迁移学习一些笔记整理
迁移学习
1. 定义及分类
定义
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
目标
将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。
简介
-
域(domain): D = { χ , P ( X ) } D=\left\{ \chi,P(X)\right\} D={χ,P(X)},其中 χ \chi χ表示特征空间, P ( X ) P(X) P(X)表示边缘概率密度分布。表示某个时刻的某个特定领域,可以表示为数据集。
-
任务(task): T = { y , f ( ˙ ) } T=\left\{y,f(\dot{})\right\} T={y,f(˙)}, y y y表示标签空间, f ( ˙ ) f(\dot{}) f(˙)表示目标预测函数。表示预测、分类任务。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MXwAucDX-1639382496688)(E:\Study\迁移学习\分布图)]
关键点
-
研究哪些知识在不同的领域或者任务中进行迁移学习,即不同领域之间有哪些共有知识可以迁移。
-
采用哪种迁移学习的特定算法,即如何设计出合适的算法来提取和迁移共有知识。
-
研究什么情况下适合迁移,负迁移的问题。负迁移指的是旧知识对算法学习新知识的阻碍作用
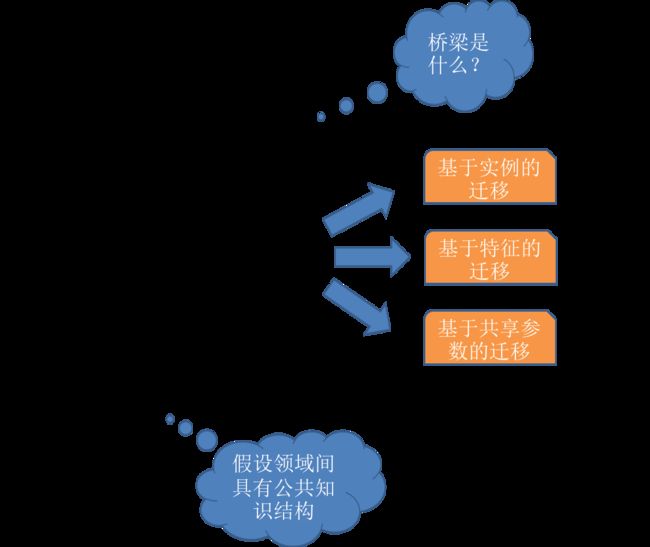
2. 基于实例的迁移
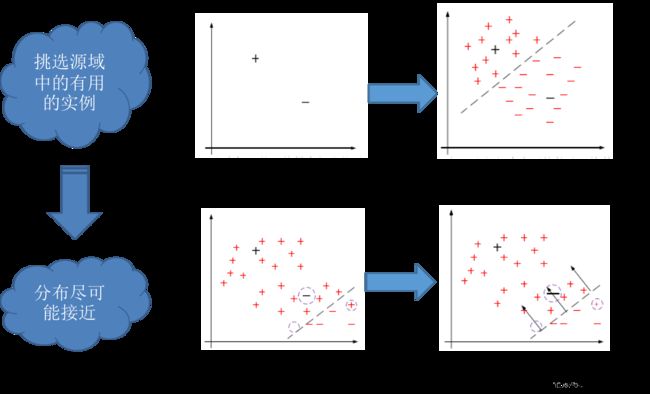
基于实例的迁移学习研究的是,如何从源领域中挑选出,对目标领域的训练有用的实例,比如对源领域的有标记数据实例进行有效的权重分配,让源域实例分布接近目标域的实例分布,从而在目标领域中建立一个分类精度较高的、可靠地学习模型。
因为,迁移学习中源领域与目标领域的数据分布是不一致,所以源领域中所有有标记的数据实例不一定都对目标领域有用。戴文渊等人提出的TrAdaBoost算法就是典型的基于实例的迁移。
3. 基于特征的迁移
基于特征映射的迁移学习算法,关注的是如何将源领域和目标领域的数据从原始特征空间映射到新的特征空间中。
这样,在该空间中,源领域数据与的目标领域的数据分布相同,从而可以在新的空间中,更好地利用源领域已有的有标记数据样本进行分类训练,最终对目标领域的数据进行分类测试。
4. 基于共享参数的迁移
基于共享参数的迁移研究的是如何找到源数据和目标数据的空间模型之间的共同参数(建模网络参数?)或者先验分布,从而可以通过进一步处理,达到知识迁移的目的,假设前提是,学习任务中的的每个相关模型会共享一些相同的参数或者先验分布。
5.Domain-Adversarial Neural Netowrk(DANN)
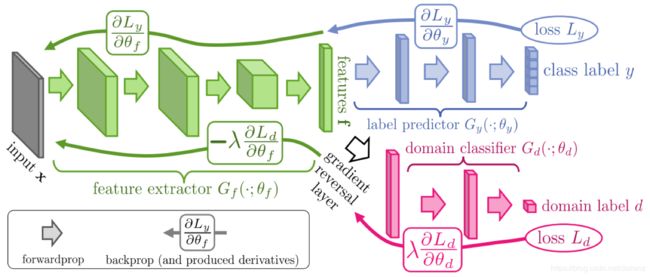
领域适应性网络,框架由Feature Extractor、Label Predictor和Domain Classifier三个部分组成,并且在Feature Extractor和Domain Classifier 之间有一个Gradient Reversal Layer,将域分类器的梯度传给特征提取器更新权重;其中Domain Classifier只在训练过程中发挥作用。label predictor 类似于Regressor。
6.(Domain Separation Networks)DSN
DSN 方法认为各领域都是由公共部分和私有部分组成的,公共部分可以学习领域的公共特征,私有部分用来保持各个领域独立的特性。
Bousmalis K , Trigeorgis G , Silberman N , et al. Domain Separation Networks[C].Annual
Conference on Neural Information Processing Systems , 2016 ,pp. 343-351.
