大数据:豆瓣电视剧爬虫反爬代理IP、spark清洗、flask框架做可视化
豆瓣电影大数据项目全步骤
1.豆瓣爬虫:
我开始写豆瓣电视剧爬虫时觉得很简单,但在实操时出现了封IP的情况,导致我苦恼了好久,现在终于写出来了
废话不多说,直接上代码:
run 函数用来获取页面的数据这里我用了代理进入
def run(self, k, nd, p):
global data_json, response
while True:
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E8%A7%86%E5%89%A7&start={}&countries=%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86&year_range={}'.format(
str(k), nd)
print(url)
px = self.get_proxy_ip()
proxies = {'http': '{}'.format(px),
'https': '{}'.format(px)}
print(proxies)
try:
response = self.get_url(url, proxies)
data_json = json.loads(response.text)
if len(data_json['data']) > 0:
print("正在爬取-----------------------------请稍后")
for i in data_json['data']:
title_name = str(i['title']).strip().replace('\n', '').replace('\t', '').replace(',', ',')
mv_url = i['url']
# print(mv_url)
zhuyan = ''
if len(i['casts']) != 0:
for e, o in zip(i['casts'], range(len(i['casts']))):
if o + 1 == len(i['casts']):
zhuyan += e
else:
zhuyan += e + '/'
else:
zhuyan += 'None'
if title_name not in p:
jishu, guanyingshu, leixing, year, short = self.get_insert_html(mv_url, proxies)
# time.sleep(1)
cunt_data = [title_name, zhuyan, jishu, guanyingshu, leixing, year, short]
p.append(title_name)
print(title_name, jishu, guanyingshu, leixing, year, short)
time.sleep(2)
# f.write(
# str(
# cunt_data[0]) + ',' + str(
# cunt_data[1]) + ',' + str(cunt_data[2]) + ',' + str(cunt_data[3]) + ',' + str(
# cunt_data[4]) + ',' + str(cunt_data[5]) + ',' + str(cunt_data[6]) + '\n')
print("已执行写入文件步骤")
else:
print("已有数据存在")
print("已爬完此页数据" + "-----------------------------" + "正在缓冲时间")
else:
break
if k < 480:
next_url_num = k + 20
time.sleep(5)
c = []
self.run(next_url_num, nd, c)
except Exception as e:
print(e)
print('此页报错--------------------正在重新爬取')
self.run(k, nd, p)
if 'data' not in str(data_json):
print(data_json)
break
elif len(data_json) == 0:
# print(data_json)
break
elif k == 480:
break
else:
# print(data_json)
break
get_insert_html函数用来将run函数里获取到的链接进入详情页 然后获取数据
def get_insert_html(self, url, proxies):
global jishu, response
print(url)
try:
response = self.get_url(url, proxies)
html = etree.HTML(response.text)
# 集数
if '数' in str(html.xpath('//*[@id="info"]//span[@class="pl"]/text()')):
jishu = ''
if '集数:' in html.xpath('//*[@id="info"]//span[@class="pl"]/text()'):
jishu += str(
html.xpath('//*[@id="info"]//span[text()="集数:"]/following-sibling::text()[position()=1]')[0])
else:
if html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[1]'):
l = html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[1]/text()')[
0]
if '数' not in l:
if html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[2]'):
b = html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[2]/text()')[
0]
if '数' not in b:
jishu += 'None'
else:
jishu += str(html.xpath(
'//div[@id="info"]/span[text()="{}"]/following-sibling::text()[position()=1]'.format(
str(b)))[0]).strip()
else:
jishu += str(html.xpath(
'//div[@id="info"]/span[text()="{}"]/following-sibling::text()[position()=1]'.format(
str(l)))[
0]).strip()
else:
if html.xpath('//*[@id="info"]//span[text()="集数:"]/following-sibling::text()[position()=1]'):
jishu += str(
html.xpath(
'//*[@id="info"]//span[text()="集数:"]/following-sibling::text()[position()=1]')[0])
elif html.xpath('//*[@id="info"]//span[text()="季数:"]/following-sibling::text()[position()=1]'):
jishu += str(html.xpath(
'//*[@id="info"]//span[text()="季数:"]/following-sibling::text()[position()=1]')[0])
else:
jishu += 'None'
else:
jishu = ''
jishu += 'None'
# 观看人数
if html.xpath('//*[@id="comments-section"]/div[1]//span[@class="pl"]/a/text()'):
guanyingshu = \
re.findall('(\d+)', html.xpath('//*[@id="comments-section"]/div[1]//span[@class="pl"]/a/text()')[0])[0]
else:
guanyingshu = 'None'
# 类型
k = ''
if html.xpath('//div[@id="info"]//span[@property="v:genre"]/text()'):
types = html.xpath('//div[@id="info"]//span[@property="v:genre"]/text()')
for i, j in zip(types, range(len(types))):
if j + 1 == len(types):
k += i
else:
k += i + '/'
else:
k += 'None'
# 获取评论
if html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()'):
# print(html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()'))
short = str(html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()')[0]).strip().replace('\n',
'').replace(
'\t', '').replace(',', ',')
else:
short = 'None'
# short = html.xpath('//*div[@id="hot-comments"]/div[1]//p[@class="comment-content"]/span/text()')
# 出版年份
if html.xpath('//span[@class="year"]/text()'):
year = str(html.xpath('//span[@class="year"]/text()')[0]).replace('(', '').replace(')', '').split('-')[
0]
elif html.xpath('//*[@id="info"]//span[text()="首播:"]/following-sibling::span[1]/text()'):
year = re.findall('(\d+)',str(html.xpath('//*[@id="info"]//span[text()="首播:"]/following-sibling::span[1]/text()')[0]))[0]
else:
year = 'None'
a = [jishu, guanyingshu, k, year, short]
if len(a) != 5:
self.get_insert_html(url, proxies)
else:
return jishu, guanyingshu, k, year, short
# if len(a) == 5:
# return jishu, guanyingshu, k, year, short
# else:
# print("数据只有这一个------正在重新爬取")
# self.get_insert_html(url, proxies)
except Exception as e:
print(e)
print(url + "当前链接出现错误------正在重新分配ip-爬取")
px = self.get_proxy_ip()
next_proxies = {'http': '{}'.format(px),
'https': '{}'.format(px)}
self.get_insert_html(url, next_proxies)
get_proxy_ip 函数这个是用来获取代理IP的
def get_proxy_ip(self):
try:
urls = requests.get(
"http://39.104.96.30:7772/Tools/proxyIP.ashx?action=GetIPAPI&OrderNumber=7bbb88a8d9186d00fed9eaaf3033d9d0&poolIndex=1617254228&qty=1&Split=JSON2").text
info = json.loads(urls)
quota = info['LeftIp']
ip = info['Data'][0]['Ip']
port = info['Data'][0]['Port']
proxy_ip = "{}:{}".format(ip, port)
print("已获取到{},剩余配额{}".format(proxy_ip, quota))
return proxy_ip
except:
self.get_proxy_ip()
def get_url(self, url, proxies):
response = requests.get(url, headers=self.get_url_headers, proxies=proxies, allow_redirects=False, timeout=30)
return response
代理IP,我这里用的是买的代理IP的 ,因为网上的那些说爬取免费的代理IP之类的90%都是不能用的 ,所以还是别老想着白嫖。
还有就是要将数据处理一下因为我这里数据保存出来有的时候有问题,就是有时候数据只会返回评论然后就保存为了csv导致数据丢失了。
但我将有问题的数据那一页去跑了一下,测试出来是没有问题的,那些评论都是有的数据也没问题,这个东西真没理解是怎么回事。希望有大佬帮我解答一手!!!
