【序列模型】第一课--循环序列模型
课程来源:吴恩达 深度学习课程 《序列模型》
笔记整理:王小草
时间:2018年4月28日
吴恩达的课程一直是我深爱喜绝的,深入浅出,10分钟可以讲完一个可能要一个小时或者半天理解的知识点,并且讲得老少都懂,男女皆晓。因此这次早起晚睡抽出时间来整理他课程的笔记,便于之后回顾与复习。
本文要介绍的是序列模型的第一课,将详细介绍序列模型RNN的结构,基础知识等。
1.什么要使用序列模型 Why sequence models
本教程要讲的是神经网络的序列模型RNN,全称Recurrent Neural Network Model,可翻译成循环神经网络,是神经网络的其中一种类型。那么它有什么用处呢?本节将简单介绍RNN在学术界与工业界的一些主要的应用。
1.1 RNN的用途:
简单地介绍下RNN目前最常用的应用场景:
(1)语音识别
(2)音乐生成
(3)情感分析
(4)DNA序列分析
(5)机器翻译
(6)视频行为识别
(7)命名实体识别
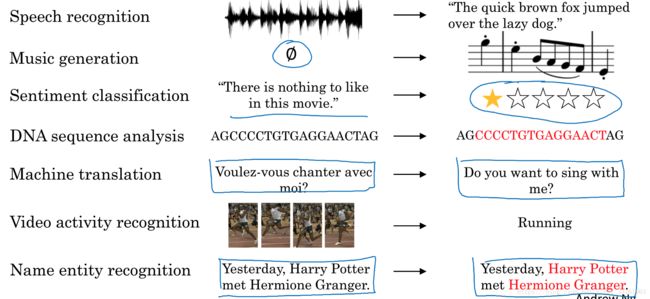
1.2 不同的应用场景,使用的模型也不同
比如有些场景下,输入与输出都是等长的序列;而有些场景下只是输入或输出为序列。等等许多应用需要具体问题具体问分析。
但无论如何,上面几个应用肯定有一些是你生活中已经享用到了,比如翻译,比如语音识别。也可以看出这些应用大多数是与语言有关。虽然业界对AI夸夸其谈者不胜枚举,但人工智能在自然语言上,尤其是中文自然语言上的成果,虽也可圈可点,但最多也只能给个中评都算勉强。而可以说RNN的确给垂死挣扎的自然语言患者带了一线生机,相信学术界与工业界共同的努力下,自然语言可以在深度学习中找到真命天子。
那么就从现在开始,学习RNN循环神经网络吧~
2.数学符号说明 Notation
上一节中,了解了序列模型广泛的应用,在进入深入学习之前,我们需要来定义一些数学符号,以方便接下去的课程中的表示与共识
1.开胃小栗子
假设有这样一句话:
X:Harry Potter and Hermoine Granger invented a new spell.
目的是想识别出句子中的实体词。所谓实体词包括人名, 地名,组织机构名称等等。
可见,输入的句子可以看成是单词的序列,那么我们期望的输出应是如下对应的输出:
Y:1 1 0 1 1 0 0 0 0
1代表的是“是实体”;0代表的是“非实体”
(当然,实际的命名实体识别比这输出要复杂得多,还需要表示实体词的结束位置与开始位置,在这个栗子中我们暂且选择以上这种简单的输出形式来讲解)
显而易见,输入的x与输出的y的序列个数一致,且索引位置相对应,我们用如下符号来表示输入与输出:

t表示第t时刻的输入;
Tx 表示样本x的序列长度;Ty 表示样本x输入模型后,输出序列的词长度,在本例中,输出与输出序列的长度相等,为9;
样本往往有很多个,用以下符号表示,第i个样本t时刻的输入与输出:

用以下符号表示第i个样本的输入序列的长度与输出序列的长度:

若换一个句子,句子有15个单词,则输入与输出的序列长度变为了5
2.2 representing words
上面讲了输入的序列是一句话中的单词,但是的但是,文字无法直接用于计算,预想将它表示称数字符号的形式。于是我们来讲一讲,如何来表示句子里的单词。
(1)首先,要建立一个词典,以List的形式存储,将语料中的所有单词去重后以一定的顺序放进list中。
如下是一个长度10000的词典(词典的长度是和你的语料有关的)

