最大似然和贝叶斯参数估计
- 统计生成模型的参数估计
– Maximum Likelihood(ML) 假设参数是某个确定的值,通过使似然度最大求出参数
– Bayesian estimation 假设参数是随机变量,估计参数分布的参数
– 最大似然求出具体的参数,贝叶斯求的是参数的分布
最大似然估计
- 假设概率密度函数 p ( x ∣ ω i , θ i ) , θ i p\left(x \mid \omega_i, \theta_i\right), \quad \theta_i p(x∣ωi,θi),θi to be estimated,估计每一类的概率密度函数, θ i \theta_i θi就是每一类概率密度函数的待估计参数
- 样本数据 D 1 , … , D c D_1, \ldots, D_c D1,…,Dc,假设每一类 D i D_i Di中的样本满足独立同分布i.i.d
- 总体流程就是从每一类中估计出一个概率密度函数,组成分类器
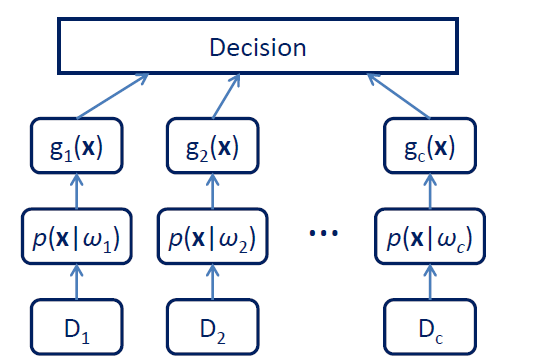
如何估计每一类的参数
- 似然函数(在某种参数下得到现有样本的概率,并应用独立同分布条件)
p ( D ∣ θ ) = ∏ k = 1 n p ( x k ∣ θ ) p(\mathcal{D} \mid \boldsymbol{\theta})=\prod_{k=1}^n p\left(\mathbf{x}_k \mid \boldsymbol{\theta}\right) p(D∣θ)=k=1∏np(xk∣θ) - 求使得似然函数最大化的参数(可能有解析解;如果没有可以考虑用梯度下降或其他优化方法)
max θ p ( D ∣ θ ) ↔ ∇ θ p ( D ∣ θ ) = 0 \max _{\boldsymbol{\theta}} p(D \mid \boldsymbol{\theta}) \leftrightarrow \nabla_{\boldsymbol{\theta}} p(D \mid \boldsymbol{\theta})=0 θmaxp(D∣θ)↔∇θp(D∣θ)=0
∇ θ ≡ [ ∂ ∂ θ 1 ⋮ ∂ ∂ θ p ] \nabla_{\boldsymbol{\theta}} \equiv\left[\begin{array}{c} \frac{\partial}{\partial \theta_1} \\ \vdots \\ \frac{\partial}{\partial \theta_p} \end{array}\right] ∇θ≡ ∂θ1∂⋮∂θp∂
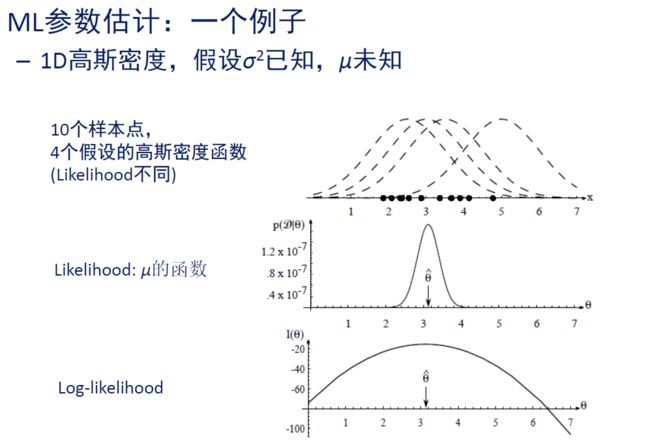
- 似然度通常取对数,这样比较好算(累乘变累加),也就是对数似然度
l ( θ ) ≡ ln p ( D ∣ θ ) l ( θ ) = ∑ k = 1 n ln p ( x k ∣ θ ) l(\boldsymbol{\theta}) \equiv \ln p(\mathcal{D} \mid \boldsymbol{\theta}) \quad l(\boldsymbol{\theta})=\sum_{k=1}^n \ln p\left(\mathrm{x}_k \mid \boldsymbol{\theta}\right) l(θ)≡lnp(D∣θ)l(θ)=k=1∑nlnp(xk∣θ) - ML估计
θ ^ = arg max θ l ( θ ) ∇ θ l = ∑ k = 1 n ∇ θ ln p ( x k ∣ θ ) = 0 ∂ l ∂ θ j = 0 , j = 1 , … , p \begin{aligned} & \hat{\boldsymbol{\theta}}=\arg \max _{\boldsymbol{\theta}} l(\boldsymbol{\theta}) \\ & \nabla_{\boldsymbol{\theta}} l=\sum_{k=1}^n \nabla_{\boldsymbol{\theta}} \ln p\left(\mathrm{x}_k \mid \boldsymbol{\theta}\right)=0 \\ & \frac{\partial l}{\partial \theta_j}=0, \quad j=1, \ldots, p \end{aligned} θ^=argθmaxl(θ)∇θl=k=1∑n∇θlnp(xk∣θ)=0∂θj∂l=0,j=1,…,p
【例子】假设样本服从高斯分布,但是均值 μ \mu μ未知
- 单个样本的对数似然度极其梯度
