前言
在Mybatis源码-Executor的执行过程中对Mybatis的一次实际执行进行了说明,在整个执行过程中,没有对缓存相关逻辑进行分析,这本篇文章中,将结合示例与源码,对Mybatis中的一级缓存和二级缓存进行说明。
正文
一. 一级缓存机制展示
在Mybatis中如果多次执行完全相同的SQL语句时,Mybatis提供了一级缓存机制用于提高查询效率。一级缓存是默认开启的,如果想要手动配置,需要在Mybatis配置文件中加入如下配置。
其中localCacheScope可以配置为SESSION(默认)或者STATEMENT,含义如下所示。
| 属性值 | 含义 |
|---|---|
| SESSION | 一级缓存在一个会话中生效。即在一个会话中的所有查询语句,均会共享同一份一级缓存,不同会话中的一级缓存不共享。 |
| STATEMENT | 一级缓存仅针对当前执行的SQL语句生效。当前执行的SQL语句执行完毕后,对应的一级缓存会被清空。 |
下面以一个例子对Mybatis的一级缓存机制进行演示和说明。首先开启日志打印,然后关闭二级缓存,并将一级缓存作用范围设置为SESSION,配置如下。
映射接口如下所示。
public interface BookMapper {
Book selectBookById(int id);
}映射文件如下所示。
Mybatis的执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
System.out.println(bookMapper.selectBookById(1));
}
}在执行代码中,连续执行了三次查询操作,看一下日志打印,如下所示。
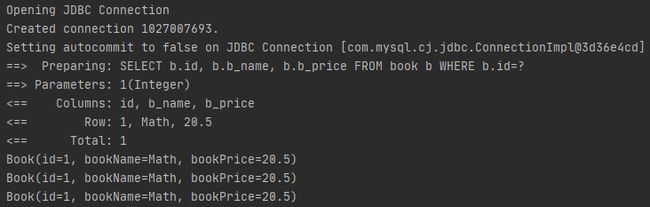
可以知道,只有第一次查询时和数据库进行了交互,后面两次查询均是从一级缓存中查询的数据。现在往映射接口和映射文件中加入更改数据的逻辑,如下所示。
public interface BookMapper {
Book selectBookById(int id);
// 根据id更改图书价格
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
}
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
执行的操作为先执行一次查询操作,然后执行一次更新操作并提交事务,最后再执行一次查询操作,执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession = sqlSessionFactory.openSession(false);
BookMapper bookMapper = sqlSession.getMapper(BookMapper.class);
System.out.println(bookMapper.selectBookById(1));
System.out.println("Change database.");
bookMapper.updateBookPriceById(1, 22.5f);
sqlSession.commit();
System.out.println(bookMapper.selectBookById(1));
}
}执行结果如下所示。
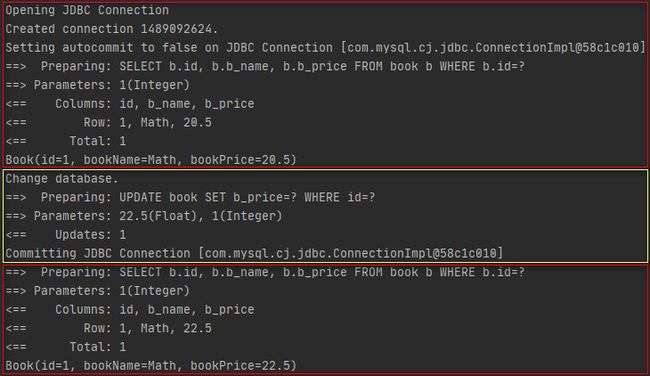
通过上述结果可以知道,在执行更新操作之后,再执行查询操作时,是直接从数据库查询的数据,并未使用一级缓存,即在一个会话中,对数据库的增,删,改操作,均会使一级缓存失效。
现在在执行代码中创建两个会话,先让会话1执行一次查询操作,然后让会话2执行一次更新操作并提交事务,最后让会话1再执行一次相同的查询。执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
System.out.println("Change database.");
bookMapper2.updateBookPriceById(1, 22.5f);
sqlSession2.commit();
System.out.println(bookMapper1.selectBookById(1));
}
}执行结果如下所示。
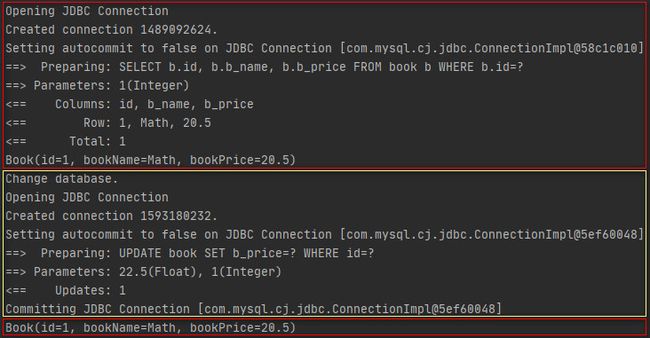
