HA高可用集群文档搭建
HA高可用集群文档搭建
准备工作
1.准备好三台虚拟机分别为hadoop01、hadoop02、hadoop03
创建安装包以及安装后的文档文件夹
[root@hadoop01 ~]# mkdir export
[root@hadoop01 ~]# cd export
[root@hadoop01 export]# mkdir servers
[root@hadoop01 export]# mkdir softwares
2.准备好ZOOKEEPER与HADOOP包以及安装好Java
安装包:
我这里用的安装包是:hadoop-2.9.2.tar.gz、zookeeper-3.4.9.tar.gz、jdk-8u181-linux-x64.tar.gz
3.记得配置免登录
三台虚拟都要配置免登录以免后续密码的频繁输入
- hadoop01 ——> hadoop01、hadoop02、hadoop03
- hadoop02——> hadoop01、hadoop02、hadoop03
- hadoop03 ——> hadoop01、hadoop02、hadoop03
HA的规划
- 192.168.46.121 hadoop01 namenode、datanode、jouranlnode、quroumPeerMain、zkf
- 192.168.46.121 hadoop02 namenode、datanode、jouranlnode、quroumPeerMain、zkf
- 192.168.46.121 hadoop03 datanode、jouranlnode、quroumPeerMain
安装流程
1.安装HADOOP
2.安装ZOOKEEPER
启动流程
1.三台虚拟机必须先启动ZOOKEEPER
2.后续再启动HA高可用集群
安装HADOOP
配置hadoop配置文件:
1、hadoop-env.sh
2、core-site.xml
3、hdfs-site.xml
4、yarn-site.xml
5、mapred-site.xml
6、slaves
1、将servers里的hadoop包解压到softwares文件下的新建的hadoop文件
1. [root@hadoop01 servers]# mkdir ../softwares/hadoop
2. [root@hadoop01 servers]# tar -zxvf hadoop-2.9.2.tar.gz -C /root/export/softwares/hadoop
3. # 配置环境变量
vi /etc/profile
# 添加如下变量
export HADOOP_HOME=/root/export/softwares/hadoop/hadoop-2.9.2.tar.gz
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH$:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
退出保存 wq
4. 刷新变量
source /etc/profile
2、修改Hadoop的配置文件
2.1、hadoop-env.sh
将该文件中的“export JAVA_HOME=”这一行改为你安装java的路径地址

2.2、core-site.xml
在该文件底部添加:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://vkchenvalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/root/export/softwares/hahadoopdata/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181value>
property>
configuration>
2.3、hdfs-site.xml
在该文件底部configuration中添加:
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.name.dirname>
<value>/root/export/softwares/hahadoopdata/dfsdata/namenodevalue>
property>
<property>
<name>dfs.data.dirname>
<value>/root/export/softwares/hahadoopdata/dfsdata/datanodevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>vkchenvalue>
property>
<property>
<name>dfs.ha.namenodes.vkchenname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.vkchen.nn1name>
<value>hadoop01:9000value>
property>
<property>
<name>dfs.namenode.rpc-address.vkchen.nn2name>
<value>hadoop02:9000value>
property>
<property>
<name>dfs.namenode.http-address.vkchen.nn2name>
<value>hadoop01:50070value>
property>
<property>
<name>dfs.namenode.http-address.vkchen.nn2name>
<value>hadoop02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/vkchenvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/root/export/softwares/hahadoopdata/journal/datavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.vkchenname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
2.4、yarn-site.xml
在该文件底部configuration中添加:
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>vkoingvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop02value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>hadoop01:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>hadoop02:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
2.5、mapred-site.xml
先将mapred-site.xml.template改名为mapred-site.xml
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml
后在该文件底部configuration中添加:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<final>truefinal>
property>
configuration>
2.6、slaves
在该文件中添加如下:
hadoop01
hadoop02
hadoop03
3、分别将配置好的hadoop分别分发到另外两台虚拟机中
# 删除这个文件可以利于我们的发送
[root@hadoop01 hadoop-2.9.2]# rm -rf ./share/doc/
[root@hadoop01 hadoop-2.9.2]# cd ..
