深度学习硬件实现
文章目录
- 各种硬件
-
- CPU
- GPU
- NPU
- FPGA
- 各芯片架构特点总结
- 国产化分析
-
- 华为
-
- Atlas 300
- 寒武纪
- 比特大陆
各种硬件
CPU
CPU(Central Processing Unit)中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control,运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。
简单说,就是计算单元、控制单元和存储单元。
架构图如下所示:

CPU遵循的是冯诺依曼架构,其核心是存储程序、顺序执行。CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
GPU
CPU无法做到大量矩阵数据并行计算的能力,但GPU可以。
GPU(Graphics Processing Unit),即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,专为同时处理多重任务而设计。
为什么GPU可以做到并行计算的能力?GPU中也包含基本的计算单元、控制单元和存储单元,但GPU的架构与CPU有所不同,如下图所示:
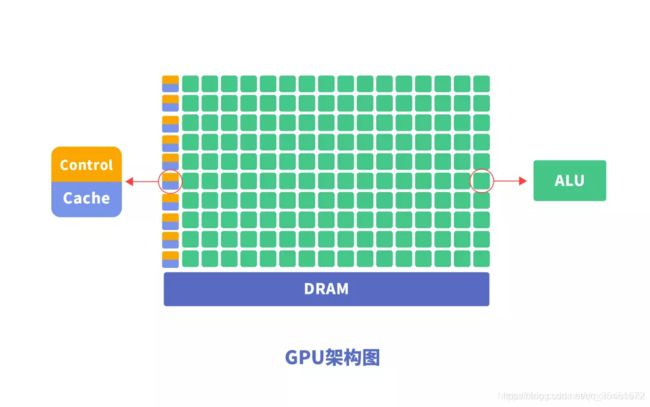
与CPU相比,CPU芯片空间的不到20%是ALU,而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。
以Darknet构建的神经网络模型AlexNet、VGG-16及Restnet152在GPU Titan X, CPU Intel i7-4790K (4 GHz) 进行ImageNet分类任务预测的结果:
| Model | Top-1 | Ops | GPU | CPU | Rate |
|---|---|---|---|---|---|
| AlexNet | 57.0 | 2.27 Bn | 3.1 ms | 0.29 s | 93.55 |
| Darknet Reference | 61.1 | 0.96 Bn | 2.9 ms | 0.14 s | 48.27 |
| VGG-16 | 70.5 | 30.94 Bn | 9.4 ms | 4.36 s | 463.82 |
| Extraction | 72.5 | 8.52 Bn | 4.8 ms | 0.97 s | 202.08 |
| Darknet19 | 72.9 | 7.29 Bn | 6.2 ms | 0.87 s | 140.32 |
| Darknet19 448x448 | 76.4 | 22.33 Bn | 11.0 ms | 2.96 s | 269.09 |
| Resnet 18 | 70.7 | 4.69 Bn | 4.6 ms | 0.57 s | 123.91 |
| Resnet 34 | 72.4 | 9.52 Bn | 7.1 ms | 1.11 s | 156.34 |
| Resnet 50 | 75.8 | 9.74 Bn | 11.4 ms | 1.13 s | 99.12 |
| Resnet 101 | 77.1 | 19.70 Bn | 20.0 ms | 2.23 s | 111.5 |
| Resnet 152 | 77.6 | 29.39 Bn | 28.6 ms | 3.31 s | 115.73 |
| ResNeXt 50 | 77.8 | 10.11 Bn | 24.2 ms | 1.20 s | 45.59 |
| ResNeXt 101 (32x4d) | 77.7 | 18.92 Bn | 58.7 ms | 2.24 s | 38.16 |
| ResNeXt 152 (32x4d) | 77.6 | 28.20 Bn | 73.8 ms | 3.31 s | 44.85 |
| Densenet 201 | 77.0 | 10.85 Bn | 32.6 ms | 1.38 s | 42.33 |
| Darknet53 | 77.2 | 18.57 Bn | 13.7 ms | 2.11 s | 154.01 |
| Darknet53 448x448 | 78.5 | 56.87 Bn | 26.3 ms | 7.21 s | 274.14 |
总结GPU具有如下特点:
- 多线程,提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算
- 拥有更高的访存速度;
- 更高的浮点运算能力。
因此,GPU比CPU更适合深度学习中的大量训练数据、大量矩阵、卷积运算。
GPU虽然在并行计算能力上尽显优势,但并不能单独工作,需要CPU的协同处理,对于神经网络模型的构建和数据流的传递还是在CPU上进行。同时存在功耗高,体积大的问题。
性能越高的GPU体积越大,功耗越高,价格也昂贵,对于一些小型设备、移动设备来说将无法使用。
NPU
NPU (Neural Networks Process Units)神经网络处理单元。NPU工作原理是在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU和GPU,NPU通过突触权重实现存储和计算一体化,从而提高运行效率。
NPU是模仿生物神经网络而构建的,CPU、GPU处理器需要用数千条指令完成的神经元处理,NPU只要一条或几条就能完成,因此在深度学习的处理效率方面优势明显。
实验结果显示,同等功耗下NPU 的性能是GPU 的118 倍。
与GPU一样,NPU同样需要CPU的协同处理才能完成特定的任务。下面,我们可以看一下GPU和NPU是如何与CPU协同工作的。
GPU的加速
GPU当前只是单纯的并行矩阵的乘法和加法运算,对于神经网络模型的构建和数据流的传递还是在CPU上进行。
CPU加载权重数据,按照代码构建神经网络模型,将每层的矩阵运算通过CUDA或OpenCL等类库接口传送到GPU上实现并行计算,输出结果;CPU接着调度下层神经元组矩阵数据计算,直至神经网络输出层计算完成,得到最终结果。