上述结果表明,会话1的第一次查询是直接查询的数据库,然后会话2执行了一次更新操作并提交了事务,此时数据库中id为1的图书的价格已经变更为了22.5,紧接着会话1又做了一次查询,但查询结果中的图书价格为20.5,说明会话1的第二次查询是从缓存获取的查询结果。所以在这里可以知道,Mybatis中每个会话均会维护一份一级缓存,不同会话之间的一级缓存各不影响。
在本小节最后,对Mybatis的一级缓存机制做一个总结,如下所示。
Mybatis的一级缓存默认开启,且默认作用范围为SESSION,即一级缓存在一个会话中生效,也可以通过配置将作用范围设置为STATEMENT,让一级缓存仅针对当前执行的SQL语句生效;- 在同一个会话中,执行增,删,改操作会使本会话中的一级缓存失效;
- 不同会话持有不同的一级缓存,本会话内的操作不会影响其它会话内的一级缓存。
二. 一级缓存源码分析
本小节将对一级缓存对应的Mybatis源码进行讨论。在Mybatis源码-Executor的执行过程中已经知道,禁用二级缓存的情况下,执行查询操作时,调用链如下所示。

在BaseExecutor中有两个重载的query()方法,下面先看第一个query()方法的实现,如下所示。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler) throws SQLException {
// 获取Sql语句
BoundSql boundSql = ms.getBoundSql(parameter);
// 生成CacheKey
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 调用重载的query()方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
} 在上述query()方法中,先会在MappedStatement中获取SQL语句,然后生成CacheKey,这个CacheKey实际就是本会话一级缓存中缓存的唯一标识,CacheKey类图如下所示。
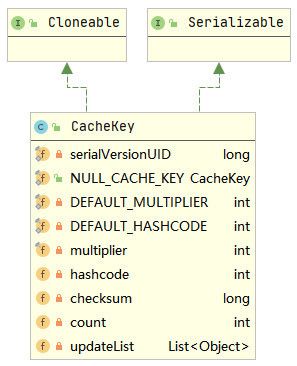
CacheKey中的multiplier,hashcode,checksum,count和updateList字段用于判断CacheKey之间是否相等,这些字段会在CacheKey的构造函数中进行初始化,如下所示。
public CacheKey() {
this.hashcode = DEFAULT_HASHCODE;
this.multiplier = DEFAULT_MULTIPLIER;
this.count = 0;
this.updateList = new ArrayList<>();
}同时hashcode,checksum,count和updateList字段会在CacheKey的update()方法中被更新,如下所示。
public void update(Object object) {
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}主要逻辑就是基于update()方法的入参计算并更新hashcode,checksum和count的值,然后再将入参添加到updateList集合中。同时,在CacheKey重写的equals()方法中,只有当hashcode相等,checksum相等,count相等,以及updateList集合中的元素也全都相等时,才算做两个CacheKey是相等。
回到上述的BaseExecutor中的query()方法,在其中会调用createCacheKey()方法生成CacheKey,其部分源码如下所示。
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, BoundSql boundSql) {
......
// 创建CacheKey
CacheKey cacheKey = new CacheKey();
// 基于MappedStatement的id更新CacheKey
cacheKey.update(ms.getId());
// 基于RowBounds的offset更新CacheKey
cacheKey.update(rowBounds.getOffset());
// 基于RowBounds的limit更新CacheKey
cacheKey.update(rowBounds.getLimit());
// 基于Sql语句更新CacheKey
cacheKey.update(boundSql.getSql());
......
// 基于查询参数更新CacheKey
cacheKey.update(value);
......
// 基于Environment的id更新CacheKey
cacheKey.update(configuration.getEnvironment().getId());
return cacheKey;
}所以可以得出结论,判断CacheKey是否相等的依据就是MappedStatement id + RowBounds offset + RowBounds limit + SQL + Parameter + Environment id相等。
获取到CacheKey后,会调用BaseExecutor中重载的query()方法,如下所示。
@Override
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// queryStack是BaseExecutor的成员变量
// queryStack主要用于递归调用query()方法时防止一级缓存被清空
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
// 先从一级缓存中根据CacheKey命中查询结果
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
// 处理存储过程相关逻辑
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 未命中,则直接查数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (BaseExecutor.DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
// 如果一级缓存作用范围是STATEMENT时,每次query()执行完毕就需要清空一级缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list;
} 上述query()方法中,会先根据CacheKey去缓存中命中查询结果,如果命中到查询结果并且映射文件中CURD标签上的statementType为CALLABLE,则会先在handleLocallyCachedOutputParameters()方法中处理存储过程相关逻辑然后再将命中的查询结果返回,如果未命中到查询结果,则会直接查询数据库。上述query()方法中还使用到了BaseExecutor的queryStack字段,主要防止一级缓存作用范围是STATEMENT并且还存在递归调用query()方法时,在递归尚未终止时就将一级缓存删除,如果不存在递归调用,那么一级缓存作用范围是STATEMENT时,每次查询结束后,都会清空缓存。下面看一下BaseExecutor中的一级缓存localCache,其实际是PerpetualCache,类图如下所示。
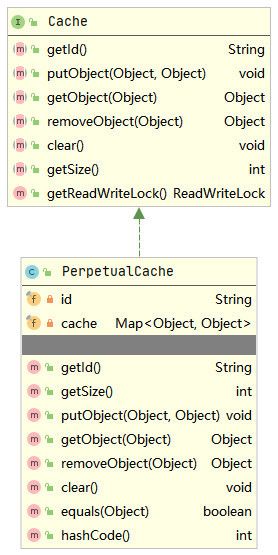
所以PerpetualCache的内部主要是基于一个Map(实际为HashMap)用于数据存储。现在回到上面的BaseExecutor的query()方法中,如果没有在一级缓存中命中查询结果,则会直接查询数据库,queryFromDatabase()方法如下所示。
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 调用doQuery()进行查询操作
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将查询结果添加到一级缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
// 返回查询结果
return list;
} queryFromDatabase()方法中和一级缓存相关的逻辑就是在查询完数据库后,会将查询结果以CacheKey作为唯一标识缓存到一级缓存中。
Mybatis中如果是执行增,改和删操作,并且在禁用二级缓存的情况下,均会调用到BaseExecutor的update()方法,如下所示。
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource())
.activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 执行操作前先清空缓存
clearLocalCache();
return doUpdate(ms, parameter);
}所以Mybatis中的一级缓存在执行了增,改和删操作后,会被清空即失效。
最后,一级缓存的使用流程可以用下图进行概括。
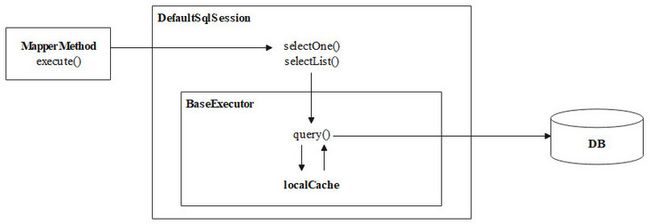
三. 二级缓存机制展示
Mybatis的一级缓存仅在一个会话中被共享,会话之间的一级缓存互不影响,而Mybatis的二级缓存可以被多个会话共享,本小节将结合例子,对Mybatis中的二级缓存的使用机制进行分析。要使用二级缓存,需要对Mybatis配置文件进行更改以开启二级缓存,如下所示。
上述配置文件中还将一级缓存的作用范围设置为了STATEMENT,目的是为了在例子中屏蔽一级缓存对查询结果的干扰。映射接口如下所示。
public interface BookMapper {
Book selectBookById(int id);
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
}要使用二级缓存,还需要在映射文件中加入二级缓存相关的设置,如下所示。
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
二级缓存相关设置的每一项的含义,会在本小节末尾进行说明。
场景一:创建两个会话,会话1以相同SQL语句连续执行两次查询,会话2以相同SQL语句执行一次查询。执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper2.selectBookById(1));
}
}执行结果如下所示。
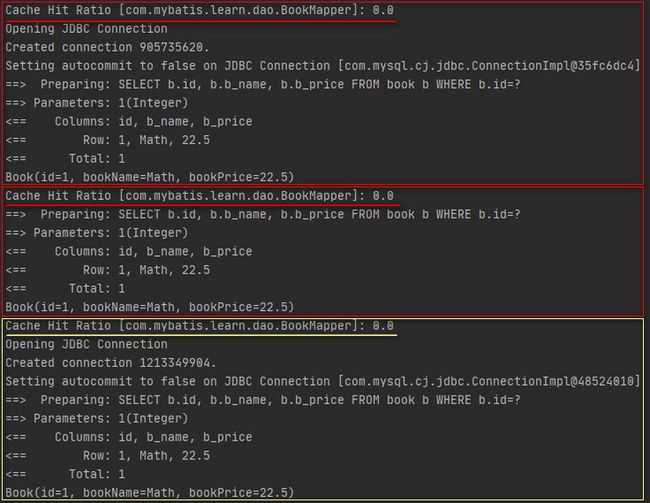
Mybatis中的二级缓存开启时,每次查询会先去二级缓存中命中查询结果,未命中时才会使用一级缓存以及直接去查询数据库。上述结果截图表明,场景一中,SQL语句相同时,无论是同一会话的连续两次查询还是另一会话的一次查询,均是查询的数据库,仿佛二级缓存没有生效,实际上,将查询结果缓存到二级缓存中需要事务提交,场景一中并没有事务提交,所以二级缓存中是没有内容的,最终导致三次查询均是直接查询的数据库。此外,如果是增删改操作,只要没有事务提交,那么就不会影响二级缓存。