[root@hadoop01 hadoop]# scp -r hadoop-2.9.2 root@hadoop02:/root/export/softwares/hadoop
[root@hadoop01 hadoop]# scp -r hadoop-2.9.2 root@hadoop03:/root/export/softwares/hadoop
记得另外两台也得配置环境变量
安装ZOOKEEPER
1、将servers里的zookeeper包解压到softwares文件下的新建的zk文件
1. [root@hadoop01 servers]# mkdir ../softwares/zk
2. [root@hadoop01 servers]# tar -zxvf zookeeper-3.4.9.tar.gz -C /root/export/softwares/zk
3. # 配置环境变量
vi /etc/profile
# 添加如下变量
# Zookeeper
export ZK_HOME=/root/export/softwares/zk/zookeeper-3.4.9
export PATH=$PATH:$ZK_HOME/bin
退出保存 wq
4. 刷新变量
source /etc/profile
2、修改zookeeper的配置文件
2.1配置zoo.cnf文件
[root@hadoop01 ~]# cd export/softwares/zk/zookeeper-3.4.9
# 删除该文件有利于后续传输
[root@hadoop01 zookeeper-3.4.9]# rm -rf /docs/
[root@hadoop01 zookeeper-3.4.9]# cd conf
[root@hadoop01 conf]#mv zoo_sample.cfg zoo.cfg
[root@hadoop01 conf]#vi zoo.cfg
# 把 dataDir 那一行修改成自己的地址,最后在文件最后再加上三行server的配置
dataDir=/root/export/softwares/zk/zkdata # 这个就是自己设定,想放哪里都可以,它是用于存储块键目录的
# server.1是服务名序号 你想怎么排序都可以 server.0也行,就是到时候要myid文件必须跟设定的服务序号一样
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
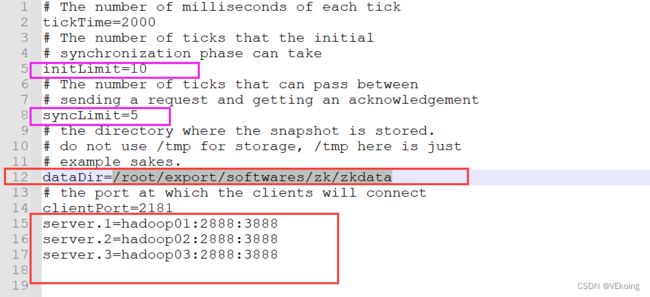
- 该图中红色是要更改的,紫色圈起来的是可以更改可以不更改的,这里我没有更改,如果想要改这个或是理解这个建议去看一下官方文档
- 官方文档中initLimit是为5,syncLimit是为2
2.2配置myid文件
[root@hadoop01 conf]# cd ..
[root@hadoop01 zookeeper-3.4.9]# mkdir data
[root@hadoop01 zookeeper-3.4.9]# cd data
[root@hadoop01 data]# vi myid
# 在文件写入为:
1
3、配置另外两个节点
把上面配置好的zookeeper文件夹直接传到两个子节点
[root@master data]# cd ../../..
[root@master softwares]# scp -r zookeeper root@slave1:/root/export/softwares/
[root@master softwares]# scp -r zookeeper root@slave2:/root/export/softwares/
# 注意在两个子节点上把myid文件里面的 1 给分别替换成 2 和 3
# 注意在两个子节点上像步骤1一样,在/etc/profile文件里配置zookeeper的环境变量,保存后别忘source一下
测试
# 在三个节点上分别执行命令,启动服务: zkServer.sh start
# 在三个节点上分别执行命令,查看状态: zkServer.sh status
# 正确结果应该是:三个节点中其中一个是leader,另外两个是follower
# 在三个节点上分别执行命令: jps
# 检查三个节点是否都有QuromPeerMain进程
启动流程
下面是Hadoop的HA集群启动流程:
第一步,在Hadoop01机器上启动Zookeeper:
[root@hadoop01 ~]# /root/apps/zookeeper/bin/zkServer.sh start
第二步,在Hadoop02机器上启动Zookeeper:
[root@hadoop02 ~]# /root/apps/zookeeper/bin/zkServer.sh start
第三步,在Hadoop03机器上启动Zookeeper:
[root@hadoop03 ~]# /root/apps/zookeeper/bin/zkServer.sh start
启动Zookeeper之后,可以分别在3台机器上使用如下命令查看Zookeeper的启动状态:
/root/apps/zookeeper/bin/zkServer.sh status
第四步,在Hadoop01机器上启动journalnode:
[root@hadoop01 ~]# hadoop-daemons.sh start journalnode
第五步,在Hadoop01机器上格式化namenode:
[root@hadoop01 ~]# hdfs namenode -format
# 此时会在我们设定的softwares下会多出一个hahadoopdata 里面存放着我们在配置文件中的数据存储文件路径地址 存储的元数据之类的
第六步,在Hadoop02同步元数据:
# 单个启动
[root@hadoop02 ~]# hadoop-daemon.sh start namenode
# 拉取元数据
[root@hadoop02 ~]# hdfs namenode -bootstrapStandby
# 此时在hadoop02虚拟机中也有了hahadoopdata文件并且存在namenode的文件数据地址
第七步,格式化zkfc
[root@hadoop01 ~]# hdfs zkfc -formatZK
# 此时在zk中创建了hadoop-ha 并在hadoop-ha中也有我们自己设定的hdfs的虚拟服务名 vkchen

第八步,启动:
# 在Hadoop01机器上启动HDFS,YARN
[root@hadoop01 ~]# start-dfs.sh
[root@hadoop01 ~]# start-yarn.sh
第九步,在Hadoop02机器上单独启动一个ResourceManager:
(注意这里使用的是“yarn-daemon.sh”命令,而不是“hadoop-daemon.sh”,不知道为什么使用“hadoop-daemon.sh”无法启动ResourceManager)
[root@hadoop02 ~]# /root/apps/hadoop/sbin/yarn-daemon.sh start resourcemanager
第十步:分别在3台机器上使用jps命令查看进程:
[root@hadoop01 ~]# jps
2836 ResourceManager
2310 DataNode
2036 QuorumPeerMain
2630 DFSZKFailoverController
2481 JournalNode
2938 NodeManager
3212 Jps
2212 NameNode
[root@hadoop02 ~]# jps
2489 DFSZKFailoverController
3281 Jps
2193 QuorumPeerMain
2292 NameNode
2348 DataNode
3028 NodeManager
2427 JournalNode
3244 ResourceManager
[root@hadoop03 ~]# jps
2734 Jps
2420 DataNode
2327 QuorumPeerMain
2484 JournalNode
2616 NodeManager
[root@hadoop03 ~]#
可以进行HA测试
如果某一个NameNode进程挂掉了的话,就使用如下命令单独启动一个NameNode:
# hadoop-daemon.sh start namenode
先杀死一个namenode然看是否能进行自动切换active以及standby
比如杀死hadoop01的namenode 因为hadoop01的web ui 是active,hadoop02是standby,当杀死hadoop01的namenode后,查看hadoop02是否会切换为active
并且测试当杀死后是否能进行hdfs操作
还可以进行yarn的高可用测试,这里就不写了,流程也是跟测试namenode是一样的
下面是停止Hadoop的HA集群的流程:
第一步,在Hadoop01机器上停止HDFS:
[root@hadoop01 ~]# /root/apps/hadoop/sbin/stop-dfs.sh
第二步,在Hadoop01机器上停止YARN:
[root@hadoop01 ~]# /root/apps/hadoop/sbin/stop-yarn.sh
第三步,在Hadoop02机器上单独停止ResourceManager:
[root@hadoop02 ~]# /root/apps/hadoop/sbin/yarn-daemon.sh stop resourcemanager
第四步,在Hadoop01机器上停止Zookeeper:
[root@hadoop01 ~]# /root/apps/zookeeper/bin/zkServer.sh stop
第五步,在Hadoop02机器上停止Zookeeper:
[root@hadoop02 ~]# /root/apps/zookeeper/bin/zkServer.sh stop
第六步,在Hadoop03机器上停止Zookeeper:
[root@hadoop03 ~]# /root/apps/zookeeper/bin/zkServer.sh stop
最后,分别在3台机器上使用jps命令查看进程,确定有关进程是否停止成功。
[root@hadoop01 ~]# jps
4455 Jps
[root@hadoop02 sbin]# jps
4713 Jps
[root@hadoop03 ~]# jps
3208 Jps
如果启动或停止Hadoop的时候,遇到了问题,我们想查看一下日志,由于日志中的内容可能会非常多,我们改怎么查看呢?我们以查看hadoop01机器上的namenode的日志为例来说明一下,这里我们使用的是less命令:
[root@hadoop01 ~]# less /root/apps/hadoop/logs/hadoop-root-namenode-hadoop01.log
使用以上命令进入到日志之后,按回车光标处会显示一个冒号,输入斜杠“/”会进入到搜索模式,输入关键字再按回车,可以在日志中查询关键字小写的字母“n”可以向下搜索关键字,输入大写的字母“N”可以向上查找关键字。在键盘上输入大写的字母“G”,可以瞬间跳转到日志的末尾。
zkServer.sh stop
最后,分别在3台机器上使用jps命令查看进程,确定有关进程是否停止成功。
```bash
[root@hadoop01 ~]# jps
4455 Jps
[root@hadoop02 sbin]# jps
4713 Jps
[root@hadoop03 ~]# jps
3208 Jps
如果启动或停止Hadoop的时候,遇到了问题,我们想查看一下日志,由于日志中的内容可能会非常多,我们改怎么查看呢?我们以查看hadoop01机器上的namenode的日志为例来说明一下,这里我们使用的是less命令:
[root@hadoop01 ~]# less /root/apps/hadoop/logs/hadoop-root-namenode-hadoop01.log
使用以上命令进入到日志之后,按回车光标处会显示一个冒号,输入斜杠“/”会进入到搜索模式,输入关键字再按回车,可以在日志中查询关键字小写的字母“n”可以向下搜索关键字,输入大写的字母“N”可以向上查找关键字。在键盘上输入大写的字母“G”,可以瞬间跳转到日志的末尾。
输入小写字母“q”可以退出日志。