ln p ( x k ∣ μ ) = − 1 2 ln [ ( 2 π ) d ∣ Σ ∣ ] − 1 2 ( x k − μ ) t Σ − 1 ( x k − μ ) ∇ θ ln p ( x k ∣ μ ) = Σ − 1 ( x k − μ ) \begin{gathered} \ln p\left(\mathrm{x}_k \mid \boldsymbol{\mu}\right)=-\frac{1}{2} \ln \left[(2 \pi)^d|\boldsymbol{\Sigma}|\right]-\frac{1}{2}\left(\mathrm{x}_k-\boldsymbol{\mu}\right)^t \boldsymbol{\Sigma}^{-1}\left(\mathrm{x}_k-\boldsymbol{\mu}\right) \\ \nabla_{\boldsymbol{\theta}} \ln p\left(\mathrm{x}_k \mid \boldsymbol{\mu}\right)=\boldsymbol{\Sigma}^{-1}\left(\mathrm{x}_k-\boldsymbol{\mu}\right) \end{gathered} lnp(xk∣μ)=−21ln[(2π)d∣Σ∣]−21(xk−μ)tΣ−1(xk−μ)∇θlnp(xk∣μ)=Σ−1(xk−μ) - 令梯度为0,可以看到均值的最大似然估计就是样本均值
∇ θ l ( θ ) = 0 ⇒ ∑ k = 1 n Σ − 1 ( x k − μ ^ ) = 0 ⇒ μ ^ = 1 n ∑ k = 1 n x k \begin{aligned} \nabla_{\boldsymbol{\theta}} l(\boldsymbol{\theta})=0 & \Rightarrow \sum_{k=1}^n \boldsymbol{\Sigma}^{-1}\left(\mathrm{x}_k-\hat{\boldsymbol{\mu}}\right)=0 \\ & \Rightarrow \hat{\mu}=\frac{1}{n} \sum_{k=1}^n \mathrm{x}_k \end{aligned} ∇θl(θ)=0⇒k=1∑nΣ−1(xk−μ^)=0⇒μ^=n1k=1∑nxk
【例子】假设样本服从高斯分布,但是均值 μ \mu μ和协方差矩阵 Σ \Sigma Σ均未知
(1)假设一维情况: θ 1 = μ \theta_1=\mu θ1=μ and θ 2 = σ 2 \theta_2=\sigma^2 θ2=σ2
- 单样本对数似然度
ln p ( x k ∣ θ ) = − 1 2 ln 2 π θ 2 − 1 2 θ 2 ( x k − θ 1 ) 2 \ln p\left(x_k \mid \boldsymbol{\theta}\right)=-\frac{1}{2} \ln 2 \pi \theta_2-\frac{1}{2 \theta_2}\left(x_k-\theta_1\right)^2 lnp(xk∣θ)=−21ln2πθ2−2θ21(xk−θ1)2 - 对参数求梯度
∇ θ l = ∇ θ ln p ( x k ∣ θ ) = [ 1 θ 2 ( x k − θ 1 ) − 1 2 θ 2 + ( x k − θ 1 ) 2 2 θ 2 2 ] \nabla_{\boldsymbol{\theta}} l=\nabla_{\boldsymbol{\theta}} \ln p\left(x_k \mid \boldsymbol{\theta}\right)=\left[\begin{array}{c} \frac{1}{\theta_2}\left(x_k-\theta_1\right) \\ -\frac{1}{2 \theta_2}+\frac{\left(x_k-\theta_1\right)^2}{2 \theta_2^2} \end{array}\right] ∇θl=∇θlnp(xk∣θ)=[θ21(xk−θ1)−2θ21+2θ22(xk−θ1)2] - 令梯度为0,解方程得
∇ θ l ( θ ) = 0 ⇒ ∑ k = 1 n 1 θ ^ 2 ( x k − θ ^ 1 ) = 0 ⇒ μ ^ = 1 n ∑ k = 1 n x k − ∑ k = 1 n 1 θ ^ 2 + ∑ k = 1 n ( x k − θ 1 ^ ) 2 θ ^ 2 2 = 0 ⇒ σ ^ 2 = 1 n ∑ k = 1 n ( x k − μ ^ ) 2 \begin{aligned} \nabla_{\boldsymbol{\theta}} l(\boldsymbol{\theta})&=0 \Rightarrow \sum_{k=1}^n \frac{1}{\hat{\theta}_2}\left(x_k-\hat{\theta}_1\right)=0 \Rightarrow \hat{\mu}=\frac{1}{n} \sum_{k=1}^n x_k \\ -\sum_{k=1}^n \frac{1}{\hat{\theta}_2}&+\sum_{k=1}^n \frac{\left(x_k-\hat{\theta_1}\right)^2}{\hat{\theta}_2^2}=0 \Rightarrow \hat{\sigma}^2=\frac{1}{n} \sum_{k=1}^n\left(x_k-\hat{\mu}\right)^2 \end{aligned} ∇θl(θ)−k=1∑nθ^21=0⇒k=1∑nθ^21(xk−θ^1)=0⇒μ^=n1k=1∑nxk+k=1∑nθ^22(xk−θ1^)2=0⇒σ^2=n1k=1∑n(xk−μ^)2 - 这个估计是有偏估计,但是我忘记怎么证了(手动狗头),本科概率论有讲