场景二:创建两个会话,会话1执行一次查询并提交事务,然后会话1以相同SQL语句再执行一次查询,接着会话2以相同SQL语句执行一次查询。执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
SqlSession sqlSession1 = sqlSessionFactory.openSession(false);
SqlSession sqlSession2 = sqlSessionFactory.openSession(false);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
sqlSession1.commit();
System.out.println(bookMapper1.selectBookById(1));
System.out.println(bookMapper2.selectBookById(1));
}
}执行结果如下所示。
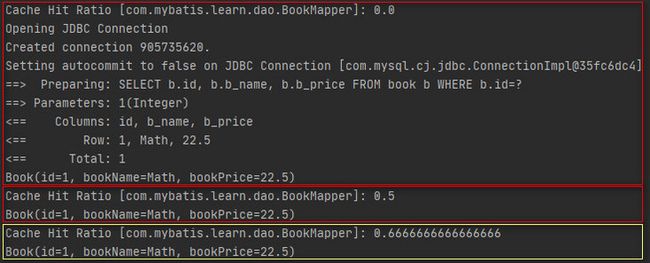
场景二中第一次查询后提交了事务,此时将查询结果缓存到了二级缓存,所以后续的查询全部在二级缓存中命中了查询结果。
场景三:创建两个会话,会话1执行一次查询并提交事务,然后会话2执行一次更新并提交事务,接着会话1再执行一次相同的查询。执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
// 将事务隔离级别设置为读已提交
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookMapper bookMapper2 = sqlSession2.getMapper(BookMapper.class);
System.out.println(bookMapper1.selectBookById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookMapper2.updateBookPriceById(1, 20.5f);
sqlSession2.commit();
System.out.println(bookMapper1.selectBookById(1));
}
}执行结果如下所示。
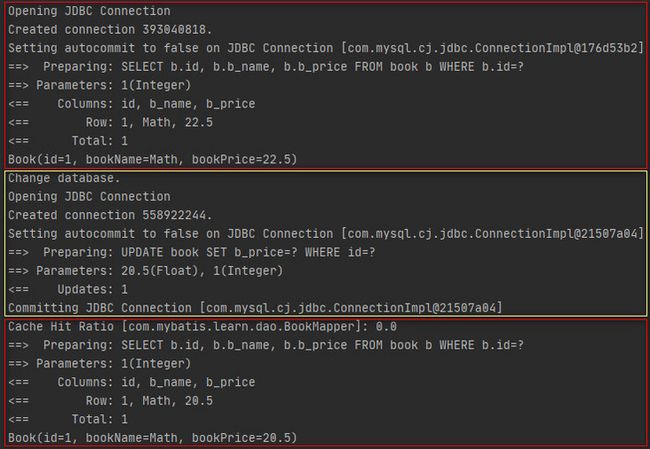
场景三的执行结果表明,执行更新操作并且提交事务后,会清空二级缓存,执行新增和删除操作也是同理。
场景四:创建两个会话,创建两张表,会话1首先执行一次多表查询并提交事务,然后会话2执行一次更新操作以更新表2的数据并提交事务,接着会话1再执行一次相同的多表查询。创表语句如下所示。
CREATE TABLE book(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
b_name VARCHAR(255) NOT NULL,
b_price FLOAT NOT NULL,
bs_id INT(11) NOT NULL,
FOREIGN KEY book(bs_id) REFERENCES bookstore(id)
);
CREATE TABLE bookstore(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
bs_name VARCHAR(255) NOT NULL
)往book表和bookstore表中添加如下数据。
INSERT INTO book (b_name, b_price, bs_id) VALUES ("Math", 20.5, 1);
INSERT INTO book (b_name, b_price, bs_id) VALUES ("English", 21.5, 1);
INSERT INTO book (b_name, b_price, bs_id) VALUES ("Water Margin", 30.5, 2);
INSERT INTO bookstore (bs_name) VALUES ("XinHua");
INSERT INTO bookstore (bs_name) VALUES ("SanYou")创建BookStore类,如下所示。
@Data
public class BookStore {
private String id;
private String bookStoreName;
}创建BookDetail类,如下所示。
@Data
public class BookDetail {
private long id;
private String bookName;
private float bookPrice;
private BookStore bookStore;
}BookMapper映射接口添加selectBookDetailById()方法,如下所示。
public interface BookMapper {
Book selectBookById(int id);
void updateBookPriceById(@Param("id") int id, @Param("bookPrice") float bookPrice);
BookDetail selectBookDetailById(int id);
}BookMapper.xml映射文件如下所示。
UPDATE
book
SET
b_price=#{bookPrice}
WHERE
id=#{id}
还需要添加BookStoreMapper映射接口,如下所示。
public interface BookStoreMapper {
void updateBookPriceById(@Param("id") int id, @Param("bookStoreName") String bookStoreName);
}还需要添加BookStoreMapper.xml映射文件,如下所示。
UPDATE
bookstore
SET
bs_name=#{bookStoreName}
WHERE
id=#{id}
进行完上述更改之后,进行场景四的测试,执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
// 将事务隔离级别设置为读已提交
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookStoreMapper bookStoreMapper = sqlSession2.getMapper(BookStoreMapper.class);