CPU 与GPU的交互流程:
- 获取GPU信息,配置GPU id
- 加载神经元参数到GPU
- GPU加速神经网络计算
- 接收GPU计算结果
NPU的加速
NPU与GPU加速不同,主要体现为每层神经元计算结果不用输出到主内存,而是按照神经网络的连接传递到下层神经元继续计算,因此其在运算性能和功耗上都有很大的提升。
CPU将编译好的神经网络模型文件和权重文件交由专用芯片加载,完成硬件编程。

CPU在整个运行过程中,主要是实现数据的加载和业务流程的控制,其交互流程为:
- 打开NPU专用芯片设备
- 传入模型文件,得到模型task
- 获取task的输入输出信息
- 拷贝输入数据到模型内存中
- 运行模型,得到输出数据
FPGA
FPGA(Field-Programmable Gate Array)称为现场可编程门阵列,用户可以根据自身的需求进行重复编程。与CPU、GPU 相比,具有性能高、功耗低、可硬件编程的特点。
FPGA基本原理是在芯片内集成大量的数字电路基本门电路以及存储器,而用户可以通过烧入FPGA 配置文件来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,可重复编写定义,重复配置。
FPGA的内部结构如下图所示:

FPGA的编程逻辑块(Programable Logic Blocks)中包含很多功能单元,由LUT(Look-up Table)、触发器组成。FPGA是直接通过这些门电路来实现用户的算法,没有通过指令系统的翻译,执行效率更高。
我们可以对比一下
CPU/GPU/NPU/FPGA各自的特点

各芯片架构特点总结
/ CPU /
70%晶体管用来构建Cache,还有一部分控制单元,计算单元少,适合逻辑控制运算。
/ GPU /
晶体管大部分构建计算单元,运算复杂度低,适合大规模并行计算。主要应用于大数据、后台服务器、图像处理。
/ NPU /
在电路层模拟神经元,通过突触权重实现存储和计算一体化,一条指令完成一组神经元的处理,提高运行效率。主要应用于通信领域、大数据、图像处理。
/ FPGA /
可编程逻辑,计算效率高,更接近底层IO,通过冗余晶体管和连线实现逻辑可编辑。本质上是无指令、无需共享内存,计算效率比CPU、GPU高。主要应用于智能手机、便携式移动设备、汽车。
CPU作为最通用的部分,协同其他处理器完成着不同的任务。GPU适合深度学习中后台服务器大量数据训练、矩阵卷积运算。NPU、FPGA在性能、面积、功耗等方面有较大优势,能更好的加速神经网络计算。而FPGA的特点在于开发使用硬件描述语言,开发门槛相对GPU、NPU高。
可以说,每种处理器都有它的优势和不足,在不同的应用场景中,需要根据需求权衡利弊,选择合适的芯片。
AI大数据及人工智能服务平台:www.aideeptech.com

