DeepLearning tutorial(1)Softmax回归原理简介+代码详解
DeepLearning tutorial(1)Softmax回归原理简介+代码详解
@author:wepon
@blog:http://blog.csdn.net/u012162613/article/details/43157801
本文介绍Softmax回归算法,特别是详细解读其代码实现,基于python theano,代码来自:Classifying MNIST digits using Logistic Regression,参考UFLDL。
一、Softmax回归简介
关于算法的详细教程本文没必要多说,可以参考UFLDL。下面只简单地总结一下,以便更好地理解代码。
Softmax回归其实就相当于多类别情况下的逻辑回归,对比如下:
逻辑回归的假设函数(hypothesis):
整个逻辑回归模型的参数就是theta,h(*)是sigmoid函数,输出在0~1之间,一般作为二分类算法。对于具体的问题,找出最合适的theta便是最重要的步骤,这是最优化问题,一般通过定义代价函数,然后最小化代价函数来求解,逻辑回归的代价函数为:
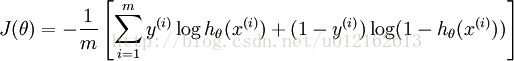
最小化J(theta),一般采用梯度下降算法,迭代计算梯度并更新theta。
Softmax的假设函数:

逻辑回归里将-theta*x作为sigmoid函数的输入,得到的是0或者1,两个类别。而softmax有有k个类别,并且将-theta*x作为指数的系数,所以就有e^(-theta_1*x)至e^( -theta_k*x)共k项,然后除以它们的累加和,这样做就实现了归一化,使得输出的k个数的和为1,而每一个数就代表那个类别出现的概率。因此:softmax的假设函数输出的是一个k维列向量,每一个维度的数就代表那个类别出现的概率。
Softmax的代价函数:

本质上跟逻辑回归是一样的,采用NLL,如果加上权重衰减项(正则化项),则为:

最小化代价函数,同样可以采用简单而有效的梯度下降,需要提到的是,在程序实现中,我们一般采用批量随机梯度下降,即MSGD,minibatch Stochastic Gradient Descent,简单来说,就是每遍历完一个batch的样本才计算梯度和更新参数,一个batch一般有几十到几百的单个样本。PS:随机梯度下降则是一个样本更新一次。
二、Softmax代码详细解读
首先说明一点,下面的程序采用的是MSGD算法,代价函数是不带权重衰减项的,整个程序实现用Softmax回归来classfy MINST数据集(识别手写数字0~9)。代码解读是个人理解,仅供参考,不一定正确,如有错误请不吝指出。
原始代码和经过我注释的代码:github地址
参数说明:上面第一部分我们的参数用theta表示,在下面的程序中,用的是W,权重,这两者是一样的。还有一点需要注意,上面的假设函数中是-theta*x,而在程序中,用的是W*X+b,本质也是一样的,因为可以将b看成W0,增加一个x0=1,则W*X+b=WX=-theta*x。
(1)导入一些必要的模块
import cPickle
import gzip
import os
import sys
import time
import numpy
import theano
import theano.tensor as T(2)定义Softmax回归模型
在deeplearning tutorial中,直接将LogisticRegression视为Softmax,而我们所认识的二类别的逻辑回归就是当n_out=2时的LogisticRegression,因此下面代码定义的LogisticRegression就是Softmax。
代码解读见注释:
#参数说明:
#input,输入的一个batch,假设一个batch有n个样本(n_example),则input大小就是(n_example,n_in)
#n_in,每一个样本的大小,MNIST每个样本是一张28*28的图片,故n_in=784
#n_out,输出的类别数,MNIST有0~9共10个类别,n_out=10
class LogisticRegression(object):
def __init__(self, input, n_in, n_out):
#W大小是n_in行n_out列,b为n_out维向量。即:每个输出对应W的一列以及b的一个元素。WX+b
#W和b都定义为theano.shared类型,这个是为了程序能在GPU上跑。
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
#input是(n_example,n_in),W是(n_in,n_out),点乘得到(n_example,n_out),加上偏置b,
#再作为T.nnet.softmax的输入,得到p_y_given_x
#故p_y_given_x每一行代表每一个样本被估计为各类别的概率
#PS:b是n_out维向量,与(n_example,n_out)矩阵相加,内部其实是先复制n_example个b,
#然后(n_example,n_out)矩阵的每一行都加b
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
#argmax返回最大值下标,因为本例数据集是MNIST,下标刚好就是类别。axis=1表示按行操作。
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
#params,模型的参数
self.params = [self.W, self.b]
#代价函数NLL
#因为我们是MSGD,每次训练一个batch,一个batch有n_example个样本,则y大小是(n_example,),
#y.shape[0]得出行数即样本数,将T.log(self.p_y_given_x)简记为LP,
#则LP[T.arange(y.shape[0]),y]得到[LP[0,y[0]], LP[1,y[1]], LP[2,y[2]], ...,LP[n-1,y[n-1]]]
#最后求均值mean,也就是说,minibatch的SGD,是计算出batch里所有样本的NLL的平均值,作为它的cost
def negative_log_likelihood(self, y):
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])
#batch的误差率
def errors(self, y):
# 首先检查y与y_pred的维度是否一样,即是否含有相等的样本数
if y.ndim != self.y_pred.ndim:
raise TypeError(
'y should have the same shape as self.y_pred',
('y', y.type, 'y_pred', self.y_pred.type)
)
# 再检查是不是int类型,是的话计算T.neq(self.y_pred, y)的均值,作为误差率
#举个例子,假如self.y_pred=[3,2,3,2,3,2],而实际上y=[3,4,3,4,3,4]
#则T.neq(self.y_pred, y)=[0,1,0,1,0,1],1表示不等,0表示相等
#故T.mean(T.neq(self.y_pred, y))=T.mean([0,1,0,1,0,1])=0.5,即错误率50%
if y.dtype.startswith('int'):
return T.mean(T.neq(self.y_pred, y))
else:
raise NotImplementedError()上面已经定义好了softmax模型,包括输入的batch :input,每个样本的大小n_in,输出的类别n_out,模型的参数W、b,模型预测的输出y_pred,代价函数NLL,以及误差率errors。
(3)加载MNIST数据集
def load_data(dataset):
# dataset是数据集的路径,程序首先检测该路径下有没有MNIST数据集,没有的话就下载MNIST数据集
#这一部分就不解释了,与softmax回归算法无关。
data_dir, data_file = os.path.split(dataset)
if data_dir == "" and not os.path.isfile(dataset):
# Check if dataset is in the data directory.
new_path = os.path.join(
os.path.split(__file__)[0],
"..",
"data",
dataset
)
if os.path.isfile(new_path) or data_file == 'mnist.pkl.gz':
dataset = new_path
if (not os.path.isfile(dataset)) and data_file == 'mnist.pkl.gz':
import urllib
origin = (
'http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz'
)
print 'Downloading data from %s' % origin
urllib.urlretrieve(origin, dataset)
print '... loading data'
#以上是检测并下载数据集mnist.pkl.gz,不是本文重点。下面才是load_data的开始
#从"mnist.pkl.gz"里加载train_set, valid_set, test_set,它们都是包括label的
#主要用到python里的gzip.open()函数,以及 cPickle.load()。
#‘rb’表示以二进制可读的方式打开文件
f = gzip.open(dataset, 'rb')
train_set, valid_set, test_set = cPickle.load(f)
f.close()
#将数据设置成shared variables,主要时为了GPU加速,只有shared variables才能存到GPU memory中
#GPU里数据类型只能是float。而data_y是类别,所以最后又转换为int返回
def shared_dataset(data_xy, borrow=True):
data_x, data_y = data_xy
shared_x = theano.shared(numpy.asarray(data_x,
dtype=theano.config.floatX),
borrow=borrow)
shared_y = theano.shared(numpy.asarray(data_y,
dtype=theano.config.floatX),
borrow=borrow)
return shared_x, T.cast(shared_y, 'int32')
test_set_x, test_set_y = shared_dataset(test_set)
valid_set_x, valid_set_y = shared_dataset(valid_set)
train_set_x, train_set_y = shared_dataset(train_set)
rval = [(train_set_x, train_set_y), (valid_set_x, valid_set_y),
(test_set_x, test_set_y)]
return rval(4)将模型应用于MNIST数据集
def sgd_optimization_mnist(learning_rate=0.13, n_epochs=1000,
dataset='mnist.pkl.gz',
batch_size=600):
#加载数据
datasets = load_data(dataset)
train_set_x, train_set_y = datasets[0]
valid_set_x, valid_set_y = datasets[1]
test_set_x, test_set_y = datasets[2]
#计算有多少个minibatch,因为我们的优化算法是MSGD,是一个batch一个batch来计算cost的
n_train_batches = train_set_x.get_value(borrow=True).shape[0] / batch_size
n_valid_batches = valid_set_x.get_value(borrow=True).shape[0] / batch_size
n_test_batches = test_set_x.get_value(borrow=True).shape[0] / batch_size
######################
# 开始建模 #
######################
print '... building the model'
#设置变量,index表示minibatch的下标,x表示训练样本,y是对应的label
index = T.lscalar()
x = T.matrix('x')
y = T.ivector('y')
#定义分类器,用x作为input初始化。
classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10)
#定义代价函数,用y来初始化,而其实还有一个隐含的参数x在classifier中。
#这样理解才是合理的,因为cost必须由x和y得来,单单y是得不到cost的。
cost = classifier.negative_log_likelihood(y)
#这里必须说明一下theano的function函数,givens是字典,其中的x、y是key,冒号后面是它们的value。
#在function被调用时,x、y将被具体地替换为它们的value,而value里的参数index就是inputs=[index]这里给出。
#下面举个例子:
#比如test_model(1),首先根据index=1具体化x为test_set_x[1 * batch_size: (1 + 1) * batch_size],
#具体化y为test_set_y[1 * batch_size: (1 + 1) * batch_size]。然后函数计算outputs=classifier.errors(y),
#这里面有参数y和隐含的x,所以就将givens里面具体化的x、y传递进去。
test_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: test_set_x[index * batch_size: (index + 1) * batch_size],
y: test_set_y[index * batch_size: (index + 1) * batch_size]
}
)
validate_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: valid_set_x[index * batch_size: (index + 1) * batch_size],
y: valid_set_y[index * batch_size: (index + 1) * batch_size]
}
# 计算各个参数的梯度
g_W = T.grad(cost=cost, wrt=classifier.W)
g_b = T.grad(cost=cost, wrt=classifier.b)
#更新的规则,根据梯度下降法的更新公式
updates = [(classifier.W, classifier.W - learning_rate * g_W),
(classifier.b, classifier.b - learning_rate * g_b)]
#train_model跟上面分析的test_model类似,只是这里面多了updatas,更新规则用上面定义的updates 列表。
train_model = theano.function(
inputs=[index],
outputs=cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
###############
# 开始训练 #
###############
print '... training the model'
patience = 5000
patience_increase = 2
#提高的阈值,在验证误差减小到之前的0.995倍时,会更新best_validation_loss
improvement_threshold = 0.995
#这样设置validation_frequency可以保证每一次epoch都会在验证集上测试。
validation_frequency = min(n_train_batches, patience / 2)
best_validation_loss = numpy.inf #最好的验证集上的loss,最好即最小。初始化为无穷大
test_score = 0.
start_time = time.clock()
done_looping = False
epoch = 0
#下面就是训练过程了,while循环控制的时步数epoch,一个epoch会遍历所有的batch,即所有的图片。
#for循环是遍历一个个batch,一次一个batch地训练。for循环体里会用train_model(minibatch_index)去训练模型,
#train_model里面的updatas会更新各个参数。
#for循环里面会累加训练过的batch数iter,当iter是validation_frequency倍数时则会在验证集上测试,
#如果验证集的损失this_validation_loss小于之前最佳的损失best_validation_loss,
#则更新best_validation_loss和best_iter,同时在testset上测试。
#如果验证集的损失this_validation_loss小于best_validation_loss*improvement_threshold时则更新patience。
#当达到最大步数n_epoch时,或者patience> sys.stderr, ('The code for file ' +
os.path.split(__file__)[1] +
' ran for %.1fs' % ((end_time - start_time)))
完