迁移学习在风控建模冷启动中的应用(简介)
迁移学习在风控建模冷启动中的应用(简介)
目录
迁移学习在风控建模冷启动中的应用(简介)
背景与文献回顾
基础理论介绍
迁移学习概念
迁移学习方法
实证分析
实验结论与局限性
现状与展望
背景与文献回顾
背景
- 风控在国家层面的重要性
三大攻坚战的“作战图”,其中之一就是推动重大风险防范化解取得明显进展。 2020年是进行防范化解金融风险目标的收官之年。
- 风控在金融机构层面的重要性
信贷风险控制是贷款机构的生存之本,也是提高收益的关键。
- 互联网金融风控体系
互联网金融风控体系有三个构成部分:数据信息,策略信息,人工智能模型。 在风控领域,风险规避手段有规则挖掘和人工智能模型两种。
- 冷启动问题
而当从业者面临新业务时,总是会遇到只有很少量数据甚至没有数据的情况,而且在很多场景下,收集标注数据代价是十分昂贵并且十分困难的。冷启动就是指在这种缺少数据的情况下,建立新业务模型的过程。
文献回顾
在风险控制领域中,信用评估的方法在初期是定性分析为主,后来统计方法进入到信用评估领域。 近些年来,随着人工智能越来越多得进入到风险控制领域,信用评估又增添了更多的方法。
以前解决初创期信贷产品的冷启动问题多依赖于业务人员的丰富的经验,可能因为业务理解有偏差而造成建模的不精确。后来针对产品初创期基本无数据积累的特点,提出类产品模型、伪风险模型、综合评价法、相似度模型、第三方通用评分几种建模方案的观点 , 以及无样本可依的风险模型可以根据德尔菲法(也叫做专家调查法)的模型来进行风险控制 。
机器学习领域,最初的关于迁移学习的基本研究是在研讨话题为“Learning to Learn”的NIPS-95研讨会上,这是关注于保留和重用之前学到的知识的机器学习方法的研讨会。自从1995年开始,越来越多的人开始关注和如今的迁移学习类似的学习方法,比如知识迁移,感应迁移等等。上世纪九十年代,Baxter等学者将迁移学习概念引入到统计学领域并且提出一些迁移学习方法。2005年, 美国国防部高级研究计划局的信息处理技术办公室发表的代理公告,给出了迁移学习的新任务,即把之前任务中学习到的知识运用到新的任务中的能力。21世纪初期,Schuller等对学习任务之间的相关性进行形式化的定义,等等,这些是对迁移学习理论的研究。 上海交大Dai等人提出TrAdaboost方法,在迁移学习领域使用AdaBoost的算法思想。香港科技大学Pan等人提出Transfer Component Analysis(TCA)方法,将MMD作为度量准则。Blitzer等人提出Structural Corresponding Learning(SCL)算法,将一个空间中的一些特征使用映射变换到其他空间中的轴特征上。中科院的赵等人对于无标签和有标签两种情况,提出TransEMDT方法,对前者,使用K均值聚类算法寻找最优化的标定参数,对后者,使用Decision Tree建立Robust的行为识别模型 , 等等。 迁移学习越来越成为研究的热门领域。
基础理论介绍
迁移学习
因为迁移学习打破了传统机器学习的独立同分布假设前提,所以,传统的机器学习从每个任务中抓取信息,而迁移学习可以在目标任务缺少高质量的训练数据的时候,从旧任务中获取知识并迁移到目标任务的完成过程中。 概念:给定源域DS和任务TS,一个目标域DT和任务TT,迁移学习使用DS和TS中学到的知识,来进行 DT中目标预测函数的学习,并且有DS≠DT或TS≠TT。当源域和目标域相同且源任务和目标任务相同,则学习问题是一个传统机器学习问题。
根据迁移什么可分为:
- 基于样本的迁移学习
根据一定的权重生成规则,重新加权源域中的一些标记数据,以便在目标域中使用
- 基于特征的迁移学习
通过特征变换的方式来迁移,或者将源域、目标域的数据特征变换到统一特征空间中,再利用传统的机器学习方法进行分类识别。