国产化分析
华为
目前已有厂商针对安防监控后端推出了GPU的替代方案。2018年10月份,华为自研的云端AI芯片昇腾系列,基于达芬奇架构的华为昇腾910。在年底,华为又推出了基于ARM的服务器芯片“Hi1620”,采用台积电7nm工艺制造,在ARMv8架构的基础上,华为自主设计了代号“TaiShan”(泰山)的核心,支持48核心、64核心+2.6/3.0GHz配置。百度发布AI“昆仑”芯片,它是目前行业内运行速度最快的智能芯片。
Atlas 300

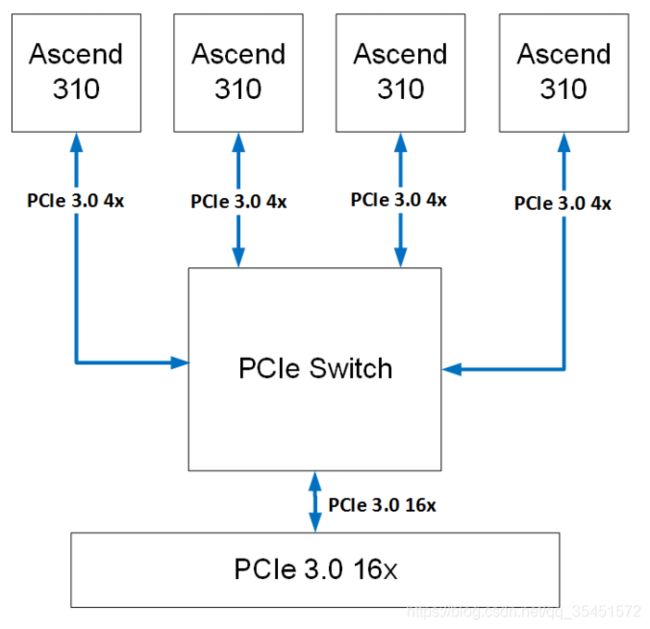
采用4个高性能低功耗的海思Ascend 310 AI处理器,最高可提供16TOPS(INT8)/PCS Ascend 310的计算能力。




寒武纪
成立于2016年的寒武纪,成立之初就发布了世界首款商用深度学习专用处理器寒武纪1A处理器(Cambricon-1A),并成为全球第一个成功流片并拥有成熟产品的AI芯片公司,拥有终端AI处理器IP和云端高性能AI芯片两条产品线。其中中科曙光与寒武纪合作,在最新的人工智能服务器Phaneron中搭载寒武纪的深度学习ASIC芯片,在深度学习应用中比传统的CPU/GPU在性能、功耗和芯片面积方面均有较大优势,有望在安防监控领域落地应用。
比特大陆
2017年,比特大陆推出其AI品牌Sophon(算丰),并发布其第一代云端AI芯片张量计算处理器BM1680,适用于 CNN / RNN / DNN 的训练和推理。BM1680 单芯片能够提供 2TFlops 单精度加速计算能力,芯片由 64 NPU 构成。2018 年比特大陆发布第 2 代算丰 AI 芯片 BM1682,计算力有大幅提升。同时,今年10月份比特大陆基于云端芯片BM1682还发布了算丰智能服务器SA3。
AI 芯片的竞争现状 - 链闻 ChainNews
https://www.chainnews.com/articles/166969049344.htm