System.out.println(bookMapper1.selectBookDetailById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookStoreMapper.updateBookStoreById(1, "ShuXiang");
sqlSession2.commit();
System.out.println(bookMapper1.selectBookDetailById(1));
}
}执行结果如下所示。
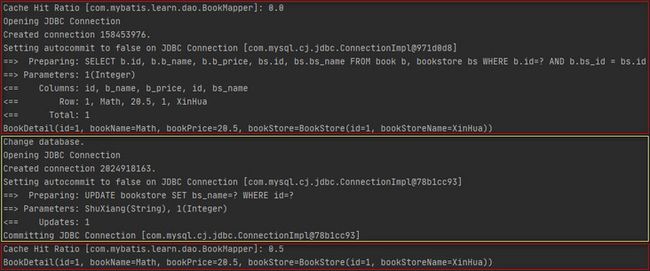
会话1第一次执行多表查询并提交事务时,将查询结果缓存到了二级缓存中,然后会话2对bookstore表执行了更新操作并提交了事务,但是最后会话1第二次执行相同的多表查询时,却从二级缓存中命中了查询结果,最终导致查询出来了脏数据。实际上,二级缓存的作用范围是同一命名空间下的多个会话共享,这里的命名空间就是映射文件的namespace,可以理解为每一个映射文件持有一份二级缓存,所有会话在这个映射文件中的所有操作,都会共享这个二级缓存。所以场景四的例子中,会话2对bookstore表执行更新操作并提交事务时,清空的是BookStoreMapper.xml持有的二级缓存,BookMapper.xml持有的二级缓存没有感知到bookstore表的数据发生了变化,最终导致会话1第二次执行相同的多表查询时从二级缓存中命中了脏数据。
场景五:执行的操作和场景四一致,但是在BookStoreMapper.xml文件中进行如下更改。
UPDATE
bookstore
SET
bs_name=#{bookStoreName}
WHERE
id=#{id}
执行代码如下所示。
public class MybatisTest {
public static void main(String[] args) throws Exception {
String resource = "mybatis-config.xml";
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream(resource));
// 将事务隔离级别设置为读已提交
SqlSession sqlSession1 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
SqlSession sqlSession2 = sqlSessionFactory.openSession(
TransactionIsolationLevel.READ_COMMITTED);
BookMapper bookMapper1 = sqlSession1.getMapper(BookMapper.class);
BookStoreMapper bookStoreMapper = sqlSession2.getMapper(BookStoreMapper.class);
System.out.println(bookMapper1.selectBookDetailById(1));
sqlSession1.commit();
System.out.println("Change database.");
bookStoreMapper.updateBookStoreById(1, "ShuXiang");
sqlSession2.commit();
System.out.println(bookMapper1.selectBookDetailById(1));
}
}执行结果如下所示。
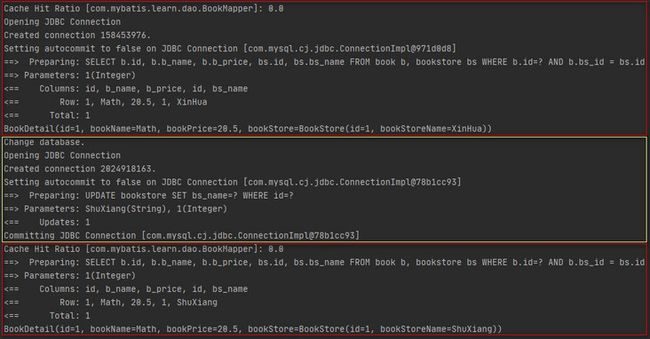
在BookStoreMapper.xml中使用BookMapper.xml映射文件与BookStoreMapper.xml映射文件持有同一份二级缓存,会话2在BookStoreMapper.xml映射文件中执行更新操作并提交事务后,会导致二级缓存被清空,从而会话1第二次执行相同的多表查询时会从数据库查询数据。
现在对Mybatis的二级缓存机制进行一个总结,如下所示。
Mybatis中的二级缓存默认开启,可以在Mybatis配置文件中的Mybatis中的二级缓存作用范围是同一命名空间下的多个会话共享,这里的命名空间就是映射文件的namespace,即不同会话使用同一映射文件中的SQL语句对数据库执行操作并提交事务后,均会影响这个映射文件持有的二级缓存;Mybatis中执行查询操作后,需要提交事务才能将查询结果缓存到二级缓存中;Mybatis中执行增,删或改操作并提交事务后,会清空对应的二级缓存;Mybatis中需要在映射文件中添加
最后,对
| 属性 | 含义 | 默认值 |
|---|---|---|
| eviction | 缓存淘汰策略。LRU表示最近使用频次最少的优先被淘汰;FIFO表示先被缓存的会先被淘汰;SOFT表示基于软引用规则来淘汰;WEAK表示基于弱引用规则来淘汰 | LRU |
| flushInterval | 缓存刷新间隔。单位毫秒 | 空,表示永不过期 |
| type | 缓存的类型 | PerpetualCache |
| size | 最多缓存的对象个数 | 1024 |
| blocking | 缓存未命中时是否阻塞 | false |
| readOnly | 缓存中的对象是否只读。配置为true时,表示缓存对象只读,命中缓存时会直接将缓存的对象返回,性能更快,但是线程不安全;配置为false时,表示缓存对象可读写,命中缓存时会将缓存的对象克隆然后返回克隆的对象,性能更慢,但是线程安全 | false |
| 属性 | 含义 |
|---|---|
| namespace | 其它映射文件的命名空间,设置之后则当前映射文件将和其它映射文件将持有同一份二级缓存 |
四. 二级缓存的创建
在Mybatis源码-加载映射文件与动态代理中已经知道,XMLMapperBuilder的configurationElement()方法会解析映射文件的内容并丰富到Configuration中,但在Mybatis源码-加载映射文件与动态代理中并未对解析映射文件的configurationElement()方法如下所示。
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// 解析标签
cacheRefElement(context.evalNode("cache-ref"));
// 解析标签
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '"
+ resource + "'. Cause: " + e, e);