- 基于模型的迁移学习
发现源域和目标域之间的共享信息
- 基于关系的迁移学习
构建源域和目标域之间的相关性知识的映射,关注源域和目标域的样本之间的关系。
迁移学习方法
- TrAdaBoost
给源域中的样本赋予权重,经过迭代逐渐降低与目标域样本最不相同的样本的权重来削弱其影响来使其分布靠近目标域。
- 数据分布自适应
- TCA: 假设如果边缘分布接近,则目标域和源域的条件分布也会接近 目标是减小目标域和源域的边缘概率分布的距离。
- JDA: 假设源域和目标域的边缘分布和条件分布不同。其同时适配源域和目标域的边缘分布和条件分布。
- BDA: BDA通过采用一种平衡因子μ来动态调整边缘分布以及条件分布的距离。 TCA是μ=0时的BDA,JDA是μ=0.5时的BDA。
- 其他
特征选择法SCL, 子空间学习法之统计特征对齐CORAL
实证分析
(一)数据准备
- 源域数据
贷款业务A:贷款期限1-3年,平均贷款金额几千到几万,特点是无抵押,凭信用程度来贷款,即中等额度的信用贷款 数据集A保存在A_train_final.csv(含特征,标签),有40k条,业务A的训练数据。
- 目标域数据
贷款业务B:贷款期限7-30天,平均贷款金额为一千,特点是额度小、周期短、无抵押、流程快、利率高,即小额短期现金贷款。 数据集B保存在B_train_final.csv(含特征,标签)中,为4k条,是业务B的训练数据。
数据集中的特征包括no(用户id),ProductInfo开头的字段,WebInfo开头的字段,UserInfo开头的字段等,特征一共490维。标记:flag,取值0或1。数据集A和数据集B的字段相同。 本文所用的跨产品数据即具有两个不同产品的数据,来自平安旗下专业第三方商业征信机构——前海征信的信用贷款业务和现金贷业务脱敏数据。
(二)特征工程
缺失值图
数据集A的列的无效的简单可视化

数据集B的列的无效的简单可视化
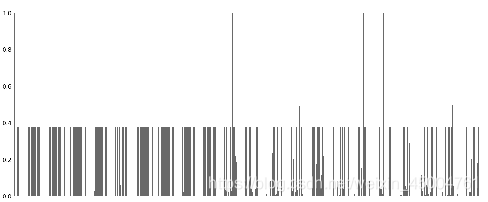
数据的缺失比较严重,数据集A绝大多数的列有约40%的缺失,数据集B绝大多数的列有60%多的缺失。且数据集A和数据集B缺失也是有规律的。 不删除, 采用缺失值填充-1的方法。
相关性
相关性热力图:
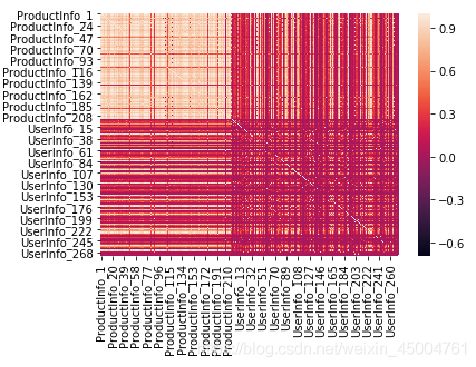
计算相关系数矩阵,可以发现相关系数大于等于0.9的列数达到了302个。之后利用热力图可以可视化数据表里多个特征两两的相似度,由图可以看到,相关性也有一定的规律。
其他
数据部分维度为分类“0-1”变量,数据集缺失值填充-1后,归为离散型变量。其余归为连续型变量。将连续型变量做标准化Normalization处理。
因为数据不平衡,所以做过采样处理,又因为有分类变量,SMOTE不合适,所以使用SMOTENC增加少数类样本。
(三)TrAdaBoost迁移学习实验
为了控制变量,超参数优化后输出相对最优的传统机器学习模型后,将该模型作为相应的TrAdaBoost迁移学习模型的基学习器。使用随机搜索RandomizedSearchCV
|
|
模型 |
AUC |
ACC |
precision |
Recall |
F1-score |
|
对照组1 |
RandomForest |
0.6843 |
0.6842 |
0.6430 |
0.8271 |
0.7235 |
| TrAdaBoost(RandomForest) |
0.7702 |
0.7704 |
0.9274 |
0.5863 |
0.7184 |
|
|
对照组2 |
GradientBoosting |
0.7759 |
0.7758 |
0.7538 |
0.8170 |
0.7841 |