(2)然后,遍历你的样本,将每一个单词转换成词向量,比如,Harry在词典的索引为4075,则用一个长度为10000的词向量表示,这个词向量在4075的位置上为1,其他位置上都为0;同理其他每个词都一用这样一个向量来表示,如下图:
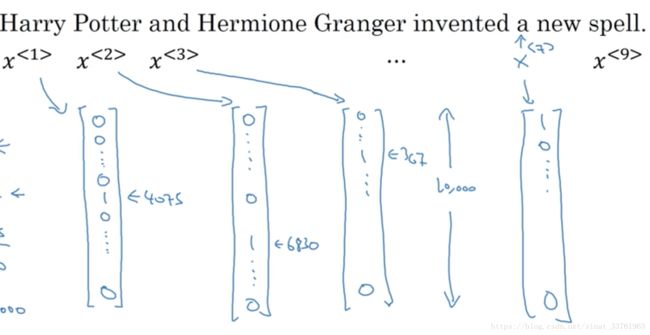
这样的词表示方法,我们叫独热编码one-hot
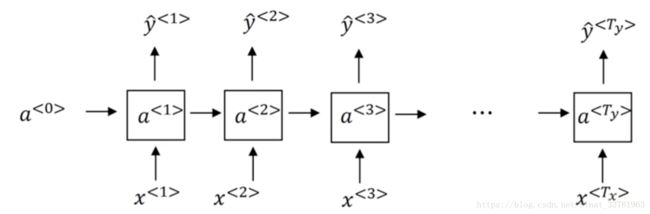
3.循环神经网络 Recurrent Neural Network Model
上一节了解了循环神经网络中的符号表示,这一节要正式揭开RNN神秘的面纱了:即学习构建模型,来实现输入x到输出y的映射。
3.1 Why not a standard network?
首先需要解释一个疑问,那就是为什么处理序列的问题,不能用标准的神经网络,或者卷积神经网络。有以下两个主要原因:
(1)不同的样本的输入与输出的序列长度是不同的。对于图片样本可以实现统一的像素大小作为输入,输出也是给定的,于是神经网络的输入层与输出层的神经元个数也是给定的;但对于文本,每次输入的句子长度都往往相异,因而输出的长度也相异。
(2)一般的神经网络不会对不同位置上的文本进行共享特征。意思是第一个单词Harry是人名,其特征影响第二个单词的预测,而若使用传统的神经网络,每个单词之间都不共享彼此的特征,丧失了序列上的特性。
3.2 What is the Recurrent Neural Networks
为什么叫循环神经网络呢?看了它的结构就明白了。
仍然使用这句话作为例子
X:Harry otter and Hermoine Granger invented a new spell.
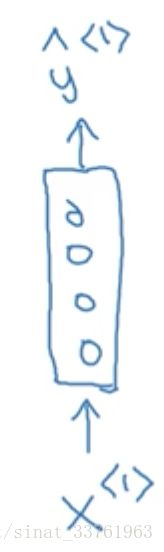
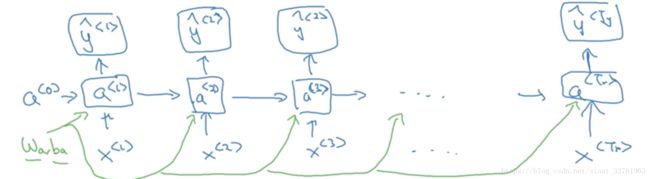
首先将第一个词Harry作为第一个输入x,中间经过一堆隐藏层,然后输出y:
接着将第二个词Potter作为第二个输入, 通用经过相同的隐藏层结构,获得输出。但这次,输入不但来自于第二个单词Potter, 还有一个来自上一个单词隐藏层中出来的信息(一般叫做激活值)a作为输入:
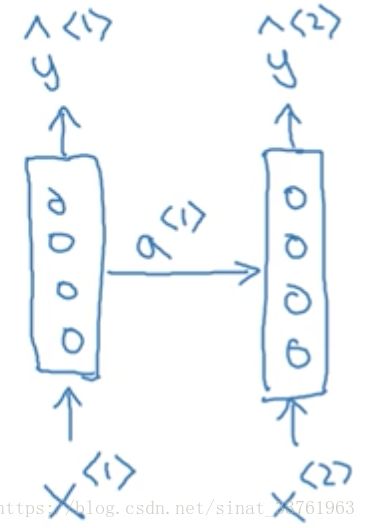
同理,接着是输入第3个词and, 同样也会输入来自第二个词的激活值;以此类推,直到最后一个词:
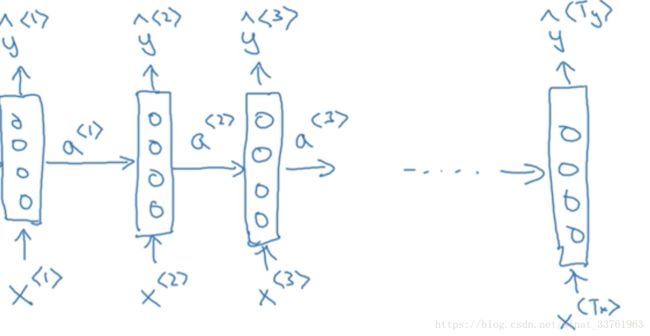
另外,第一个单词前面也需要一个激活值,这个可以人为编造,可以是0向量,也可以是用一些方法随机初始化的值。

再一些论文中会出现以下形式表示RNN,但有点不简明易懂,因此本课程中采用以上的画法:
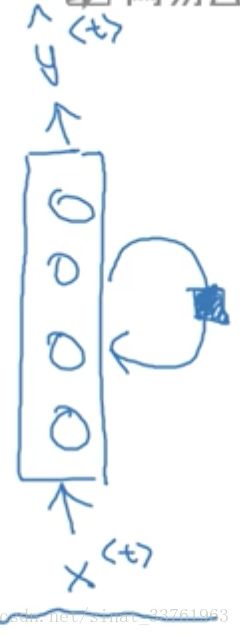
词一个一个输入的,可以看成每个时间输入一次,所有输入的隐藏层是共享参数的。设输入层到隐藏层到参数为wa_x,激活值到隐藏层到参数记为wa_a.
根据以上结构,显而易见,第一次输入的单词会通过激活值影响下一个单词的预测,甚至影响接下去的所有单词的预测,这就是循环神经网络。
但是有一个问题是,以上网络,只体现了前面的单词对后面的单词的影响,然而实际上序列的后面部分也会对前面部分有影响,比如以下例子:

第一句话中的Teddy是人名,第二句话中的Teddy是小熊,但两句话中的Teddy前面的信息都是一样的,我们需要读了后面的词之后才能分辨,因此后面的信息对前面的预测也是至关重要呢。
要解决这个问题很简单,在之后的课程中会介绍双向神经网络BRNN。
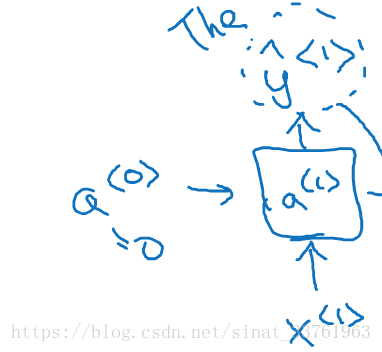
3.3 Forward Propagation
知道了RNN的结构,现在来详细学习其计算过程
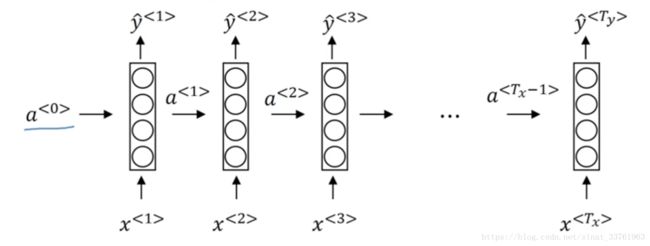
a<0>是人为初始化的到的;
x<1>是t=1时刻的输入;
输入层的权重是Wax;
激活层的权重是Waa;
输出层的权重是Wy1;
要计算的是每个时刻的激活值a与输出值y
a<1>的计算:

y<1>的计算:

g()是一个激活函数,通常选用tanh,有时也是用relu用于避免梯度弥散。若是输出是2分类,往往采用sigmoid作为激活函数,因为本例中是要判别是否为实体店而分类,因此采用sigmoid函数。
扩展的一般情况a与输出值y如下计算:


3.4 Simplified RNN notation
以上计算公式可以继续简化如下:
![]()
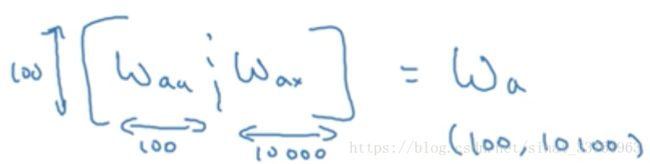
其中wa是Waa与Wax的左右拼接,若Waa纬度100*10000, Wax纬度100*10000,则组合后Wa纬度是100*10100
[a由如下关系得来
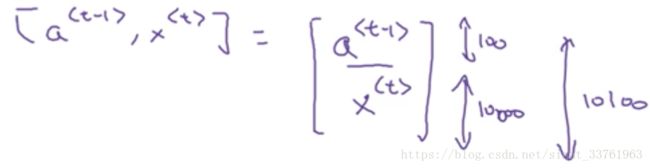
可证将以上两者相乘等到:

与原式相同。
同理第二个公式也简化成:

与原式相同。
4.RNN中的时间反向传播 Backpropagation through time
本节将讲述如何在RNN中实现反向传播算法。
4.1 前向传播 Forward propagation
先来回顾前向传播的过程,你有一个长度为Tx的序列:
](http://img.e-com-net.com/image/info8/4b4c99c9e63448ca9e9b085b5ddf5e45.jpg)
通过输入的x,可以求出每一个时间上的激活值a:
回顾上一节,时间t上的激活值a是由t-1时刻的a,与t时刻的输入x乘以参数而得:
![]()
每一个时间上的运算都是共享一组参数wa, wb的,如下:

接着,计算RNN的输出y:
同样,回顾y是通过当前时刻的激活值与参数相乘的到的:
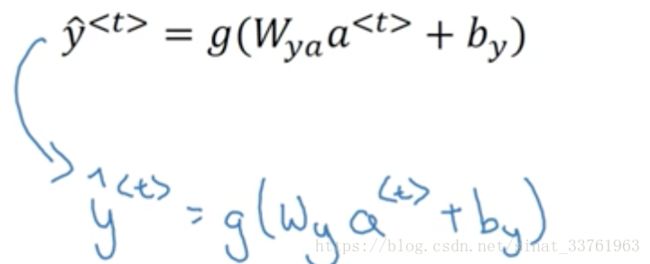
每一时刻的计算也是共享了一组参数Wy:

于是前向传播就完成了。
4.2 损失函数 loss function
前向传播的过程是反向传播的基础, 而为了计算反向传播,还需要定义一个损失函数。
此处使用交叉熵损失函数
(1)首先计算每个时间t上的损失,即计算序列中单次输入x,计算得到y的损失L( ):
(2)接着计算总的损失,即计算所有时间上的损失的总和:
4.3 反向传播 back propogation
将损失函数对各个参数求导,利用梯度下降法更新参数,红色箭头表示反向传播的过程:
在RNN中的反向传播亦叫时间反向传播back propogation through time
5.RNN的不同类型 Different types of RNNs
5.1 Examples of RNN architectures
在第一节中举过一些例子如下:

其中音乐生成,输入的可以是空值或者单一值,输出的是序列
情感分析,输入的是文本序列,输出的是二分类
机器翻译,输入与输出都是序列,但是长度却往往不同
因此不用场景下,我们需要去更改RNN的结构,以适应实际需求。
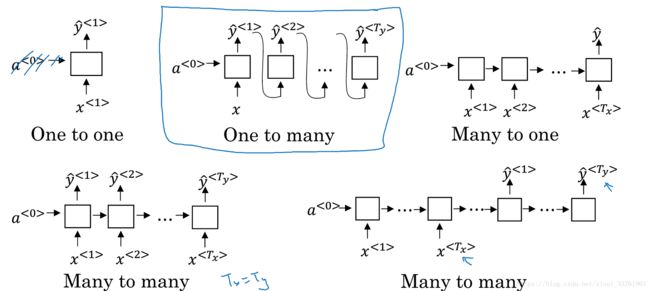
5.2 many-to-many architecture
前几节中讲到的命名实体识别中,输入的序列与输出的序列都有多个元素,且长度相同,称之为many-to-many结构,多对多结构。:
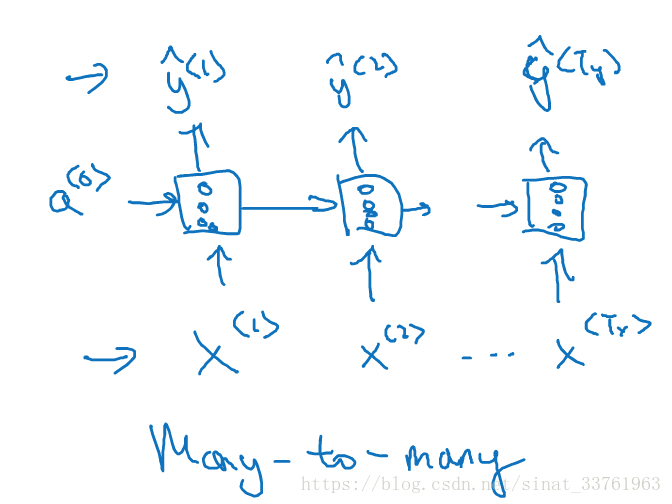
多对多也可以实现输入与输出序列长度不等的情况,最常见的是机器翻译,先来看看结构:
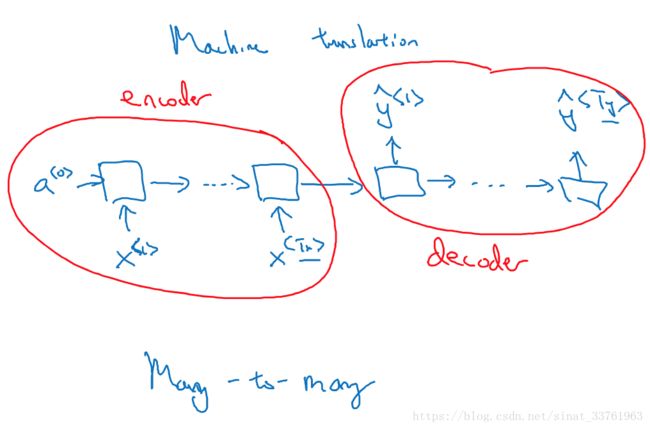
模型由2部分组成,前面一部分叫做encoder(编码), 将要翻译的文本序列逐次输入,但不产生输出;后一部分叫做decoder(解码),编码器的输出是解码器的输入,而接下去的每个时间上都不再有输入,但每次都会有一个输出。解码器输出的序列就是对编码器输出序列的翻译。
5.3 many-to-one architecture
在文本情感分析中,输入的是文本的序列,每个词都是一个输入,而输出的往往是类别标签,比如给电影的评价等级分为5档,或者判别文章正面情感与负面情感的2档。此时RNN的结构应是如下的:
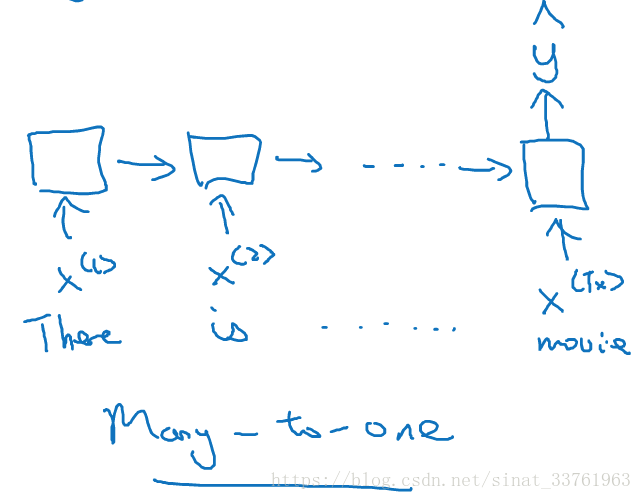
最后一个时间上会有y输出,而其他时间上都不再有y输出。这种结构叫做many-to-one结构,多对一结构。
5.4 one-to-many architectures
比如音乐生成的例子,输出的是一段音符的序列,而输入的可以是整数,表示你想要的音乐风格,或者是第一个音符,表示你想要用这个音符开头,或者什么都不输入,让模型自由发挥。显然这是需要一个一对多的RNN结构。那么one-to-many的模型结构是怎么样的呢:
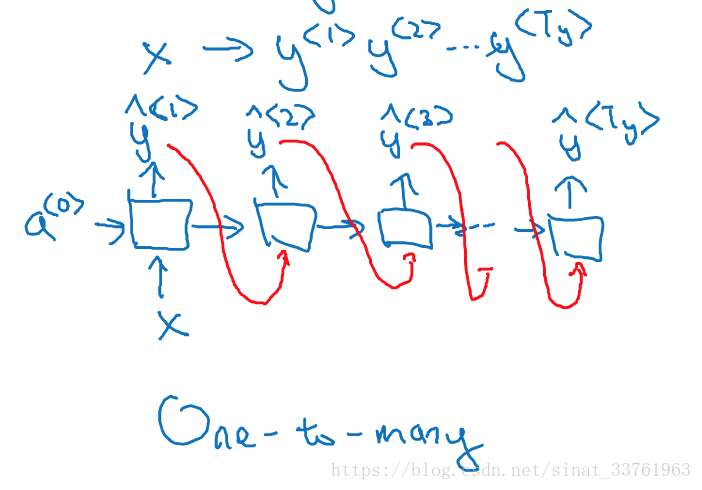
首先,只在第一个时间有输入x,其他时刻都没有;
其次,每一个时刻都会有输出,总的输出形成一个序列;
要注意的是,有一个技术细节,通常用RNN生成序列的时候,会把前一个时刻的输出y也作为t时刻的输入,以上红色箭头表示。
5.5 总结
来总结一下上文讲的几个结构:
6.语言模型与序列生成 Language model and sequence generation
本节将讲述如何使用RNN与构建一个语言模型
6.1 what is language modelling?
什么是语言模型呢?
比如speech recognition语音识别,即将声音识别成文字(国内语音识别做得不错的是科大讯飞)。
假如人说一句话“The apple and pear salad”,可以识别成以下两句话:

其中,pair与pear读音相同,显然第二句话才是正确识别说话人的意图。那要如何来选择最正确的句子呢?这就要用到语言模型了。
语言模型计算出两句话概率:

显然第二句的概率是第一句概率的近100倍,因此选择第二句话。也就是说语言模型会给你任何一句的概率,从而可以根据概率来选择最有可能正确的句子。
语言模型的应用目前有两大范畴,第一就是上面说的语音识别;第二就是机器翻译,同理,通过计算句子概率找到最正确的那句翻译。
6.2 How to build a language model–use RNN
(1)首先要拥有一个训练集:巨大的语料库,越大越好
(2)对语料库进行标记化,在前面几节中提高过,根据语料库整理出一个词典,并用one-hot的词向量表示每个词。有三个注意点:
A.一般会用
B.对于之后新的文本中出现了语料库中未出现过的词,则将其用
C.至于要不要将标点符号作为词典的一部分,这个看具体需求与问题来定夺。
(3)接着,建立RNN模型
假设有这样一句话:
![]()
在第一个时间t=1时,输出的x<1>为0向量,因为第一个词之前没有词;激活值a<0>也初始化为0向量;如此计算后,得到的y<1>是softmaxt里出来的一个向量,其长度为词典的长度,每一个位置上的值都是对应词典中的词的概率。注意字典也包括

在第二个时间t=2时,输入的x<2>实际上就是第一个单词y<1>:cat;通过softmax计算,同样会得到词典长度的概率分布向量,这个概率是P(Word / cat)即前面为单词cat时,词典中每个词出现的条件概率。
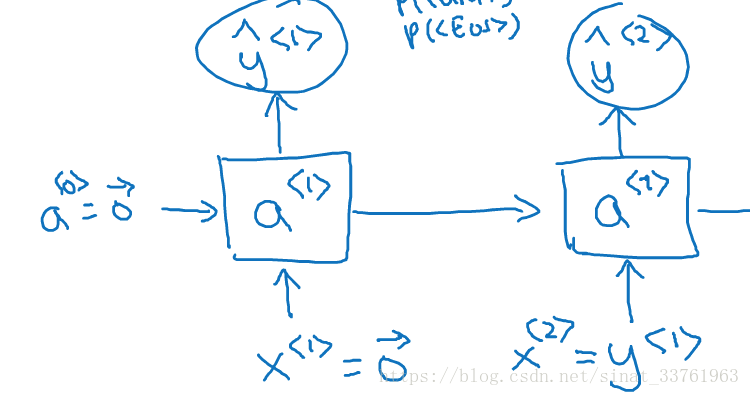
以此类推,一直到最后一个时刻,输入的x<9>=y<8>="day"。

(4)计算损失函数
每次计算输出的概率分布时预测值,与实际值比较从而计算损失,对于单词次时刻,损失的公式为:

i 遍历词典,对词典中每个词的值进行汇总
总的损失,是所有时间上的损失的和:

7.采样新序列 Sampling novel sequences
当你训练好一个RNN之后,想要知道这个模型到底学到了什么呢?最基本的应用就是进行一次新序列采样,换一种说法,就是让RNN去随机生成一个新的序列。
7.1 采样生成新序列过程
假设我们用大量的英文语料根据如下过程训练出了一个RNN模型:
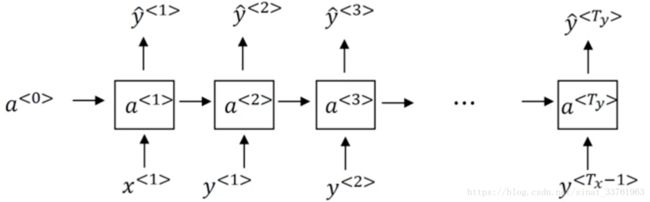
接着我们要用这个训练好的RNN来采样生成一个新的序列。
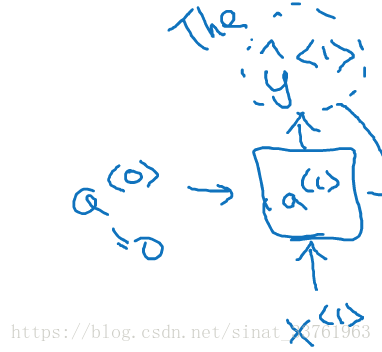
首先时刻t=1,仍然输入的是初始化的x<1>=0,a<0>=0,通过softmaxt的计算,会输出一个词典大小的概率分布向量,此时我们对这个向量进行采样,随机采出一个词作为输出(注意是随机,不是取最大概率)
接着来到了t=2时刻,此时的输入是上一个时间随机采样的词,同理对softmaxt概率分布随机采样,又采出了第二个词。
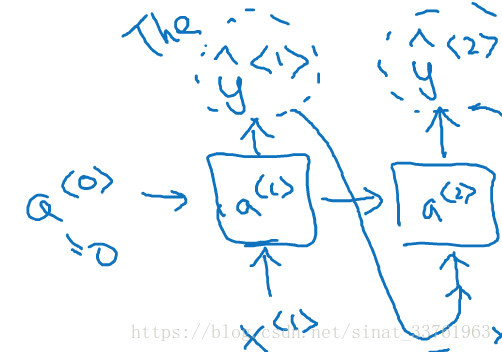
同理,每一个时间t,都取t-1点输出词作为输入,直到某个时刻的输出为

当然有的时候会采样出
7.2 character-level language model
也有许多人尝试基于字的RNN模型,即每次的输入不再是一个单词,而是一个字母,字典里还包括空格,符号等等。但这有两个问题:
第一:一句话有10-20个单词,但却有上百个字母,这使得序列的长度大大加大了,序列约长,则前面的词对后面的词传递的信息就会越来越弱,从而使词的依赖关系逐渐丧失。
第二:训练起来会比较复杂和耗资源
但是也有两个原因使得现在越累越多的应用中会尝试基于字的RNN模型:
第一:目前的计算能力越来越大
第二:在某些领域中,有专有名词,而专有名词往往很稀少得不被词典包含,从而产生许多
笔者:以上讲的是英文的应用,中文其实略有不同。
首先英文的单词是被空格天然地分割,因此不会产生把一个单词错误地一劈为二的情况,但中文是没有任何符号表示单词与单词之间的分割,中文分词的瓶颈仍然是一大阻碍。因此,有时候尝试基于字的建模可能反而效果会比基于词的要好。
8.RNN的梯度弥散 Vanishing gradients with RNNs
前面我们介绍了RNN的结构,前向传播与反向传播,RNN在命名实体、语言模型中的应用,这一节要讲述在构建RNN中会遇到的一个问题:梯度弥散问题。本节讲述什么是梯度弥散,后面几节会讲述如何解决这个问题。
8.1 什么是梯度弥散
首先来看传统的深层神经网络:
假设这个网络很深,有1000层甚至更多,那么经过前向传播得到输出层的y之后,很难再通过梯度下降法将y的梯度传播回去,即后面的梯度很难影响前面的权重。
对于RNN也是同样的道理,你已经很熟悉RNN的结构了:
假设有两个训练样本,句子的长度非常长:
The cat, with already ate…………, was full.
The cats, with already ate…………, where full.
第一个句子的was是依赖于cat, 第二个were是依赖于cats,但是这两个单词被隔得非常远,以至于后者的单词很难依赖于前者得到。
因为,与传统的深层神经网络类似,经过前向传播之后,反向传播中后面的y误差很难通过梯度影响到前面层的计算,因此当RNN在计算后面的单词was还是were的时候,对前面出现过的cat或cats已经忘得差不多了。
也因此,其实每次的输出y只能反向传播影响到前面附近的几层计算,也就是说,在训练时无论y的预测是正确的还是错误的,或者说损失是大是小,都无法通过反向传播告诉很前面的层,并且对前面的层有效调整权重。
是基本的RNN算法的一个缺点,但是表担心,接下去的几节会详细讲述解决这个问题的方法。
8.2 梯度爆炸exploding gradients
除了梯度弥散的问题,RNN也会遇到梯度爆炸的问题,但这个问题比较好解决,因此在这里顺带讲述。
如何发现梯度爆炸?
梯度爆炸很好发现,因为指数极大的梯度,会让你的参数变得极其大,以至于你的网络参数奔溃,你会看到很多NaN或者不是数字的情况,这说明你的网络出现了数值溢出。
如何解决梯度爆炸?
当发现梯度爆炸时,一个解决方式就是梯度修剪。
观察你的梯度向量,一旦发现超过某个阀值,就缩放梯度向量,保证他不会太大。比如通过一些最大值来修剪的方法
9.GRU单元Gated Recurrent Unit
上一节中讲了RNN有个梯度弥散的缺陷,难以捕捉深层依赖,于是,这一节要讲述一个解决该问题的方法,即在隐藏层加入GRU(Gated Recurrent Unit, 门控循环神经单元)。它可以捕捉深层链接,并大大改善梯度消散问题。
9.1 前戏
首先,回顾一下,我们之前讲的时间t上的神经元计算过程:

对于t时刻,有一个t-1时刻的激活值作为输入,有一个t时刻的x值作为输入,两个输入乘以各自的权重之后,作为激活函数tanh的输入,tanh的输出一边传给softmaxt层得到y, 一边直接传给下一个时间。a的公式如下:
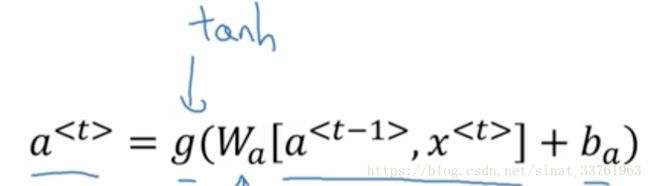
9.2 GRU的计算过程
现在我们来讲一讲GRU.
首先我们直观地来看一下GRU的计算过程图:
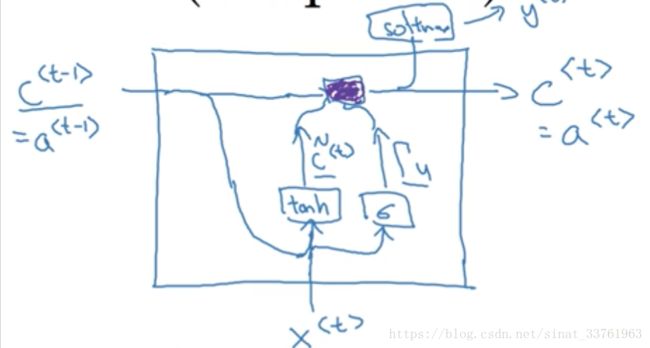
在问这是什么鬼之前,我们先一步一步讲解这其中的计算过程:
(1)首先我们用C表示记忆细胞,C表示t-1时刻的记忆信息,在GRU中,你暂且认为c,是层与层之间传递的激活值,只是计算过程略有不同。
(2)同样,有两个输入,一个是上一层的c, 一个是本时刻的输入x
(3)第一步计算:c与x分别乘以各自的权重之后经过tanh激活函数,输出c_mao。
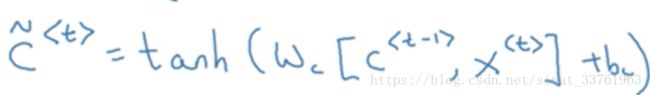
这个计算过程就相当于之前讲述的传统RNN计算过程,只是现在输出的c不是最终输出值,将它放在一边等待,我们来看另一步计算。
(4)第二步计算:可以看成是与第一步计算平行进行,将输入的c与x分别乘以另一组权重,经过一个sigmoid函数,输出Γu:
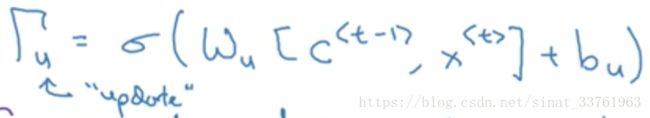
sigmoid函数是分布在0与1之间,大部分值会非常接近0或着1.
(5)第三步计算:第一步与第二步计算中我们得到了两个值,一个来自于tanh函数,一个来自于sigmoid函数。这一步我们将这两个值整合如下,计算出最终的c值
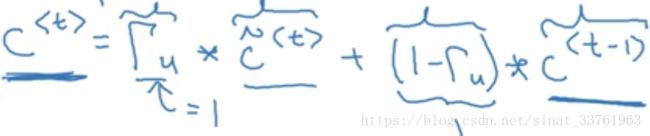
上一步可知,Γu是sigmoid函数的输出,因此大部分值会分布在0或者1的附近,假设Γu=1,它与c_mao相乘之后,c_mao的信息被原封不动地保留下来了,而c的信息被去除了;反之,若Γu=0, 则该层原来的激活值c_mao被去除,而上一层的信息c被全部保留。因此可以发现Γu其实就像是一个记忆门,由它决定是否需要记忆上一层的信息或着这一层的信息。
(6)上面计算所得的c为最终的激活值,继续按照老套路,一边传给softmaxt函数输出y, 一边传给下一层神经元
以上就是GRU的整个过程,或者说是一个简化版的GRU。
9.3 GRU的优点
(1)大部分时候,其实Γu是为0的,那么其实大部分时候c这非常有利于维持细胞的值
(2)由于大部分时候c,因此就一定程度上解决了梯度弥散的问题,深处的神经元也可依赖到很前面的信息,可以使神经网络运行在很深的层次上
9.4 更复杂一点的GRU
上面讲的GRU是简单版本的,在实际应用中的GRU会更复杂,接下去详细讲述。
首先,上面的公式回顾一下:
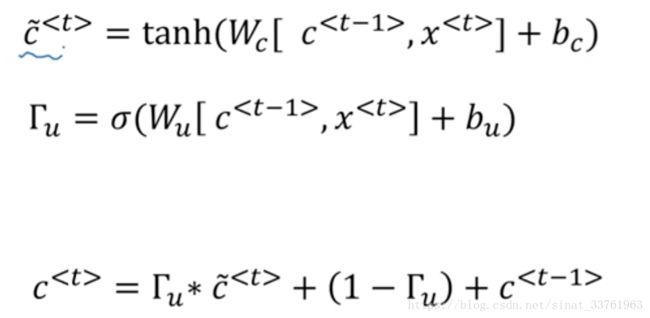
在上面的公式的基础之上做一些改变:
(1)c_mao的计算中加上一个另一个门Γr:
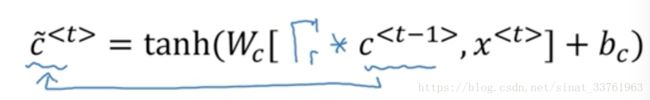
可以看成是一个表示相关性的门,将它乘以c表示c_mao与c有多大的相关性,即有c向量中有哪些位置上的信息相关性大则保留得更多。
(2)计算Γr的公式如下:

嗯嗯,就结束了。
9.5 总结
研究者们前赴后继地寻找着探索着更优的神经单元结构来使得RNN有更好的深层次依赖能力,来解决梯度弥散等问题,GRU算是一个非常标准或者基础,且被学术界和工业界广泛使用的结构,当然你也可以自己去探索出更优的结构。下一节将讲述另一个非常常用的RNN结构:LSTM。
10.长短时记忆单元LSTM unit
上一节中学习了GRU,能够有效避免梯度弥散,而这一节要学习的LSTM,可谓是比GRU有更大的能力,因此也备受业界喜爱。
LSTM全称:long short term memory
以下是提出LSTM的论文,略难,大神可仔细阅读,小白还是先绕道
![]()
首先我们从图形上直观地看一下LSTM unit的运行结构:
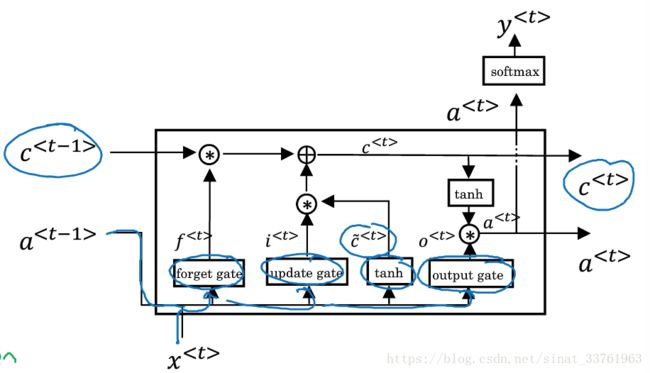
先别急着抱怨“这一点儿也不直观啊,到底是个什么鬼”。任何复杂的事物也不过是及其简单的事物组合而成,因此我们将其一步一步分解来看才能做到像学霸级的恍然大悟。
第一步:忘记门
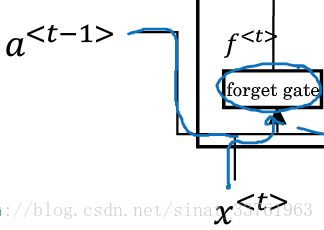
先来看上图中最左边的这块运算,
首先下方有一个叫做forget gate的小方块,它有两个输入,一个是上一个时刻的a,另一个输入是这一个时刻的x.
接着这两个输入会各自乘以一组权重,并且进入一个sigmoid函数得到Γf:

这个运算叫做忘记门,权重w里存储的是哪些信息对应的位置应该被忘记,这样不重要的信息,或者对之后的预测没有用的信息就可以被过滤掉。
第二步:记忆门
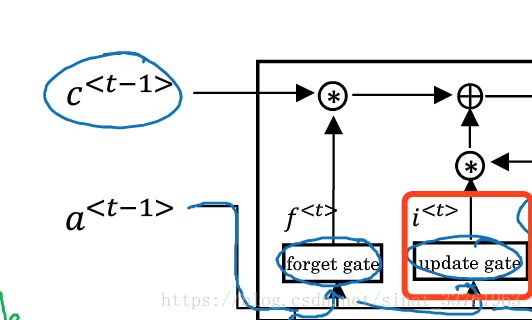
接着看到update gate的小方块,叫做记忆门,与上面的忘记门对比显然可猜测,这个门的运算应该是为了能够更新一些信息。输入也是a与x, 将它们乘以一组权重之后,也进入一个sigmoid函数,得到Γu,即被更新的信息

第三步:输出门

直接看输出门的计算:

和上面几个门是一样的,无非是换了一组参数
第四步:
a与x这两个输入还会乘以第四组权重,并且过一个tanh激活函数,得到c_mao:
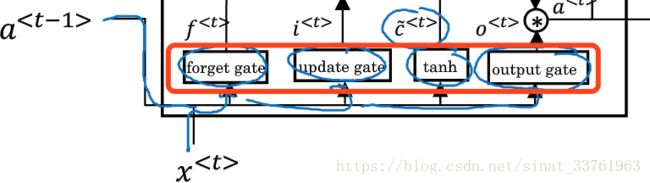
可以看到,以上讲的四部运算,刚好是第一张全图的下面4个小框:
第五步:计算c
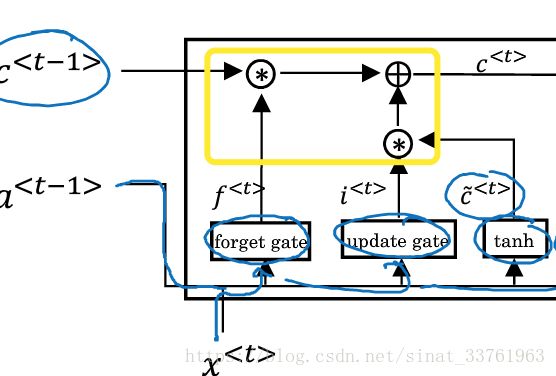
来看黄色圈出来的这块区域,圆圈里的星号表示乘法运算,加号表示求和运算。第一个乘号分别由两个箭头指向,分别是上一个时刻的c,以及第一步中计算得到的忘记门Γf;第二个乘号也分别由两个箭头指向,分别是第二部计算中得到的更新门Γu,以及c_mao.中间的加号,将两边的乘积求和。
以上一大堆废话,不如来个公式简明易了:
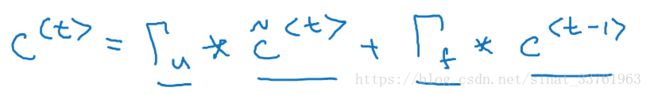
第六步:计算a
一言不合直接上公式:

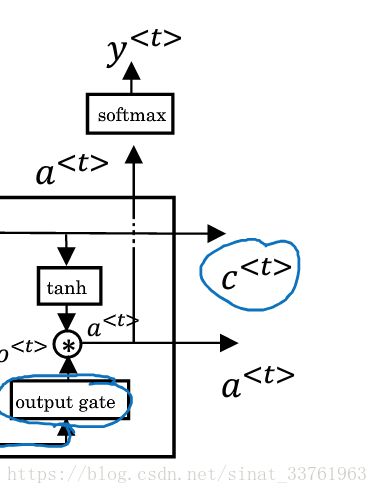
第七步:输出
千辛万苦终于等到你,一个LSTM unit的输出有两个,分别是第5步与第6步计算的c与a(注意与GRU的区别,GRU中a=c).
c会直接输给下一个时刻t+1, 它是由忘记门与更新门共同作用的,承载着滚滚黄河中前朝往事的记忆,让来世代代后人不忘初心。
a由两个方向的输出,一方面它会输给本时刻的softmax层去得到y, 另一方面,它也会作为下一个时刻的输入。
将一个LSTM unit链接起来就是酱紫的:
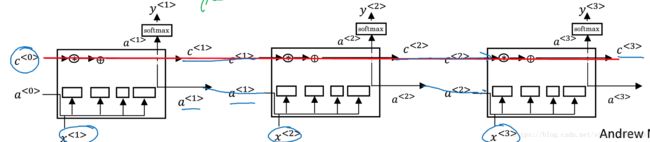
红线的路径就是c的流动路线,和GRU一样,它能够掌握时间维度上的深层依赖,使得后面的计算仍然能参考到前面的信息。
上面讲述的是基础的LSTM的结构,在其他文献或者博客中你可能还会看到一个不同点,即会多一个门,叫做偷窥门。即在忘记门,更新门,输出门计算的时候,会增加一个c作为输入,以偷窥前面的记忆。:

公式的变动上,只是在三个门中多输入一个c即可,其他并无差别。
结束语:
无论是上一节讲述的GRU,还是这一节讲述的LSTM并不是由于它们是什么高深的算法,所以要特地拿出来讲,而是因为它们确确实实地被广泛地应用在了业界,是算法工程师们的头号青睐对象。
LSTM比GRU提出地更早,GRU的效果没有LSTM好,但是其结构简单,计算复杂度低,适合于很复杂的深层网络;LSTM效果更好,但是结构略复杂。
不过如果你硬要在建模的时候推荐一个,那么还是建议先使用LSTM哈哈。
11.双向神经网络Bidirectional RNN
到目前为止,已经掌握了RNN的主要构件,但还有两个很重要的知识,能够帮助你的RNN产生更好的效果,一个就是双向RNN,另一个是深层RNN。本节将讲述双向RNN的内容。
11.1Why BRNN?
顾名思义,双向RNN,即可以从过去的时间点获取记忆,又可以从未来的时间点获取信息。那么我们为什么要获取未来的信息呢?还是以一开始的例子实体识别来看,假设以下两个句子,第一句话中的teddy是一只熊,非实体,第二句话中的Tedddy是一个人,是人名实体,但是仅仅是依靠这个单词前面的内容,完全无法判别它们的差异,而要继续看了后面的内容,才知道,原来第一句话讲的是bear, 第二句话将的是president.