}
} 在configurationElement()方法中会先解析cacheElement()方法如下所示。
private void cacheElement(XNode context) {
if (context != null) {
// 获取标签的type属性值
String type = context.getStringAttribute("type", "PERPETUAL");
Class typeClass = typeAliasRegistry.resolveAlias(type);
// 获取标签的eviction属性值
String eviction = context.getStringAttribute("eviction", "LRU");
Class evictionClass = typeAliasRegistry.resolveAlias(eviction);
// 获取标签的flushInterval属性值
Long flushInterval = context.getLongAttribute("flushInterval");
// 获取标签的size属性值
Integer size = context.getIntAttribute("size");
// 获取标签的readOnly属性值并取反
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
// 获取标签的blocking属性值
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
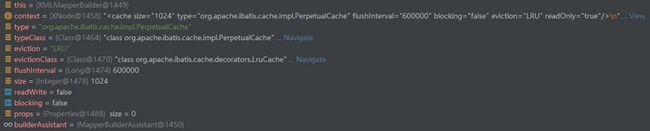
} 单步跟踪cacheElement()方法,每个属性解析出来的内容可以参照下图。
Cache的实际创建是在MapperBuilderAssistant的useNewCache()方法中,实现如下所示。
public Cache useNewCache(Class typeClass,
Class evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}在MapperBuilderAssistant的useNewCache()方法中会先创建CacheBuilder,然后调用CacheBuilder的build()方法构建Cache。CacheBuilder类图如下所示。

CacheBuilder的构造函数如下所示。
public CacheBuilder(String id) {
this.id = id;
this.decorators = new ArrayList<>();
}所以可以知道,CacheBuilder的id字段实际就是当前映射文件的namespace,其实到这里已经大致可以猜到,CacheBuilder构建出来的二级缓存Cache在Configuration中的唯一标识就是映射文件的namespace。此外,CacheBuilder中的implementation是PerpetualCache的Class对象,decorators集合中包含有LruCache的Class对象。下面看一下CacheBuilder的build()方法,如下所示。
public Cache build() {
setDefaultImplementations();
// 创建PerpetualCache,作为基础Cache对象
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
if (PerpetualCache.class.equals(cache.getClass())) {
// 为基础Cache对象添加缓存淘汰策略相关的装饰器
for (Class decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
// 继续添加装饰器
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}CacheBuilder的build()方法首先会创建PerpetualCache对象,作为基础缓存对象,然后还会为基础缓存对象根据缓存淘汰策略添加对应的装饰器,比如LruCache,根据eviction属性值的不同,对应的装饰器就不同,下图是Mybatis为缓存淘汰策略提供的所有装饰器。
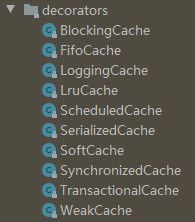
CacheBuilder的build()方法中,为PerpetualCache添加完缓存淘汰策略添装饰器后,还会继续添加标准装饰器,Mybatis中定义的标准装饰器有ScheduledCache,SerializedCache,LoggingCache,SynchronizedCache和BlockingCache,含义如下表所示。
| 装饰器 | 含义 |
|---|---|
ScheduledCache |
提供缓存定时刷新功能, |
SerializedCache |
提供缓存序列化功能, |
LoggingCache |
提供日志功能,默认会添加该装饰器 |
SynchronizedCache |
提供同步功能,默认会添加该装饰器 |
BlockingCache |
提供阻塞功能, |
如下是一个
那么生成的二级缓存对象如下所示。
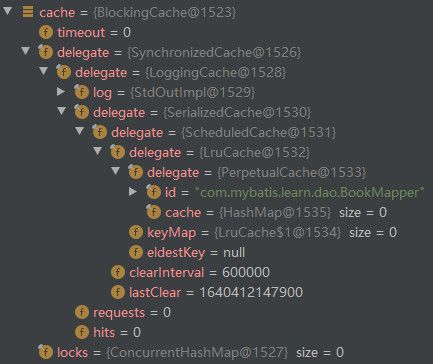
整个装饰链如下图所示。

现在回到MapperBuilderAssistant的useNewCache()方法,构建好二级缓存对象之后,会将其添加到Configuration中,Configuration的addCache()方法如下所示。
public void addCache(Cache cache) {
caches.put(cache.getId(), cache);
}这里就印证了前面的猜想,即二级缓存Cache在Configuration中的唯一标识就是映射文件的namespace。
现在再分析一下XMLMapperBuilder中的configurationElement()方法对cacheRefElement()方法如下所示。
private void cacheRefElement(XNode context) {
if (context != null) {
// 在Configuration的cacheRefMap中将当前映射文件命名空间与引用的映射文件命名空间建立映射关系
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
