百人计划(程序)2
第三章 进阶应用
一、深度与模板测试 Z Test & Stencil Test
-
模板测试
1.模板测试概述:
①从渲染管线角度(逐片元操作流程):


PixelOwnershipTest:控制对当前屏幕像素的使用权限,没有使用权限的屏幕上的像素会被裁剪。
Scissor Test:可以控制需要渲染的部分。
Alpha Test:通过设置一个阈值(0到1),对比数值进行渲染设置。只能实现不透明或全透明效果。
Blending:实现半透明效果。
②从逻辑的角度:

通过一定条件来判断是对该片元或片元属性执行抛弃操作还是保留操作。
③从书面的角度:

模板测试:模板缓冲区可以为屏幕上的每个像素点保存一个无符号整数值(通常的话是个8位整数)。这个值的具体意义视程序的具体应用而定。在渲染的过程中,可以用这个值与一个预先设定的参考值相比较,根据比较的结果来决定是否更新相应的像素点的颜色值。
模板测试发生在透明度测试(alpha test)之后,深度测试(depth test)之前。
如果模板测试通过,则相应的像素点更新,否则不更新。
2.举例:

*共同点:分为三层结构(门外场景、门、门内场景)
3.Unity Shader中的模板测试具体表现:
①模板测试结构:
stencil{
//给当前的片元设定一个参考值 0~25 用来和模板缓冲区的值作比较
Ref referenceValue
//读取遮罩值
ReadMask readMask
//写遮罩值
WriteMask writeMask
//设置比较操作函数
Comp comparisonFunction
//模板测试通过了 模板缓冲区对应的操作
Pass stencilOperation
//模板测试失败 模板缓冲区对应的操作
Fail stencilOperation
//模板测试通过 但深度测试没通过 模板缓冲区对应的操作
ZFail stencilOperation
}②ComparisonFunction:

③StencilOperation 更新值:

4.案例效果:
①3D卡牌效果:
*Unity中模板缓冲区默认都是0
StencilMask shader代码:


物体Shader代码:
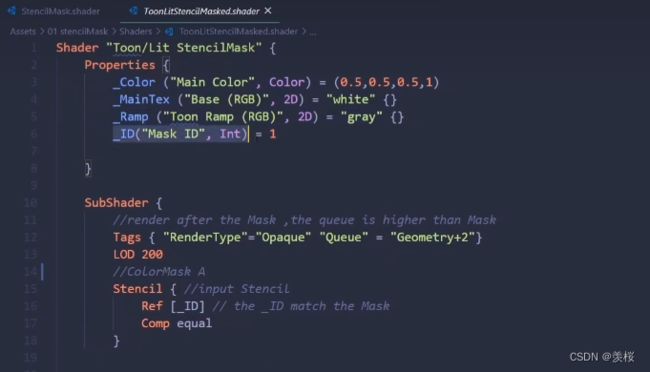
渲染队列在模板遮罩后,并且如果ID值和当前模板缓冲区的值一样才会渲染,否则就抛弃。
②盒子不同面显示不同场景:

渲染顺序是Queue越小,越先渲染,先渲染好Queue小的物体,那么Queue大的物体覆盖已经渲染好的Queue小物体的,表现效果就是Queue大的物体在Queue小的物体“前面”,符合引擎渲染实际情况。
代码:

*模板测试总结:
1.使用模板缓冲区最重要的两个值:当前模板缓冲值(stencilBufferValue)和模板参考值(referenceValue)。
2.模板测试主要就是对这两个值使用特定的比较操作:Never,Always,Less ,LEqual,Greater,Equal等等。
3.模板测试之后要对模板缓冲区的值(stencilBufferValue)进行更新操作,更新操作包括:Keep,Zero,Replace,IncrSat,DecrSat,Invert等等。
4.模板测试之后可以根据结果对模板缓冲区做不同的更新操作,比如模板测试成功操作Pass,模板测试失败操作Fail,深度测试失败操作ZFail,还有正对正面和背面精确更新操作PassBack,PassFront,FailBack等等。
5.模板测试拓展:

-
深度测试
1.深度测试概述:
①从渲染管线来说(逐片元操作流程): 模板测试 → 深度测试 → 透明度混合
②从逻辑上来说:

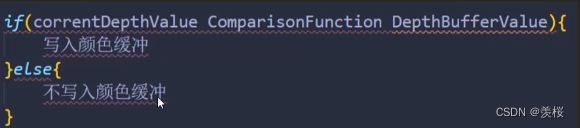
③从书面上来说:
所谓深度测试,就是针对当前对象在屏幕上(更准确的说是frame buffer)对应的像素点,将对象自身的深度值与当前该像素点缓存的深度值进行比较,如果通过了,本对象在该像素点才会将颜色写入颜色缓冲区,否则否则不会写入颜色缓冲。
④从发展上理解:

画家算法:从远离屏幕的物体开始渲染,一层层叠加在上面。(造成很大的性能浪费,即Over Draw)。
Z-Buffer:通过深度缓冲区来控制渲染顺序。
2.深度缓冲区 Z-Buffer:
深度缓冲就像颜色缓冲(储存所有的片段颜色:视觉输出)一样,在每个片段中储存了信息,并且(通常)和颜色缓冲有着一样的宽度和高度。深度缓冲是由窗口系统自动创建的,它会以16、24或32位float的形式储存它的深度值。在大部分的系统中,深度缓冲的精度都是24位的。
z-buffer中存储的是当前的深度信息,对于每个像素存储一个深度值。
通过 Z Write 和 Z Test 来调用 Z-Buffer,实现想要的渲染结果。
3.深度写入 Z Write:

开启深度写入 并且通过深度测试,才会写入深度缓冲区。
4.深度测试 Z Test:

默认情况:Z Write On & Z Test LEqual,深度缓存一开始为无穷大
5.渲染队列:
①Unity内置的渲染队列:按照渲染顺序,从先到后进行排序, 队列数越小的,越先渲染,队列数越大的,越后渲染。
②Unity中设置渲染队列:Tags { “Queue” = “Transparent” },默认是Geometry。
③不透明物体的渲染顺序:从前往后
透明物体的渲染顺序:从后往前(会造成OverDraw)

6.Early Z技术:

7.深度值:

*为什么深度缓冲区中要存储一个非线性的深度值?
①给离镜头更近的物体更多的精度。
深度缓冲区的深度值是介于0~1的,从观察者看到其内容与场景中的所有对象的 z 值进行了比较。正确的投影特性的非线性深度方程是和1/z成正比的 。这样基本上做的是在z很近是的高精度和 z 很远的时候的低精度。
值为 0.5 在深度缓冲区并不意味着该对象的 z 值是投影平头截体的中间;顶点的 z 值是实际上相当接近近平面的。
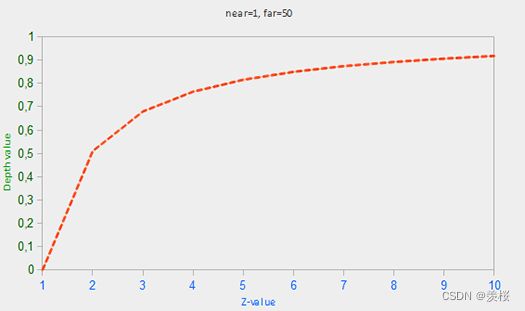
②避免近处深度冲突(Z-fighting):
两个平面或三角形如此紧密相互平行深度缓冲区不具有足够的精度以至于无法得到哪一个靠前。结果是,这两个形状不断似乎切换顺序导致怪异出问题。深度冲突是深度缓冲区的普遍问题,当对象的距离越远一般越强(因为深度缓冲区在z值非常大的时候没有很高的精度)。
8.深度测试案例:
①案例一:

代码:
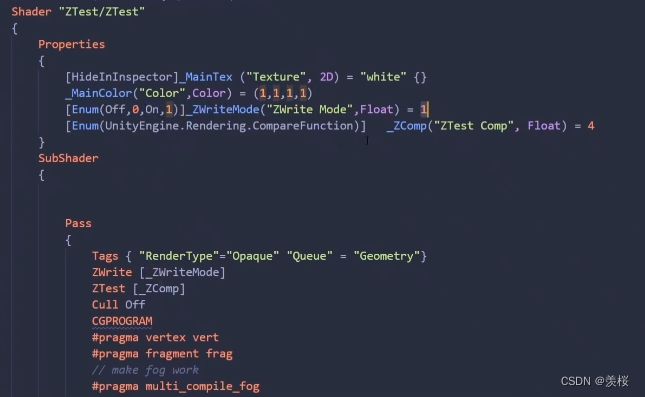


②案例二:

代码:
XRay:




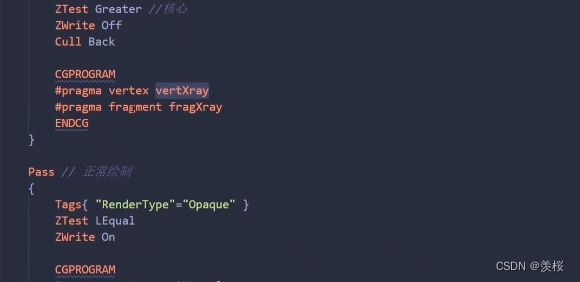
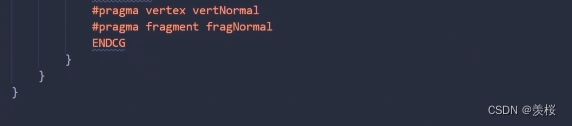
*深度测试总结:
使用深度缓冲区最重要的两个值:当前深度缓冲值(ZBufferValue)和深度参考值(referenceValue),并通过比较操作获取理想渲染效果。
Unity中的渲染顺序:先渲染不透明物体,顺序是从前到后;再渲染透明物体,顺序是从后到前。
通过Zwrite 和Z Test组合使用控制半透明物体的渲染。
引入early-z技术后的深度测试相关的渲染流程。
深度缓冲区中存储的深度值为0到1范围的浮点值,且为非线性。
9.深度测试拓展:

二、混合模式和剔除
-
混合模式(Blend)
1.混合模式:就是把两种颜色混在一起。具体就是把某一像素位置原来的颜色和将要画上去的颜色,通过某种方式或者算法混在一起,从而实现新的效果。
最终颜色 = Shader计算后的颜色值 * 源因子(SrcFactor) +累积颜色 * 目标因子(DstFactor)
累计颜色可以理解为渲染当前物体后面的颜色即GBuffer中的像素,比如你的背景,还有身后的物体。 混合模式控制的就是源因子和目标因子,在脚本里会看到的就是 :Blend SrcFactor DstFactor
2.混合模式的类型:
①PS的混合模式:

②ShaderLab中的混合模式:

Ⅰ 如果颜色的某一分量超过了1.0,则它会被自动截取为1.0,不需要考虑越界的问题。
Ⅱ 在所有着色器执行完毕,所有纹理都被应用,所有像素准备被呈现到屏幕之后,使用Blend命令来操作这些像素进行混合。
Ⅲ 语法
| Blend Off | 关闭blend混合(默认值)。 |
| Blend SrcFactor DstFactor | 配置并启动混合。Shader产生的颜色被乘以SrcFactor,已存在于屏幕的颜色乘以DstFactor,并且两者将被加在一起。 |
| Blend SrcFactor DstFactor, SrcFactorA DstFactorA | 同上,但是使用不同的要素来混合alpha通道。 |
| BlendOp Value | 如果使用 BlendOp 命令,则混合操作将设置为该值。否则,混合操作默认为 Add。不是添加混合颜色在一起,而是对它们做不同的操作。 |
| BlendOp OpColor, OpAlpha | 同上,但是使用不同的操作来处理alpha通道. |
| AlphaToMaskOn | 常用在开启多重渲染(MSAA)的地表植被的渲染 |
Ⅳ 混合因子
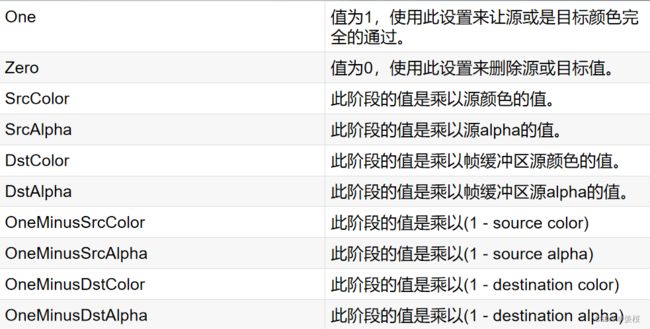
Ⅴ操作符

总结:

3.混合模式的实现方法:


没有在SubShader的uniform内写入_Src/DstBlend值,是因为我们的混合操作不是在shader层内。
-
剔除
①法线剔除:也称为背面消隐,根据法线朝向判断哪个面被剔除掉。 可以用来控制是否双面渲染。
语法:Cull(Off Front Back)
②面裁切:clip函数会将参数小于某像素点直接在片元阶段丢弃掉,常用于制作溶解,裁剪等效果。
语法:Clip();默认会切掉0.5的部分。 或者使用if。


*总结:
1.开启双面渲染相当于绘制了两次。
2.Clip函数在某些PowerVR的机型上效率很低。
3.面裁切Clip使用AlphaTest队列。
三、曲面细分着色器和几何着色器
-
曲面细分着色器(Tessellation Shader)
1.曲面细分着色器的应用:
①海浪、雪地等

