Openstack J版本 NUMA特性相关分析(一)
声明:
本博客欢迎转载,但请保留原作者信息!
作者:黄堆荣
团队:华为杭州OpenStack团队
1、简介
Openstack在J版本中新增NUMA特性,用户可以通过将虚拟机只能的CPU和内存绑定到物理机的NUMA节点上来提升虚拟机的性能。
2、使用方式
NUMA分配方式有两种方式:
1、用户指定NUMA节点的个数,然后由Nova根据套餐中的规格平均将CPU和内存分布到不同的NUMA节点上(默认从node 0开始分配,依次递增)。
2、用户指定NUMA节点的个数,以及每个NUMA上分配的虚拟机CPU的编号以及内存大小
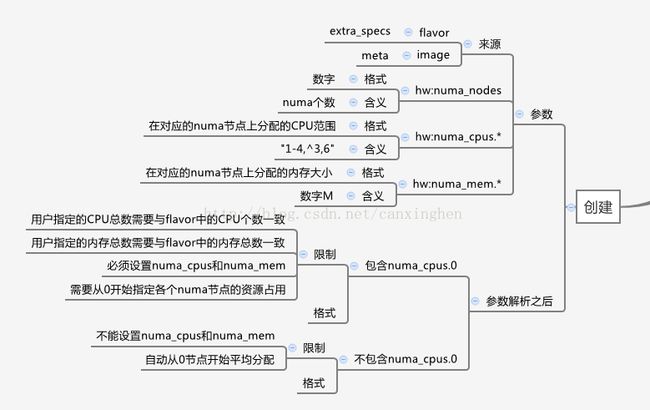
可以通过设置套餐和镜像的属性来指定虚拟机的NUMA的部署方式,创建虚拟机的时候选择特定套餐或则镜像来实现NUMA,具体方法如下:
1、设置套餐的extra_specs属性,设置方式如下
nova flavor-key flv_name set hw:numa_nodes=2 hw:numa_cpus.0=0 hw:numa_mem.0=512 hw:numa_cpus.1=0 hw:numa_mem.1=512
2、创建镜像的property属性,设置方式如下
glance image-update --property hw_numa_nodes=2 hw_numa_cpus.0=0 hw_numa_mem.0=512 hw_numa_cpus.1=0 hw_numa_mem.1=512 image_name
各个字段表示的含义如下:
numa_nodes:该虚拟机包含的NUMA节点个数
numa_cpus.0:虚拟机上NUMA节点0包含的虚拟机CPU的ID,格式"1-4,^3,6",如果用户自己指定部署方式,则需要指定虚拟机内每个NUMA节点的CPU部署信息,所有NUMA节点上的CPU总和需要与套餐中vcpus的总数一致。
numa_mem.0:虚拟机上NUMA节点0包含的内存大小,单位M,如果用户自己指定部署方式,则需要指定虚拟机内每个NUMA节点的内存信息,所有NUMA节点上的内存总和需要等于套餐中的memory_mb大小。
自动分配NUMA的约束和限制:
1、不能设置numa_cpus和numa_mem
2、自动从0节点开始平均分配
手动指定NUMA的约束和限制:
1、用户指定的CPU总数需要与套餐中的CPU个数一致
2、用户指定的内存总数需要与套餐中的内存总数一致
3、必须设置numa_cpus和numa_mem
4、需要从0开始指定各个numa节点的资源占用
3、总体流程分析
Nova各个组件实现NUMA特性的处理如下:
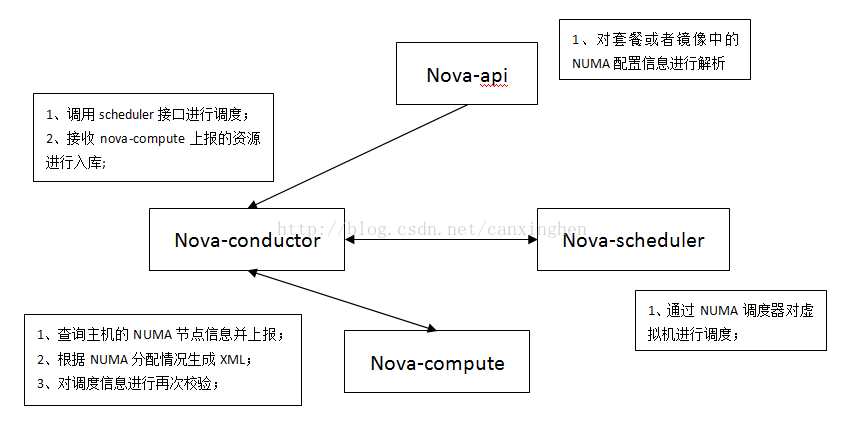
nova-api对于套餐或者镜像中的参数处理之后,保存在instance['numa_topology']中,信息格式如下:
{
"cells": [
{
"mem": {
"total": 1024
},
"cpus": "0,1",
"id": 0
},
{
"mem": {
"total": 1024
},
"cpus": "2,3",
"id": 0
}
]
} nova-api创建虚拟机的处理流程中对于NUMA参数的处理如下:
nova-compute获取主机侧总的资源信息逻辑如下:

nova-scheduler中NUMATopologyFilter调度器的处理流程如下:

nova-compute中的Claim流程会对资源再做一次校验,校验完成之后生成的XML信息:

虚拟机部署完成之后生成的XML对应信息如下:
/*虚拟机CPU与物理机的绑定关系,4-7,12-15在一个物理机的NODE节点上,0-3,8-11在另外一个NODE节点上*/
***
/*cpus表示该NODE节点内包含的虚拟机CPU的ID信息,memory表示该NODE节点包含的内存大小,默认单位KB*/
|
|
通过对流程分析,J版本中虚拟机的NUMA分配主要采用的是平均分配或者用户指定的方式,因此在nova-api中就已经确定好虚拟机对应的拓扑信息。但是在最终XML里面并没有numatune的信息,因此从现有的XML并无法看出虚拟机每个NUMA节点上的内存是从哪个物理机的NUMA节点上分配的,在Redhat的OS中,内存默认的分配方式与CPU的分配方式一致,但是在SUSE的平台上,需要指定numatune信息才能生效。
本篇主要是对J版本中NUMA特性的总体逻辑进行下简单的分析,下一篇博客会对代码中的详细流程进行分析。