[Code] [NeRF] VQRF代码与实验 (3)
VQRF Code
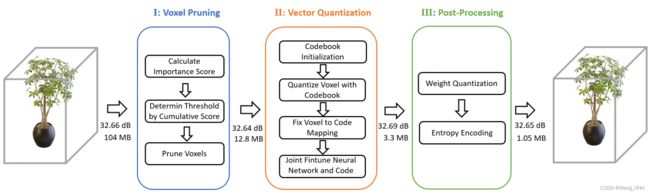
- VQRF Contributions
-
- importance
- voxel prune
- vector quantize
- Apply voxel pruning and vector quantization
- Joint finetune VQ-DVGO
Paper Link: Compressing Volumetric Radiance Fields to 1 MB
Code Link: VQRF
相关内容:
VQRF代码与实验 (1)
VQRF代码与实验 (2)
VQRF Contributions
importance
In run_final.py
init_importance(
render_poses=data_dict[‘poses’][data_dict[‘i_train’]],
HW=data_dict[‘HW’][data_dict[‘i_train’]],
Ks=data_dict[‘Ks’][data_dict[‘i_train’]],
savedir=importance_savedir,
**render_viewpoints_kwargs)
def init_importance(model, render_poses, HW, Ks, ndc, render_kwargs, savedir=None, render_factor=0, ):
'''Render images for the given viewpoints; run evaluation if gt given.
'''
imp_path = os.path.join(savedir, 'importance.pth')
if os.path.exists(imp_path):
print('load exsited importance calculation')
model.importance = torch.load(imp_path)
return
assert len(render_poses) == len(HW) and len(HW) == len(Ks)
print('start importance calculation')
if render_factor!=0:
HW = np.copy(HW)
Ks = np.copy(Ks)
HW = (HW/render_factor).astype(int)
Ks[:, :2, :3] /= render_factor
pseudo_grid = torch.ones_like(model.density.grid)
pseudo_grid.requires_grad = True
for i, c2w in enumerate(tqdm(render_poses)):
H, W = HW[i]
K = Ks[i]
c2w = torch.Tensor(c2w)
rays_o, rays_d, viewdirs = dvgo.get_rays_of_a_view(
H, W, K, c2w, ndc, inverse_y=render_kwargs['inverse_y'],
flip_x=cfg.data.flip_x, flip_y=cfg.data.flip_y)
rays_o = rays_o.flatten(0,-2)
rays_d = rays_d.flatten(0,-2)
viewdirs = viewdirs.flatten(0,-2)
i = 0
for ro, rd, vd in zip(rays_o.split(8192, 0), rays_d.split(8192, 0), viewdirs.split(8192, 0)):
ret = model.forward_imp(ro, rd, vd, pseudo_grid, **render_kwargs)
if (ret['weights'].size(0) !=0) and (ret['sampled_pseudo_grid'].size(0) !=0):
(ret['weights'].detach()*ret['sampled_pseudo_grid']).sum().backward()
i += 1
model.importance = pseudo_grid.grad.clone()
model.density.grid.grad = None
torch.save(model.importance, imp_path)
return
we can get the sampling point xi which is tri-linearly interpolated with its neighboring voxels vl where vl ∈ Ni

The importance score is assigned to the voxel vl proportionally according to its distance to the point xi

关键部分:
i = 0
for ro, rd, vd in zip(rays_o.split(8192, 0), rays_d.split(8192, 0), viewdirs.split(8192, 0)):
ret = model.forward_imp(ro, rd, vd, pseudo_grid, **render_kwargs)
if (ret['weights'].size(0) !=0) and (ret['sampled_pseudo_grid'].size(0) !=0):
(ret['weights'].detach()*ret['sampled_pseudo_grid']).sum().backward()
i += 1
model.importance = pseudo_grid.grad.clone()
其中model.forward_imp位于lib/dvgo.py
def forward_imp(self, rays_o, rays_d, viewdirs, pseudo_grid, global_step=None, **render_kwargs):
'''Volume rendering
@rays_o: [N, 3] the starting point of the N shooting rays.
@rays_d: [N, 3] the shooting direction of the N rays.
@viewdirs: [N, 3] viewing direction to compute positional embedding for MLP.
'''
assert len(rays_o.shape)==2 and rays_o.shape[-1]==3, 'Only suuport point queries in [N, 3] format'
ret_dict = {}
N = len(rays_o)
# sample points on rays
ray_pts, ray_id, step_id = self.sample_ray(
rays_o=rays_o, rays_d=rays_d, **render_kwargs)
interval = render_kwargs['stepsize'] * self.voxel_size_ratio
# skip known free space
if self.mask_cache is not None:
mask = self.mask_cache(ray_pts)
ray_pts = ray_pts[mask]
ray_id = ray_id[mask]
step_id = step_id[mask]
debug = False
with utils.Timing('-alpha calc', debug):
# query for alpha w/ post-activation
density, sampled_pseudo_grid = self.density(ray_pts, importance=pseudo_grid)
alpha = self.activate_density(density, interval)
if self.fast_color_thres > 0:
mask = (alpha > self.fast_color_thres)
ray_pts = ray_pts[mask]
ray_id = ray_id[mask]
step_id = step_id[mask]
density = density[mask]
alpha = alpha[mask]
sampled_pseudo_grid = sampled_pseudo_grid[mask]
# compute accumulated transmittance
weights, alphainv_last = Alphas2Weights.apply(alpha, ray_id, N)
if self.fast_color_thres > 0:
mask = (weights > self.fast_color_thres)
weights = weights[mask]
alpha = alpha[mask]
ray_pts = ray_pts[mask]
ray_id = ray_id[mask]
step_id = step_id[mask]
density = density[mask]
sampled_pseudo_grid = sampled_pseudo_grid[mask]
ret_dict.update({
'alphainv_last': alphainv_last,
'weights': weights,
'raw_alpha': alpha,
'ray_id': ray_id,
'density':density,
'sampled_pseudo_grid':sampled_pseudo_grid
})
return ret_dict
self.density定义:
self.density = grid.create_grid(
density_type, channels=1, world_size=self.world_size,
xyz_min=self.xyz_min, xyz_max=self.xyz_max,
config=self.density_config)
self.density对应lib/grid.py中的class DenseGrid():
class DenseGrid(nn.Module):
def __init__(self, channels, world_size, xyz_min, xyz_max, **kwargs):
super(DenseGrid, self).__init__()
self.channels = channels
self.world_size = world_size
self.register_buffer('xyz_min', torch.Tensor(xyz_min))
self.register_buffer('xyz_max', torch.Tensor(xyz_max))
self.grid = nn.Parameter(torch.zeros([1, channels, *world_size]))
self.trilinear_interpolation = TrilinearIntepolation().cuda()
def forward(self, xyz, importance=None, vq=None):
'''
xyz: global coordinates to query
'''
shape = xyz.shape[:-1]
xyz = xyz.reshape(1,1,1,-1,3)
ind_norm = ((xyz - self.xyz_min) / (self.xyz_max - self.xyz_min)).flip((-1,)) * 2 - 1
if vq is None:
out = F.grid_sample(self.grid, ind_norm, mode='bilinear', align_corners=False)
else:
out = self.trilinear_interpolation(self.grid, ind_norm.squeeze(0), vq)
if importance is not None:
sampled_importance = F.grid_sample(importance, ind_norm, mode='bilinear', align_corners=False)
sampled_importance = sampled_importance.reshape(self.channels,-1).T.reshape(*shape,self.channels)
if self.channels == 1:
sampled_importance = sampled_importance.squeeze(-1)
out = out.reshape(self.channels,-1).T.reshape(*shape,self.channels)
if self.channels == 1:
out = out.squeeze(-1)
if importance is not None:
return out, sampled_importance
else:
return out
voxel prune
计算了importance后,根据重要性分数,对voxel进行剪枝
model.init_cdf_mask(args.importance_prune, args.importance_include) # voxel prune
@torch.no_grad()
def init_cdf_mask(self, thres_mid=1.0, thres_high=0):
print("start cdf three split")
importance = self.importance.flatten()
if thres_mid!=1.0:
percent_sum = thres_mid
vals,idx = sorted_importance = torch.sort(importance+(1e-6))
cumsum_val = torch.cumsum(vals, dim=0)
split_index = ((cumsum_val/vals.sum()) > (1-percent_sum)).nonzero().min()
split_val_nonprune = vals[split_index]
percent_point = (importance+(1e-6)>= vals[split_index]).sum()/importance.numel()
print(f'{percent_point*100:.2f}% of most important points contribute over {(percent_sum)*100:.2f}% importance ')
self.non_prune_mask = importance>split_val_nonprune
else:
self.non_prune_mask = torch.ones_like(importance).bool()
if thres_high!=0 :
percent_sum = thres_high
vals,idx = sorted_importance = torch.sort(importance+(1e-6))
cumsum_val = torch.cumsum(vals, dim=0)
split_index = ((cumsum_val/vals.sum()) > (1-percent_sum)).nonzero().min()
split_val_reinclude = vals[split_index]
percent_point = (importance+(1e-6)>= vals[split_index]).sum()/importance.numel()
print(f'{percent_point*100:.2f}% of most important points contribute over {(percent_sum)*100:.2f}% importance ')
self.keep_mask = importance>split_val_reinclude
else:
self.keep_mask = torch.zeros_like(importance).bool()
self.keep_mask[-1] = True # for code robustness issue
return self.non_prune_mask, self.keep_mask
取[args.importance_include, args.importance_prune]区间的voxel,对应的mask为
vq_mask = torch.logical_xor(model.non_prune_mask, model.keep_mask)
vector quantize
(We randomly select a batch of voxels from the grid at each iteration and calculate the euclidean distance between the selected voxel and each code vector in the codebook to determine which code the voxel associates with. The code vector is optimized by weighted accumulating the voxel features belonging to the code by virtue of importance score.)
对剪枝后的voxel,进行矢量量化
if vq_mask.any():
k0_needs_vq = model.k0.grid.clone().reshape(model.k0_dim, -1).T[vq_mask]
imp = model.importance.flatten()[vq_mask]
k = args.k_expire
if k > model.vq.codebook_size:
k = 0
for _ in trange(1000):
indexes = torch.randint(low=0, high=k0_needs_vq.shape[0], size=[VQ_CHUNK])
vq_weight = imp[indexes]
vq_feature = k0_needs_vq[indexes, :]
model.vq(vq_feature.unsqueeze(0), weight=vq_weight.reshape(1, -1, 1))
其中,终止容量最低的J代码,这些代码使用batch中最重要的前J个voxel的特征进行重新初始化。
replace_val, replace_index = torch.topk(model.vq._codebook.cluster_size, k=k, largest=False)
_, most_important_index = torch.topk(vq_weight, k=k, largest=True)
model.vq._codebook.embed[:, replace_index, :] = vq_feature[most_important_index, :]
(We track the capacity of each code vector bk by estimating the accumulated importance of the voxels assigned to it during iteration, i.e., sk = ∑ Ij 1{vj ∈ R(bk)}. Then we rank them in descending order and expire J codes with lowest capacity, which are reinitialized with the features of the top J mostly important voxels in the batch.)