②与置换贴图的结合

可以用来制作海浪、雪地里出现的脚印;改变物体形状。可以根据距离或者自定的规则来动态调整模型的复杂度。
2.输入和输出:
①输入:Patch(可以看成多个顶点的几何,包含每个顶点的属性,可以指定一个Patch包含的顶点数以及自己的属性)
②功能:将图元进行细分(可以是三角形、矩形等)
③输出:细分后的顶点
3.曲面细分着色器的流程:
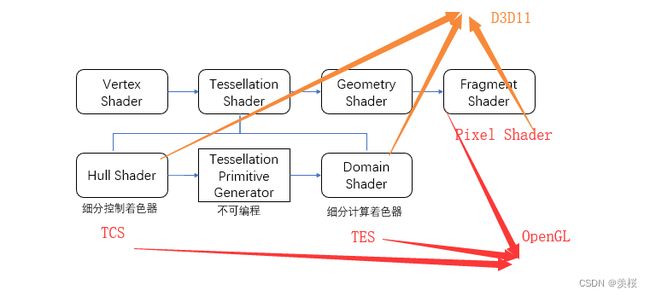
①Hull Shader:
Ⅰ决定细分的数量(设定Tessellation factor以及Inner Tessellation factor)
*Tessellation factor:
equal_Spacing(等分,并限制在[1, max], 如果有小数则向上取整)
fractional_even_spacing(限制在[2, max], 向上取最近的偶数)
fractional_odd_spacing(限制在[1, max - 1], 向上取最近的奇数,周长会被划分为n-2的等长部分,以及两个位于两端的部分(可能比中间部分更短)。具体长度与小数部分有关,为了获取更平滑的细分。)
![]()
![]()
![]()
*Inner Tessellation factor:

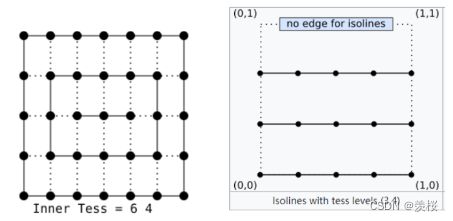
Ⅱ对输入的patch参数进行改变(如果需要)
②Tessellation Primitive Generation: 进行细分操作(不可编程)
③Domain Shader:对细分后的点进行处理,从重心空间转换到屏幕空间
-
几何着色器(Geometry Shader)
1.几何着色器的应用:
①几何动画
②草地等(与曲面细分着色器结合)

四、延迟渲染(RenderPath)
-
渲染路径(Rendering Path)
渲染路径即决定光照的实现方式。简言之,就是当前渲染目标使用光照的流程。
-
渲染方式
1.前向渲染(Forward Rendering):
①具体流程:

在渲染每一帧时,每个顶点/片元都要执行一次片元着色器代码,这时需要将所有的光照信息都传递到片元着色器中。虽然大部分情况下的光源都趋向于小型化,而其照亮的区域也不大,但即便是光源离这个像素所对应的世界空间中的位置很远,但计算光照时,还是会把所有的光源都考虑进去。
*总结:计算光源时会把所有光源都计算进去,造成很大浪费。
2.延迟渲染(Deferred Rendering):
①原理介绍:主要解决大量光照渲染的方案。延迟渲染的实质,是先不要做迭代三角形做光照计算,而是先找出来你能看到的所有像素,再去迭代光照。直接迭代三角形的话,由于大量三角形你是看不到的,无疑是极大的浪费。
②流程:
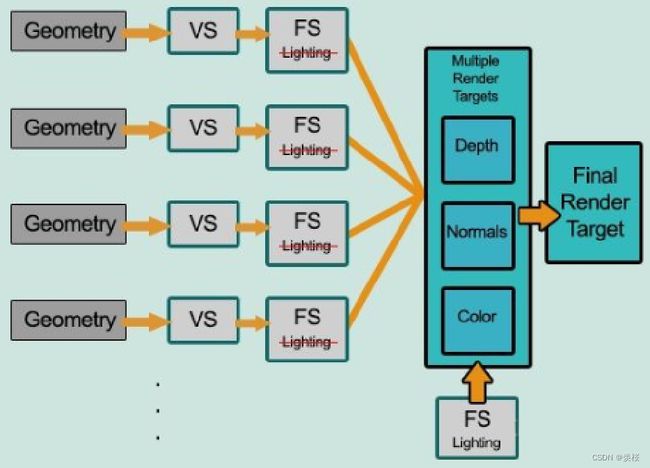
Ⅰ将渲染过程拆分成两个渲染通路(pass)。
Ⅱ第一个pass称为几何处理通路。首先将场景渲染一次,获取到待渲染对象的各种几何信息存储到名为G-buffer的缓冲区中,这些缓冲区将会在之后用作更复杂的光照计算。由于有深度测试,所以最终写入G-buffer中的各个数据都是离摄像机最近的片元的几何属性,这意味着最后在G-buffer中的片元必定要进行光照计算的。
Ⅲ第二个pass称为光照处理通路。该pass会遍历所有G-buffer中的位置、颜色、法线等参数,执行一次光照计算。
RT(G-buffer)相当于把整个屏幕的信息绘制到一个图中,每个RT都可以写到一个G-buffer中。
G-buffer中的数据都是2D的,所以我们的光照计算就相当于一个2D的光照后处理。
 G-Buffer
G-Buffer
③G-Buffer:指Geometry Buffer,亦即“几何缓冲”。区别于普通的仅将颜色渲染到纹理中,G-Buffer指包含颜色、法线、世界空间坐标的缓冲区,亦即指包含颜色、法线、世界空间坐标的纹理。由于G-Buffer需要的向量长度超出通常纹理能包含的向量的长度,通常在游戏开发中,使用多渲染目标技术来生成G-Buffer,即在一次绘制中将颜色、法线、世界空间坐标分别渲染到三张浮点纹理中。
④延迟渲染不支持不透明物体的渲染,延迟渲染中的透明物体渲染方式为前向渲染。(没有深度信息)
3.不同渲染路径的优劣及特性:
①特性:
后处理方式不同。(如果需要深度信息进行后处理,前向渲染需要单独渲染出一张深度图,延迟渲染直接用G-buffer中的深度信息计算即可)
着色计算不同(shader)。(延迟渲染因为是最后统一计算光照的,所以只能算一个光照模型(如果需要其他光照模型,只能切换pass))
抗锯齿方式不同
②前向渲染:
优点:1.支持半透明渲染 2.支持使用多个光照pass 3.支持自定义光照计算方式
缺点:1.光源数量对计算复杂度影响巨大 2.访问深度等数据需要额外计算(额外渲染一张深度图)。
③延迟渲染:
优点:1.大量光照场景优势明显 2.只渲染可见像素,节省计算量 3.对后处理支持良好 4.用更少的shader
缺点:1.不支持MSAA 2.不能渲染透明物体 3.占用大量的显存带宽
-
渲染路径设置

-
移动端优化
两个TBDR
一个是SIGGRAPH 2010上提出的,通过分块来降低带宽内存用量
一个是PowerVR基于手机GPU的TBR架构提出的,通过HSR减少overdraw
-
其他渲染路径

https://zhuanlan.zhihu.com/p/54694743
-
关于MSAA
https://docs.microsoft.com/en-us/windows/win32/direct3d9/multiple-render-targets
https://catlikecoding.com/unity/tutorials/rendering/part-13/
http://docs.nvidia.com/gameworks/index.html#gameworkslibrary/graphicssamples/d3d_samples/antialiaseddeferredrendering.htm
五、early-Z 与 Z-Prepass
-
(前置知识)深度测试Depth Test
1.深度测试位于逐片元操作中的模板测试后,透明度混合前。

2.深度测试是用来解决物体遮挡的问题:


3.深度测试的流程和逻辑:
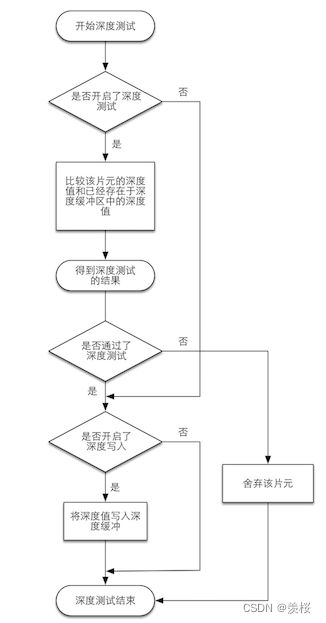

4.深度测试带来的问题:
性能浪费:深度测试前计算过的部分片元未通过深度测试会被抛弃掉,则深度测试前的计算就是性能浪费。
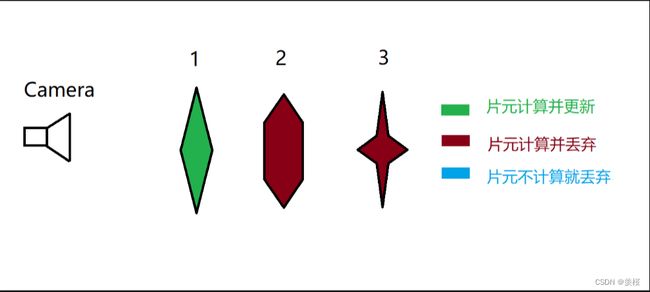
5.解决方法:early-z
-
提前深度测试 early-Z
1.early-z位于光栅化阶段后,片元着色器之前。

2.early-z流程:
①先渲染1的深度值,写入深度缓冲区中,当进行2和3的渲染时,会进行early-z的判断,不通过就不会进行片元着色器及以下的计算。
②在early-z的阶段可以添加模板测试。
③提前的深度测试叫做z-cull 后续的深度测试为了确定正确的遮挡关系,叫作Z-Check。

3.early-z失效:
①开启Alpha Test 或 clip/discard 等手动丢弃片元操作
②手动修改GPU插值得到的深度
③开启Alpha Blend (Zwrite Off)
④关闭深度测试Depth Test
4.如何高效利用early-z:
①在渲染前,cpu将不透明物体从近往远排序,再给gpu渲染。(但是复杂的场景,cpu性能消耗很大;严格按照由近到远的顺序渲染,将不能同时搭配批处理优化手段。)
②pre-z
-
使用Z-Prepass
1.方式1:
①双Pass法(在第一个Pass即Z-Prepass中仅仅只写入深度,不计算输出任何颜色,在第二个Pass中关闭深度写入,并且将深度比较函数设置为相等,进行正常的透明度混合。)
②效果:每个物体都会渲染两个pass,且所有物体的z-prepass的结果就自动形成了一个最小深度值的缓冲区Z-buffer,无需cpu进行排序。
Shader "Custom/EarlyZPresentation"{
Properties{ //.......}
SubShader
{
Tags { "RenderType"="Opaque" }
//Z-Prepass部分
Pass
{
ZWrite On //开启深度写入
ColorMask 0 //关闭颜色输出
CGPROGRAM
//...这里省略了单纯地顶点变换计算部分
ENDCG
}
//正常地计算输出颜色的Pass
Pass
{
Zwrite Off //关闭深度写入
ZTest Equal //深度相等为通过
CGPROGRAM
//...这里省略了顶点变换和颜色等计算部分
ENDCG
}
}
}③问题:
Ⅰ动态批处理(多pass shader无法进行动态批处理 ---> Draw Call问题)
ⅡDraw Call(使用z-prepass shader 的物体,draw call会多一倍)

2.方式2:
①提前分离的PrePass:仍然使用两个Pass,将原先第一个Pass(即Z-Prepass)单独分离出来为单独一个Shader,并先使用这个Shader将整个场景的Opaque的物体渲染一遍。而原先材质只剩下原先的第二个Pass,仍然关闭深度写入,并且将深度比较函数设置为相等。
②效果:用于解决DrawCall问题
③例子:使用URP下的RendererFeature
勘误(评论区):URP的SRP batch做的合批是不会减少Draw Call的,他的最大的优化在于合并set pass call,减少set pass call的开销,因为CPU上的最大开销来自于准备工作(设置工作),而非DrawCall本身(这只是要放置GPU命令缓冲区的一些字节而已),draw call是不会减少的。可以看看这篇文章翻译https://blog.csdn.net/lsjsoft/article/details/90734932
3.Z-Prepass也是透明渲染的一种解决方案:

问题:无法看到透明物体的背面
→解决方法:透明物体双面渲染(pass1渲染背面 pass2渲染正面)
*由于Unity会顺序执行Subshader中的各个Pass,所以我们可以保证背面总是在正面被渲染之前渲染,来得到正确的深度渲染关系。
-
Z-Prepass所带来的问题
1.性能消耗是否能被忽视:
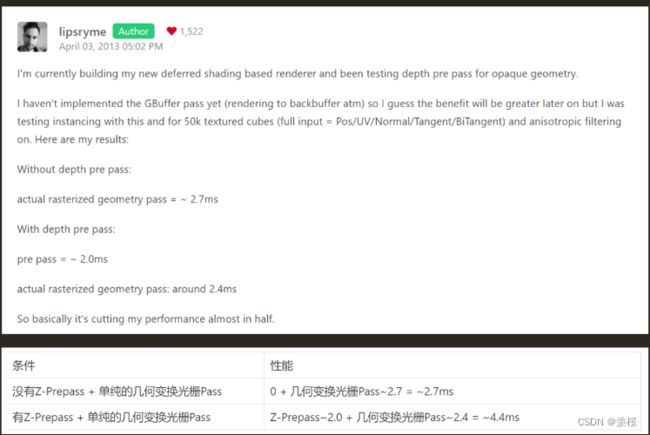
结论:当一个有非常多OverDraw的场景,且不能很好的将不透明物体从前往后进行排序时,可以考虑使用PreZ进行优化。PreZ会增加DrawCall,如果用错了可能是负优化。
-
Early-Z 和 Z-prepass的实例应用
1.面片叠加的头发渲染:对于半透明的面片来说,需要从后往前进行排序渲染才能得到正确的透明度混合结果。


问题:会带来很多OverDraw的问题。
2.性能改善:使用Early-Z剔除,透明度测试开启时Early-Z无法使用的解决方案:使用一个简单的shader进行透明度测试形成 Z-Buffer。(就是我们上边说的提前分离的z-prepass)

3.改善的渲染方案:

六、纹理压缩
-
纹理压缩概述:
1.纹理压缩:为了解决内存、带宽问题,专为在计算机图形渲染系统中存储纹理而使用的图像压缩技术。
2.图片与纹理:
①图片格式:图片格式是图片文件的存储格式,通常在磁盘、内存中储存和传输文件时使用;例如:JPG、PNG、GIF、BMP等;
②纹理格式:纹理格式是显卡能够直接进行采样的纹理数据格式,通常在向显卡中加载纹理时使用;
3.纹理管线:
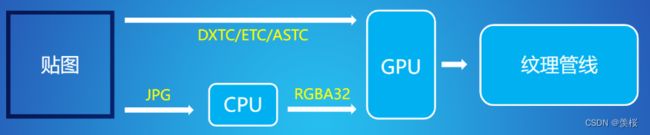
①纹理压缩格式基于块压缩,能够更快读取像素所属字节块进行解压缩以支持随机访问;
②图片压缩格式基于整张图片进行压缩,无法直接实现单个像素的解析;
③图片压缩格式无法被GPU识别,还需要经CPU解压缩成非压缩纹理格式才能被识别;
4.常见纹理格式:
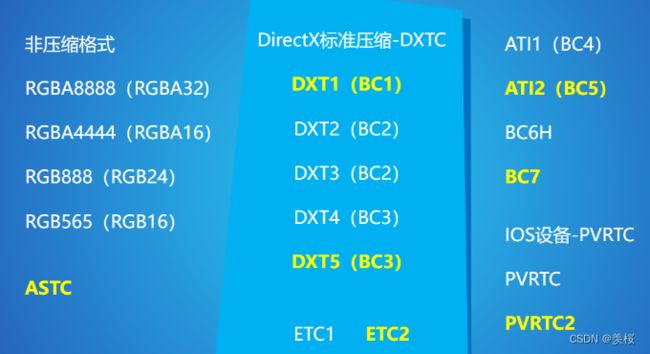
*黄色为最常用格式、
5.非压缩格式:
①RGBA8888(RGBA32):一个像素32位,包含A通道,所以一个像素消耗:4 * 8 = 32位(bit)= 4字节(byte),即一个像素消耗4字节;
②RGBA4444(RGBA16):一个像素16位,包含A通道,一个像素消耗:4 * 4 = 16位 = 2字节,即一个像素消耗2字节;
③RGB888(RGB24):一个像素24位,无A通道,即一个像素消耗3字节;
④RGB565(RGB16):一个像素16位,无A通道,即一个像素消耗2字节;
-
DXTC
①DCTC纹理压缩格式来源于S3公司提出的S3TC算法,基本思想是把4×4的像素块压缩成一个64或128位的数据块,优点为创建了一个固定大小且独立的编码片段,没有共享查找表或其他依赖关系,简化了解码过程;
②DXT1:每一个块具有2个16位RGB颜色值(RGB565),代表了此4×4像素块中颜色极端值,然后通过线性插值计算出两个中间颜色值,16个2位索引值则表示了每一个像素的颜色值索引;
③DXT2/3:DXT2/3与DXT1类似,表示颜色信息的64位数据块不变,另外附加了64位数据来表示每个像素的Alpha信息,整个数据块变为了128位;每个像素占用8位,0-3表示透明信息,4-7表示颜色信息;
④DXT4/5:DXT4/5与DXT2/3的差异在于其Alpha信息是通过线性插值所得的,表示颜色信息的64位数据块依然不变,而Alpha信息则由2个8位Alpha极端值和16个3位索引值组成;我们可以看到在Unity内贴图类型选为法线后会采用DXTnm压缩格式,该格式会把法线贴图R通道存入A通道,然后RB通道清除为1,这样可以将法线XY信息分别存入到RGB/A中分别压缩,以获得更高的精度,然后再根据XY构建出Z通道数据;
-
ATI1/2
①ATI1:ATI公司开发的纹理压缩格式,也被称为BC4,其每个数据块存储单个颜色的数据通道,以与DXT5中的Alpha数据相同的方式进行编码,常用于存储高度图、光滑度贴图,效果与原始图像基本无差异;
②ATI2:也被称为BC5,每一个块中存储两个颜色通道的数据,同上以与DXT5中Alpha数据相同的方式进行编码,相当于存储了两个BC4块;
如果是在将法线存储在XY双通道中采用BC5格式压缩,由于每个通道都有自己的索引,因此法线贴图XY信息可以比在BC1中保留更多的保真度,缺点是需要使用两倍内存,也需要更多的带宽才能将纹理传递到着色器中;
-
BC6/7
①BC6和BC7仅在D3D11级图形硬件中受支持,他们每个块占用16字节,BC7针对8位RGB或RGBA数据,而BC6针对RGB半精度浮点数据,因此BC6是唯一一个可以原生存储HDR的BC格式;
②BC6是专门针对HDR(高动态范围)图像设计的压缩算法,压缩比为6:1;
③BC7是专门针对LDR(低动态范围)图像设计的压缩算法,压缩比为3:1,该格式用于高质量的RGBA压缩,可以显著减少由于压缩法线带来的错误效果;
④BC6和BC7的官方原理说明:
https://docs.microsoft.com/zh-cn/windows/uwp/graphics-concepts/bc6h-format
https://docs.microsoft.com/zh-cn/windows/uwp/graphics-concepts/bc7-format
-
ETC
上述我们说的DirectX选择了DXTC作为标准压缩格式,那对于OpenGL则选择了爱立信研发的ETC格式,几乎所有的安卓设备都可以支持ETC压缩,所以其在移动平台上被广泛应用;
ETC方案与DXTC具有相同特点,将4×4的像素单元压缩成64位数据块,并将像素单元水平或竖直朝向分为两个区块,每个像素颜色等于基础颜色加上索引指向的亮度范围;
①ETC1:每一个数据块分区中的4位亮度索引信息会从16个内置亮度表中获取当前像素单元对应的亮度表,每个像素的2位像素索引值可以从亮度表的四个值中选取对应的亮度补充值;
②ETC2:ETC2是ETC1的扩展,支持了Alpha通道的压缩,硬件要求OpenGL ES 3.0和OpenGL 4.3以上;
-
ASTC
ASTC是由ARM和AMD联合开发的纹理压缩格式,ASTC在各项指标上都挺不错,优点是可根据不同图片选择不同压缩率的算法,图片不需要为2的幂次,同时支持LDR和HDR,缺点是兼容性不够完善且解码时间较长;
ASTC也是基于块的压缩算法,与BC7类似,其数据块大小固定为128位,不同的是块中的像素数量可变,从4×4到12×12像素都有;
每一个数据块中存储了两个插值端点,但不一定存储的是颜色信息,也可能是Layer信息,这样可以用来对Normal或Alpha进行更好的压缩;
对于块中每一个纹素,存储其对应插值端点的权重,存储的权重数量可以少于纹素数量,可通过插值得到每一个纹素的权重值,然后再进行颜色的计算;

-
PVRTC
①PVRTC由Imagination公司专为PowerVR显卡设计,仅支持Iphone、Ipad和部分安卓机;不同于DXTC和ETC这类基于块的算法,PVRTC将图像分为了低频信号和高频信号,低频信号由两张低分辨率图像AB组成,高频信号则是低精度的调制图像,记录了每个像素混合的权重,解码时AB图像经过双线性插值放大,然后根据调制图像的权重进行混合;
②PVRTC 4-bpp把一个4×4的像素单元压成一个64位数据块,每一个块中存储一个32位的调制数据,一个1位的调制标志,15位的颜色A,1位颜色A不透明标志,14位颜色B,1位颜色B不透明标志;而PVRTC 2-bpp则是把一个8×4的像素单元压成了64位数据块;
-
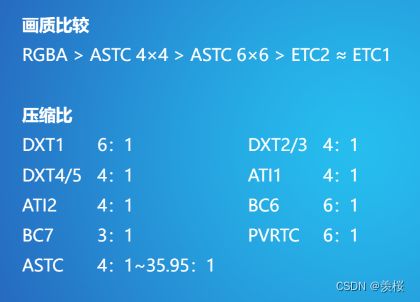
总结:

七、现代移动端的TBR和TBDR渲染管线
-
当前移动端GPU概况
1.移动端和桌面端功耗对比
①桌面级主流性能平台,功耗一般为300W(R7/I7+X60级别显卡),游戏主机150-200W
②入门和旗舰游戏本平台功耗为100W
③主流笔记本为50-60W,超极本为15-25W
④旗舰平板为8-15W
⑤旗舰手机为5-8W,主流手机为3-5W
2.移动端和桌面端带宽对比

-
名词解释
1.SOC(System on Chip):Soc是把CPU、GPU、内存、通信基带、GPS模块等等整合在一起的芯片的称呼。常见有A系Soc(苹果),骁龙Soc(高通),麒麟Soc(华为),联发科Soc,猎户座Soc(三星),苹果推出的M系Soc,暂用于Mac,但这说明手机、笔记本和PC的通用芯片已经出现了。
2.物理内存:Soc中GPU和CPU共用一块片内LPDDR物理内存,就是我们常说的手机内存,也叫System Memory,大概几个G。此外CPU和GPU还分别有自己的高速SRAM的Cache缓存,也叫On-chip Memory,一般几百K~几M。不同距离的内存访问存在不同的时间消耗,距离越近消耗越低,读取System Memory的时间消耗大概是On-chip Memory的几倍到几十倍。
3.On-Chip Buffer:在TB(D)R架构下会存储Tile的颜色、深度和模板缓冲,读写修改都非常快。如果Load/Store指令中缓冲需要被Preserve,将会被写入一份到System Memory中。
4.Stall:当一个GPU核心的两次计算结果之间有依赖关系而必须串行时,等待的过程便是Stall。
5.FillRate:像素填充率 = ROP运行的时钟频率 x ROP的个数 x 每个时钟ROP可以处理的像素个数。
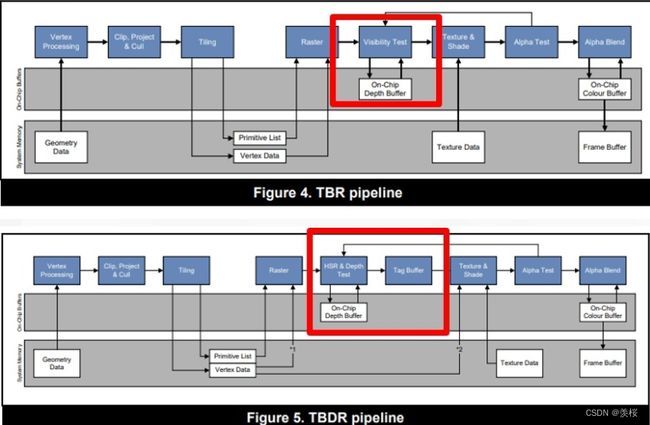
6.TBR(Tile-Based (Deferred) Rendering):目前主流的移动GPU渲染架构,对应一般PC上的GPU渲染架构则是IMR(Immediate Mode Rendering )。
TB(D)R简单的意思:屏幕被分块(16*16像素或者32*32像素)渲染
TBR:VS - Defer - RS - PS
TBDR:VS - Defer - RS - Defer - PS
Defer:字面是延迟,但从渲染数据的角度来看,Defer就是“阻塞+批处理”GPU的“一帧”的多个数据,然后一起处理。
-
一般PC上的GPU渲染架构:立即渲染(IMR)
1.架构流程:
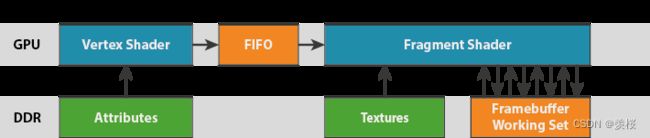
①用户应用程序提交的几个数据经过顶点Shader的处理
②经过一个类似于先进先出的管道顺序提交给片段shader
③把最终结果刷到FrameBuffer里
2.伪代码理解:

①每个renderPass里面有各种各样的DrawCall,每个DrawCall里面有很多图元。
②对每个图元里面的顶点做一个顶点Shader的处理,如果这个图元没有被剔除,则对每个图元里面的片段做一个片段Shader的处理。
3.Powervr公司官网详细示意图:
https://www.imgtec.com/blog/a-look-at-the-powervr-graphics-architecture-tile-based-rendering/
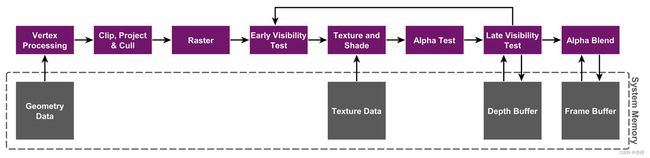
①虚框:代表系统内存区域
②整个过程直接和系统内存进行交互
-
移动端GPU架构:基于块元的渲染 TB(D)R
1.简述(见上名词解释):屏幕被分块(16*16像素或者32*32像素)渲染。
2.宏观上分为两个阶段:
①执行所有与几何相关的处理,并生成Primitive List(图元列表),并且确定每个tile上面有哪些primitive。(分图元)
②逐块执行光栅化及其后续处理,并在完成后将FrameBuffer从Tile Buffer写回到System Memory中。(不是直接写回到系统内存,而是写到片上内存里,即On-chip Memory)
3.架构流程:

①用户数据经过顶点shader的处理
②分图元处理(Tile)
③经过片元Shader处理
④数据存入On-chip Memory
4.伪代码:

①第一阶段:对每个renderPass的DrawCall里的图元进行顶点Shader处理(第一阶段关键是要分每个Tile上的Primitive)。
②第二阶段:对每个tile的primitive执行片元shader处理。
5.TB(D)R的硬件渲染顺序
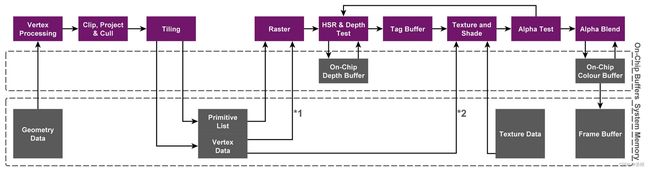
①第一个虚线框:On-chip Memory,片上的内存。
②第二个虚线框:System Memory,系统内存。
6.举例动图:
 TBR渲染顺序
TBR渲染顺序