因此,未来时间点的信息也对当前的预测起着至关重要的作用,双向RNN可以有效解决这个问题。
11.2 How BRNN?
那么双向RNN到底是如何运作的呢?
首先,回顾一下前向RNN的结构:
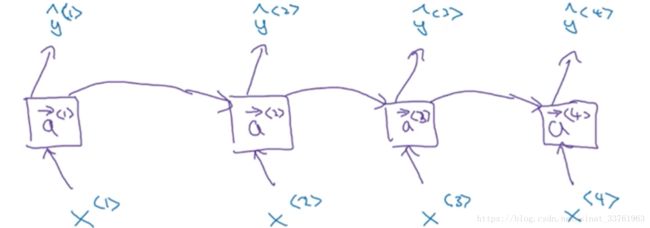
双向RNN在以上基础之上,在每一个时间上增加了一个新的激活单元:
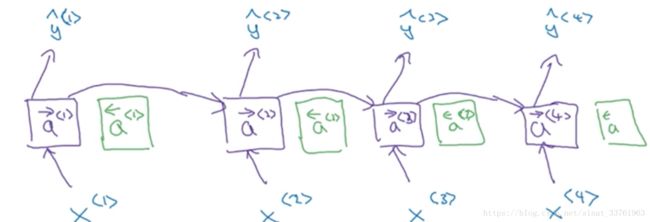
同样,新增的激活单元也会向上连接:

最重要的是,绿色的新增激活值会向左传递,由时间t传给时间t-1,就像这样:
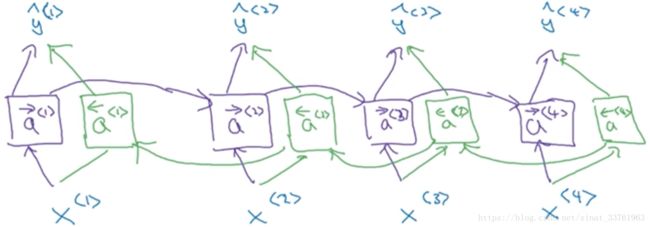
这样就构成了一个无环图,输入一个序列,计算的过程是这样的:
(1)前向和反向的计算会同时异向进行
前向从计算a<1>到a<2>..到a<4>,同时反向从a<4>到a<1>
(2)两个方向的激活值都计算完毕后,就可以计算输出值y了
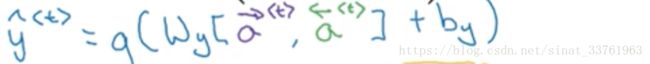
以y<3>输出为例,在双向RNN中,它说到前面时间1,2的影响,即x<1>,x<2>的影响,同时又受到了后面信息x<4>的影响。
注意,以上的神经元,不仅仅可以是标准的RNN单元,还可以是GRU,LSTM等。事实上,双向 LSTM RNN用得是最广泛的。
总之,双向RNN避免了只听半语就妄下定论的不良习性,对事物有全盘了解之后再做决断,偏听则暗,兼听则明。
12.深层循环神经网络Deep RNN
本节要讲的是深层循环神经网络。又可以顾名思义了,深层,那肯定是在原来的基础之上多加了几层而已。
12.1 Deep RNN 的结构
只有一层的循环神经网络如下:

那么深层,其实就是这样:
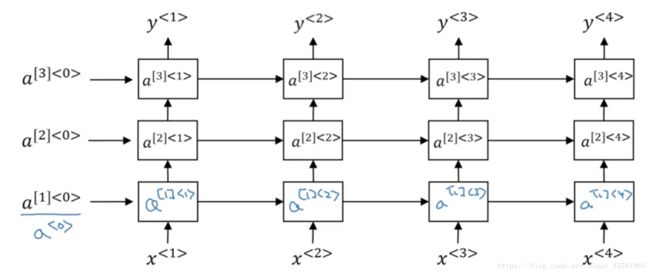
上面是一个3层的循环神经网络,其中a1<0>表示第1层的第0时刻的激活值。
12.2 Deep RNN 激活值的计算
那么这些激活值是怎么计算的呢?以a[2]<3>为例,它有两个输入:
一个来自是当前时刻的,前一层的输出;
一个是来自前一时刻,同层的输出。
公式如下:

其中Wa[2],ba[2]是指第二层的权重,整个第二层都共享这组权重
12.3 深层?
以上介绍了一个有3个隐藏层循环神经网络,但是只有3层,你确定可以叫“深层”吗?
额,是的,对于RNN来说,3层已经深得不容易了。由于时间的维度,就算只有恨少的层次,RNN的网络会变得异常大。你很少会见到向卷积神经网络那样堆叠到几十层甚至一百层的RNN。
但是如果你说,不行不行不行,人家就要放很深很深的层,那好,可以这样放:
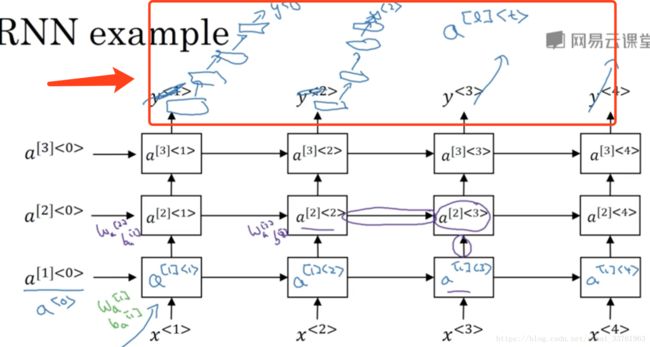
也就是说,在3层的RNN基础之上,将每个时刻输出的y再进入一个深层的普通神经网络,注意这些神经元之间没有横向的连接。
同样,深层RNN中的神经单元也可以用GRU,LSTM等。
嗯,至此为止,我们学完了循环序列模型的基础知识,下一个笔记将介绍如何用循环序列模型去进行自然语言处理,开心吗。
欢迎关注王小草的微信公众号,推送大数据,机器学习,深度学习,NLP等原创文章,欢迎交流与指正:
