【python】(4)深度学习相关:概念理解:CPU | GPU | cuda | CUDNN | tensorflow | pytorch | keras安装及配置
目录
1 CPU | GPU
6.2 cuda、cuda驱动、显卡
6.3 CUDNN
6.4 py-torch和TensorFlow框架
6.5 miniconda
6.6 pytorch介绍
7 MATLAB 深度学习包
8 写在最后
1 CPU | GPU

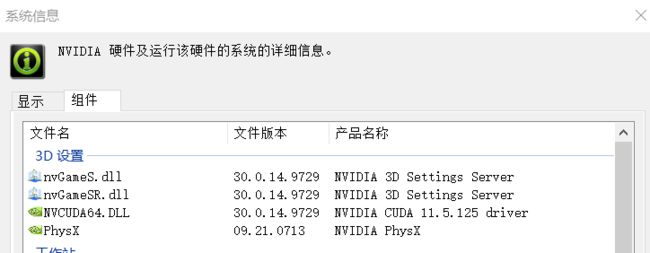
本机显卡驱动版本:11.5.125
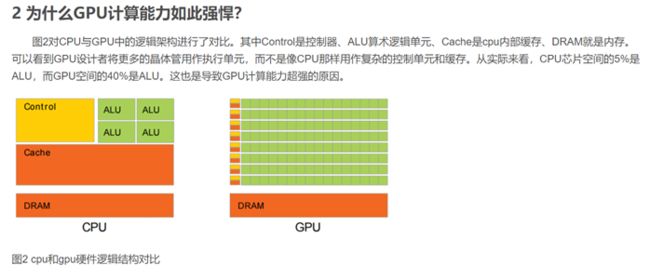
因为CPU要做得很通用,支持并行和串行操作。所以需要很强的通用性来处理各种不同的数据类型,同时又要支持复杂通用的逻辑判断,这样会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂,计算单元的比重被降低了。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。因此GPU的芯片比CPU芯片简单很多。
GPU计算能力这么强,被广泛使用!比如挖矿(比特币)、图形图像处理、数值模拟、机器学习算法训练等等。
怎么进行GPU编程呢?现在GPU形形色色,比如Nvidia、AMD、Intel都推出了自己的GPU,其中最为流行的就是(英伟达)Nvidia的GPU,其还推出了CUDA并行编程库。在Nvidia的GPU上,CUDA性能明显更高。目前CUDA和OpenCL(APPLE)是最主流的两个GPU编程库。
从编程语言角度看,CUDA和OpenCL都是原生支持C/C++的,其它语言想要访问还有些麻烦,比如Java,需要通过JNI来访问CUDA或者OpenCL。基于JNI,现今有各种Java版本的GPU编程库,比如JCUDA等。另一种思路就是语言还是由java来编写,通过一种工具将java转换成C。


2 显卡、显卡驱动、cuda、cuDNN
2.1 介绍
显卡:相当于一个小型的电脑系统,显卡这块PCB板,就好比电脑的主板,上面焊接了GPU核心(CPU),同时还有显存(内存),供电模块,散热。属于硬件层面。
显卡驱动:相当于介绍显卡的名片,告诉操作系统(Win10),这个显示设备叫什么,使用这个显示设备需要哪些文件,就好比用一些词语、句子来描述一个人。属于软件层面。
CUDA:统一计算设备架构(Compute Unified Device Architecture, CUDA)通用并行计算架构,GPU编程可以使用更多的流处理器、更多的线程数。作为全球两大电脑GPU生产商NVIDIA和AMD之中NVIDIA开发的一套并行运算平台,可以利用NVIDIA旗下显卡(AMD的不支持)的架构特性,进行科学计算,比如现在大热的人工智能等等,都需要GPU来协助进行计算。你可以把CUDA想象成NVIDIA公司提供的一个计算平台,你在这个平台上,可以使用NV公司提供给你的各种便捷计算工具来进行计算,不需要你自己再来开发这些工具。
简单来讲,比如,我们要算100000次从1加到10000000,如果利用一个4线程CPU,需要100000/4=250000次,而用GPU(假如它是1000个线程),性能相同的情况下,AMD的这个1000线程的GPU要算1000000/1000=1000次,NV的这个1000线程的GPU也是1000次。但是现在如果使用CUDA,它能提供一种类似高斯“1加到50,利用首尾相加再除以2”的方法来简化计算,那么使用CUDA后的NV显卡可能只需要计算200次,可见效率提高了很多。
NVIDIA cuDNN:是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow等,简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
总之,CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN。
2.2 安装
1.升级nvidia 显卡驱动 NVCUDA64.DLL 11.5.125
下载显卡管家 官方 GeForce 驱动程序 | NVIDIA
下载显卡驱动 驱动程序
2.下载nvidia cuda 11.3 CUDA Toolkit Archive | NVIDIA Developer
3.下载CUDNN
https://www.zhihu.com/search?type=content&q=CUDA%E5%AE%89%E8%A3%85%E6%95%99%E7%A8%8B
https://blog.csdn.net/weixin_43848614/article/details/117221384?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166116317616782248529168%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166116317616782248529168&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-117221384-null-null.142%5Ev42%5Epc_rank_34,185%5Ev2%5Econtrol&utm_term=cuda&spm=1018.2226.3001.4187cuDNN 作为 CUDA 的补丁 专为深度学习运算进行优化的
4.离线下载包 torch和tensorflow
一般包可以使用官方途径:pyserial · PyPI
这里介绍一下官方包怎么看:

.gz 源码 需要搭建环境
.whl 二进制文件 名字 -python版本-支持3 -none与构架无关
torch:Start Locally | PyTorch
conda创建环境并启动此环境,输入此代码:
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge
选择版本tensorflow:在 Windows 环境中从源代码构建 | TensorFlow
TensorFlow:使用 pip 安装 TensorFlow
pip install tensorflow-gpu==2.2.0 -i Simple Index
5.在线下载包 torchvision 、 torchaudio 、 tensorboard 、 pytorch-lightning
6.验证 torch和tensorflow 是否安装成功
https://www.tensorflow.org/guide/gpu
>> import torch
>>> torch.cuda.is_available()
True
>>> import tensorflow as tf
>>> print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
Num GPUs Available: 1 7.官网是有公开数据集,初学者可进行学习
3 其他及现存问题
总之,先不用管怎么在GPU环境下运行,之后再说,先把tensorflow和keras跑起来,准备学习时序预测的输入输出等。