E [ 1 n ∑ i = 1 n ( x i − x ˉ ) 2 ] = n − 1 n σ 2 ≠ σ 2 \mathcal{E}\left[\frac{1}{n} \sum_{i=1}^n\left(x_i-\bar{x}\right)^2\right]=\frac{n-1}{n} \sigma^2 \neq \sigma^2 E[n1i=1∑n(xi−xˉ)2]=nn−1σ2=σ2
(2)多变量情形
∇ θ l = ∑ k = 1 n ∇ θ ln p ( x k ∣ θ ) = 0 μ ^ = 1 n ∑ k = 1 n x k Σ ^ = 1 n ∑ k = 1 n ( x k − μ ^ ) ( x k − μ ^ ) t \begin{aligned} \nabla_{\boldsymbol{\theta}} l & =\sum_{k=1}^n \nabla_{\boldsymbol{\theta}} \ln p\left(\mathrm{x}_k \mid \boldsymbol{\theta}\right)=0 \\ \hat{\mu} & =\frac{1}{n} \sum_{k=1}^n \mathrm{x}_k \\ \widehat{\boldsymbol{\Sigma}} & =\frac{1}{n} \sum_{k=1}^n\left(\mathrm{x}_k-\hat{\boldsymbol{\mu}}\right)\left(\mathrm{x}_k-\hat{\boldsymbol{\mu}}\right)^t \end{aligned} ∇θlμ^Σ =k=1∑n∇θlnp(xk∣θ)=0=n1k=1∑nxk=n1k=1∑n(xk−μ^)(xk−μ^)t
- 无偏估计应该是这样的,但是实际差别不大
E [ 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 ] = σ 2 C = 1 n − 1 ∑ k = 1 n ( x k − μ ^ ) ( x k − μ ^ ) t \begin{aligned} & \mathcal{E}\left[\frac{1}{n-1} \sum_{i=1}^n\left(x_i-\bar{x}\right)^2\right]=\sigma^2 \\ & \mathbf{C}=\frac{1}{n-1} \sum_{k=1}^n\left(\mathbf{x}_k-\hat{\boldsymbol{\mu}}\right)\left(\mathrm{x}_k-\hat{\boldsymbol{\mu}}\right)^t \end{aligned} E[n−11i=1∑n(xi−xˉ)2]=σ2C=n−11k=1∑n(xk−μ^)(xk−μ^)t
贝叶斯参数估计
- 后验概率(全概率公式,后面都带一个 D \mathcal{D} D,代表样本集)
P ( ω i ∣ x , D ) = p ( x ∣ ω i , D ) P ( ω i ∣ D ) ∑ j = 1 c p ( x ∣ ω j , D ) P ( ω j ∣ D ) P\left(\omega_i \mid \mathbf{x}, \mathcal{D}\right)=\frac{p\left(\mathbf{x} \mid \omega_i, \mathcal{D}\right) P\left(\omega_i \mid \mathcal{D}\right)}{\sum_{j=1}^c p\left(\mathbf{x} \mid \omega_j, \mathcal{D}\right) P\left(\omega_j \mid \mathcal{D}\right)} P(ωi∣x,D)=∑j=1cp(x∣ωj,D)P(ωj∣D)p(x∣ωi,D)P(ωi∣D) - 假设先验概率和样本无关
P ( ω i ∣ x , D ) = p ( x ∣ ω i , D i ) P ( ω i ) ∑ j = 1 c p ( x ∣ ω j , D j ) P ( ω j ) P\left(\omega_i \mid \mathbf{x}, \mathcal{D}\right)=\frac{p\left(\mathbf{x} \mid \omega_i, \mathcal{D}_i\right) P\left(\omega_i\right)}{\sum_{j=1}^c p\left(\mathbf{x} \mid \omega_j, \mathcal{D}_j\right) P\left(\omega_j\right)} P(ωi∣x,D)=∑j=1cp(x∣ωj,Dj)P(ωj)p(x∣ωi,Di)P(ωi) - 我们已知样本集 D \mathcal{D} D,去估计 x \mathbf{x} x