vq具体为:
self.vq = VectorQuantize(
dim = self.k0_dim,
codebook_size = kwargs[“codebook_size”],
decay = 0.8, # specify number of quantizersse
commitment_weight = 1.0 , # codebook size
use_cosine_sim = kwargs[“use_cosine_sim”],
threshold_ema_dead_code=0,
)
class VectorQuantize(nn.Module):
def __init__(
self,
dim,
codebook_size,
codebook_dim = None,
heads = 1,
separate_codebook_per_head = False,
decay = 0.8,
eps = 1e-5,
kmeans_init = False,
kmeans_iters = 10,
use_cosine_sim = False,
threshold_ema_dead_code = 0,
channel_last = True,
accept_image_fmap = False,
commitment_weight = 1.,
orthogonal_reg_weight = 0.,
orthogonal_reg_active_codes_only = False,
orthogonal_reg_max_codes = None,
sample_codebook_temp = 0.,
sync_codebook = False
):
super().__init__()
self.heads = heads
self.separate_codebook_per_head = separate_codebook_per_head
codebook_dim = default(codebook_dim, dim)
codebook_input_dim = codebook_dim * heads
requires_projection = codebook_input_dim != dim
self.project_in = nn.Linear(dim, codebook_input_dim) if requires_projection else nn.Identity()
self.project_out = nn.Linear(codebook_input_dim, dim) if requires_projection else nn.Identity()
self.eps = eps
self.commitment_weight = commitment_weight
has_codebook_orthogonal_loss = orthogonal_reg_weight > 0
self.orthogonal_reg_weight = orthogonal_reg_weight
self.orthogonal_reg_active_codes_only = orthogonal_reg_active_codes_only
self.orthogonal_reg_max_codes = orthogonal_reg_max_codes
codebook_class = EuclideanCodebook if not use_cosine_sim else CosineSimCodebook
self._codebook = codebook_class(
dim = codebook_dim,
num_codebooks = heads if separate_codebook_per_head else 1,
codebook_size = codebook_size,
kmeans_init = kmeans_init,
kmeans_iters = kmeans_iters,
decay = decay,
eps = eps,
threshold_ema_dead_code = threshold_ema_dead_code,
use_ddp = sync_codebook,
learnable_codebook = has_codebook_orthogonal_loss,
sample_codebook_temp = sample_codebook_temp
)
self.codebook_size = codebook_size
self.accept_image_fmap = accept_image_fmap
self.channel_last = channel_last
@property
def codebook(self):
codebook = self._codebook.embed
if self.separate_codebook_per_head:
return codebook
return rearrange(codebook, '1 ... -> ...')
def forward(self, x, weight=None, verbose=False):
shape, device, heads, is_multiheaded, codebook_size = x.shape, x.device, self.heads, self.heads > 1, self.codebook_size
need_transpose = not self.channel_last and not self.accept_image_fmap
if self.accept_image_fmap:
height, width = x.shape[-2:]
x = rearrange(x, 'b c h w -> b (h w) c')
if need_transpose:
x = rearrange(x, 'b d n -> b n d')
x = self.project_in(x)
if is_multiheaded:
ein_rhs_eq = 'h b n d' if self.separate_codebook_per_head else '1 (b h) n d'
x = rearrange(x, f'b n (h d) -> {ein_rhs_eq}', h = heads)
quantize, embed_ind = self._codebook(x, weight, verbose)
if self.training:
quantize = x + (quantize - x).detach()
loss = torch.tensor([0.], device = device, requires_grad = self.training)
if self.training:
if self.commitment_weight > 0:
commit_loss = F.mse_loss(quantize.detach(), x)
loss = loss + commit_loss * self.commitment_weight
if self.orthogonal_reg_weight > 0:
codebook = self._codebook.embed
if self.orthogonal_reg_active_codes_only:
# only calculate orthogonal loss for the activated codes for this batch
unique_code_ids = torch.unique(embed_ind)
codebook = codebook[unique_code_ids]
num_codes = codebook.shape[0]