| TrAdaBoost(GradientBoosting) |
0.7815 |
0.7819 |
0.8597 |
0.6721 |
0.7544 |
从以上表格可以发现,TrAdaBoost(RandomForest),TrAdaBoost(GradientBoosting)的precision相比于各自的对照组均较高,而recall较低,模型较为保守。F1-score是综合考虑precision和recall的,但是当两个模型,一个precision较高,recall较低,另一个recall较高,precision较低的时候,f1-score可能是差不多的,也不能基于此来作出选择。 从表格可以看到,以GradientBoosting和RandomForest为基学习器的TrAdaBoost迁移学习模型效果较好,相比于传统机器学习模型RandomForest和GradientBoosting,在AUC上有了一定提升。 总的来看,对于源域和目标域不同的跨产品数据,相比于部分传统机器学习模型来说,TrAdaBoost迁移学习算法可以取得更好的结果。TrAdaBoost迁移学习算法可以成为冷启动问题方面研究的一个方向。
(四)TrAdaBoost的拓展实验
选择其中表现较好且运行速度较快的RandomForest进行进一步的实验。
- 拓展实验1
TrAdaBoost (RandomForest)评价指标:
| test_size |
AUC |
ACC |
precision |
Recall |
F1-score |
| 0.3 |
0.7758 |
0.7769 |
0.9297 |
0.5960 |
0.7264 |
| 0.5 |
0.7757 |
0.7733 |
0.9078 |
0.6158 |
0.7338 |
| 0.75 |
0.7702 |
0.7704 |
0.9274 |
0.5863 |
0.7184 |
RandomForest评价指标:
| test_size |
AUC |
ACC |
precision |
Recall |
F1-score |
| 0.3 |
0.7247 |
0.7240 |
0.6817 |
0.8341 |
0.7502 |
| 0.5 |
0.7015 |
0.7031 |
0.6704 |
0.8161 |
0.7361 |
| 0.75 |
0.6843 |
0.6842 |
0.6430 |
0.8271 |
0.7235 |
首先看目标域数据划分训练集与测试集的比例对实验结果的影响,选择测试集所占比例(test_size)分别为0.3,0.5,0.75进行实验。 可以看到test_size对训练结果有些影响,从0.3到0.5再到0.75,主要的评价指标AUC逐渐降低。其中,RandomForest和基于RandomForest的迁移学习都是test_size取值为0.3时候效果较好。
- 拓展实验2
| Ratio |
0.01 |
0.02 |
0.03 |
0.04 |
0.05 |
0.1 |
0.2 |
0.3 |
0.4 |
0.5 |
| RF
|
0.6322 |
0.6892 |
0.6897 |
0.7165 |
0.7082 |
0.7036 |
0.7090 |
0.7175 |
0.7229 |
0.7238 |
| TrAdaBoost(RF) |
0.7783 |
0.7785 |
0.8007 |
0.7841 |
0.7672 |
0.7650 |
0.7670 |
0.7652 |
0.7619 |
0.7511 |
选择test_size=0.3,进行下面的实验。再看目标域训练数据和源域训练数据的比例对训练结果的影响。选择比例0.01,0.02,0.03,0.04,0.05,0.1,0.2,0.3,0.4,0.5。
