的区域,同时这个transformer又能够具有旋转、缩放变换的功能,这样图片局部的重要信息能够通过变换而被框盒提取出来。

比如这个直观的实验图:
(a)列是原始的图片信息,其中第一个手写数字7没有做任何变换,第二个手写数字5,做了一定的旋转变化,而第三个手写数字6,加上了一些噪声信号;
(b)列中的彩色边框是学习到的spatial transformer的框盒(bounding box),每一个框盒其实就是对应图片学习出来的一个spatial transformer;
©列中是通过spatial transformer转换之后的特征图,可以看出7的关键区域被选择出来,5被旋转成为了正向的图片,6的噪声信息没有被识别进入。
2. SENET (通道域)—2017CPVR

中间的模块就是SENet的创新部分,也就是注意力机制模块。这个注意力机制分成三个部分:挤压(squeeze),激励(excitation),以及scale(attention)。
流程:
- 将输入特征进行 Global AVE pooling,得到 11 Channel
- 然后bottleneck特征交互一下,先压缩 channel数,再重构回channel数
- 最后接个 sigmoid,生成channel 间0~1的 attention weights,最后 scale 乘回原输入特征
详见《论文阅读笔记—SENET》
3. Residual Attention Network(混合域)—2017
文章中注意力的机制是软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
文提出的注意力mask,不仅仅只是对空间域或者通道域注意,这种mask可以看作是每一个特征元素(element)的权重。通过给每个特征元素都找到其对应的注意力权重,就可以同时形成了空间域和通道域的注意力机制。
很多人看到这里就会有疑问,这种做法应该是从空间域或者通道域非常自然的一个过渡,怎么做单一域注意力的人都没有想到呢?原因有:
- 如果你给每一个特征元素都赋予一个mask权重的话,mask之后的信息就会非常少,可能直接就破坏了网络深层的特征信息;
- 另外,如果你可以加上注意力机制之后,残差单元(Residual Unit)的恒等映射(identical mapping)特性会被破坏,从而很难训练。
该文章的注意力机制的创新点在于提出了残差注意力学习(residual attention learning),不仅只把mask之后的特征张量作为下一层的输入,同时也将mask之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。

文章中模型结构是非常清晰的,整体结构上,是三阶注意力模块(3-stage attention module)。每一个注意力模块可以分成两个分支(看stage2),上面的分支叫主分支(trunk branch),是基本的残差网络(ResNet)的结构。而下面的分支是软掩码分支(soft mask branch),而软掩码分支中包含的主要部分就是残差注意力学习机制。通过下采样(down sampling)和上采样(up sampling),以及残差模块(residual unit),组成了注意力的机制。
模型结构中比较创新的残差注意力机制是:
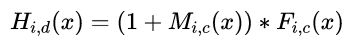
H是注意力模块的输出,F是上一层的图片张量特征,M是软掩码的注意力参数。这就构成了残差注意力模块,能将图片特征和加强注意力之后的特征一同输入到下一模块中。F函数可以选择不同的函数,就可以得到不同注意力域的结果:

-
f1是对图片特征张量直接sigmoid激活函数,就是混合域的注意力;
-
f2是对图片特征张量直接做全局平均池化(global average pooling),所以得到的是通道域的注意力(类比SENet);
-
f3 是求图片特征张量在通道域上的平均值的激活函数,类似于忽略了通道域的信息,从而得到空间域的注意力。
Non-local Neural Networks, CVPR2018
FAIR的杰作,主要 inspired by 传统方法用non-local similarity来做图像 denoise
主要思想也很简单,CNN中的 convolution单元每次只关注邻域 kernel size 的区域,就算后期感受野越来越大,终究还是局部区域的运算,这样就忽略了全局其他片区(比如很远的像素)对当前区域的贡献。
所以 non-local blocks 要做的是,捕获这种 long-range 关系:对于2D图像,就是图像中任何像素对当前像素的关系权值;对于3D视频,就是所有帧中的所有像素,对当前帧的像素的关系权值。
网络框架图也是简单粗暴:
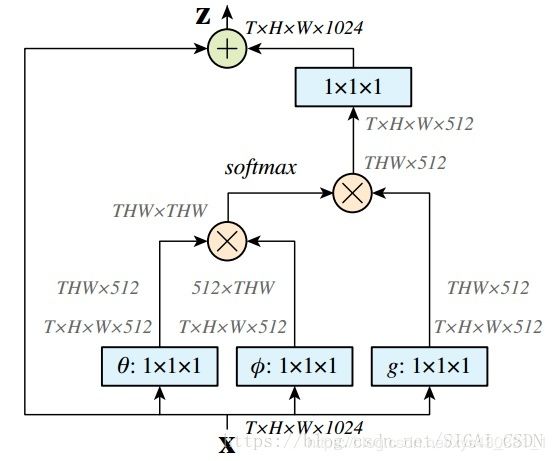
文中有谈及多种实现方式,在这里简单说说在DL框架中最好实现的 Matmul 方式:
- 首先对输入的 feature map X 进行线性映射(说白了就是 1x1x1 卷积,来压缩通道数),然后得到 θ , ϕ , g θ , ϕ , g θ , ϕ , g θ,ϕ,gθ,ϕ,g \theta, \quad \phi, \quad g θ,ϕ,gθ,ϕ,gθ,ϕ,glt−1 位置中产生的图片信息,而下一个时刻,随着t的增加,采样的位置又开始变化,至于l随着t该怎么变化,这就是需要使用增强学习来训练的东西了。
自注意力
自注意力机制在计算机视觉中的应用
用Attention玩转CV,一文总览自注意力语义分割进展自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
在神经网络中,我们知道卷积层通过卷积核和原始特征的线性结合得到输出特征,由于卷积核通常是局部的,为了增加感受野,往往采取堆叠卷积层的方式,实际上这种处理方式并不高效。同时,计算机视觉的很多任务都是由于语义信息不足从而影响最终的性能。自注意力机制通过捕捉全局的信息来获得更大的感受野和上下文信息。
自注意力机制 (self-attention)[1] 在序列模型中取得了很大的进步;另外一方面,上下文信息(context information)对于很多视觉任务都很关键,如语义分割,目标检测。自注意力机制通过(key, query, value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。接下来首先介绍几篇相应的工作,然后分析相应的优缺点以及改进方向。
RelatedWorks
Attention is all you need [1] 是第一篇提出在序列模型中利用自注意力机制取代循环神经网络的工作,取得了很大的成功。其中一个重要的模块是缩放点积注意力模块(scaled dot-product attention)。文中提出(key,query, value)三元组捕捉长距离依赖的建模方式,如下图所示,key和query通过点乘的方式获得相应的注意力权重,最后把得到的权重和value做点乘得到最终的输出。

Non-localneural network [2] 继承了(key, query, value) 三元组的建模方式, 提出了一个高效的non-local 模块, 如下图所示。在Resnet网络中加入non-local模块后无论是目标检测还是实例分割,性能都有一个点以上的提升(mAP),这说明了上下文信息建模的重要性。

Danet [3]是来自中科院自动化的工作,其核心思想就是通过上下文信息来监督语义分割任务。作者采用两种方式的注意力形式,如下图所示,分别是spatial和 channel上,之后进行特征融合,最后接语义分割的head 网络。思路上来说很简单,也取得了很好的效果。

Ocnet[4]是来自微软亚洲研究所的工作。同样它采用(key, query, value)的三元组,通过捕捉全局的上下文信息来更好的监督语义分割任务。与Danet [3]不同的是它仅仅采用spatial上的信息。最后也取得了不错的结果。

DFF [5] 是来自微软亚洲研究所视觉计算组的工作。如下图所示,它通过光流来对视频不同帧之间的运动信息进行建模, 从而提出了一个十分优雅的视频检测框架DFF。其中一个很重要的操作是warp, 它实现了点到点之间的对齐。在此以后出现了很多关于视频检测的工作,如, FGFA[6],Towards High Performance [7]等,他们大部分都是基于warp这个特征对其操作。由于光流网络的不准确性以及需要和检测网络进行联合训练,这说明现在视频检测中的光流计算其实不准确的。如何进行更好的建模来代替warp操作,并且起到同样的特征对其的作用是很关键的。通常而言我们假设flow运动的信息不会太远,这容易启发我们想到通过每个点的邻域去找相应的运动后的特征点,具体做法先不介绍了,欢迎大家思考(相关操作和自注意力机制)。

自注意力的缺点和改进策略
前面主要是简单的介绍了自注意力机制的用途,接下来分析它的缺点和相应的改进策略,由于每一个点都要捕捉全局的上下文信息,这就导致了自注意力机制模块会有很大的计算复杂度和显存容量。如果我们能知道一些先验信息,比如上述的特征对其通常是一定的邻域内,我们可以通过限制在一定的邻域内来做。另外还有如何进行高效的稀疏化,以及和图卷积的联系,这些都是很开放的问题,欢迎大家积极思考。
接下来介绍其他的一些改进策略,Senet[9] 启发我们channel上的信息很重要,如下图所示。
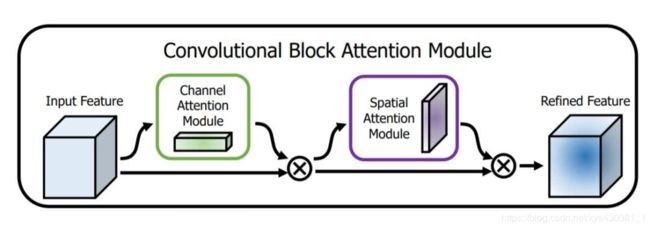
CBAW [10] 提出了结合spatial和channel的模块,如下图所示,在各项任务上也取得很好的效果。
最后介绍一篇来自百度IDL的结合channel as spatial的建模方式的工作 [11]。本质上是直接在(key, query, value)三元组进行reshape的时候把channel的信息加进去,但是这带来一个很重要的问题就是计算复杂度大大增加。我们知道分组卷积是一种有效的降低参数量的方案,这里也采用分组的方式。但是即使采用分组任然不能从根本上解决计算复杂度和参数量大的问题,作者很巧妙的利用泰勒级数展开后调整计算key, query, value的顺序,有效的降低了相应的计算复杂度。下表是优化后的计算量和复杂度分析,下图是CGNL模块的整体框架。
自注意力小结
自注意力机制作为一个有效的对上下文进行建模的方式,在很多视觉任务上都取得了不错的效果。同时,这种建模方式的缺点也是显而易见的,一是没有考虑channel上信息,二是计算复杂度仍然很大。相应的改进策,一方面是如何进行spatial和channel上信息的有效结合,另外一方面是如何进行捕捉信息的稀疏化,关于稀疏的好处是可以更加鲁棒的同时保持着更小的计算量和显存。最后,图卷积作为最近几年很火热的研究方向,如何联系自注意力机制和图卷积,以及自注意力机制的更加深层的理解都是未来的很重要的方向。