分布式深度神经网络(DDNN)
本文出自论文 Distributed Deep Neural Networks over the Cloud,the Edge and End Devices
,是一种分布式的深度神经网络,可以在本地终端设备、边缘和云端进行网络推理。
一、简介
分布式深度神经网络不仅能够允许在云端进行深度神经网络的推理,还允许在边缘和终端设备上使用神经网络的浅层部分进行快速、本地化推理。在可伸缩的分布式计算层次结构的支持下,DDNN可以在神经网络规模上进行扩展和在地理范围上扩展。由于分布式的性质,DDNNs增强了传感器融合、系统容错性和数据隐私性。在实现DDNN时,我们将DNN部分映射到分布式计算层次结构下。通过联合训练这些部分,我们最小化设备的通信和资源使用量,最大化利用云计算中提取的特性。DDNN可以利用传感器的地理多样性来提高目标识别的准确性和降低通信成本。在实验中,与传统的将原始传感器数据在云中进行处理的方法相比,DDNN局部处理终端设备上的大部分传感器数据,同时获得了较高的精度。
二、提出原因
- 目前机器学习系统在终端设备上的状态有着不太令人满意的选择:
(1)将输入传感器中的数据卸载到云端的大型神经网络模型中,并承担着相应的通信成本、延迟问题和隐私问题;
(2)使用简单的机器学习模型,如SVM,直接在终端设备上进行分类,会导致系统的精确度下降。因此,使用由云端、边缘和设备组成的分层分布式计算结构,对于基于地理分布式物理网设备的大规模智能任务,具有很多内在优势,例如:支持协调中心和本地决策、提供系统可扩展性。 - 这种分布式方法的一个例子是将终端设备的小型神经网络模型(参数数量较少)和云端中较大的神经网络模型(参数数量较多)进行结合。终端设备上的小型模型可以快速地进行初始特征提取,在模型可信的情况下还可以进行分类任务。然后,终端设备处理后的数据会传递到云端的大型网络模型中,进行下一步的特征处理和最终分类。这种方法与传统的神经网络模型相比,具有通信成本低、精确度高的优点。另外,传递到云端的数据已经被终端设备所处理过,不是原始的传感器数据,因此系统可以提供更好的隐私保护。
- 这种基于计算层次结构的分布式方法也具有挑战性:
(1)像嵌入式传感器节点这样的终端设备通常内存和电池预算有限,在满足所需精度和能量约束的设备上安装网络模型较为困难;
(2)在计算节点之间传输中间结果时,在计算层次上直接划分神经网络模型可能会产生很大的通信成本;
(3)当使用不同终端设备上的多个传感器输入时,需要将它们聚合在一起才能实现单个分类目标,一个好的神经网络结构将能够支持这样的传感器融合;
(4)在云端、边缘和设备上的多个模型需要联合学习,以便协调决策;
(5)一个分布式神经网络的逐层处理并不能直接为神经网络早期的快速推理(如终端设备)提供一种处理机制;
(6)在给定的分布式计算层下,需要在模型的准确性(以及相关的模型大小)和上一层的通信成本之间进行平衡。
三、总体方案
1. DDNN架构
一种新的DDNN框架和它将DNN的部分映射到分布式计算层次结构。在DDNN中,我们使用BNNs,eBNNs等来容纳终端设备,使它们可以与边缘和云中的神经网络层进行联合训练。在分布式神经网络中,退出点被放置在物理边界上(终端设备的最后一个神经网络层和分布式计算层次结构的接下来的较高层的第一个神经网络层之间)。能够被提前分类的样本在本地退出,从而实现较低的响应延迟,并将通信保存到下一个物理边界。