7.零次学习(Zero-shot Learning)
7.文献有价值内容
迁移学习的泛化边界
J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. Wortman. Learning bounds for
domain adaptation[C]. In Advances in neural information processing systems, 2008 , pp.
129–136.
通过多个源域分布的加权组合结果来表示目标域数据的预测结果
Y. Mansour, M. Mohri, and A. Rostamizadeh. Domain adaptation with multiple
sources[C]. In Advances in neural information processing systems, 2009, pp. 1041–1048.
多源域对抗网络(Multi-source Domain Adversarial Network, MDAN),深度鸡尾酒网络(Deep
Cocktail Network,DCTN),矩匹配网络(Moment Matching Network,MMN),多特征空间适应网络(Multiple Feature Spaces Adaptation Network,MFSAN)。
所有这些深度多源域自适应方法都使用共享特征提取器网络对称地将多个源域和目标域映射到同一个空间中。
对于 MDAN 和 DCTN 中的每个源域与目标域对,两个网络都采用了领域判别器来区分源域和目标域特征。
MDAN 将所有源域的数据特征和标签输入到同一个特征提取网络中,以训练单一的任务分类器,然而DCTN 将不同源域的数据特征输入到不同的特征提取网路中,并为各个源域训练一个任务分类器,将置信分数作为各分类器的权重以预测目标域数据。
MMN 和 MFSAN 将各源域与目标域的特征分布进行对齐,在特征对齐迭代过程中,各支路产生的的自适应损失其权重设置相同且不变。
MFSAN 通过各源域分类器的均值输出得到目标域数据的预测结果,然而 MMN 是通过各源域分类器的加权输出对目标域数据进行预测。
迁移学习的有效性
(1)源域和目标域的学习任务是相关的或者是相似的,源域和目标域应该拥有相同的种类类别
(2)源域和目标域不能有太大的分布差异,即领域样本之间不能有太大的差异;
(3)需要训练出一个可以同时适用于源域和目标域的网络模型。
负迁移
负迁移指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。
方法没选好,从源域上获得的知识与任务域的知识具有相反作用。
特征分布差异的评价指标
特征分布差异的评价指标,最大均值差异(MMD)度量准则,相互关系对齐(CORAL)度量准则,对比领域差异(Contrastive Domain Discrepancy,CDD)度量和 Wasserstein 度量,四种度量准则量化数据分布差异;
最大均值差异(MMD)度量准则
为了使用 MMD 度量进行域自适应,研究学者主要是在源域与目标域相同全连接层的输出之间计算 MMD,并将其最小化。
DDC方法 :在第 2 层全连接层加入域自适应层,采用的度量为 MMD 度量,提出了 DDC 方法,解决了域自适应问题;
多核MMD:在3 层全连接层处同时加入了域自适应层,采用的度量为多核 MMD 度量,区别于 DDC 方法中只在第七层全连接层后加入单核的 MMD 度量,多核 MMD 更具有特征表达能力;
相互关系对齐(CORAL)度量准则
相似于 MMD,主要是通过计算以及最小化领域特征之间的二阶统计量,也可称为协方差矩阵或欧式距离。
对比领域差异(Contrastive Domain Discrepancy,CDD)度量
基于 MMD 度量提出的,它与 CORAL 度量准则和原始的 MMD 度量准则不同,它是将同一种类数据之间的差异最小化,同时将不同种类之间的差异最大化。