将数据保存为csv后再在excel里面操作,用查找定位,找到某列为空的删了就行了。下面就是spark操作后的流程了:
现在最后一步就是要把数据转换为人能直观的看出来这是这些数据的意思:
这就是可视化操作了
先创建一个flask的项目,然后将处理完的数据导入到这个项目中
直接上代码:
from flask import Flask, request, render_template, jsonify
import pandas as pd
import json
import re
import jieba
app = Flask(__name__, static_folder='/')
@app.route('/')
def hello_world():
return render_template('index.html')
@app.route('/TestEcharts', methods=['POST'])
def TestEcharts():
data = pd.read_csv('part-00000.txt', names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
a = []
z = {}
for i in data['db_types']:
for k in i.split('/'):
a.append(k)
for c in a:
if c in list(z.keys()):
p = z.get(c) + 1
z[c] = p
else:
z.update({c: 1})
xdatas = list(z.keys())
yvalues = list(z.values())
l = {}
l['xdays'] = xdatas
l['yvalues'] = yvalues
j = json.dumps(l)
return (j)
@app.route('/qushi1',methods=['POST'])
def qushi1():
df_2000 = pd.read_csv('2000-2010.csv')
df_2000_groupby = df_2000[['db_years', 'db_gks']].groupby(by='db_years', as_index=False).max()
c_1 = [str(i) for i in df_2000_groupby['db_years']]
c_2 = [int(i) for i in df_2000_groupby['db_gks']]
l = {}
l['xdays'] = c_1
l['yvalues'] = c_2
q1 = json.dumps(l)
return (q1)
@app.route('/qushi2',methods=['POST'])
def qushi2():
df_2011 = pd.read_csv('2011-2021.csv')
df_2011_groupby = df_2011[['db_years', 'db_gks']].groupby(by='db_years', as_index=False).max()
d_1 = [str(i) for i in df_2011_groupby['db_years']]
d_2 = [int(i) for i in df_2011_groupby['db_gks']]
l = {}
l['xdays'] = d_1
l['yvalues'] = d_2
q2 = json.dumps(l)
return (q2)
@app.route('/paiming',methods=['POST'])
def paiming():
data = pd.read_csv('part-00000.txt',
names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
data['db_name'] = data['db_name'].str.replace(r'(', '')
data['db_short'] = data['db_short'].str.replace(r')', '')
# out_data=data[(data['db_zhuyan']>=2000)&(data['db_years']<=2010)]
a = []
z = {}
for i in data['db_zhuyan']:
for k in i.split('/'):
a.append(k)
for c in a:
if c in list(z.keys()):
p = z.get(c) + 1
z[c] = p
else:
z.update({c: 1})
sort_d = sorted(z.items(), key=lambda z: z[1], reverse=True)
count = 0
k = {}
for key, value in sort_d:
count += 1
k[key] = value
if count >= 10:
break
cate = list(k.keys())
data = list(k.values())
l = {}
l['xdays'] = cate
l['yvalues'] = data
j = json.dumps(l)
return (j)
@app.route('/temps',methods=['POST'])
def temps():
data = pd.read_csv('统计集数.txt', names=['db_fanwei', 'db_all_jishu'])
k = []