p ( x ∣ D ) = ∫ p ( x , θ ∣ D ) d θ = ∫ p ( x ∣ θ ) p ( θ ∣ D ) ‾ d θ \begin{aligned} p(\mathbf{x} \mid \mathcal{D}) & =\int p(\mathbf{x}, \boldsymbol{\theta} \mid \mathcal{D}) d \theta \\ & =\int p(\mathbf{x} \mid \boldsymbol{\theta}) \underline{p(\boldsymbol{\theta} \mid \mathcal{D})} d \boldsymbol{\theta} \end{aligned} p(x∣D)=∫p(x,θ∣D)dθ=∫p(x∣θ)p(θ∣D)dθ - 我们知道 p ( x ∣ θ ) p(\mathbf{x} \mid \boldsymbol{\theta}) p(x∣θ),但不知道 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D),这就是贝叶斯估计要解的问题,咱们是在已知样本集的情况下,去估计未知参数的分布 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)
高斯密度贝叶斯估计
- 一维情况估计 p ( θ ∣ D ) p(\boldsymbol{\theta} \mid \mathcal{D}) p(θ∣D)
- 假设样本服从高斯分布 p ( x ∣ μ ) ∼ N ( μ , σ 2 ) p(x \mid \mu) \sim N\left(\mu, \sigma^2\right) p(x∣μ)∼N(μ,σ2),假设均值也服从高斯分布 p ( μ ) ∼ N ( μ 0 , σ 0 2 ) p(\mu) \sim N\left(\mu_0, \sigma_0^2\right) p(μ)∼N(μ0,σ02), p ( D ∣ μ ) = ∏ k = 1 n p ( x k ∣ μ ) p(D \mid \mu)=\prod_{k=1}^n p\left(x_k \mid \mu\right) p(D∣μ)=∏k=1np(xk∣μ)
p ( μ ∣ D ) = p ( D ∣ μ ) p ( μ ) ∫ p ( D ∣ μ ) p ( μ ) d μ = α ∏ k = 1 n p ( x k ∣ μ ) p ( μ ) \begin{aligned} p(\mu \mid \mathcal{D}) & =\frac{p(\mathcal{D} \mid \mu) p(\mu)}{\int p(\mathcal{D} \mid \mu) p(\mu) d \mu} & =\alpha \prod_{k=1}^n p\left(x_k \mid \mu\right) p(\mu) \end{aligned} p(μ∣D)=∫p(D∣μ)p(μ)dμp(D∣μ)p(μ)=αk=1∏np(xk∣μ)p(μ) - α \alpha α是个归一化常数
p ( μ ∣ D ) = α ∏ k = 1 n 1 2 π σ exp [ − 1 2 ( x k − μ σ ) 2 ] ⏞ p ( x k ∣ μ ) 1 2 π σ 0 exp [ − 1 2 ( μ − μ 0 σ 0 ) 2 ] ⏞ p ( μ ) = α ′ exp [ − 1 2 ( ∑ k = 1 n ( μ − x k σ ) 2 + ( μ − μ 0 σ 0 ) 2 ) ] = α ′ ′ exp [ − 1 2 [ ( n σ 2 + 1 σ 0 2 ) μ 2 − 2 ( 1 σ 2 ∑ k = 1 n x k + μ 0 σ 0 2 ) μ ] ] \begin{aligned} p(\mu \mid \mathcal{D})&=\alpha \prod_{k=1}^n \overbrace{\frac{1}{\sqrt{2 \pi} \sigma} \exp \left[-\frac{1}{2}\left(\frac{x_k-\mu}{\sigma}\right)^2\right]}^{p\left(x_k \mid \mu\right)} \overbrace{\frac{1}{\sqrt{2 \pi} \sigma_0} \exp \left[-\frac{1}{2}\left(\frac{\mu-\mu_0}{\sigma_0}\right)^2\right]}^{p(\mu)} \\ & =\alpha^{\prime} \exp \left[-\frac{1}{2}\left(\sum_{k=1}^n\left(\frac{\mu-x_k}{\sigma}\right)^2+\left(\frac{\mu-\mu_0}{\sigma_0}\right)^2\right)\right] \\ & =\alpha^{\prime \prime} \exp \left[-\frac{1}{2}\left[\left(\frac{n}{\sigma^2}+\frac{1}{\sigma_0^2}\right) \mu^2-2\left(\frac{1}{\sigma^2} \sum_{k=1}^n x_k+\frac{\mu_0}{\sigma_0^2}\right) \mu\right]\right] \\ & \end{aligned} p(μ∣D)=αk=1∏n2πσ1exp[−21(σxk−μ)2] p(xk∣μ)2πσ01exp[−21(σ0μ−μ0)2] p(μ)=α′exp[−21(k=1∑n(σμ−xk)2+(σ0μ−μ0)2)]=α′′exp[−21[(σ2n+σ021)μ2−2(σ21k=1∑nxk+σ02μ0)μ]]
p ( μ ∣ D ) = 1 2 π σ n exp [ − 1 2 ( μ − μ n σ n ) 2 ] p(\mu \mid \mathcal{D})=\frac{1}{\sqrt{2 \pi} \sigma_n} \exp \left[-\frac{1}{2}\left(\frac{\mu-\mu_n}{\sigma_n}\right)^2\right] p(μ∣D)=2πσn1exp[−21(σnμ−μn)2]
σ n 2 = σ 0 2 σ 2 n σ 0 2 + σ 2 ⟶ μ n = ( n σ 0 2 n σ 0 2 + σ 2 ) μ ^ n + σ 2 n σ 0 2 + σ 2 μ 0 \sigma_n^2=\frac{\sigma_0^2 \sigma^2}{n \sigma_0^2+\sigma^2} \longrightarrow \mu_n=\left(\frac{n \sigma_0^2}{n \sigma_0^2+\sigma^2}\right) \hat{\mu}_n+\frac{\sigma^2}{n \sigma_0^2+\sigma^2} \mu_0 σn2=nσ02+σ2σ02σ2⟶μn=(nσ02+σ2nσ02)μ^n+nσ02+σ2σ2μ0
贝叶斯估计一般情况
- 估计参数后验概率分布
p ( θ ∣ D ) = p ( D ∣ θ ) p ( θ ) ∫ p ( D ∣ θ ) p ( θ ) d θ p ( D ∣ θ ) = ∏ k = 1 n p ( x k ∣ θ ) p(\boldsymbol{\theta} \mid \mathcal{D})=\frac{p(\mathcal{D} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta})}{\int p(\mathcal{D} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta}) d \boldsymbol{\theta}} \quad p(\mathcal{D} \mid \boldsymbol{\theta})=\prod_{k=1}^n p\left(\mathbf{x}_k \mid \boldsymbol{\theta}\right) p(θ∣D)=∫p(D∣θ)p(θ)dθp(D∣θ)p(θ)p(D∣θ)=k=1∏np(xk∣θ) - 估计数据概率分布
p ( x ∣ D ) = ∫ p ( x ∣ θ ) p ( θ ∣ D ) d θ p(\mathbf{x} \mid \mathcal{D})=\int p(\mathbf{x} \mid \boldsymbol{\theta}) p(\boldsymbol{\theta} \mid \mathcal{D}) d \boldsymbol{\theta} p(x∣D)=∫p(x∣θ)p(θ∣D)dθ
If p ( θ ∣ D ) peaks at θ = θ ^ , p ( x ∣ D ) will be approximately p ( x ∣ θ ^ ) \text { If } p(\theta \mid D) \text { peaks at } \boldsymbol{\theta}=\hat{\boldsymbol{\theta}}, p(\mathbf{x} \mid \mathrm{D}) \text { will be approximately } p(\mathbf{x} \mid \hat{\boldsymbol{\theta}}) If p(θ∣D) peaks at θ=θ^,p(x∣D) will be approximately p(x∣θ^)