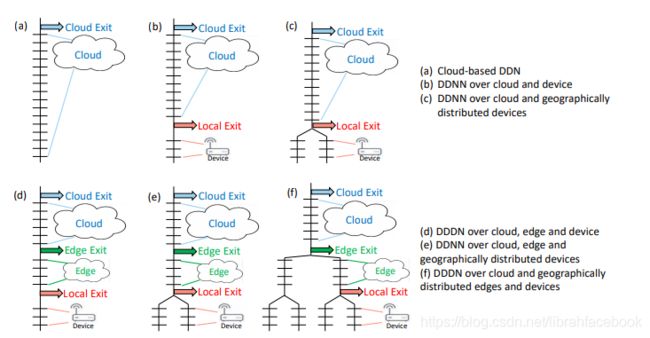
2. DDNN聚合方法
(1)最大池化(Max pooling),通过获取每个分量的最大值来聚合输入向量;
v ^ j = max 1 ⩽ i ⩽ n v i j \hat{v}_j=\max_{1\leqslant i \leqslant n} v_{ij} v^j=1⩽i⩽nmaxvij
(2)平均池化(Average pooling),通过获取每个分量的平均值来聚合输入向量;
v ^ j = ∑ i = 1 n v i j n \hat{v}_j=\sum_{i=1}^n \frac {v_{ij}}{n} v^j=i=1∑nnvij
(3)连接(Concatenation),将输入向量连接在一起,保留所有对高层(云)有用的信息,这将扩展输出向量的维数。为了将输出向量映射回输入向量相同的维数,需要添加一个额外的线性层。
3. DDNN训练方法
我们提出了一种方法,可以在可部署在分布式计算层次结构上的深层网络上训练和执行前馈推理。在训练时,将每个出口点的损失函数值在反向传播过程中进行结合,使整个网络可以进行联合训练,每个出口点相对于其深度可以获得较好的精度。为了训练DDNN,我们构造了一个联合优化问题,即使每一个出口点损失函数的加权和最小化。
我们使用softmax cross entropy损失函数来作为优化目标,对于每个出口点,其损失函数可表达为:
L ( y ^ , y ; θ ) = − 1 ∣ C ∣ ∑ c ϵ C y c l o g y c ^ ; L(\hat{y},y;\theta)=-\frac{1}{\left|C\right|}\sum_{c\epsilon C}y_c log \hat{y_c}; L(y^,y;θ)=−∣C∣1cϵC∑yclogyc^;
预测输出向量 y ^ \hat{y} y^为:
y ^ = s o f t m a x ( z ) = e z ∑ c ϵ C e z c ; \hat{y}=softmax(z)=\frac{e^z}{\sum_{c \epsilon C}e^{z_c}}; y^=softmax(z)=∑cϵCezcez;
输出z为网络层的最终输出结果:
z = f e x i t n ( x ; θ ) ; z=f_{exit_n}(x;\theta); z=fexitn(x;θ);
最终整个网络的优化目标损失函数为:
L ( y ^ , y ; θ ) = ∑ n = 1 N w n L ( y ^ e x i t n , y ; θ ) L(\hat{y},y;\theta)=\sum_{n=1}^{N} w_nL(\hat{y}_{exit_n},y;\theta) L(y^,y;θ)=n=1∑NwnL(y^exitn,y;θ)
4. DDNN推理过程
DDNN将已经训练好的DNN映射到本地、边缘和云端分布的异构物理设备上。利用设备推理后的退出点,我们可以对本地网络可信度高的样本进行分类,无需向云端发送任何信息。对于更多无法处理的样本,我们将中间DNN输出(直到本地退出点)发送到云端,在云中使用额外的神经网络层执行进一步的推理,并做出最终的分类决策任务。DDNN也可以扩展到地理分布的多个终端设备,一起来做分类决策。每个终端设备执行各自的本地计算,但它们的输出在本地退出点之间进行聚合。由于整个DDNN是跨所有终端设备和出口点进行联合训练的,所以网络会自动将输入进行聚合,以达到分类精度的最大化。DDNN通过在终端设备和云之间的分布式计算层次结构中使用边缘层,它从终端设备获取输出,如果可能的话执行聚合和分类,如果需要更多处理则将中间输出传递给云。
在DDNN中,使用多个预先设置好的出口阈值T作为对样本预测的信心度量,分别在几个阶段中执行推理。在一个给定的退出点,如果预测期对结果不自信,系统回落到一个更高的出口点的层次直到到达最后的出口点,此时总是执行分类任务。
每个出口点的样本信息熵定义为:
η ( x ) = − ∑ i = 1 ∣ C ∣ x i l o g x i l o g ∣ C ∣ \eta (x)=- \sum_{i=1}^{|C|} \frac{x_i logx_i}{log|C|} η(x)=−i=1∑∣C∣log∣C∣xilogxi
5.通信成本
本地的终端设备和云端聚合器的总通信成本为:
c = 4 × ∣ C ∣ + ( 1 − l ) × f × o 8 c=4 \times |C|+(1-l)\times \frac{f \times o}{8} c=4×∣C∣+(1−l)×8f×o
其中, l l l是本地退出样本的比例, C C C是所有可能类别标签的集合, f f f是过滤器的数量, o o o是在终端设备上对于最后一个神经网络层单个滤波器的输出大小。第一项假设每个类都有一个浮点数,它表示样本从终端设备传输到本地聚合器属于该类的概率。不管样本在本地退出还是在后面的出口点退出,都会发生这个步骤。第二项是当样本在云端而不是本地退出时终端设备和云之间的通信占据总时间的 ( 1 − l ) (1-l) (1−l)部分。
四、实验分析
1.精度衡量
对于DDNN的不同出口点,我们采用了不同的精度测量如下:
(1)本地化精度是DDNN在本地出口退出全部样本时的精度;
(2)边缘精度是DDNN在边缘出口点退出全部样本的精度;
(3)云端精度是DDNN在云端出口点退出全部样本的精度;
(4)总体精度是在每一个出口点退出一定比例的样本的精度。在每个出口点被分类的样本都由那个出口点的信息熵阈值T所决定;
(5)个体精度是终端设备神经网络模型分别从DDNN训练后的精度,在评价体系中,通过使用单个神经网络模型对所有样本进行分类,而不依赖于DDNN的本地或云端出口点,从而计算出每个设备的个体精度。
2.系统评估
(1)DDNNs允许多个终端设备协同工作,以提高本地和云端出口点的准确性;
(2)DDNNs通过将难处理的样本传递到云端无缝地扩展了终端设备的能力;
(3)DDNNs具有内置的容错功能;
(4)DDNNs降低了终端设备的通信成本。
3.评价体系结构
为了适应终端设备的小内存容量,我们使用了二进制神经网络块。我们使用两种类型的块:融合的二进制全连接块和融合的二进制卷积块。全连接块由一个全连接层和m个结点(用来批处理正则化和二进制激活)组成。卷积块由卷积层、池化层、批处理正则化和二进制激活组成。
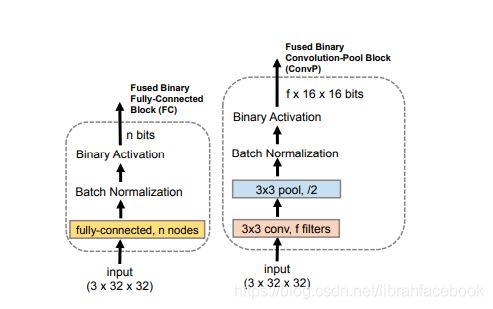
4.实验数据集
我们在多视点多摄像机数据集上对所提出的DDNN框架进行了评估。该数据集由6个摄像机同时拍摄的图像组成,这些摄像机被放置在面对相同区域的不同位置。出于评估的目的,我们假设每个相机都连接到一个终端设备,可以通过带宽受限的无线网络将拍摄到的图像传输到连接着云端的物理断点。

5.实验网络结构
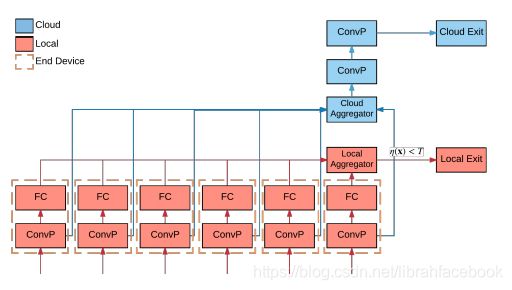
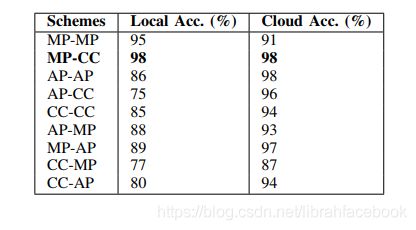
6.聚合方案对网络性能影响
为了对来自多个终端设备输入进行分类,我们必须聚合来自每个终端设备的信息。本地聚合器的每个输入都是一个浮点向量,长度等于类的数量(对应于单个设备的最后一个全连接块的输出)。终端设备发送到云聚合器的输出是最后一个卷积块的输出。本地聚合器中的向量中的元素输入对应于每个类别的可能性,因此,最大池化对应于在所有终端设备上每个类获取最大响应,并显示出良好的性能。在云中使用CC聚合器允许让所有设备学习更好的过滤器,为本地MP聚合器提供更强的响应,从而可以提高分类精度。综合来说,使用MP-CC聚合器对于DDNN的实验性能最好。
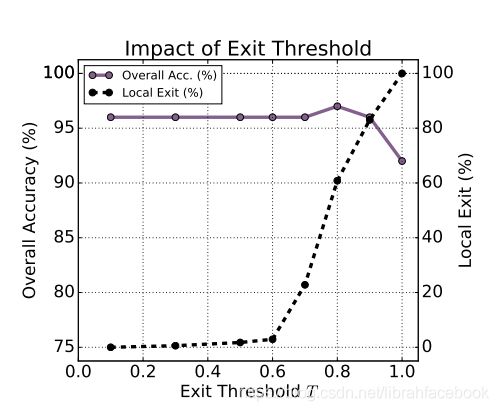
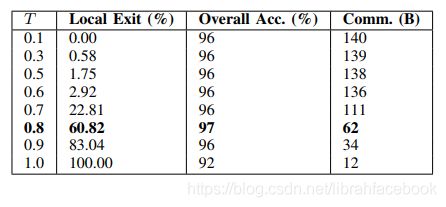
7.本地出口点阈值设置
在实验中,T=0.8对应于局部分类器能够正确分类一些被云分类器错误分类的样本的最佳点。该阈值表示本地分类器和云分类器协同工作的最佳位置点。
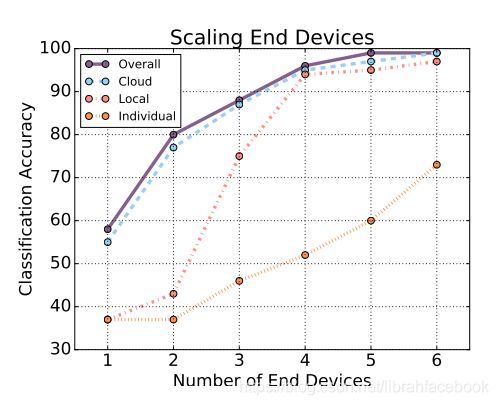
8.跨终端设备伸缩的影响
终端设备是按照它们各自的精度从最差到最好的顺序添加的,首先是精度最低的设备,然后是精度最高的设备。与任何设备的单独精度相比,通过结合多个设备视点,我们可以在本地和云端级别上显著提高分类精度。
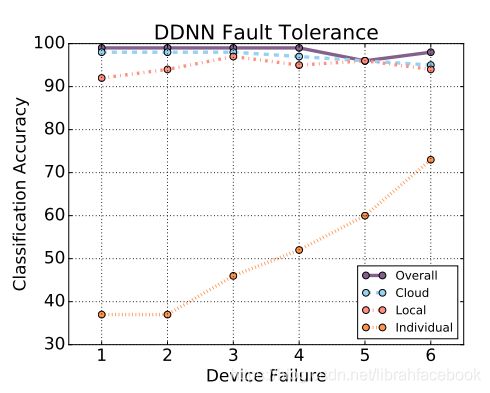
9.DDNN的容错性
DDNN提供的自动容错性使系统在设备出现故障时仍然可靠,该系统对于多故障终端设备也具有鲁棒性。
10.DDNN的通信量减少原因
当需要额外的神经网络层处理以提高分类精度时,终端设备的通信减少的结果是将与类标签相关的中间结果传输到所有样本的本地聚合器,并与云端进行二值化通信。
五、结论
实验结果表明,使用所设计的DDNN框架,一个经过适当训练的DNN可以映射到一个分布式计算层次结构上,以满足目标应用程序的精度、通信和延迟需求,同时获得与分布式计算相关的一些好处,例如容错性和隐私性。
与标准的云处理方法相比,DDNN通过在本地聚合器中退出许多样本,并在需要额外处理时向云发送紧凑的二进制特性表示,从而减少了所需的通信量。对于我们的评估数据集,相对于将原始传感器输入传输到云中执行所有推理计算的DNN, DDNN的通信成本降低了20倍以上。