// CacheRefResolver会将引用的映射文件的二级缓存从Configuration中获取出来并赋值给MapperBuilderAssistant的currentCache
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}cacheRefElement()方法会首先在Configuration的cacheRefMap中将当前映射文件命名空间与引用的映射文件命名空间建立映射关系,然后会通过CacheRefResolver将引用的映射文件的二级缓存从Configuration中获取出来并赋值给MapperBuilderAssistant的currentCache,currentCache这个字段后续会在MapperBuilderAssistant构建MappedStatement时传递给MappedStatement,以及如果映射文件中还存在MapperBuilderAssistant会将
五. 二级缓存的源码分析
本小节将对二级缓存对应的Mybatis源码进行讨论。Mybatis中开启二级缓存之后,执行查询操作时,调用链如下所示。

在CachingExecutor中有两个重载的query()方法,下面先看第一个query()方法,如下所示。
@Override
public List query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取Sql语句
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} 继续看重载的query()方法,如下所示。
@Override
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds,
ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 从MappedStatement中将二级缓存获取出来
Cache cache = ms.getCache();
if (cache != null) {
// 清空二级缓存(如果需要的话)
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 处理存储过程相关逻辑
ensureNoOutParams(ms, boundSql);
// 从二级缓存中根据CacheKey命中查询结果
List list = (List) tcm.getObject(cache, key);
if (list == null) {
// 未命中缓存,则查数据库
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将从数据库查询到的结果缓存到二级缓存中
tcm.putObject(cache, key, list);
}
// 返回查询结果
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} 上述query()方法整体执行流程比较简单,概括下来就是:先从缓存中命中查询结果,命中到查询结果则返回,未命中到查询结果则直接查询数据库并把查询结果缓存到二级缓存中。但是从二级缓存中根据CacheKey命中查询结果时,并没有直接通过Cache的getObject()方法,而是通过tcm的getObject()方法,合理进行推测的话,应该就是tcm持有二级缓存的引用,当需要从二级缓存中命中查询结果时,由tcm将请求转发给二级缓存。实际上,tcm为CachingExecutor持有的TransactionalCacheManager对象,从二级缓存中命中查询结果这一请求之所以需要通过TransactionalCacheManager转发给二级缓存,是因为需要借助TransactionalCacheManager实现只有当事务提交时,二级缓存才会被更新这一功能。联想到第三小节中的场景一和场景二的示例,将查询结果缓存到二级缓存中需要事务提交这一功能,其实就是借助TransactionalCacheManager实现的,所以下面对TransactionalCacheManager进行一个说明。首先TransactionalCacheManager的类图如下所示。

TransactionalCacheManager中持有一个Map,该Map的键为Cache,值为TransactionalCache,即一个二级缓存对应一个TransactionalCache。继续看TransactionalCacheManager的getObject()方法,如下所示。
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}通过上述代码可以知道,一个二级缓存对应一个TransactionalCache,且TransactionalCache中持有这个二级缓存的引用,当调用TransactionalCacheManager的getObject()方法时,TransactionalCacheManager会将调用请求转发给TransactionalCache,下面分析一下TransactionalCache,类图如下所示。
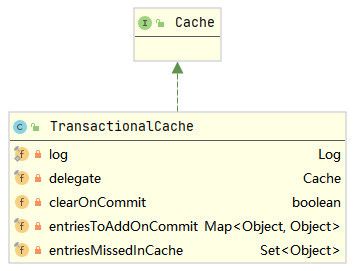
继续看TransactionalCache的getObject()方法,如下所示。
@Override
public Object getObject(Object key) {
// 在二级缓存中命中查询结果
Object object = delegate.getObject(key);
if (object == null) {
// 未命中则将CacheKey添加到entriesMissedInCache中
// 用于统计命中率
entriesMissedInCache.add(key);
}
if (clearOnCommit) {
return null;
} else {
return object;
}
}到这里就可以知道了,在CachingExecutor中通过CacheKey命中查询结果时,其实就是CachingExecutor将请求发送给TransactionalCacheManager,TransactionalCacheManager将请求转发给二级缓存对应的TransactionalCache,最后再由TransactionalCache将请求最终传递到二级缓存。在上述getObject()方法中,如果clearOnCommit为true,则无论是否在二级缓存中命中查询结果,均返回null,那么clearOnCommit在什么地方会被置为true呢,其实就是在CachingExecutor的flushCacheIfRequired()方法中,这个方法在上面分析的query()方法中会被调用到,看一下flushCacheIfRequired()的实现,如下所示。