for i, j in zip(data['db_fanwei'], data['db_all_jishu']):
c = {}
c['value'] = j
c['name'] = i
k.append(c)
return json.dumps(k)
@app.route('/wrodcloud',methods=['POST'])
def WordCloud():
data = pd.read_csv('part-00000.txt',
names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
c = ''
data['db_short'] = data['db_short'].str.replace(r')', '')
for i in data['db_short']:
c += i
pattern = re.compile(r'([\u4e00-\u9fa5]+|[a-zA-Z]+)')
deal_comments = re.findall(pattern, c)
# print(deal_comments)
newComments = ""
for item in deal_comments:
newComments += item
words_lst = jieba.cut(newComments.replace('\n', '').replace(' ', ''))
total = {}
for i in words_lst:
total[i] = total.get(i, 0) + 1
data_s = dict(
sorted({k: v for k, v in total.items() if len(k) >= 2}.items(), key=lambda x: x[1], reverse=True)[:200])
k = []
for i, j in zip(list(data_s.keys()), list(data_s.values())):
c = {}
c['name'] = i
c['value'] = j
k.append(c)
return json.dumps(k)
if __name__ == '__main__':
app.run(debug = True)
HTML那块我用Ajax获取数据请求然后展示处理的 所以那个步骤需要自己写了
先展示一下index文件,这里我onclick触发按钮事件然后点击哪一块就会回调哪一块的HTML页面展示出来:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Documenttitle>
<link rel="stylesheet" href="../static/css/stly.css">
<link rel="stylesheet" href="../static/css/font-awesome-4.7.0/css/font-awesome.min.css">
<script src="../static/js/index_js.js" type='text/javascript'>script>
<script src="../static/js/jquery-3.3.1.min.js" type='text/javascript'>script>
head>
<body>
<div >
<div class="left_div" id="left">
<div class="top_left_div">
<i class="fa fa-rocket">i> 数据可视化
div>
<div class="-left_div">
<ul>
<li> <i class="fa fa-cog">i> 可视化
<dl>
<dd id="types" onclick="changehtml(this)">电视剧类型统计dd>
<dd id="jishu" onclick="changehtml(this)">集数统计dd>
<dd id="qushi" onclick="changehtml(this)">电视趋势dd>
<dd id="paiming" onclick="changehtml(this)" >演员排名dd>
<dd id="pinglun" onclick="changehtml(this)" >评论dd>
dl>
li>
ul>
div>
<div class="main_right">
<iframe id="Ifram" frameborder="0" scrolling="yes" style="width: 100%;height: 100%;" src="/templates/TestEcharts.html" >iframe>
div>
div>
div>
body>
html>
这就是一个简单的可视化了,由于将视频懒得转GIF动图了,所以我就截个图看看就行
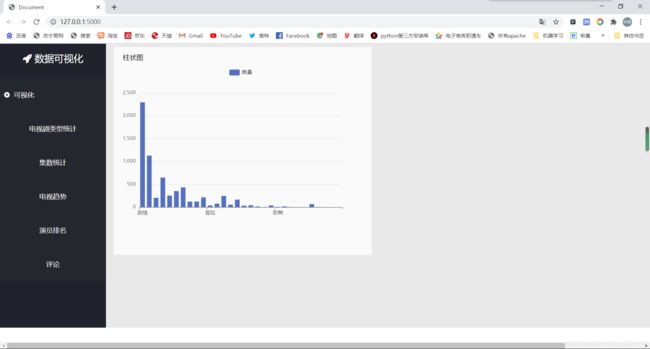
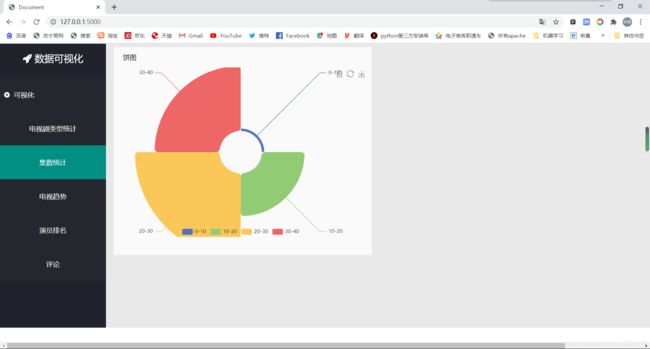
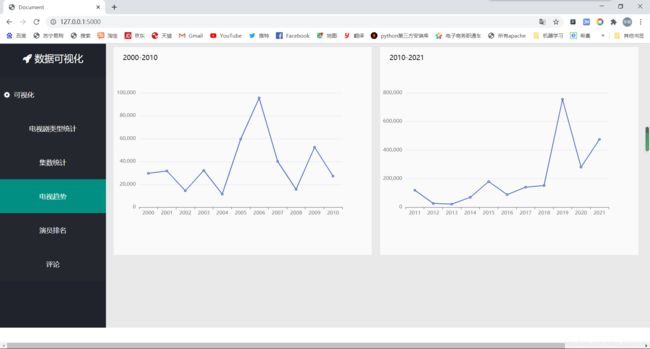
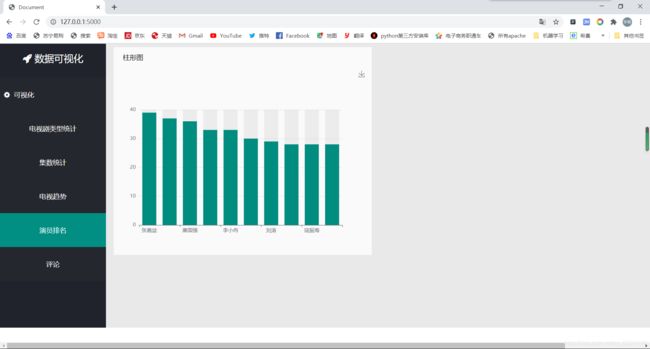
对了 我这里词云加载用的是网络的js接口:https://cdn.bootcss.com/echarts/3.7.0/echarts.simple.js
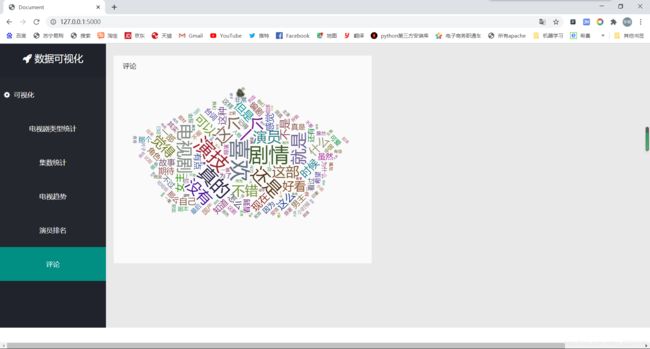
- 到这里就是全部过程了
- 由于我是第一次写博客,不怎么美观,所以将就看看嘛
- 感谢观看全过程的朋友哦!!!