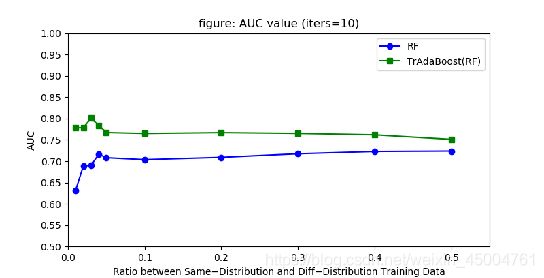
可以看到在目标域训练数据量和源域训练数据量相差悬殊(比例小于0.1)的时候,每个模型的AUC的变化相差较大,两个模型之间(RandomForest和使用TrAdaBoost的RandomForest)的AUC相差较大。可以发现,此时使用TrAdaBoost的RandomForest效果明显好于RandomForest。当比例趋于0的时候,未使用TrAdaBoost的RandomForest效果明显下降。 当在目标域训练数据量和源域训练数据量比例在0.1到0.5之间的时候,两个模型各自变化不大,其中RandomForest的AUC缓慢上升,使用TrAdaBoost的RandomForest的AUC则略有缓慢下降的趋势。两者之间的AUC差距在缩小。
总结可知,目标域训练数据和源域训练数据两者数量相差越悬殊,使用TrAdaBoost的RandomForest的效果比单纯使用RandomForest要好得更多。由TrAdaBoost算法原理也可以更好的解释以上的现象,Tradaboost的主要思想是通过自动调整训练数据的权重,利用Boosting筛选出源域训练数据中与目标域数据很不相同的数据。剩下的源域训练数据被当作额外的训练数据,在目标域训练数据稀缺的情况下,对训练模型大有帮助。
- 拓展实验3
TrAdaBoost : AUC
| iters |
0.0500 |
0.1000 |
0.5000 |
| 5 |
0.7346 |
0.7087 |
0.6520 |
| 10 |
0.7672 |
0.7650 |
0.7511 |
| 30 |
0.7776 |
0.7800 |
0.7762 |
| 50 |
0.7857 |
0.7675 |
0.7856 |
| 70 |
0.7836 |
0.7744 |
0.7768 |
| 90 |
0.7739 |
0.7863 |
0.7788 |
最后选择拓展实验2中的比例0.05,0.1,0.5,进行TrAdaBoost中迭代次数(iterations)对结果的影响的实验。
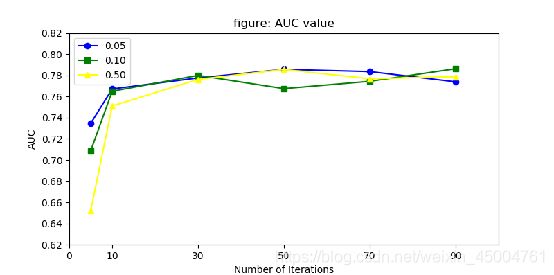
在迭代次数较低的时候(比如5),模型的效果明显降低,算法原理也可以解释这种情况,每次迭代,对于源域训练数据,当它们被错误地预测时,他们可能是那些与目标域训练数据最不相似的数据。 因此,算法添加了一个机制来减少这些源域训练数据的权重,以削弱它们的影响。
TrAdaBoost: ACC
| iters |
0.0500 |
0.1000 |
0.5000 |
| 5 |
0.7425 |
0.7070 |
0.6501 |
| 10 |
0.7726 |
0.7639 |
0.7500 |
| 30 |
0.7839 |
0.7796 |
0.7755 |
| 50 |
0.7913 |
0.7666 |
0.7849 |
| 70 |
0.7893 |
0.7742 |
0.7760 |
| 90 |
0.7779 |
0.7863 |
0.7782 |
ACC可以大致看作TrAdaBoost中错误率的相反面,随着迭代次数的增加,可以预见TrAdaBoost将逐渐收敛。
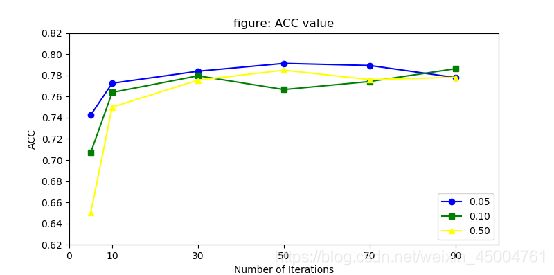
总结可知,在选择迭代次数的时候,迭代次数最好不要选的太小。
(五)数据分布自适应迁移学习实验
|
|
AUC |
ACC |
precision |
Recall |
F1-score |
| TCA |
0.5984 |
0.5984 |
0.6312 |
0.4734 |
0.5410 |
| JCA |
0.5758 |
0.5758 |
0.6036 |
0.4415 |
0.5100 |
| BCA |
0.5771 |
0.5771 |
0.6051 |
0.4441 |
0.5123 |
因为TCA,JDA,BDA的缺点即对于大矩阵还是需要很多计算时间和内存空间,容易内存溢出,以及电脑性能有限的原因 , 所以选取原数据中的10%进行了实验。
实验数据量偏小,质量较差,原数据缺失值较多 , 并且存在一定的实验误差,在误差范围内,三种方法都取得了不错的效果。
总体来说,数据分布自适应迁移学习全程没有使用目标域的样本标签,它的效果比TrAdaBoost要差,但是仍然可以作为风控中冷启动问题的研究方法之一。特别是在初期,目标域完全没有标签的时候,这是一种非常实用的方法。之后,在冷启动的中后期有少量样本标签的时候,可以转而使用TrAdaBoost算法。
(六)其他迁移学习方法初探
- SCL
| num_pivots |
AUC |
ACC |
precision |
Recall |
F1-score |
| 5 |
0.7238 |
0.7222 |
0.6831 |
0.8102 |
0.7412 |
| 10 |
0.7266 |
0.7249 |
0.6877 |
0.8000 |
0.7396 |
| 30 |
0.7165 |
0.7146 |
0.6772 |
0.7912 |
0.7297 |
| 50 |
0.7078 |
0.7083 |
0.6829 |
0.7856 |
0.7307 |
| 100 |
0.6846 |
0.6841 |
0.6570 |
0.7619 |
0.7056 |
SCL实验中,本次实验的公共特征数目(num_pivots)分别取5,10,30,50,100个特征,基本分类器采用RandomForest。结果如下表。SCL方法中,公共特征的数量对结果有一定影响,需要根据风控的实际问题来选择。从表中可以看出,SCL有一定的应用效果。
- CORAL
|
|
AUC |
ACC |
precision |
Recall |
F1-score |
| CORAL |
0.5359 |
0.5359 |
0.5213 |
0.8798 |
0.6547 |
CORAL实验中,将数据的统计特征变换对齐后,利用RandomForest构建分类器学习。结果如下表。评价结果比SCL较差,但也是可以研究应用于冷启动的方法之一。
实验结论与局限性
实验结论
在目标域有一定标签的时候,可以选择使用TrAdaBoost。
另外,本论文对TrAdaBoost进行了扩展实验发现: (1)需要选择合适的目标域划分训练集和测试集的比例 (2)目标域训练数据和源域训练数据的比例对训练结果影响较大,目标域训练数据和源域训练数据两者数量相差越悬殊,使用TrAdaBoost的效果比单纯使用传统机器学习的效果要好的更多,所以在冷启动初期,目标域样本稀缺时候,使用TrAdaBoost迁移学习模型要比传统机器学习要好; (3) TrAdaBoost的迭代次数较低的时候,模型的效果较低,随着迭代次数的增加,TrAdaBoost将逐渐收敛,所以迭代。 次数不能选的太小。
而之后我们研究了当目标域完全没有标签的时候,可以尝试采用数据分布自适应 . 数据分布自适应完全没有使用目标域样本,它们的效果比TrAdaBoost要差,但是冷启动初期完全没有目标域标签的时候,非常实用的一种方法。可以在冷启动初期采用数据分布自适应的方法,而在有一定目域样本的冷启动中后期采用TrAdaBoost。
进而本论文提出,可以将特征选择法SCL,统计特征对齐CORAL等迁移学习方法纳入到风控冷启动问题的研究之中。
局限性与建议
- 如果源域和目标域不相似却强制迁移,或者源域和目标域虽然相似但是迁移学习方法不够好,都可能造成负迁移。 传递迁移学习(TTL)
