pytorch MMseg训练自己数据集
摘要
mmdet,mmseg,mmocr是商汤开源的cv工具库,代码风格具有很强的相似性,简单来学习一下使用。方便快速入手各种比赛。mmseg主要用来处理语义分割等任务。
初始准备
下载mmsegmentation,由于我服务器之前安装成功了mmdet,已经包含的mmcv等换就需求包,所以直接pip install -v -e.编译
数据准备
这里我暂定使用voc2007的数据集,之后可以将任意数据集处理成voc的格式,数据集链接百度网盘如下:
链接: https://pan.baidu.com/s/1vkk3lMheUm6IjTXznlg7Ng 提取码: 44mk
数据摆放如下

训练
norm_cfg = dict(type='SyncBN', requires_grad=True)
custom_imports = dict(imports='mmcls.models', allow_failed_imports=False)
checkpoint_file = 'https://download.openmmlab.com/mmclassification/v0/convnext/downstream/convnext-tiny_3rdparty_32xb128-noema_in1k_20220301-795e9634.pth' # noqa
model = dict(
type='EncoderDecoder',
pretrained=None,
backbone=dict(
type='mmcls.ConvNeXt',
arch='tiny',
out_indices=[0, 1, 2, 3],
drop_path_rate=0.4,
layer_scale_init_value=1.0,
gap_before_final_norm=False,
init_cfg=dict(
type='Pretrained', checkpoint=checkpoint_file,
prefix='backbone.')),
decode_head=dict(
type='UPerHead',
in_channels=[96, 192, 384, 768],
in_index=[0, 1, 2, 3],
pool_scales=(1, 2, 3, 6),
channels=384,
dropout_ratio=0.1,
num_classes=21,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
auxiliary_head=dict(
type='FCNHead',
in_channels=384,
in_index=2,
channels=192,
num_convs=1,
concat_input=False,
dropout_ratio=0.1,
num_classes=21,
norm_cfg=norm_cfg,
align_corners=False,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
# model training and testing settings
train_cfg=dict(),
test_cfg=dict(mode='whole'))
dataset_type = 'PascalVOCDataset'
data_root = 'VOCdevkit/VOC2007'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
type='PascalVOCDataset',
data_root='VOCdevkit/VOC2007',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=(512, 512), cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size=(512, 512), pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg'])
]),
val=dict(
type='PascalVOCDataset',
data_root='VOCdevkit/VOC2007',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='PascalVOCDataset',
data_root='VOCdevkit/VOC2007',
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
log_config = dict(
interval=50, hooks=[dict(type='TextLoggerHook', by_epoch=False)])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
cudnn_benchmark = True
optimizer_config = dict()
optimizer = dict(
#constructor='LearningRateDecayOptimizerConstructor',
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg={
'decay_rate': 0.9,
'decay_type': 'stage_wise',
'num_layers': 12
})
lr_config = dict(
#_delete_=True,
policy='poly',
warmup='linear',
warmup_iters=1500,
warmup_ratio=1e-6,
power=1.0,
min_lr=0.0,
by_epoch=False)
runner = dict(type='IterBasedRunner', max_iters=20000)
checkpoint_config = dict(by_epoch=False, interval=2000)
evaluation = dict(interval=2000, metric='mIoU', pre_eval=True)
work_dir = './work_dirs/conv'
gpu_ids = [0]
auto_resume = False
可以直接运行的训练代码,如果是其他数据集我们只需要修改num_classes 数目就可以了
训练效果
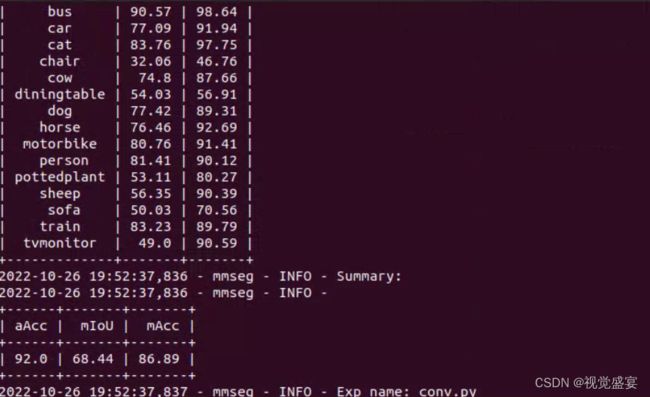
我跑了一部分迭代,如果代码出问题大概率是环境导致的。
处理任意数据集变成png标注格式
import base64
import json
import os
import os.path as osp
import cv2
import numpy as np
import matplotlib.pyplot as plt
import PIL.Image
from labelme import utils
classes = ["_background_","aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
path='../datasets/before/1.jpg'
path2='../datasets/before/1.json'
data = json.load(open(path2))
imageData = data['imageData']
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
print(data['shapes'])
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
new = np.zeros([np.shape(img)[0], np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all*(np.array(lbl) == index_json)
utils.lblsave('./1111.png', new)
voc数据特点,训练图像是三通道的jpg格式文件,标注数据集是单通道的png格式文件,如果比赛给出我们其他格式的标注类型我们应该如何处理,在seg中最重要的是points字段,里面是[x1,y1,x2,y2,x3,y3······]等等,在图像的一个一个点最终形成的闭环,在coco数据格式中segmentation字段中就是给出的这种格式。只要有这个标注信息我们就可以将其生成为png格式图像,具体代码参考上面案例。0.json是labelme标注图像产生的文件,labelme==3.16.7,不同版本运行可以会报错。

通过json多个点提取图像
from PIL import Image
from PIL import ImageDraw
import numpy as np
import cv2
import numpy.ma as npm
img=Image.open("D:/racedata/2022boat/boxGimg/0.jpg")
w,h=img.size
mask = np.zeros((h, w), dtype=np.uint8)
mask = Image.fromarray(mask)
draw = ImageDraw.Draw(mask)
points=[[20,20],[200,20],[200,200],[100,250],[20,200]]
xy = [tuple(point) for point in points]
draw.polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=np.uint8)
img=np.array(img)
masked_img = cv2.bitwise_and(img,img,mask = mask)
print(masked_img.shape)
for i,x,y in enumerate(points):
print(x,y)
cv2.imwrite("./1.jpg",masked_img)
利用draw库进行截取图像,在语义分割大图像切分
数据也经常用到