if exists(self.orthogonal_reg_max_codes) and num_codes > self.orthogonal_reg_max_codes:
rand_ids = torch.randperm(num_codes, device = device)[:self.orthogonal_reg_max_codes]
codebook = codebook[rand_ids]
orthogonal_reg_loss = orthogonal_loss_fn(codebook)
loss = loss + orthogonal_reg_loss * self.orthogonal_reg_weight
if is_multiheaded:
if self.separate_codebook_per_head:
quantize = rearrange(quantize, 'h b n d -> b n (h d)', h = heads)
embed_ind = rearrange(embed_ind, 'h b n -> b n h', h = heads)
else:
quantize = rearrange(quantize, '1 (b h) n d -> b n (h d)', h = heads)
embed_ind = rearrange(embed_ind, '1 (b h) n -> b n h', h = heads)
quantize = self.project_out(quantize)
if need_transpose:
quantize = rearrange(quantize, 'b n d -> b d n')
if self.accept_image_fmap:
quantize = rearrange(quantize, 'b (h w) c -> b c h w', h = height, w = width)
embed_ind = rearrange(embed_ind, 'b (h w) ... -> b h w ...', h = height, w = width)
return quantize, embed_ind, loss
Code vector 更新

class EuclideanCodebook(nn.Module):
def __init__(
self,
dim,
codebook_size,
num_codebooks = 1,
kmeans_init = False,
kmeans_iters = 10,
decay = 0.8,
eps = 1e-5,
threshold_ema_dead_code = 2,
use_ddp = False,
learnable_codebook = False,
sample_codebook_temp = 0
):
super().__init__()
self.decay = decay
init_fn = uniform_init if not kmeans_init else torch.zeros
embed = init_fn(num_codebooks, codebook_size, dim)
self.codebook_size = codebook_size
self.num_codebooks = num_codebooks
self.kmeans_iters = kmeans_iters
self.eps = eps
self.threshold_ema_dead_code = threshold_ema_dead_code
self.sample_codebook_temp = sample_codebook_temp
self.sample_fn = sample_vectors_distributed if use_ddp else batched_sample_vectors
self.all_reduce_fn = distributed.all_reduce if use_ddp else noop
self.register_buffer('initted', torch.Tensor([not kmeans_init]))
self.register_buffer('cluster_size', torch.zeros(num_codebooks, codebook_size))
self.register_buffer('embed_avg', embed.clone())
self.learnable_codebook = learnable_codebook
if learnable_codebook:
self.embed = nn.Parameter(embed)
else:
self.register_buffer('embed', embed)
@torch.jit.ignore
def init_embed_(self, data):
if self.initted:
return
embed, cluster_size = kmeans(
data,
self.codebook_size,
self.kmeans_iters,
sample_fn = self.sample_fn,
all_reduce_fn = self.all_reduce_fn
)
self.embed.data.copy_(embed)
self.embed_avg.data.copy_(embed.clone())
self.cluster_size.data.copy_(cluster_size)
self.initted.data.copy_(torch.Tensor([True]))
def replace(self, batch_samples, batch_mask):
batch_samples = l2norm(batch_samples)
for ind, (samples, mask) in enumerate(zip(batch_samples.unbind(dim = 0), batch_mask.unbind(dim = 0))):
if not torch.any(mask):
continue
sampled = self.sample_fn(rearrange(samples, '... -> 1 ...'), mask.sum().item())
self.embed.data[ind][mask] = rearrange(sampled, '1 ... -> ...')
def expire_codes_(self, batch_samples, verbose):
if self.threshold_ema_dead_code == 0:
return
expired_codes = self.cluster_size < self.threshold_ema_dead_code
if not torch.any(expired_codes):
return
if verbose:
print(f'expire code count: {expired_codes.sum()}')
batch_samples = rearrange(batch_samples, 'h ... d -> h (...) d')
self.replace(batch_samples, batch_mask = expired_codes)
@autocast(enabled = False)
def forward(self, x, weight=None, verbose=False):
if weight is not None:
weight = weight * weight.numel()/weight.sum()
needs_codebook_dim = x.ndim < 4
x = x.float()
if needs_codebook_dim:
x = rearrange(x, '... -> 1 ...')
shape, dtype = x.shape, x.dtype
flatten = rearrange(x, 'h ... d -> h (...) d')
self.init_embed_(flatten)
embed = self.embed if not self.learnable_codebook else self.embed.detach()
dist = -torch.cdist(flatten, embed, p = 2)
embed_ind = gumbel_sample(dist, dim = -1, temperature = self.sample_codebook_temp)
embed_onehot = F.one_hot(embed_ind, self.codebook_size).type(dtype)
embed_ind = embed_ind.view(*shape[:-1])
quantize = batched_embedding(embed_ind, self.embed)
if self.training:
if weight is not None:
cluster_size = (embed_onehot*weight).sum(dim = 1)
else:
cluster_size = embed_onehot.sum(dim = 1)
self.all_reduce_fn(cluster_size)
ema_inplace(self.cluster_size, cluster_size, self.decay)
if weight is not None:
embed_sum = einsum('h n d, h n c -> h c d', flatten*weight, embed_onehot)
else:
embed_sum = einsum('h n d, h n c -> h c d', flatten, embed_onehot)
self.all_reduce_fn(embed_sum)
cluster_size = laplace_smoothing(self.cluster_size, self.codebook_size, self.eps) * self.cluster_size.sum()
ema_inplace(self.embed, embed_sum/rearrange(cluster_size, '... -> ... 1'), self.decay)
self.expire_codes_(x, verbose)
if needs_codebook_dim:
quantize, embed_ind = map(lambda t: rearrange(t, '1 ... -> ...'), (quantize, embed_ind))
return quantize, embed_ind
Apply voxel pruning and vector quantization
all_indices = model.fully_vq_reformat(args.importance_prune, args.importance_include)
@torch.no_grad()
def fully_vq_reformat(self, thres_mid=1.0, thres_high=0, save_path=None):
print("start fully vector quantize")
k0_grid = self.k0.grid.reshape(self.k0_dim,-1)
k0_grid = k0_grid.T
density_grid = self.density.grid.reshape(1,-1)
density_grid = density_grid.T
print("caculate vq features")
all_feat, all_indice = self.calc_vector_quantized_feature()
print("start cdf three split")
self.init_cdf_mask(thres_mid=thres_mid, thres_high=thres_high)
new_k0_grid = torch.zeros_like(all_feat)
new_densiy_grid = torch.zeros_like(density_grid)# - 99999
non_prune_density = density_grid[self.non_prune_mask,:]
non_prune_density = torch.quantize_per_tensor(non_prune_density, scale=non_prune_density.std()/15, zero_point=torch.round(non_prune_density.mean()), dtype=torch.qint8)
new_densiy_grid[self.non_prune_mask,:] = non_prune_density.dequantize()
new_k0_grid[self.non_prune_mask,:] = all_feat[self.non_prune_mask,:]
non_vq_grid = k0_grid[self.keep_mask,:]
non_vq_grid = torch.quantize_per_tensor(non_vq_grid, scale=non_vq_grid.std()/15, zero_point=torch.round(non_vq_grid.mean()), dtype=torch.qint8)
new_k0_grid[self.keep_mask,:] = non_vq_grid.dequantize(
# To ease the implementation of codebook finetuneing, we add indexs of non-vq-voxels to all_indice.
# note that these part of indexs will not be saved
all_indice[self.keep_mask] = torch.arange(self.keep_mask.sum())+ self.used_kwargs["codebook_size"]
if save_path is not None:
import numpy as np
import math
from copy import deepcopy
os.makedirs(f'{save_path}/extreme_saving', exist_ok=True)
np.savez_compressed(f'{save_path}/extreme_saving/non_prune_density.npz',non_prune_density.int_repr().cpu().numpy())
np.savez_compressed(f'{save_path}/extreme_saving/non_vq_grid.npz',non_vq_grid.int_repr().cpu().numpy())
np.savez_compressed(f'{save_path}/extreme_saving/non_prune_mask.npz',np.packbits(self.non_prune_mask.reshape(-1).cpu().numpy()))
np.savez_compressed(f'{save_path}/extreme_saving/keep_mask.npz',np.packbits(self.keep_mask.reshape(-1).cpu().numpy()))
def dec2bin(x, bits):
mask = 2 ** torch.arange(bits - 1, -1, -1).to(x.device, x.dtype)
return x.unsqueeze(-1).bitwise_and(mask).ne(0).float()
# vq indice was saved in according to the bit length
bin_indices = dec2bin(all_indice[torch.logical_xor(self.non_prune_mask,self.keep_mask)], int(math.log2(self.used_kwargs["codebook_size"]))).bool().cpu().numpy()
np.savez_compressed(f'{save_path}/extreme_saving/vq_indexs.npz',np.packbits(bin_indices.reshape(-1)))
codebook = self.vq._codebook.embed.cpu().half().numpy()
np.savez_compressed(f'{save_path}/extreme_saving/codebook.npz',codebook)
np.savez_compressed(f'{save_path}/extreme_saving/rgbnet.npz',deepcopy(self.rgbnet).half().cpu().state_dict())
# we also save necessary metadata
metadata = dict()
metadata['global_step'] =20000
metadata['world_size'] = self.world_size
metadata['model_kwargs'] = self.get_kwargs()
metadata['model_state_dict'] = dict()
metadata['grid_dequant'] = dict()
metadata['grid_dequant']['zero_point'] = non_vq_grid.q_zero_point()
metadata['grid_dequant']['scale'] = non_vq_grid.q_scale()
metadata['density_dequant'] = dict()
metadata['density_dequant']['zero_point'] = non_prune_density.q_zero_point()
metadata['density_dequant']['scale'] = non_prune_density.q_scale()
model_state_dict = self.state_dict()
metadata['model_state_dict']['act_shift'] = model_state_dict['act_shift']
metadata['model_state_dict']['viewfreq'] = model_state_dict['viewfreq']
metadata['model_state_dict']['xyz_min'] = model_state_dict['xyz_min']
metadata['model_state_dict']['xyz_max'] = model_state_dict['xyz_max']
metadata['model_state_dict']['density.xyz_min'] = model_state_dict['density.xyz_min']
metadata['model_state_dict']['density.xyz_max'] = model_state_dict['density.xyz_max']
metadata['model_state_dict']['k0.xyz_min'] = model_state_dict['k0.xyz_min']
metadata['model_state_dict']['k0.xyz_max'] = model_state_dict['k0.xyz_max']
np.savez_compressed(f'{save_path}/extreme_saving/metadata.npz', metadata=metadata)
# zip everything together to get final size
os.system(f"zip -r {save_path}/extreme_saving.zip {save_path}/extreme_saving ")
new_k0_grid = new_k0_grid.T.reshape(*self.k0.grid.shape).contiguous()
new_densiy_grid = new_densiy_grid.T.reshape(*self.density.grid.shape).contiguous()
self.k0.grid = torch.nn.Parameter(new_k0_grid)
self.density.grid = torch.nn.Parameter(new_densiy_grid)
print("finish fully vector quantize")
return all_indice
对k0_grid进行矢量量化
@torch.no_grad()
def calc_vector_quantized_feature(self):
"""
apply vector quantize on feature grid and return vq indexes
"""
print("start fully vector quantize")
k0_grid = self.k0.grid.reshape(self.k0_dim,-1)
k0_grid = k0_grid.T
CHUNK = 8192
feat_list = []
indice_list = []
self.vq.eval()
self.vq._codebook.embed.half().float()
for i in tqdm(range(0, k0_grid.shape[0], CHUNK)):
feat, indices, commit = self.vq(k0_grid[i:i+CHUNK,:].unsqueeze(0))
indice_list.append(indices[0])
feat_list.append(feat[0])
self.vq.train()
all_feat = torch.cat(feat_list).half().float() # [num_elements, k0_dim]
all_indice = torch.cat(indice_list) # [num_elements, 1]
return all_feat, all_indice
Joint finetune VQ-DVGO
除了gradient descent step外,每10步,同步一次codebook
if global_step % 10 == 0:
with torch.no_grad():
gather_grid = torch.zeros(all_indices.max(), model.k0_dim).to(device)
k0_grid = model.k0.grid.reshape(model.k0_dim, -1).T
out = torch_scatter.scatter(k0_grid, index=all_indices, dim=0, reduce='mean')
max_element = min(out.shape[0], model.used_kwargs["codebook_size"])
model.vq._codebook.embed[:max_element, :].copy_(out[:max_element, :])
new_k0_grid = torch.zeros(all_indices.shape[0], model.k0_dim).to(device)
new_k0_grid = out[all_indices].T.reshape(*model.k0.grid.shape)
model.k0.grid.copy_(new_k0_grid)