- 特征工程可以使用不同方法,然后对比。比如在实际情景中,基于构造的业务特征进行算法衍生、数学变换、特征交叉与组合等,衍生出有新的含义的特征等;比如尝试使用过滤法、嵌入法、包装法等进行特征选择,来提高预测的准确度等。
- 本文所用的评价指标较少,主要看的是AUC。而在实际业务中,企业不一定看重AUC指标,例如银行更加看重预期违约的客户是否被筛选出来等等。可以根据实际情景来选择不同的指标,根据不同的场景侧重不同的方面。
- 由于时间以及篇幅问题,还有很多迁移学习算法并没有尝试和研究, 比如在最小化分布距离的同时,加入实例选择的迁移联合匹配的TJM(Tranfer Joint Matching)方法;以及随着深度学习越来越热,使用深度神经网络进行迁移学习的深度迁移学习(BA,DDC等)。在后续的研究中可以多加尝试。
现状与展望
现状难点
- “数据太少”
在金融领域,目前的做法是使用半监督学习,将业务风控专家的经验和实际的信贷结果相结合,风控专家可以实时的介入,根据输出结果做一些调整,实时反馈到模型训练的迭代提升中。并且,金融的业务结果和样本非常珍贵。之前通过业务A积累数据,后来建立业务B,虽然业务不同,但是业务A的样本不能丢掉。这时候常常在新业务下,尽可能复用旧的知识
- “数据太多”
数据特征维度多,问题在于如何将大数据和金融风控的问题挂钩起来,实践中常用的方法有深度学习。并且尝试不同的深度特征编码方法,利用半监督学习对原始数据进行预处理来进行特征的降维。
模型的可解释性的意义在于:需要和申请人解释打分的结果;金融环境是一个复杂的环境,不能从黑盒中拿出结果,这样是不利于金融风险的估计以及控制的,很有可能存在风险漏洞。常用的方法是利用LIME捕获结果或者局部结果中的关键变量,之后找出是导致结果的变化的特征是什么。
展望
对于金融领域数据太少的冷启动问题,迁移学习的应用可以协助解决新领域缺乏数据的问题,并且将金融领域珍贵的已有的业务结果和样本进行充分的运用。
目前研究者提出多种实现域自适应的算法,可以应用到冷启动中,比如用低秩矩阵来重构数据点,实现域之间的鲁棒自适应;赋给源域中的样本权重,使源域的分布接近目标域等。
迁移学习TrAdaBoost模型给源域中的样本赋予权重,经过迭代逐渐降低与目标域样本最不相同的样本的权重来削弱其影响来使其分布靠近目标域,并且TrAdaBoost没有在特征空间上做扭曲变换,具有较好的解释性,可以更加广泛得应用于风控领域。而数据分布自适应(TCA,JDA,BDA等)通过一些变换,将目标域和源域的数据概率分布的距离拉近,虽然在解释性上没有TrAdaBoost那么好,但是并不需要目标场景中有真实的样本标签,在冷启动的初期的阶段的应用会更好。特征选择法是通过机器学习方法选择出源域和目标域中公共的特征并且在这些特征上两个领域的数分布是一致的。这种方法可以帮助风控人员找到旧业务和新业务之间特征的联系,对珍贵数据的重用和新业务的建立将大有帮助。另外,还有一些基于经典的特征选择法SCL的扩展工作,比如将特征选择和空间学习相结合,或者特征选择和信息不变性相结合的FSSL,或者在优化目标中同时进行边缘分布自适应和源域样本选择的TJM等等都可以在将来研究如何在风控领域中得到良好的应用。统计特征统计特征对齐是子空间学习法的一种,其中CORAL是将目标域和源域的二阶特征对齐,还有SA、SDA进行目标域和源域的一阶特征对齐。子空间学习法假设在变换后的子空间中,目标域和源域的分布相似。子空间学习法除了统计特征对齐,还有流行学习法,子空间学习法可以和概率分布自适应方法进行结合,比如边缘分布自适应和流形变换相结合等等。
对新业务样本标签要求的放松以及对新业务样本数量要求不多,还有对旧业务珍贵样本数据的重用等等,这些迁移学习方法在风控领域具有的优点,势必将在风控领域,特别是冷启动缺少数据的阶段得到更多的关注。