在实际的GPU的渲染,并不是非常严格的按照从左到右,或者从右到左的顺序。
-
TB(D)R和IMR对比
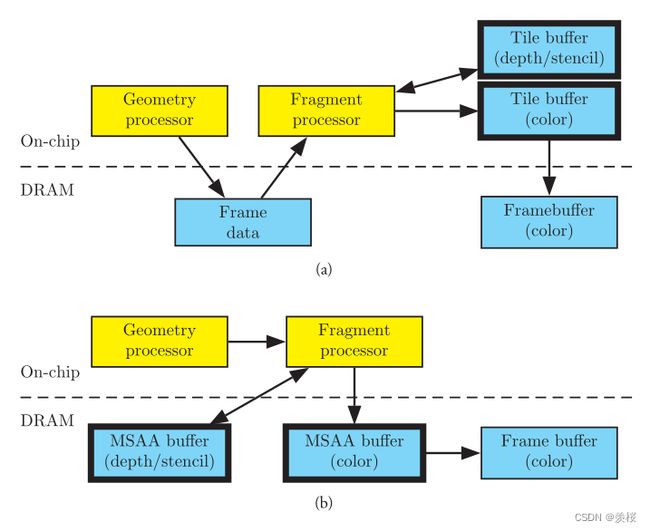
IMR少了两个环节:①几何处理和片段处理单元中间没有中间数据 ②经过片段处理后的数据没有放到On-chip Memory中而是直接刷到系统内存上。
*总结:
1.核心目的:降低带宽,减少功耗,但渲染帧率上并不比IMR快。
2.优点:
①TBR给消除Overdraw提供了机会,PowerVR用了HSR技术,Mali用了Forward Pixel Killing技术,目标一样,就是要最大限度减少被遮挡pixel的texturing和shading。
②TBR主要是 cached friendly, 在cache里头的速度要比全局内存的速度快的多,以及有可能降低render rate的代价,降低带宽,省电。
3.缺点:
①这个操作需要在vertex阶段之后,将输出的几何数据写入到DDR,然后才被fragment shader读取。这之间也就是tile写入DDR的开销和fragment shader渲染读取DDR开销的平衡。另外还有一些操作(比如tessellation)也不适用于TBR;
②如果某些三角形叠加在数个图块(Overdraw),则需要绘制数次。这意味着总渲染时间将高于即时渲染模式。
-
Binning过程(类似四叉树)/第一个Defer

1.Binning过程:确定了由哪些块元渲染哪些图元。
2.用户数据 → 分配块元去渲染。
3.样例:

来源:https://www.youtube.com/embed/SeySx0TkluE?rel=0&width=560&height=315&wmode=transparent&iframe=true&autoplay=1
4.如果Binning阶段耗时过多:几何数据过多了。
-
不同GPU的Early-Depth-Test / 第二个Defer
1.Arm Mali的FPK:
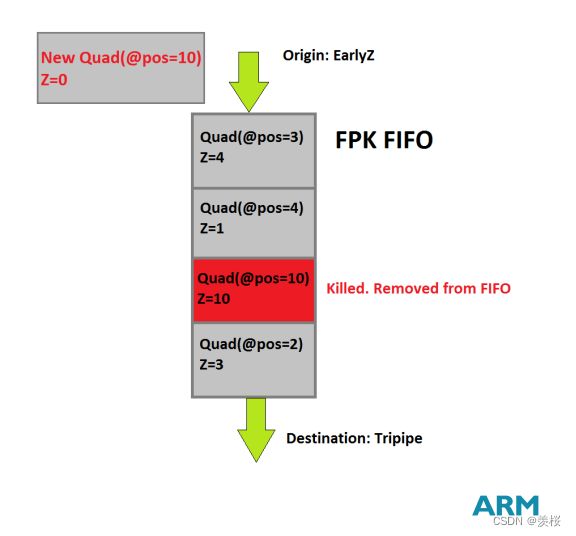
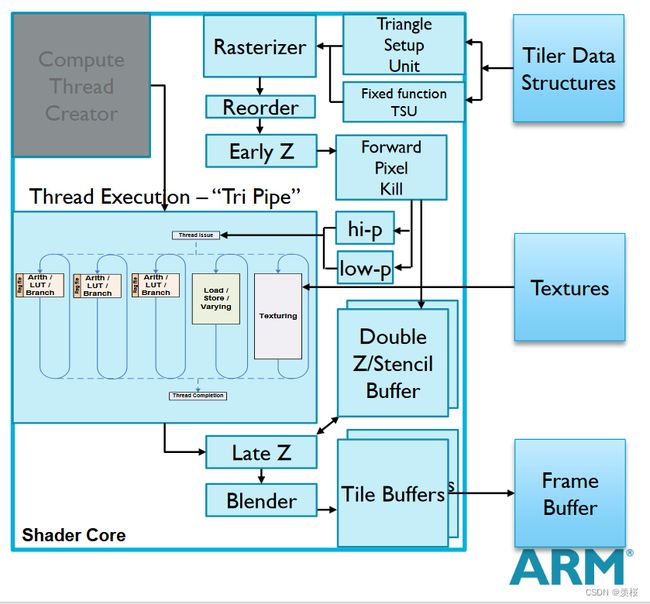
采用Forward Pixel Kill技术,在early-z之后,队列中有4个带有屏幕位置和图元深度信息的quad(平面)。
2.PVR的HSR(Hide Surface Removal,隐形面剔除):
PowerVR以及后续自研GPU,采用内置模块HSR。修改原渲染管线结构,增强rasterizer硬件模块为HSR。

实现原理:虚拟出一个射线,遇到第一个不透明的渲染模型时停止,打断后续三角形的ps处理。



3.Android的LRZ模块:
Qualcomm Adreno:采用外置模块LRZ,在正常渲染管线之前,先多执行一次vs生成低精度depth texture,来提前剔除不可见的三角形(实现细节不知),就是用硬件实现occlusion culling(遮挡剔除),功能类似软光栅中的遮挡剔除。
-
移动端Tile Based Render的优化建议
1.记得不使用Framebuffer的时候clear或者discard。
主要是清空积存在tile buffer上的 frame Data,所以在unity里面对render texture的使用也特别说明了一下,当不再使用这个rt之前,调用一次Discard。在OpenGL ES上善用glClear,gllnvalidateFrameBuffer避免不必要的Resolve(刷system memory)行为。
2.不要在一帧里面频繁的切换framebuffer的绑定。
本质上就是减少tile buffer 和system memory之间的 的stall 操作。
3.对于移动平台,建议你使用 Alpha 混合,而非 Alpha 测试。
在实际使用中,你应该分析并比较 Alpha 测试和 Alpha 混合的表现,因为这取决于具体内容,因此需要测量,通常在移动平台上应避免使用 Alpha 混合来实现透明。需要进行 Alpha 混合时,尝试缩小混合区域的覆盖范围。
4.手机上必须要做Alpha Test,先做一遍Depth prepass,参考参考目录的[Alpha Test的双pass 优化思路]
5.图片尽量压缩 例如:ASTC ETC2。
6.图片尽量走 mipmap。
7.尽量使用从Vertex Shader传来的Varying变量UV值采样贴图(连续的),不要在FragmentShader里动态计算贴图的UV值(非连续的),否则CacheMiss。
8.在延迟渲染尽量利用Tile Buffer 存储数据。
9.如果你在Unity 里面调整 ProjectSetting/Quality/Rendering/Texture Quality 不同的设置,或者不同的分辨率下,帧率有很多的变化,那么十有八九是带宽出问题啦。
10.MSAA(增加对framebuffer读取的次数)其实在TBDR上反而是非常快速的。
11.少在FS 中使用 discard 函数,调用gl_FragDepth从而打断Early-DT( HLSL中为Clip,GLSL中为discard )。
12.尽可能的在Shader里使用Half Float,如果Shader中仅有少量FP16的运算,且FP16需和FP32混合计算,则统一使用Float。
好处:(1)带宽用量减少(2)GPU中使用的周期数减少,因为着色器编译器可以优化你的代码以提高并行化程度。(3)要求的统一变量寄存器数量减少,这反过来又降低了寄存器数量溢出风险。具体有哪些数据类型适合用half或者float 或者fix,请查看参考目录的[熊大的优化建议]
13.在移动端的TB(D)R架构中,顶点处理部分,容易成为瓶颈,避免使用曲面细分shader,置换贴图等负操作,提倡使用模型LOD,本质上减少FrameData的压力。
八、command buffer及URP概述
-
URP概述
Unity URP/SRP 渲染管线浅入深出【匠】_FoxGameY的博客-CSDN博客_urp srp
-
Command Buffer概述
Command Buffer:用来存储渲染命令的缓冲区。保存着渲染命令列表,如(set render target, draw mesh等等),可以设置为在摄像机渲染期间的不同点执行。
-
为什么有Command Buffer?用来干什么?
1.例子:



https://github.com/Doppelkeks/Unity-CommandBufferRefraction
https://github.com/Arihide/unity-selective-outline
①扭曲效果:使用Command Buffer获取在渲染这图中的这三个物体之前的color buffer(背景),将其作为一张RenderTexture保存下来,当渲染图中这三个物体的时候,在片元着色器中使用切线空间的法线 X.Y对其屏幕空间的坐标做一个偏移,再用这个偏移的uv采样保存的RenderTexture。
②使用多Pass让物体在被选择的时候渲染外扩描边
*总结:command buffer实际上是用来帮助我们告诉管线下一步应该如何绘制,绘制什么。
2.从OpenGL指令分析Command Buffer原理(?)

在Opengl中,渲染过程中,出于渲染流程的需要,会频繁绑定VAO,VBO,FBO等。这样重复性的操作,很是让人感觉比较麻烦,也不利于程序的扩展。因此,在我自己写Opengl的时候,也会根据自己的需要,会将一些重复性的操作”提取”出来:使用Shader类负责编译,在Model类添加一些读取模型,绑定VAO,VBO操作函数等等。在渲染流程中常常也会需要用到上一个渲染阶段的结果作为输入,最常见的操作就是后处理阶段,需要把上一阶段的frame buffer 绑定到当前输入。
*例子:
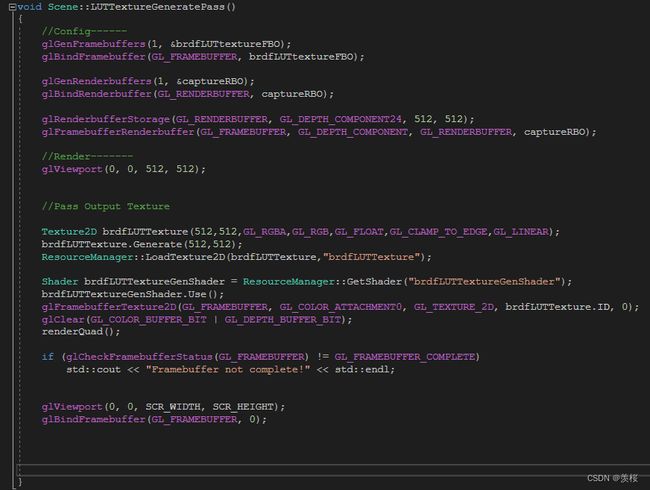

左边是我在对BRDF的镜面高光IBL项进行预积分渲染一张LUT,对每个粗糙度和入射角组合的响应结果存储在一张2D的LUT当中,计算出菲涅项的系数值(R通道)和偏移值(G通道)计算间接光的镜面高光项时:vec3 indirectSpecular = prefilteredColor * (F * envBRDF.x + envBRDF.y),然后再正式渲染的时候就是需要引用绑定刚刚预积分渲染的Texture。在整个渲染流程,如左图所示,给每一个小球设置好MVP矩阵,然后渲染skybox,如此循环。这里看不到整个LUTTextureGeneratePass是因为我把预积分项计算移动到Loop之外,这里的Debug是在Loop之内。所以整个渲染流程是分为一个一个Pass进行编写的话,更加容易辨识在每个渲染流程中应该做什么,计算出什么结果。(?)
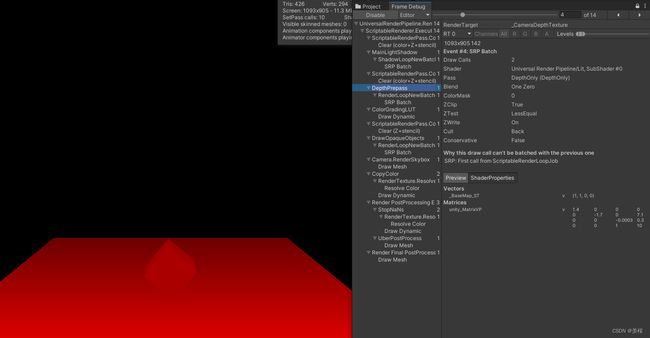


而为了更好扩展unity的渲染管线,unity提供了CommandBuffer,让你根据自己的需求,在不同的渲染阶段插入绘制指令,例如插入DrawRenderer,DrawMesh,DrawProcedure,绘制的时候也可以根据需要设置绘制时材质(Material)的MaterialPropertyBlock更改当前绘制的材质的属性。
这里我用了RenderFeature在BeforeRenderingOpaques的时候用DrawMesh指令渲染了一个Box。PS:MaterialPropertyBlock比直接修改Material的优势是:不会创建出新的材质实例。
3.从自定义RenderPipeLine分析:
-
Command Buffer常用函数
-
综合分析CommandBuffer的使用方法
1.URP
2.RenderFeature与CommandBuffer原理分析
3.Volume组件
-
Command Buffer注意事项
1.Scene窗口CameraColorTexture丢失(MSAA导致的bug resolveAA)
2.Depth Buffer和Stencil Buffer(16bit和24/32bit)
3.RT精度格式问题
4.加速优化
-
Unity官方文档
SRP概念相关: https://www.cnblogs.com/leixinyue/p/11038565.html
https://en.wikipedia.org/wiki/Render_Target
https://zhuanlan.zhihu.com/p/363793724
LoadAction/StoreAction RendertexuteMemeoryLess
https://answer.uwa4d.com/question/5e856425acb49302349a1119
https://zhuanlan.zhihu.com/p/262537295
https://developer.apple.com/library/archive/documentation/3DDrawing/Conceptual/MTLBestPracticesGuide/LoadandStoreActions.html
Instances:
https://www.xuanyusong.com/archives/4504
https://www.xuanyusong.com/archives/4640
https://www.xuanyusong.com/archives/4683
https://www.cnblogs.com/OneStargazer/p/15170931.html
Draw相关指令:
https://github.com/keijiro/Swarm
https://github.com/keijiro/GraphPlotter
Compute Shader:
https://cheneyshen.com/directcompute-tutorial-for-unity-kernels-and-thread-groups/
https://catlikecoding.com/unity/tutorials/basics/compute-shaders/
MSAA: https://www.zhihu.com/question/479915187
https://github.com/wlgys8/SRPLearn/wiki/MSAA_Implement
RT精度:
https://en.wikipedia.org/wiki/Colour_banding