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}调用TransactionalCacheManager的clear()方法时,最终会调用到TransactionalCache的clear()方法,如下所示。
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}现在继续分析为什么将查询结果缓存到二级缓存中需要事务提交。从数据库中查询出来结果后,CachingExecutor会调用TransactionalCacheManager的putObject()方法试图将查询结果缓存到二级缓存中,我们已经知道,如果事务不提交,那么查询结果是无法被缓存到二级缓存中,那么在事务提交之前,查询结果肯定被暂存到了某个地方,为了搞清楚这部分逻辑,先看一下TransactionalCacheManager的putObject()方法,如下所示。
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}继续看TransactionalCache的putObject()方法,如下所示。
@Override
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}到这里就搞明白了,在事务提交之前,查询结果会被暂存到TransactionalCache的entriesToAddOnCommit中。下面继续分析事务提交时如何将entriesToAddOnCommit中暂存的查询结果刷新到二级缓存中,DefaultSqlSession的commit()方法如下所示。
@Override
public void commit() {
commit(false);
}
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException(
"Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}在DefaultSqlSession的commit()方法中会调用到CachingExecutor的commit()方法,如下所示。
@Override
public void commit(boolean required) throws SQLException {
delegate.commit(required);
// 调用TransactionalCacheManager的commit()方法
tcm.commit();
}在CachingExecutor的commit()方法中,会调用TransactionalCacheManager的commit()方法,如下所示。
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
// 调用TransactionalCache的commit()方法
txCache.commit();
}
}继续看TransactionalCache的commit()方法,如下所示。
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
flushPendingEntries();
reset();
}
private void flushPendingEntries() {
// 将entriesToAddOnCommit中暂存的查询结果全部缓存到二级缓存中
for (Map.Entry entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
} 至此可以知道,当调用SqlSession的commit()方法时,会一路传递到TransactionalCache的commit()方法,最终调用TransactionalCache的flushPendingEntries()方法将暂存的查询结果全部刷到二级缓存中。
当执行增,删,改操作并提交事务时,二级缓存会被清空,这是因为增,删,改操作最终会调用到CachingExecutor的update()方法,而update()方法中又会调用flushCacheIfRequired()方法,已经知道在flushCacheIfRequired()方法中如果所执行的方法对应的MappedStatement的flushCacheRequired字段为true的话,则会最终将TransactionalCache中的clearOnCommit字段置为true,随即在事务提交的时候,会将二级缓存清空。而加载映射文件时,解析CURD标签为MappedStatement时有如下一行代码。
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);即如果没有在CURD标签中显式的设置flushCache属性,则会给flushCache字段一个默认值,且默认值为非查询标签下默认为true,所以到这里就可以知道,如果是增,删,改操作,那么TransactionalCache中的clearOnCommit字段会被置为true,从而在提交事务时会在TransactionalCache的commit()方法中将二级缓存清空。
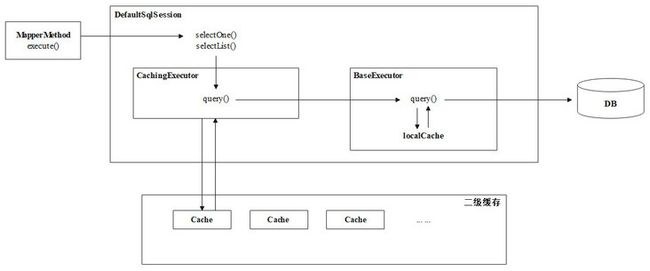
到这里,二级缓存的源码分析结束。二级缓存的使用流程可以用下图进行概括,如下所示。
总结
关于Mybatis的一级缓存,总结如下。
Mybatis的一级缓存默认开启,且默认作用范围为SESSION,即一级缓存在一个会话中生效,也可以通过配置将作用范围设置为STATEMENT,让一级缓存仅针对当前执行的SQL语句生效;- 在同一个会话中,执行增,删,改操作会使本会话中的一级缓存失效;
- 不同会话持有不同的一级缓存,本会话内的操作不会影响其它会话内的一级缓存。
关于Mybatis的二级缓存,总结如下。
Mybatis中的二级缓存默认开启,可以在Mybatis配置文件中的Mybatis中的二级缓存作用范围是同一命名空间下的多个会话共享,这里的命名空间就是映射文件的namespace,即不同会话使用同一映射文件中的SQL语句对数据库执行操作并提交事务后,均会影响这个映射文件持有的二级缓存;Mybatis中执行查询操作后,需要提交事务才能将查询结果缓存到二级缓存中;Mybatis中执行增,删或改操作并提交事务后,会清空对应的二级缓存;Mybatis中需要在映射文件中添加